
优化
spark sql 优化
- 在配置SparkSQL任务时指定executor核心数 建议为4 (同一executor[进程]内内存共享,当数据倾斜时,使用相同核心数与内存量的两个任务,executor总量少的任务不容易OOM,因为单核心最大可用内存大.但是并非越大越好,因为单个exector最大core受服务器剩余core数量限制,过大的core数量可能导致资源分配不足)
- 设置spark.default.parallelism=600 每个stage的默认task数量 (计算公式为num-executors * executor-cores 系统默认值分区为40,这是导致executor并行度上不去的罪魁祸首,之所以这样计算是为了尽量避免计算最慢的task决定整个stage的时间,将其设置为总核心的2-3倍,让运行快的task可以继续领取任务计算直至全部任务计算完毕)
- 开启spark.sql.auto.repartition=true 自动重新分区 (每个stage[阶段]运行时分区并不尽相同,使用此配置可优化计算后分区数,避免分区数过大导致单个分区数据量过少,每个task运算分区数据时时间过短,从而导致task频繁调度消耗过多时间)
- 设置spark.sql.shuffle.partitions=400 提高shuffle并行度 (shuffle read task的并行度)
- 设置spark.shuffle.service.enabled=true 提升shuffle效率 --!并未测试 (Executor 进程除了运行task 也要进行写shuffle 数据,当Executor进程任务过重时,导致GC不能为其他Executor提供shuffle数据时将会影响效率.此服务开启时代替Executor来抓取shuffle数据)
//1.下列Hive参数对Spark同样起作用。
set hive.exec.dynamic.partition=true; // 是否允许动态生成分区
set hive.exec.dynamic.partition.mode=nonstrict; // 是否容忍指定分区全部动态生成
set hive.exec.max.dynamic.partitions = 100; // 动态生成的最多分区数
//2.运行行为
set spark.sql.autoBroadcastJoinThreshold; // 大表 JOIN 小表,小表做广播的阈值
set spark.dynamicAllocation.enabled; // 开启动态资源分配
set spark.dynamicAllocation.maxExecutors; //开启动态资源分配后,最多可分配的Executor数
set spark.dynamicAllocation.minExecutors; //开启动态资源分配后,最少可分配的Executor数
set spark.sql.shuffle.partitions; // 需要shuffle是mapper端写出的partition个数
set spark.sql.adaptive.enabled; // 是否开启调整partition功能,如果开启,spark.sql.shuffle.partitions设置的partition可能会被合并到一个reducer里运行
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize; //开启spark.sql.adaptive.enabled后,两个partition的和低于该阈值会合并到一个reducer
set spark.sql.adaptive.minNumPostShufflePartitions; // 开启spark.sql.adaptive.enabled后,最小的分区数
set spark.hadoop.mapreduce.input.fileinputformat.split.maxsize; //当几个stripe的大小大于该值时,会合并到一个task中处理
//3.executor能力
set spark.executor.memory; // executor用于缓存数据、代码执行的堆内存以及JVM运行时需要的内存
set spark.yarn.executor.memoryOverhead; //Spark运行还需要一些堆外内存,直接向系统申请,如数据传输时的netty等。
set spark.sql.windowExec.buffer.spill.threshold; //当用户的SQL中包含窗口函数时,并不会把一个窗口中的所有数据全部读进内存,而是维护一个缓存池,当池中的数据条数大于该参数表示的阈值时,spark将数据写到磁盘
set spark.executor.cores; //单个executor上可以同时运行的task数
问题:
driver拉去数据量过大:
报错信息:spark.driver.maxResultSize
问题原因:样本不均衡
解决办法:将spark.driver.maxResultSize设置更大一点
spark.driver.maxResultSize 4G
因为作业内存不足,导致GC,GC可能导致executor与AM通信超时,故AM认为executor挂了,会发停止的signal
报错信息:worker机器,ERROR SIGTERM handler CoarseGrainedExecutorBackend: RECEIVED SIGNAL TERM
问题原因:设置了动态资源配置导致的
解决办法:
增加心跳时长:spark.executor.heartbeatInterval=30
关闭动态资源配置
--conf spark.network.timeout=600 \
--conf spark.sql.shuffle.partitions=100 \
--conf hive.exec.dynamic.partition=true \
--conf spark.executor.heartbeatInterval=30 \
解决pandas转dataframe的问题
报错信息:TypeError: Can not merge type <class 'pyspark.sql.types.StringType'> and <class 'pyspark.sql.types.DoubleType'>
问题原因:pandas有为空的数据,空值为np.NaN,spark无法识别
解决办法: 需要进行空值处理和数量类型处理
# 空值处理
fillna_value = {
"time_id": 0,
"hex_type_danger_score": "-",
}
print("空值处理")
danger_score_to_platform_df = danger_score_to_platform_df.fillna(fillna_value)
print(danger_score_to_platform_df.head())
print("数据类型处理")
astype_value = {
"time_id": int,
"city_id": int,
}
# 数据类型处理
for columns, dtype in astype_value.items():
danger_score_to_platform_df[columns] = danger_score_to_platform_df[columns].astype(dtype)
解决array数据类型保持到csv保存的问题
报错信息:java.lang.UnsupportedOperationException: CSV data source does not support array<string> data type.
