
一、简介
消息队列在现代软件架构中已经成为不可或缺的中间件,如果你曾经搭建过系统服务需要用到消息中间件,一定会思考到底怎么选择呢?消息队列的主要功能如下:解耦、异步、扩展性、流量削峰、顺序保障、缓存等。
出于某种原因,在大多数场景中 Kafka 和 RabbitMQ 是可以互换的,很多程序员可能都这么认为,这篇文章就带你从不同的维度让二者进行一下 PK,看看到底怎么选择。
二、消息中间件选型
目前消息中间件比较多,比如 Kafka、RabbitMQ、ActiveMQ、RocketMQ、Pulsar 等,今天以 Kafka 和 RabbitMQ 为例来教你如何进行技术选型。
分别从以下5个纬度进行分析,功能纬度、性能纬度、可靠性和可用性纬度、运维管理、社区活跃度。
三、功能维度
衡量一款消息中间件是否符合要求,首先要考虑的就是其功能是否能满足自己的业务要求,这个直接决定了你是否会选择它。
3.1 顺序消费
RabbitMQ 对发送到队列或交换器的消息的顺序性提供了很少的保证。如果想在 RabbitMQ 中保证消息的顺序性也能做到,但是条件很苛刻,要求生产者和消费者都只有一个,这样生产者按顺序发送,消费者因为只有一个只能按顺序消费,这样就能保证消息的顺序,但是在实际中并不会这么干,毕竟现在都是分布式系统,要求系统的扩展性,没人会只有一个消费者,所以这个方案基本上只限于理论。
Kafka 在顺序消费方面给了很好的顺序保障。Kafka 生产者发送消息时指定Key,就能保障发往单分区消息的顺序性,每个消费组中的消费者消费时就能按顺序消费。
**在顺序消费方面 Kafka 完胜 RabbitMQ**,如果你的业务中消息需要按顺序消费,这时就需要使用 Kafka 了。
3.2 优先队列
优先级队列,顾名思义,具有高优先级的队列具有高的优先权,优先级高的消息具备优先被消费的特权。设置优先级队列,RabbitMQ 通过设置队列的属性设置成优先队列,设置如下:
Map<String, Object> args = new HashMap<>();
args.put("x-max-priority", 10);
Queue queue = new Queue(vodQueue, true, false, false, args);
优先队列想正常工作有个前提条件,那就是需要消息有积压,如果没有积压消息,来一条消息就消费一条,那设置优先级也就毫无意义了。
