
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rgba(51, 51, 51, 1) }
.markdown-body h1, .markdown-body h2, .markdown-body h3, .markdown-body h4, .markdown-body h5, .markdown-body h6 { line-height: 1.5; margin-top: 35px; margin-bottom: 10px; padding-bottom: 5px }
.markdown-body h1 { font-size: 24px; margin-bottom: 5px }
.markdown-body h2, .markdown-body h3, .markdown-body h4, .markdown-body h5, .markdown-body h6 { font-size: 20px }
.markdown-body h2 { padding-bottom: 12px; border-bottom: 1px solid rgba(236, 236, 236, 1) }
.markdown-body h3 { font-size: 18px; padding-bottom: 0 }
.markdown-body h6 { margin-top: 5px }
.markdown-body p { line-height: inherit; margin-top: 22px; margin-bottom: 22px }
.markdown-body img { max-width: 100% }
.markdown-body hr { border-top: 1px solid rgba(221, 221, 221, 1); border-right: none; border-bottom: none; border-left: none; margin-top: 32px; margin-bottom: 32px }
.markdown-body code { border-radius: 2px; overflow-x: auto; background-color: rgba(255, 245, 245, 1); color: rgba(255, 80, 44, 1); font-size: 0.87em; padding: 0.065em 0.4em }
.markdown-body code, .markdown-body pre { font-family: Menlo, Monaco, Consolas, Courier New, monospace }
.markdown-body pre { overflow: auto; position: relative; line-height: 1.75 }
.markdown-body pre>code { font-size: 12px; padding: 15px 12px; margin: 0; word-break: normal; display: block; overflow-x: auto; color: rgba(51, 51, 51, 1); background: rgba(248, 248, 248, 1) }
.markdown-body a { text-decoration: none; color: rgba(2, 105, 200, 1); border-bottom: 1px solid rgba(209, 233, 255, 1) }
.markdown-body a:active, .markdown-body a:hover { color: rgba(39, 91, 140, 1) }
.markdown-body table { display: inline-block !important; font-size: 12px; width: auto; max-width: 100%; overflow: auto; border: 1px solid rgba(246, 246, 246, 1) }
.markdown-body thead { background: rgba(246, 246, 246, 1); color: rgba(0, 0, 0, 1); text-align: left }
.markdown-body tr:nth-child(2n) { background-color: rgba(252, 252, 252, 1) }
.markdown-body td, .markdown-body th { padding: 12px 7px; line-height: 24px }
.markdown-body td { min-width: 120px }
.markdown-body blockquote { color: rgba(102, 102, 102, 1); padding: 1px 23px; margin: 22px 0; border-left: 4px solid rgba(203, 203, 203, 1); background-color: rgba(248, 248, 248, 1) }
.markdown-body blockquote:after { display: block; content: "" }
.markdown-body blockquote>p { margin: 10px 0 }
.markdown-body ol, .markdown-body ul { padding-left: 28px }
.markdown-body ol li, .markdown-body ul li { margin-bottom: 0 }
.markdown-body ol li .task-list-item, .markdown-body ul li .task-list-item { list-style: none }
.markdown-body ol li .task-list-item ol, .markdown-body ol li .task-list-item ul, .markdown-body ul li .task-list-item ol, .markdown-body ul li .task-list-item ul { margin-top: 0 }
.markdown-body ol ol, .markdown-body ol ul, .markdown-body ul ol, .markdown-body ul ul { margin-top: 3px }
.markdown-body ol li { padding-left: 6px }
.markdown-body .contains-task-list { padding-left: 0 }
.markdown-body .task-list-item { list-style: none }
@media (max-width: 720px) { .markdown-body h1 { font-size: 24px } .markdown-body h2 { font-size: 20px } .markdown-body h3 { font-size: 18px } }
有位朋友,某天突然问磊哥:在 Java 中,防止重复提交最简单的方案是什么?
这句话中包含了两个关键信息,第一:防止重复提交;第二:最简单。
于是磊哥问他,是单机环境还是分布式环境?
