
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀**对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于python的电商数据可视化系统
设计思路
一、课题背景与意义
随着电子商务的蓬勃发展,电商数据量的快速增长使得数据分析和可视化成为了一项重要的任务。Python作为一种高效且灵活的语言,为电商数据的处理和可视化提供了丰富的工具和库。基于Python的电商数据可视化系统能够帮助电商企业更好地理解和分析数据,从而做出更加明智的决策。该系统不仅可以帮助企业监控销售情况、用户行为等关键指标,还可以预测未来的趋势,为企业的战略规划和运营优化提供有力支持。
二、设计思路
2.1 网络爬虫
网络爬虫(又称为网页蜘蛛,网络机器人)是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫技术广泛应用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。爬虫的工作原理大致可以分为以下步骤:
- 从一个或若干初始网页的URL开始,获得初始网页上的URL。
- 在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
- 对于聚焦爬虫,还需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
- 根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
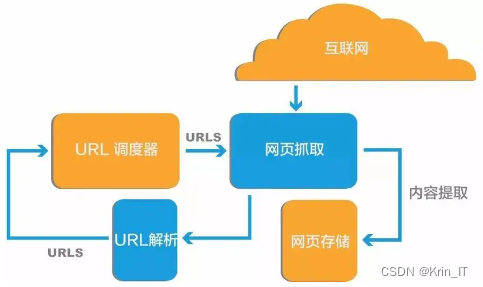

爬虫的本质是一种自动化技术,它可以实现根据用户指定的URL地址,自动获取网页上的信息,并将其保存到本地或者存储在数据库中。爬虫技术可以用来搜索网络的信息,提取有用的数据,更新网络信息,模拟人的行为,评估网站质量,测试网站可用性,帮助网站优化等。在技术上,爬虫通过发出HTTP请求,然后自动抓取返回的网页内容,并解析这些网页内容,从而获取有用的信息。爬虫一般分为数据采集,处理,储存三个部分。

2.2 时间序列分析
ARIMA是一种基于时间序列的统计模型,用于分析和预测时间序列数据。它结合了自回归(AR)和移动平均(MA)模型的特点,并通过差分运算使非平稳时间序列变得平稳。ARIMA模型要求输入数据是平稳的,这意味着时间序列的统计特性(如均值和方差)不会随时间变化。SARIMA是ARIMA模型的扩展,专门用于处理具有季节性影响的时间序列数据。它结合了ARIMA模型的特点,并添加了季节性自回归和季节性移动平均部分,以捕捉季节性因素对时间序列的影响。
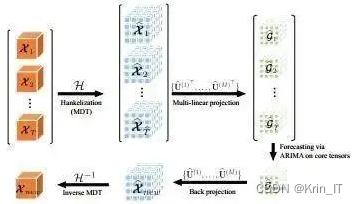
ARIMA(自回归整合移动平均模型)的优势主要体现在以下几个方面:
- ** 适应性强**:ARIMA模型可以处理非平稳时间序列数据,并对其进行建模和预测。这使得它能够适应各种复杂的时间序列数据,如金融市场数据、气候变化数据等。
- 预测准确:ARIMA模型可以通过对历史数据的分析,预测未来的发展趋势。这种预测能力在许多领域都有实际应用价值,如股票市场预测、销售预测等。
- 灵活性高:ARIMA模型可以灵活地调整参数和阶数,以适应不同的数据特征和变化趋势。这使得ARIMA模型具有较强的适应性和可扩展性。
- 广泛使用:ARIMA模型是时间序列分析中最为广泛使用的模型之一,它在学术研究和实际应用中都有很高的价值。许多统计软件和编程语言都提供了ARIMA模型的实现和工具箱。
- 模型简单:ARIMA模型只需要内生变量而不需要借助其他外生变量,这使得模型相对简单,易于理解和应用。

