
1.服务配置中心
1.1 服务配置中心介绍
首先我们来看一下,微服务架构下关于配置文件的一些问题:
1.配置文件相对分散。在一个微服务架构下,配置文件会随着微服务的增多变的越来越多,而且分散在各个微服务中,不好统─配置和管理。
⒉.配置文件无法区分环境。微服务项目可能会有多个环境,例如︰测试环境、预发布环境、生产环境。每一个环境所使用的配置理论上都是不同的,一旦需要修改,就需要我们去各个微服务下手动维护,这比较困难。
3.配置文件无法实时更新。我们修改了配置文件之后,必须重新启动微服务才能使配置生效,这对一个正在运行的项目来说是非常不友好的。
基于上面这些问题,我们就需要配置中心的加入来解决这些问题。
配置中心的思路是:
1.首先把项目中各种配置全部都放到一个集中的地方进行统—管理,并提供—套标准的接口。
2.当各个服务需要获取配置的时候,就来配置中心的接口拉取自己的配置。
3..当配置中心中的各种参数有更新的时候,也能通知到各个服务实时的过来同步最新的信息,使之动态更新
当加入了服务配置中心之后,我们的系统架构图会变成下面这样: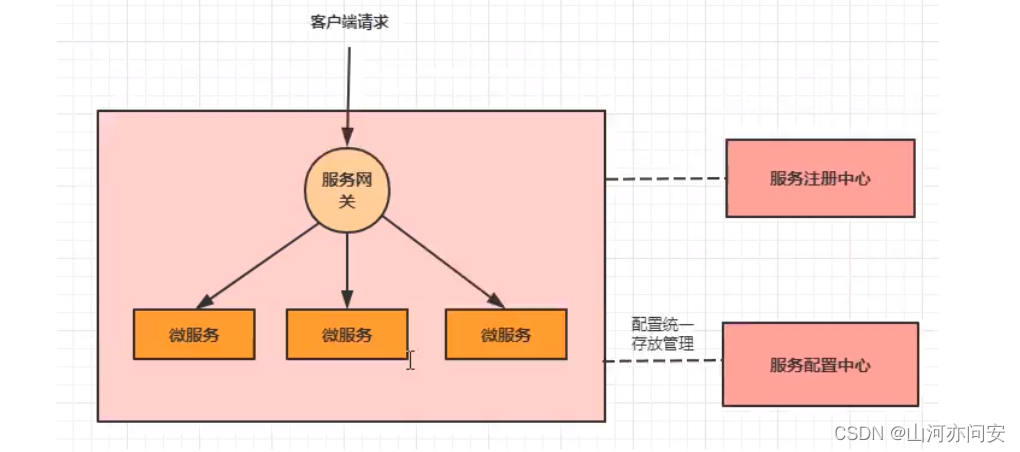
1.2 Nacos Config 实践
使用nacos作为配置中心,其实就是将nacos当做一个服务端,将各个微服务看成是客户端,我们将各个微服务的配置文件统一存放在nacos上,然后各个微服务从nacos上拉取配置即可。
1.2.1 Nacos config 入门案例
导入依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