得到的反馈是单机环境,那就简单了,于是磊哥就开始装*了。
话不多说,我们先来复现这个问题。
模拟用户场景
根据朋友的反馈,大致的场景是这样的,如下图所示: 简化的模拟代码如下(基于 Spring Boot):
简化的模拟代码如下(基于 Spring Boot):
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RequestMapping("/user")@RestControllerpublicclassUserController {
/**
* 被重复请求的方法
*/@RequestMapping("/add")public String addUser(String id) {
// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
于是磊哥就想到:通过前、后端分别拦截的方式来解决数据重复提交的问题。
前端拦截
前端拦截是指通过 HTML 页面来拦截重复请求,比如在用户点击完“提交”按钮后,我们可以把按钮设置为不可用或者隐藏状态。
执行效果如下图所示:
前端拦截的实现代码:
<html><script>functionsubCli(){
// 按钮设置为不可用document.getElementById("btn_sub").disabled="disabled";
document.getElementById("dv1").innerText = "按钮被点击了~";
}
</script><bodystyle="margin-top: 100px;margin-left: 100px;"><inputid="btn_sub"type="button"value=" 提 交 "onclick="subCli()"><divid="dv1"style="margin-top: 80px;"></div></body></html>复制代码
但前端拦截有一个致命的问题,如果是懂行的程序员或非法用户可以直接绕过前端页面,通过模拟请求来重复提交请求,比如充值了 100 元,重复提交了 10 次变成了 1000 元(瞬间发现了一个致富的好办法)。
所以除了前端拦截一部分正常的误操作之外,后端的拦截也是必不可少。
后端拦截
后端拦截的实现思路是在方法执行之前,先判断此业务是否已经执行过,如果执行过则不再执行,否则就正常执行。
我们将请求的业务 ID 存储在内存中,并且通过添加互斥锁来保证多线程下的程序执行安全,大体实现思路如下图所示: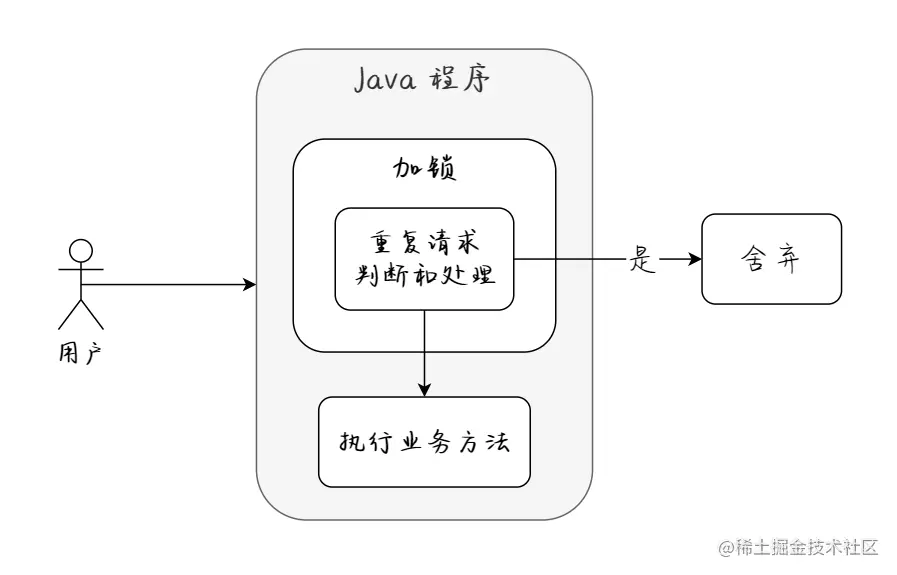
然而,将数据存储在内存中,最简单的方法就是使用
HashMap
存储,或者是使用 Guava Cache 也是同样的效果,但很显然
HashMap
可以更快的实现功能,所以我们先来实现一个
HashMap
的防重(防止重复)版本。
1.基础版——HashMap
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
/**
* 普通 Map 版本
*/@RequestMapping("/user")@RestControllerpublicclassUserController3 {
// 缓存 ID 集合private Map<String, Integer> reqCache = new HashMap<>();
@RequestMapping("/add")public String addUser(String id) {
// 非空判断(忽略)...
synchronized (this.getClass()) {
// 重复请求判断if (reqCache.containsKey(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
return"执行失败";
}
// 存储请求 ID
reqCache.put(id, 1);
}
// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
实现效果如下图所示:
存在的问题:此实现方式有一个致命的问题,因为
HashMap
是无限增长的,因此它会占用越来越多的内存,并且随着
HashMap
数量的增加查找的速度也会降低,所以我们需要实现一个可以自动“清除”过期数据的实现方案。
2.优化版——固定大小的数组
此版本解决了
HashMap
无限增长的问题,它使用数组加下标计数器(reqCacheCounter)的方式,实现了固定数组的循环存储。
当数组存储到最后一位时,将数组的存储下标设置 0,再从头开始存储数据,实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
@RequestMapping("/user")@RestControllerpublicclassUserController {
private static String[] reqCache = new String[100]; // 请求 ID 存储集合private static Integer reqCacheCounter = 0; // 请求计数器(指示 ID 存储的位置)@RequestMapping("/add")public String addUser(String id) {
// 非空判断(忽略)...
