
本来想着做一个将图片识别为文字的小功能,本想到Google上面第一页全是各种收费平台的广告。
这些平台提供的基本都是让我们通过调用相关的三方接口实现的,本着坚决不想花一分钱的态度,在论坛找有没有可以免费解决的方案。
果然,有大佬早就做出开源框架pytesseract,差点让我损失了一笔巨款,哈哈~
这次只为实现将图片识别为文字的业务功能,就不使用PyQt5做页面应用了。后面若是需要做成UI应用朋友比较多,我有时间会将这个小工具封装开发成一个PyQ5界面应用的小工具。 喜欢本文记得收藏、关注、点赞。
注:完整版代码、技术交流,文末获取。
1、环境准备
还是老规矩吧,像一些比较有歧义的环境准备工作,我都会将我使用到的python库的版本列出来,防止小伙伴们走一些弯路。
操作系统:windows7
python版本:3.8.10
pytesseract版本:0.3.9
首先需要安装两个三方模块,一个是PIL图片处理库,另一个是pytesseract识别文字用到的python库。
pip install PIL -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装好这两个python非标准库以后,还有一个比较重要的操作就是需要额外的安装一个工具Tesseract-OCR,这个工具实际上是我们用来识别图片必须的一个工具。
为了防止丢失,我将Tesseract-OCR工具的安装包和其需要的中文语言包放在了百度网盘中,在公众号内回复’Tesseract-OCR’工具可以获取网盘下载链接感兴趣的小伙伴直接去下载就好了。

下载完成以后直接进行解压即可,解压完成后的文件目录是下面这样的。

解压完成后直接安装Tesseract-OCR工具,双击打开就可以进行安装了,傻瓜式安装即可。

下面这个是我在给大家测试的时候截图的一张安装过程中的图。
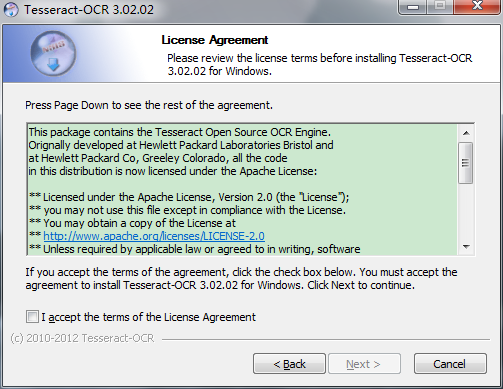
安装完成后,我们需要将上面下载的中文包加入到安装好的Tesseract-OCR工具主目录下面的\tessdata文件夹中。
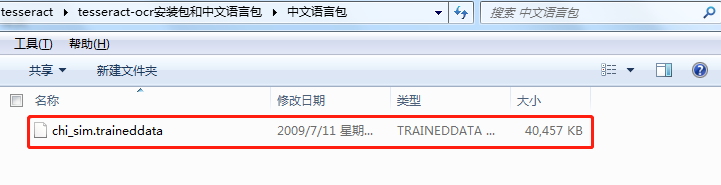
下面是我已经将中文语言包放入到…/Tesseract-OCR/tessdata文件中了。
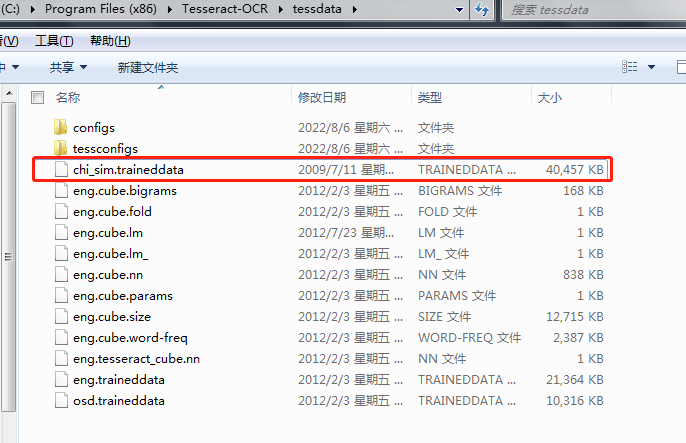
中文语言包放好后,就可以直接进入下一步的操作了,那就是修改环境相关的配置,实际上只要需要一个相关的参数就OK了。
找到本地的python环境的安装位置,找到我们前面安装好的pytesseract的位置去修改参数一个叫做tesseract_cmd变量的值,具体操作是这样的。
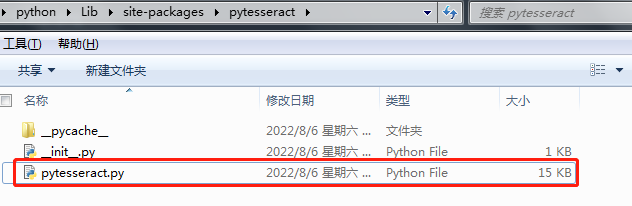
上面是我的pytesseract库的安装位置,找到之后打开pytesseract.py文件将tesseract_cmd变量的值替换为我们安装的Tesseract-OCR工具的tesseract.exe应用程序的路径。
默认Tesseract-OCR工具的安装位置是下面这样这个路径,小伙伴们可以根据自己的位置设置。
C:/Program Files (x86)/Tesseract-OCR/tesseract.exe
这是我已经修改好的pytesseract.py文件中tesseract_cmd变量的值。
tesseract_cmd ='C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
至此,准备工作终于做完了,接下来就是我们大显身手的时间了,来轻松实现一个图片到文字的转换吧!
2、业务实现
代码实现过程相当简单,比较上面的安装配置过程简直就是小菜一碟了,导入相关的python模块中实际上只需要一行代码就可以实现将图片内容识别为文字了。
# 导入python非标准模块from PIL import Image
import pytesseract as pyt
# 读取图片中的文字内容
text = pyt.image_to_string(Image.open('chinese-image.jpg'), lang='chi_sim')# 打印文字内容print(text)
3、效果展示
为了测试一下效果,我用本地的画图软件画了一张图。
技术交流
有问题、技术交流、代码获取,如下方式获取。
版权归原作者 我爱Python数据挖掘 所有, 如有侵权,请联系我们删除。