在微服务中添加nacos config的配置,不能使用原来的application.yml作为配置文件,而是新建一个bootstrap.yml作为配置文件。
配置文件优先级从高到低为:
bootstrap.properties>bootstrap.yml>application.properties>application.yml
这里举例为订单微服务,首先新建个bootstrap.yml文件,然后配置如下:
spring:
application:
name: provider
profiles:
active: dev #环境标识
cloud:
nacos:
server-addr: localhost:8848
config:
file-extension: yaml #配置文件格式
discovery:
cluster-name: BJ
sentinel:
transport:
dashboard: localhost:8080
然后在nacos配置文件中配置Data ID为bootstrap中配置订单微服务名+环境标识+配置文件格式。如下图;
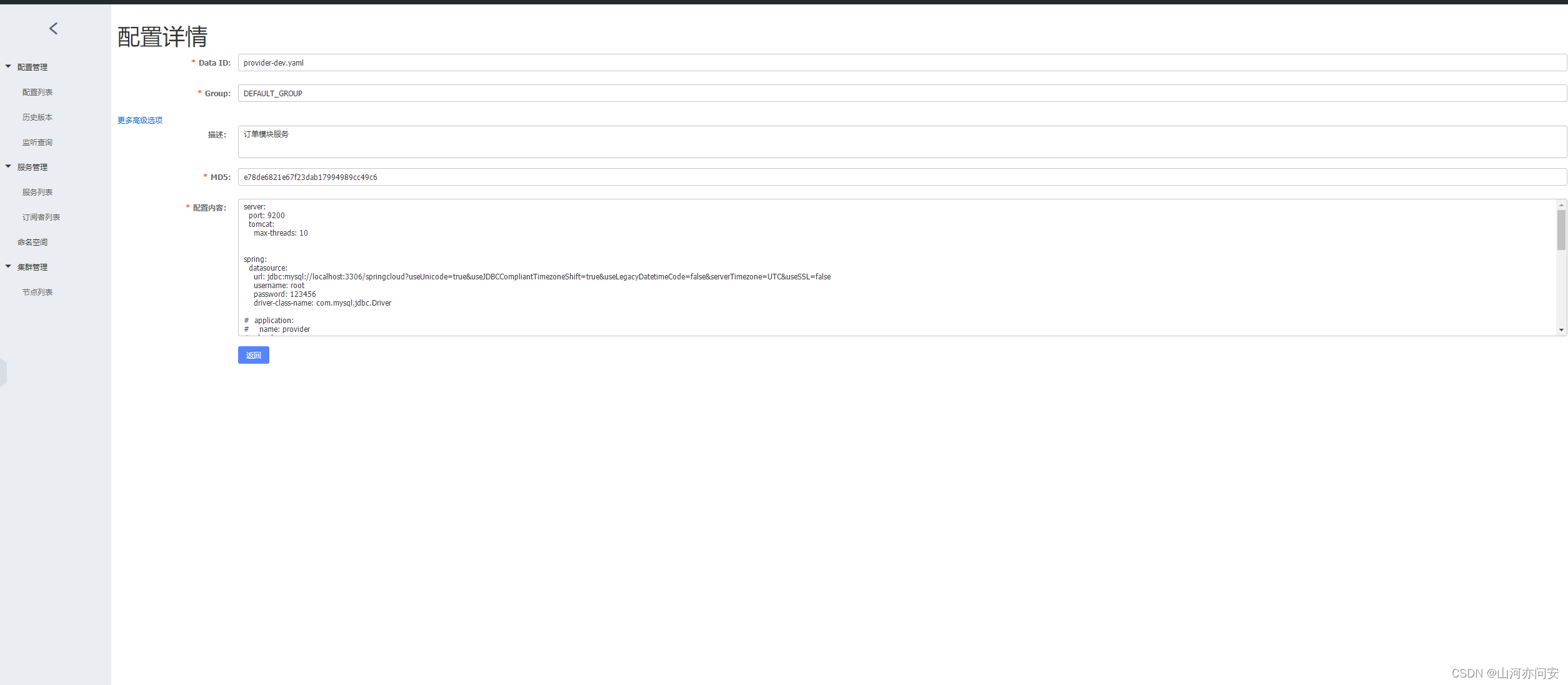
1.2.2 Nacos 配置动态刷新
实现在配置中心修改配置文件内容后,程序内部引用可以自动刷新,我们可以在自己创建的DataId配置文件中,更改项:
config:
appName: product
硬编码方式
@GetMapping("/test")
public String test(){