synchronized (this.getClass()) {
// 重复请求判断if (Arrays.asList(reqCache).contains(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
return"执行失败";
}
// 记录请求 IDif (reqCacheCounter >= reqCache.length) reqCacheCounter = 0; // 重置计数器
reqCache[reqCacheCounter] = id; // 将 ID 保存到缓存
reqCacheCounter++; // 下标往后移一位
}
// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
3.扩展版——双重检测锁(DCL)
上一种实现方法将判断和添加业务,都放入
synchronized
中进行加锁操作,这样显然性能不是很高,于是我们可以使用单例中著名的 DCL(Double Checked Locking,双重检测锁)来优化代码的执行效率,实现代码如下:
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
@RequestMapping("/user")@RestControllerpublicclassUserController {
private static String[] reqCache = new String[100]; // 请求 ID 存储集合private static Integer reqCacheCounter = 0; // 请求计数器(指示 ID 存储的位置)@RequestMapping("/add")public String addUser(String id) {
// 非空判断(忽略)...// 重复请求判断if (Arrays.asList(reqCache).contains(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
return"执行失败";
}
synchronized (this.getClass()) {
// 双重检查锁(DCL,double checked locking)提高程序的执行效率if (Arrays.asList(reqCache).contains(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
return"执行失败";
}
// 记录请求 IDif (reqCacheCounter >= reqCache.length) reqCacheCounter = 0; // 重置计数器
reqCache[reqCacheCounter] = id; // 将 ID 保存到缓存
reqCacheCounter++; // 下标往后移一位
}
// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
注意:DCL 适用于重复提交频繁比较高的业务场景,对于相反的业务场景下 DCL 并不适用。
4.完善版——LRUMap
上面的代码基本已经实现了重复数据的拦截,但显然不够简洁和优雅,比如下标计数器的声明和业务处理等,但值得庆幸的是 Apache 为我们提供了一个 commons-collections 的框架,里面有一个非常好用的数据结构
LRUMap
可以保存指定数量的固定的数据,并且它会按照 LRU 算法,帮你清除最不常用的数据。
小贴士:LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常用的数据淘汰算法,选择最近最久未使用的数据予以淘汰。
首先,我们先来添加 Apache commons collections 的引用:
<!-- 集合工具类 apache commons collections --><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-collections4 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-collections4</artifactId><version>4.4</version></dependency>复制代码
实现代码如下:
import org.apache.commons.collections4.map.LRUMap;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RequestMapping("/user")@RestControllerpublicclassUserController {
// 最大容量 100 个,根据 LRU 算法淘汰数据的 Map 集合private LRUMap<String, Integer> reqCache = new LRUMap<>(100);
@RequestMapping("/add")public String addUser(String id) {
// 非空判断(忽略)...
synchronized (this.getClass()) {
// 重复请求判断if (reqCache.containsKey(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
return"执行失败";
}
// 存储请求 ID
reqCache.put(id, 1);
}
// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
使用了
LRUMap
之后,代码显然简洁了很多。
5.最终版——封装
以上都是方法级别的实现方案,然而在实际的业务中,我们可能有很多的方法都需要防重,那么接下来我们就来封装一个公共的方法,以供所有类使用:
import org.apache.commons.collections4.map.LRUMap;
/**
* 幂等性判断
*/publicclassIdempotentUtils {
// 根据 LRU(Least Recently Used,最近最少使用)算法淘汰数据的 Map 集合,最大容量 100 个privatestatic LRUMap<String, Integer> reqCache = new LRUMap<>(100);
/**
* 幂等性判断
* @return
*/publicstaticbooleanjudge(String id, Object lockClass){
synchronized (lockClass) {
// 重复请求判断if (reqCache.containsKey(id)) {
// 重复请求
System.out.println("请勿重复提交!!!" + id);
returnfalse;
}
// 非重复请求,存储请求 ID
reqCache.put(id, 1);
}
returntrue;
}
}
复制代码
调用代码如下:
import com.example.idempote.util.IdempotentUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RequestMapping("/user")@RestControllerpublicclassUserController4 {
@RequestMapping("/add")public String addUser(String id) {
// 非空判断(忽略)...// -------------- 幂等性调用(开始) --------------if (!IdempotentUtils.judge(id, this.getClass())) {
return"执行失败";
}
// -------------- 幂等性调用(结束) --------------// 业务代码...
