
Linux环境搭建Spark分为两个版本,分别是Scala版本和Python版本。
一、 安装Pyspark
本环境以 Python 环境为例。
1、下载spark
下载网址:https://archive.apache.org/dist/spark
下载安装包:根据自己环境选择合适版本,本环境以spark3.0版本为案例。
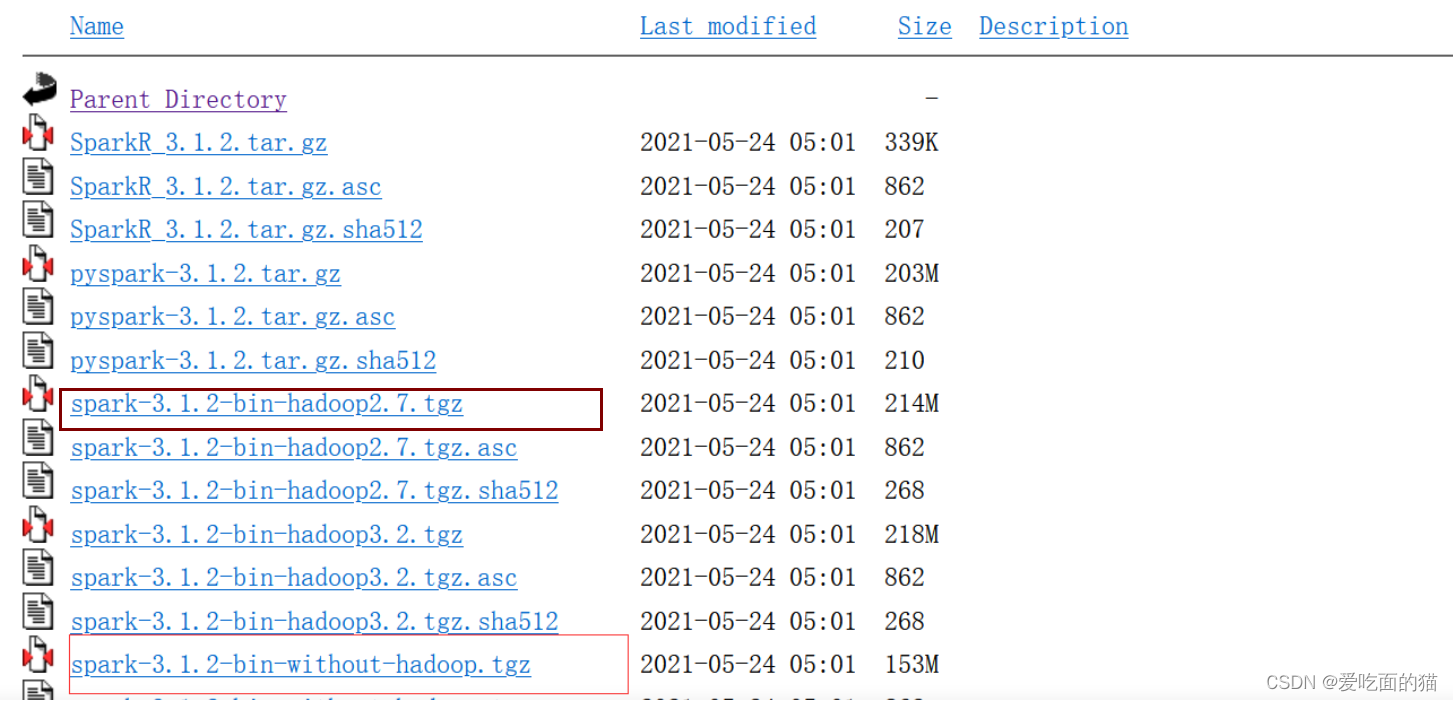
根据hadoop版本下载下载 spark-3.0.0-bin-hadoop2.7.tgz **/ ** spark-3.0.0-bin-hadoop3.2.tgz
如果不依赖hadoop,则下载** spark-3.0.0-bin-without-hadoop.tgz **
只安装pyspark下载pyspark-3.0.0.tar.gz
个人推荐带有hadoop版本 如 spark-3.0.0-bin-hadoop3.2.tgz ,将来可以使用hadoop,也可以使用python环境。
2、上传spark安装包到目录

3、解压spark安装包并重命名
重命名主要是为了便于配置环境变量



4、配置环境变量
vi .bash_profile

5、使环境生效
source .bash_profile
echo $SPARK_HOME

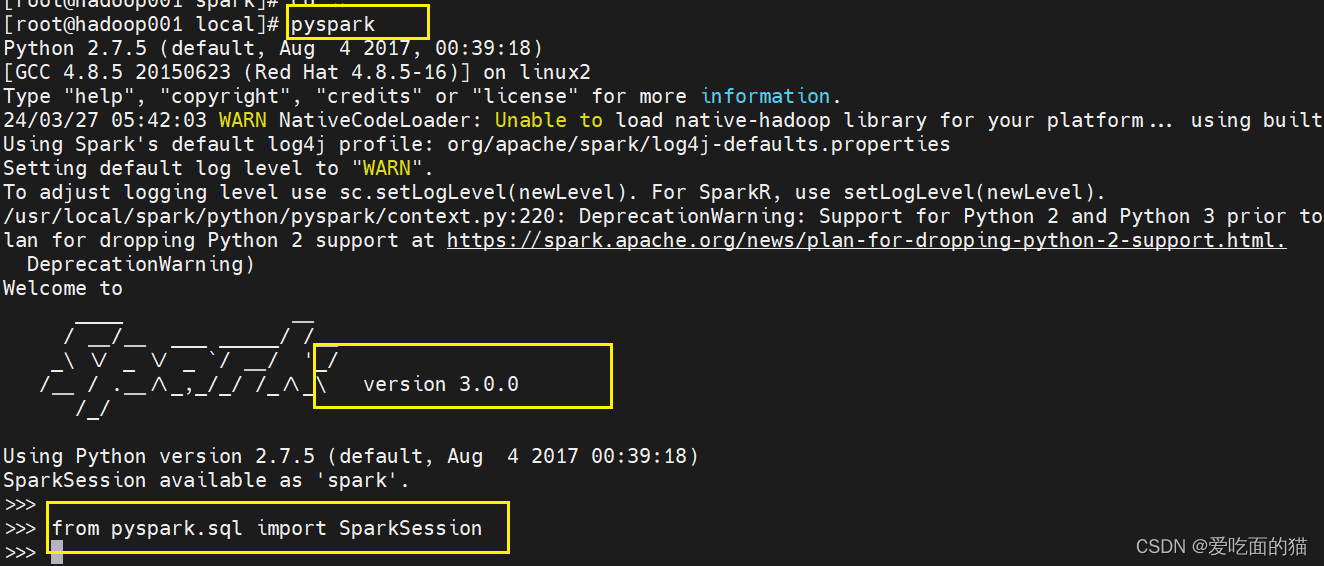
6、执行pyspark测试
输入pyspark启动后查看版本,同时可以输入 **from pyspark.sql import SparkSession **不报错则安装成功。
注意:如果输入pyspark启动后需要安装python,则需要进行安装python,见https://blog.csdn.net/qq_41946216/article/details/137068755?spm=1001.2014.3001.5501
修改文件spark-env.sh、works
cp spark-env.sh.template spark-env.sh
cp workers.template workers
vi spark-env.sh
export JAVA_HOME=/usr/local/java
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.241.101
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
版权归原作者 爱吃面的猫 所有, 如有侵权,请联系我们删除。