String property = configurableApplicationContext.getEnvironment().getProperty("config.appName");
return property;
}
注解方式
@RestController
@RefreshScope /* 只需要在需要动态读取配置的类上添加此注解就可以 */
public class UserController {
@Value("${config.appName}")
private String appName;
@GetMapping("/test")
public String test(){
return appName;
}
}
1.2.3 配置共享
当配置越来越多的时候,我们就发现有很多配置是重复的,这时候就考虑可不可以将公共配置文件提取出来,然后实现共享。共享存在两种场景:同一微服务,不同场景(namespace)下共享;不同微服务之间共享。
同一微服务,不同场景下共享配置
比如上面的订单微服务,开发环境的配置文件为provider-dev.yaml,测试环境的配置文件为provider-test.yaml,同一微服务在不同场景下共享可以配置provider.yaml文件。
** 不同微服务之间共享共享配置**
在nacos中新建all-service.yml文件作为共享配置,然后引入配置代码如下:
spring:
application:
name: provider
profiles:
active: dev
cloud:
nacos:
server-addr: localhost:8848
config:
file-extension: yaml
shared-dataids: allservice.yaml #配置要引入的配置
refreshable-dataids: allservice.yaml #配置要实现动态配置刷新的配置
discovery:
cluster-name: BJ
sentinel:
transport:
dashboard: localhost:8080
1.2.4 nacos 几个概念
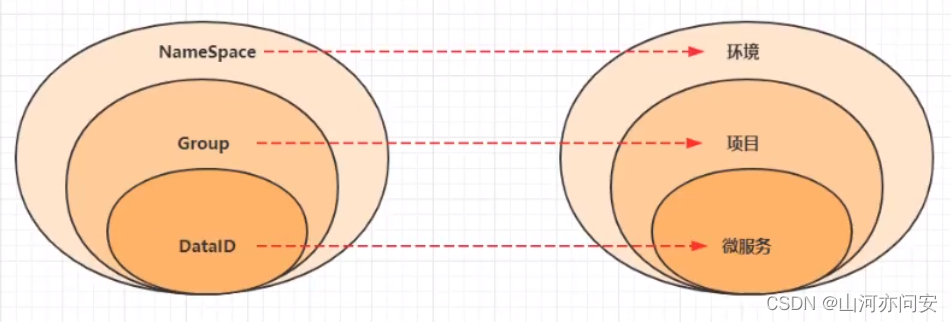
命名空间(Namespace)
命名空间可用于进行不同环境的配置隔离。一般一个环境划分到一个命名空间
配置分组(Group)
配置分组用于将不同的服务可以归类到同一分组。一般将一个项目的配置分到一组
配置集(Data ID)
在系统中,一个配置文件通常就是一个配置集。一般微服务的配置就是一个配置集
2.分布式锁
2.1 分布式锁介绍
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
在单体的应用开发场景中,在多线程的环境下,涉及并发同步的时候,为了保证一个代码块在同一时间只能由一个线程访问,我们一般可以使用synchronized语法和ReetrantLock去保证,这实际上是本地锁的方式。也就是说,在同一个JVM内部,大家往往采用synchronized或者Lock的方式来解决多线程间的安全问题。但在分布式集群工作的开发场景中,在JVM之间,那么就需要一种更加高级的锁机制,来处理种跨JVM进程之间的线程安全问题.