System.out.println("添加用户ID:" + id);
return"执行成功!";
}
}
复制代码
小贴士:一般情况下代码写到这里就结束了,但想要更简洁也是可以实现的,你可以通过自定义注解,将业务代码写到注解中,需要调用的方法只需要写一行注解就可以防止数据重复提交了,老铁们可以自行尝试一下(需要磊哥撸一篇的,评论区留言 666)。
扩展知识——LRUMap 实现原理分析
既然
LRUMap
如此强大,我们就来看看它是如何实现的。
LRUMap
的本质是持有头结点的环回双链表结构,它的存储结构如下:
AbstractLinkedMap.LinkEntry entry;复制代码
当调用查询方法时,会将使用的元素放在双链表 header 的前一个位置,源码如下:
public V get(Object key, boolean updateToMRU) {
LinkEntry<K, V> entry = this.getEntry(key);
if (entry == null) {
returnnull;
} else {
if (updateToMRU) {
this.moveToMRU(entry);
}
return entry.getValue();
}
}
protected void moveToMRU(LinkEntry<K, V> entry) {
if (entry.after != this.header) {
++this.modCount;
if (entry.before == null) {
throw new IllegalStateException("Entry.before is null. This should not occur if your keys are immutable, and you have used synchronization properly.");
}
entry.before.after = entry.after;
entry.after.before = entry.before;
entry.after = this.header;
entry.before = this.header.before;
this.header.before.after = entry;
this.header.before = entry;
} elseif (entry == this.header) {
throw new IllegalStateException("Can't move header to MRU This should not occur if your keys are immutable, and you have used synchronization properly.");
}
}
复制代码
如果新增元素时,容量满了就会移除 header 的后一个元素,添加源码如下:
protected void addMapping(int hashIndex, int hashCode, K key, V value) {
// 判断容器是否已满 if (this.isFull()) {
LinkEntry<K, V> reuse = this.header.after;
boolean removeLRUEntry = false;
if (!this.scanUntilRemovable) {
removeLRUEntry = this.removeLRU(reuse);
} else {
while(reuse != this.header && reuse != null) {
if (this.removeLRU(reuse)) {
removeLRUEntry = true;
break;
}
reuse = reuse.after;
}
if (reuse == null) {
throw new IllegalStateException("Entry.after=null, header.after=" + this.header.after + " header.before=" + this.header.before + " key=" + key + " value=" + value + " size=" + this.size + " maxSize=" + this.maxSize + " This should not occur if your keys are immutable, and you have used synchronization properly.");
}
}
if (removeLRUEntry) {
if (reuse == null) {
throw new IllegalStateException("reuse=null, header.after=" + this.header.after + " header.before=" + this.header.before + " key=" + key + " value=" + value + " size=" + this.size + " maxSize=" + this.maxSize + " This should not occur if your keys are immutable, and you have used synchronization properly.");
}
this.reuseMapping(reuse, hashIndex, hashCode, key, value);
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
}
复制代码
判断容量的源码:
publicbooleanisFull(){
return size >= maxSize;
}
复制代码
** 容量未满就直接添加数据:
super.addMapping(hashIndex, hashCode, key, value);
复制代码
如果容量满了,就调用
reuseMapping
方法使用 LRU 算法对数据进行清除。
综合来说:**
LRUMap
的本质是持有头结点的环回双链表结构,当使用元素时,就将该元素放在双链表
header
的前一个位置,在新增元素时,如果容量满了就会移除
header
的后一个元素**。
总结
本文讲了防止数据重复提交的 6 种方法,首先是前端的拦截,通过隐藏和设置按钮的不可用来屏蔽正常操作下的重复提交。但为了避免非正常渠道的重复提交,我们又实现了 5 个版本的后端拦截:HashMap 版、固定数组版、双重检测锁的数组版、LRUMap 版和 LRUMap 的封装版。
特殊说明:本文所有的内容仅适用于单机环境下的重复数据拦截,如果是分布式环境需要配合数据库或 Redis 来实现,想看分布式重复数据拦截的老铁们,请给磊哥一个「赞」,如果点赞超过 100 个,咱们更新分布式环境下重复数据的处理方案,谢谢你。
参考 & 鸣谢
blog.csdn.net/fenglllle/a…
关注公众号「Java中文社群」订阅更多精彩。

版权归原作者 程序员小明1024 所有, 如有侵权,请联系我们删除。