三、检测的实现
3.1 数据集
在构建基于Python的电商数据可视化系统时,我首先收集并整理了电商平台的交易数据、用户行为数据等多源数据。为了确保数据的质量和准确性,我进行了数据清洗和预处理工作,包括去除重复数据、填充缺失值、处理异常值等。为了更加直观地展示数据,我利用Python的Matplotlib和Seaborn库生成了多种静态图表。同时,我还采用了Plotly库实现了交互式图表,允许用户通过拖拽、缩放等操作来深入探索数据。
在数据分析和可视化的过程中,数据扩充是一个重要的环节。对于电商数据而言,通过数据扩充可以增加样本数量、提高模型的泛化能力。一种常见的数据扩充方法是利用生成对抗网络(GAN)来生成新的合成数据。GAN可以学习真实数据的分布,并生成与真实数据相似但又不完全相同的新数据,从而增加数据集的多样性。此外,还可以采用数据插值、特征工程等技术来扩充数据集。通过合理的数据扩充策略,我们可以进一步提升电商数据可视化系统的性能和准确性,为电商企业的决策提供更加可靠的支持。
3.2 实验及结果分析
基于Python的电商数据可视化系统的设计思路主要围绕以下几个关键步骤展开:
- 数据收集与预处理:首先,从电商平台的数据库或API中收集原始数据,这包括销售数据、用户行为数据、商品信息等。然后,使用Python的Pandas库对数据进行清洗和预处理,包括去除重复值、填充缺失值、处理异常值等,以确保数据的质量和准确性。
- 数据探索与分析:接下来,利用Python的数据分析库(如NumPy、Pandas等)对数据进行探索性分析,包括数据的分布、相关性、趋势等。这有助于我们理解数据的内在规律和特征,为后续的可视化设计提供指导。
- 可视化设计:根据数据探索的结果,选择合适的可视化工具和技术进行可视化设计。Python中有许多强大的可视化库可供选择,如Matplotlib、Seaborn、Plotly等。这些库提供了丰富的图表类型和交互功能,可以根据不同的数据特征和可视化需求进行选择。
- 可视化实现:在可视化设计的基础上,使用Python的可视化库实现具体的可视化效果。这包括绘制各种图表(如折线图、柱状图、散点图等)、创建交互式界面、实现动态数据更新等。
相关代码示例:
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制销售趋势图
plt.figure(figsize=(10, 5))
data['sales'].plot()
plt.title('Sales Trend Over Time')
plt.xlabel('Date')
plt.ylabel('Sales')
plt.grid(True)
plt.show()
# 绘制用户数量随时间变化的折线图
plt.figure(figsize=(10, 5))
data['users'].plot()
plt.title('User Growth Over Time')
plt.xlabel('Date')
plt.ylabel('Number of Users')
plt.grid(True)
plt.show()
# 绘制销售与用户数量的关系图
plt.figure(figsize=(10, 5))
sns.lineplot(data=data, x='date', y='sales', label='Sales')
sns.lineplot(data=data, x='date', y='users', label='Users')
plt.title('Sales and User Growth Comparison')
plt.xlabel('Date')
plt.ylabel('Values')
plt.legend()
plt.grid(True)
plt.show()
# 绘制销售与产品数量的相关性热图
plt.figure(figsize=(10, 8))
corr = data[['sales', 'products']].corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Sales and Products Correlation Heatmap')
plt.show()
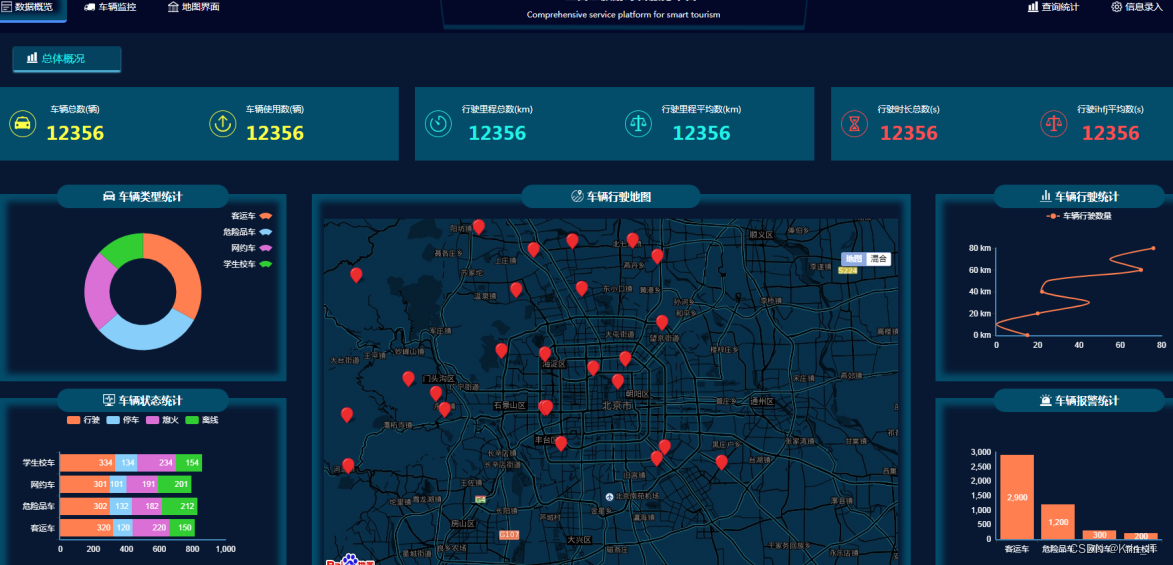
实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/136242033
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。