总之,对于分布式场景,我们可以使用分布式锁,它是控制分布式系统之间互斥访问共享资源的一种方式。比如说在一个分布式系统中,多台机器上部署了多个服务,当客户端一个用户发起一个数据插入请求时,如果没有分布式锁机制保证,那么那多台机器上的多个服务可能进行并发插入操作,导致数据重复插入,对于某些不允许有多余数据的业务来说,这就会造成问题。而分布式锁机制就是为了解决类似这类问题,保证多个服务之间互斥的访问共享资源,如果一个服务抢占了分布式锁,其他服务没获取到锁,就不进行后续操作。如下图:
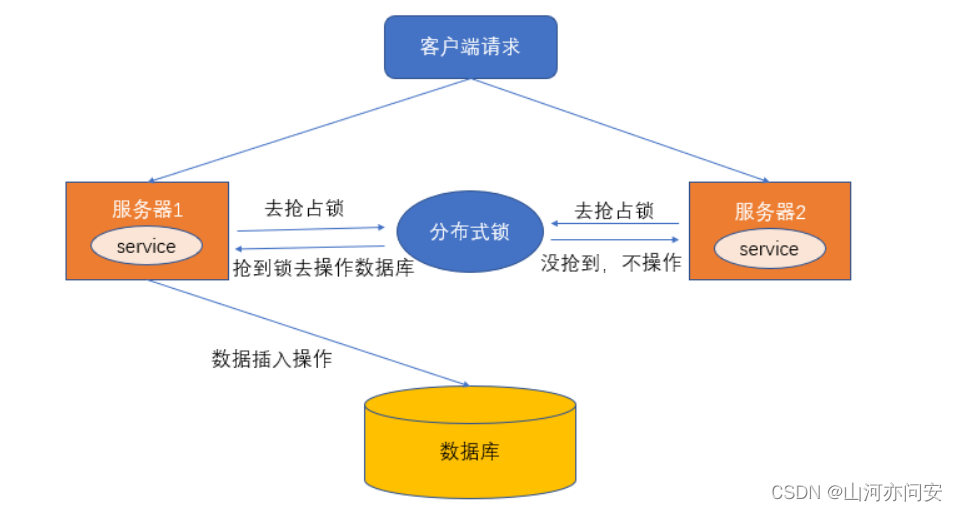
分布式锁要具有一下特征:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的 Redis 节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
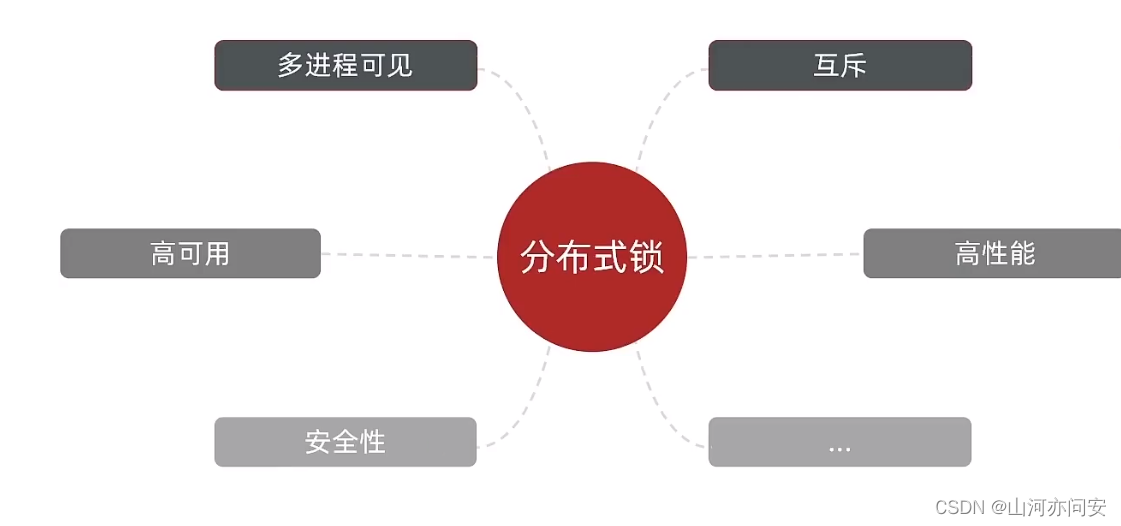
分布式锁的核心是实现多进程之间互斥,而满足这一点的方式有很多,常见的有三种:
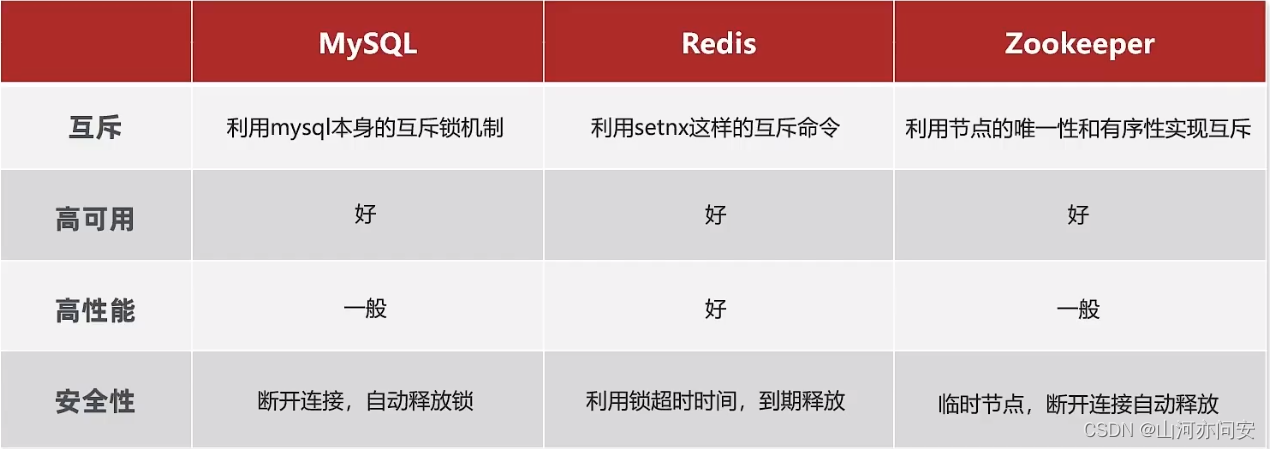
2.2 Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