问题原因:spark中存在array相关的数据类,csv无法识别
解决方案:将array类型数据转化为string
from pyspark.sql.types import StringType
for dtype in result_df.dtypes:
column = dtype[0]
data_type = dtype[1]
print(dtype[0], dtype[1])
if "array" in str(data_type):
# if "double" in str(data_type):
result_df = result_df.withColumn(column, result_df[column].cast(StringType()))
解决spark依赖的UDF jar包问题
报错信息:u"Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder':"
问题原因:spark 提交参数中的jars包含org.apache.hadoop和org.apache.spark相关的jar包
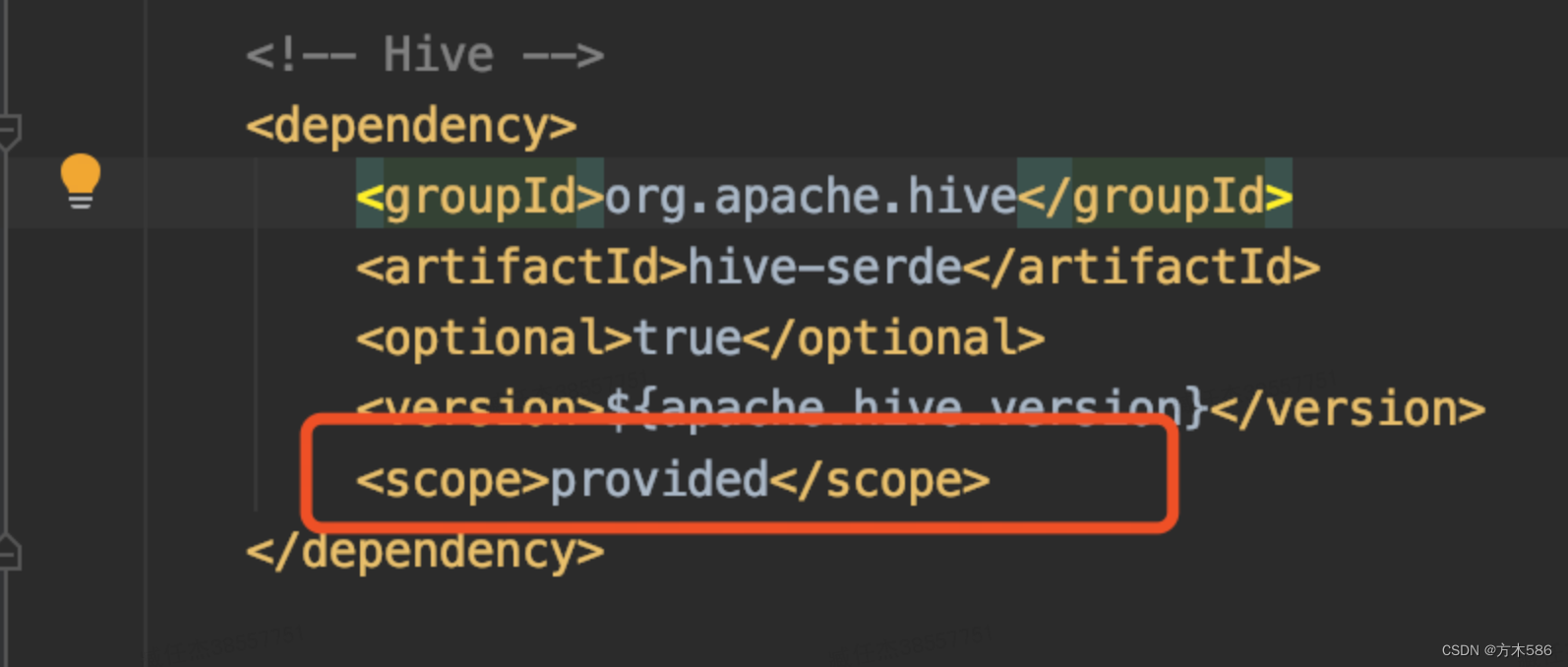
解决方案:jar包中不加入hadoop和spark相关的包, maven中:加入<scope>provided</scope >, 还注意多个jar包时,需要逗号隔开,
如: --jars "viewfs:///user/hadoop-shangchao/user_upload/hex-udf-0.1.jar,viewfs:///user/hadoop-shangchao/user_upload/zhuyong05_SafeDispatchUDF-1.0.jar"
解决spark执行持久化过程报错:
报错信息: py4j.protocol.Py4JJavaError: An error occurred while calling o151.csv.
: org.apache.spark.SparkException: Job aborted.
问题原因:暂时未弄清楚
解决方案: spark-submit增加几个配置参数
解决spark执行持久化过程报错:
报错信息: py4j.protocol.Py4JJavaError: An error occurred while calling o151.csv.
: org.apache.spark.SparkException: Job aborted.
问题原因:暂时未弄清楚
解决方案: spark-submit增加几个配置参数
--conf spark.yarn.job.priority=1 \
--conf spark.dynamicAllocation.maxExecutors=100 \
--conf spark.network.timeout=600 \
--conf spark.driver.maxResultSize=4G \
--conf spark.sql.shuffle.partitions=100 \
--conf hive.exec.dynamic.partition=true \
--conf spark.executor.heartbeatInterval=120 \
版权归原作者 方木586 所有, 如有侵权,请联系我们删除。