假如我们在微服务架构中,有个订单秒杀服务,要求同一个优惠券,一个用户只能下一单。在单机架构中,我们使用synchronized或者Lock的方式就可以解决这个问题,将查询数据库是否下过单和下单扣减库存过程锁在一块,只允许获得锁的一个线程进行访问。如果不加锁,假如高并发场景下,一百个线程同时访问并且都是同一个用户,然后就会出现多个线程先进行查询操作,如果数据库中没有该订单信息,然后这多个线程就会都符合要求进行下单扣减库存产生多个订单,就会违背一个用户只能下一单的情况。而在分布式中,因为多个服务都是以集群形式的存在存在多个jvm实例,synchronized或者Lock的方式只是针对的同一个JVM内部,这就需要分布式锁。这里使用Redission进行模拟,模拟在微服务集群高并发场景下多个用户线程下下单同一订单扣减库存情况。
2.2.1 Redisson 实践
导入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.19.0</version>
</dependency>
代码如下:
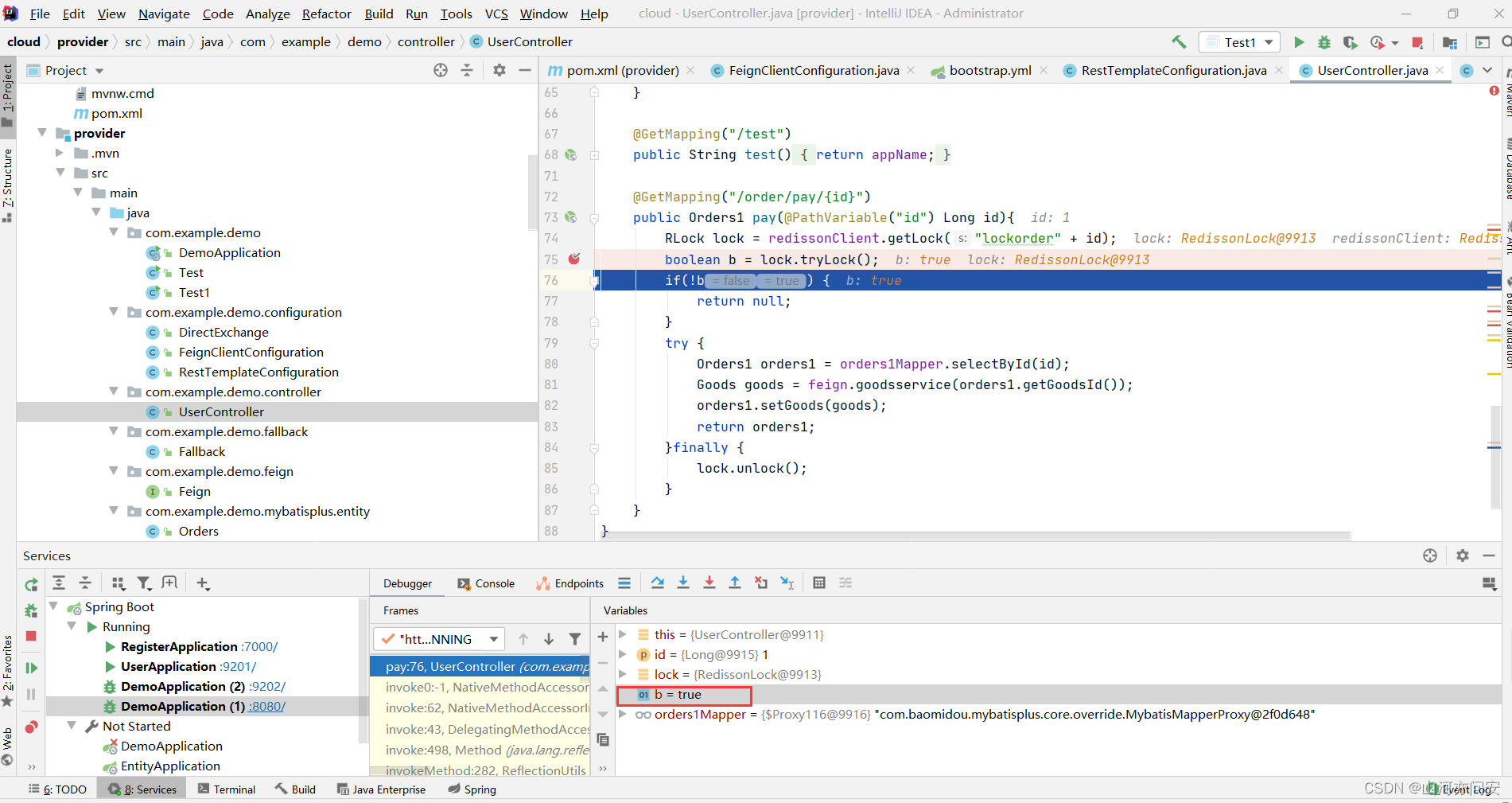
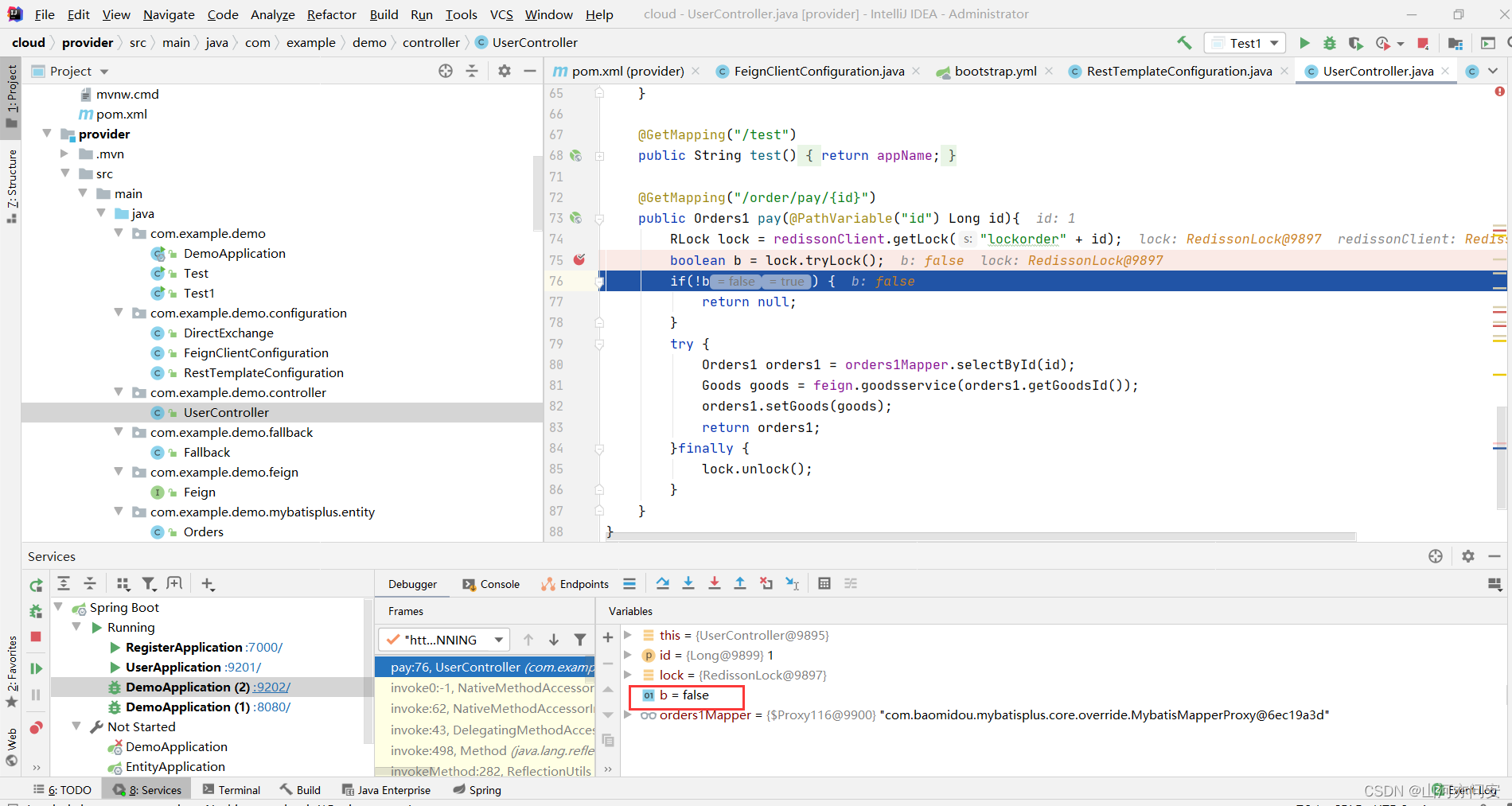
本代码模拟根据订单id查询到订单信息,然后根据订单信息中的goodsId传递到商品微服务,进行对应商品的库存减一,然后返回修改后的商品信息 存储到订单信息对应商品Goods属性上。加分布式锁是保证在同一集群中不同微服务进程中的这个方法只能由获得锁的线程进行处理业务,由于是代码模拟,所以在设计代码的时候相对随意。
@GetMapping("/order/pay/{id}")
public Orders1 pay(@PathVariable("id") Long id){
RLock lock = redissonClient.getLock("lockorder" + id);
boolean b = lock.tryLock();
if(!b) {
return null;
}
try {
Orders1 orders1 = orders1Mapper.selectById(id);
Goods goods = feign.goodsservice(orders1.getGoodsId());
orders1.setGoods(goods);
return orders1;
}finally {
lock.unlock();
}
}
debug验证结果如下:
下面订单微服务集群为8080端口和9202端口,先访问8080端口,再访问9202端口,在debug环境下验证了我们的猜想。
2.2.2 Redisson 原理
此章节引用网上相关描述
Redisson 这个框架对Redis分布式锁的实现原理图如下:
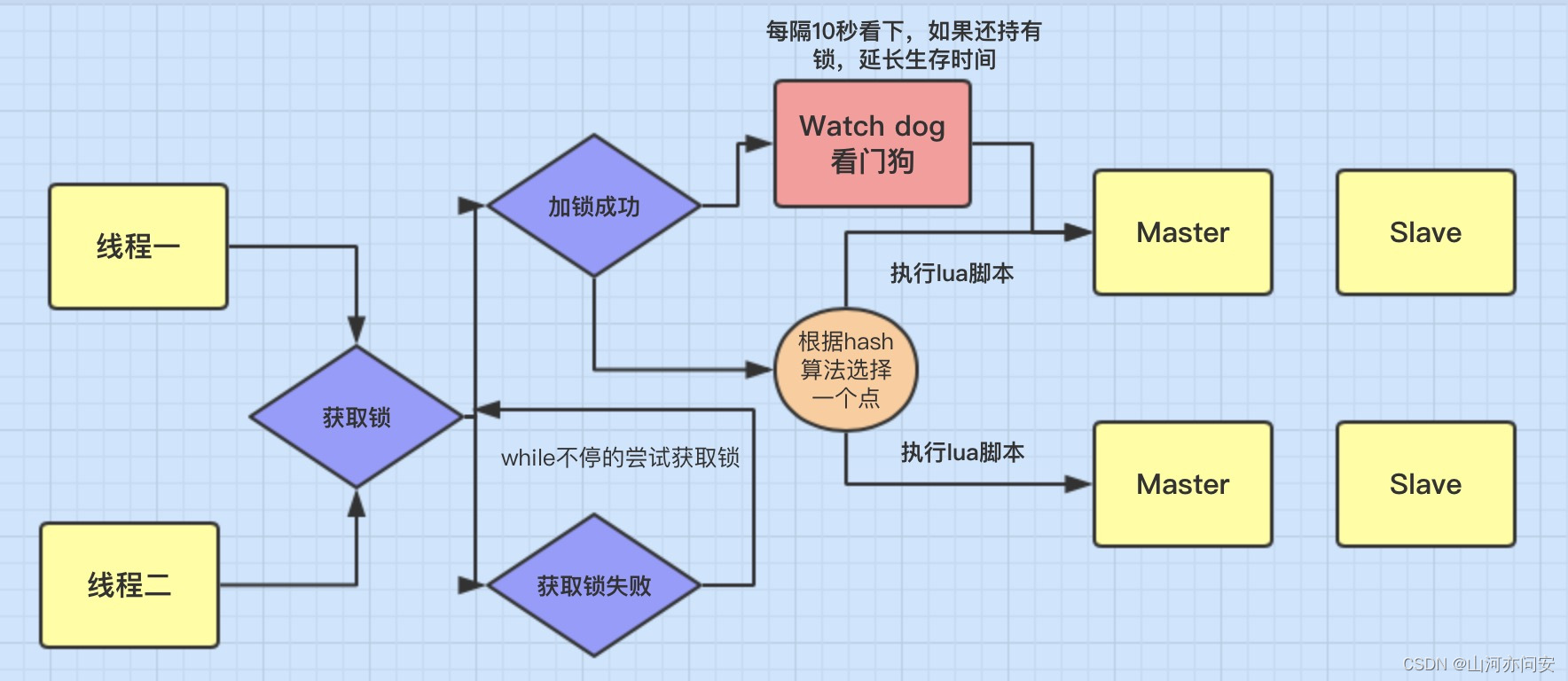
** 1.获取锁**
一个Redission客户端1要加锁,它首先会根据hash节点选择一台机器,紧接着就会发送一段lua脚本到redis上,比如加锁的那个锁key就是”mylock”,并且设置的时间是30秒,30秒后mylock锁就会被释放。
2.锁互斥机制
如果这个时候Redission客户端2来加锁,它也会会根据hash节点选择一台机器,然后执行了同样的一段lua脚本。
它首先回来判断《mylock》这个锁存在吗?如果存在则Redission客户端2会获得一个数字,这个数字就是mylock这个锁的剩余生存时间。
此时Redission客户端2就会进入到一个while循环,就是CAS不停的自旋尝试加锁,知道成功为止。
3.看门狗机制
如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。
为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。线程A拿到锁需要处理2秒,但是锁的超时时间只有1秒,也就是说锁超时的时候,业务还没处理完。这时候线程B就进来了又拿到锁,导致加锁跟解锁的时候并不是同一线程。看门狗的作用就是当遇到这种情况的时候,看门狗会定时去查看一下这个线程A是否还在执行任务,如果还在执行则给他继续延长时间。
4.可重入加锁机制
我们知道ReentrantLock是可重入锁,它的特点就是:同一个线程可以重复拿到同一个资源的锁,Redisson也能很好的满足这点。
Redisson客户端1获得mylock锁时,里面会有一个hash结构的数据,如下图所示:

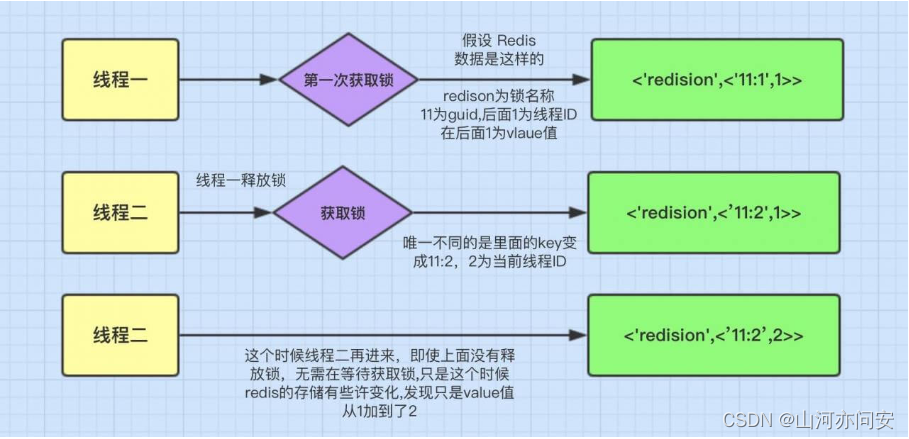
上面这图的意思就是可重入锁的机制,它最大的优点就是相同线程不需要在等待锁,而是可以直接进行相应操作。
5.释放锁机制
如果发现加锁次数变为0了,那么说明这个Redisson客户端1不再持有锁了,Redisson客户端2就可以加锁了。
版权归原作者 山河亦问安 所有, 如有侵权,请联系我们删除。