Kafka 自身是不支持优先级的,如果想支持需要很复杂的处理流程,比如设计多个优先级的topic,不同的优先级发送到不同的topic种,然后消费者做相应的处理,但是这种设计扩展性很差,基本不会使用。
**在优先队列级队列方面 RabbitMQ 完胜 Kafka**,如果你的业务需要按优先级处理消息,可以考虑使用 RabbitMQ。
3.2 延迟消费
延迟队列是指当消息被发出后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到消息。在 RabbitMQ 中可以通过设置队列的过期时间和死信队列配合工作的方式来达到延迟消费的目的。
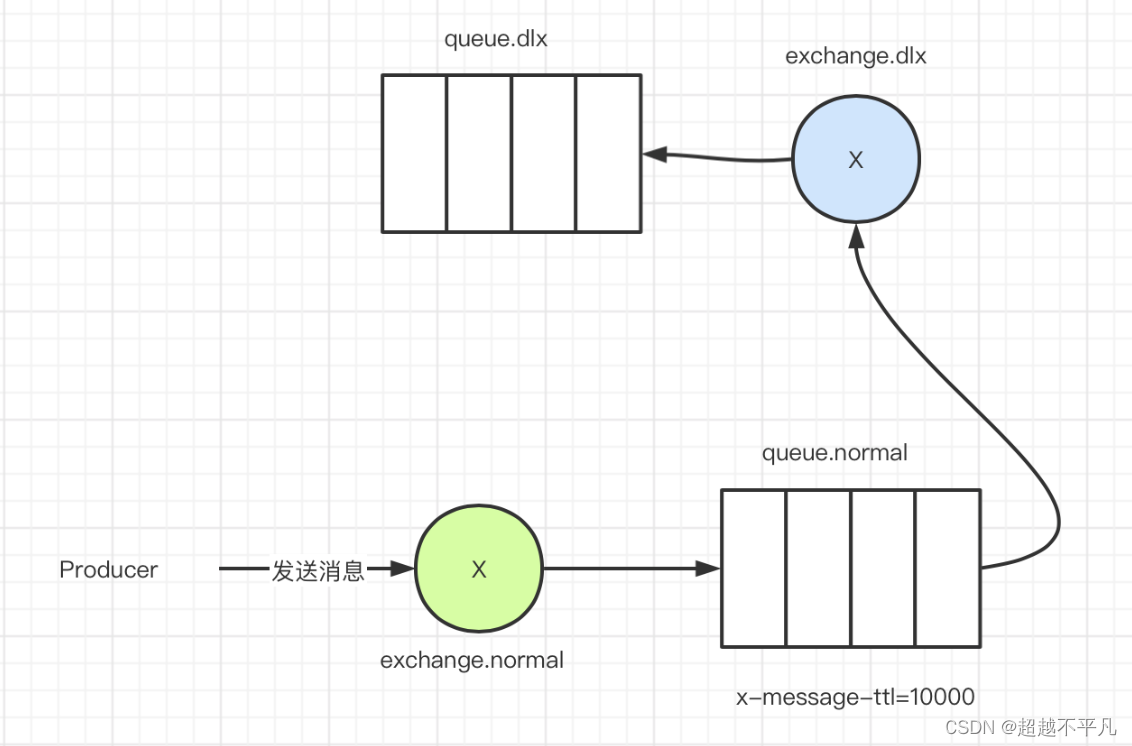
给消息或队列设置过期时间,而这个队列是没有消费者的,所以无法消费,等过期时间达到后消息将被投递到死信队列中,而死信队列是有消费者的,这时可以正常消费消息,通过这种方式来实现延迟消费。
不过有一点需要注意,RabbitMQ 中的队列是先进先出,如果前边的消息设置的过期时间晚,后边的消息过期时间早,也不会跳过去执行的。
而 Kafka 并不支持死信队列、延迟消费等功能。
**在延迟消费、死信队列方面,RabbitMQ 完胜 Kafka**。
3.3 回溯消费
Kafka 和其他消息中间件有一个很大的不同,就是消息可以回溯消费,只要消息还没被删除,那么可以通过指定 offset 来重新消费消息,如果不知道 offset 的话,也可以指定时间,从指定的时间开始来消费消息。这就提供了很大的便利,如果消费者未消费,或者因为某些原因出错了,那么通过这种方式可以找到丢失的消息重复消费。而 RabbitMQ 在这方面就没有响应的功能了。
**在回溯消费方面,Kafka 完胜 RabbitMQ**。
3.4 其他功能
其他消息队列的功能,二者差不多都能支持。比如跨语言、流量控制、消息堆积、事务等功能。
总结:在功能方面要看你的业务需要什么样的功能,有些功能是特有的,那么只能选择某一种消息中间件,这时一个权衡的过程。
四、性能纬度
消息中间件的性能一般指的事吞吐量,从功能上说 RabbitMQ 的功能略多于 Kafka,但是就性能方面,Kafka 的吞吐量要比 RabbitMQ 高出一至两个数量级。Kafka以其高吞吐量著称,能够每秒处理数十万条消息,非常适合大规模数据流处理场景。相比之下,RabbitMQ的吞吐量通常在每秒几万条消息,适合于传统消息队列应用,如任务分发和通知服务。
如果你的应用场景涉及处理高吞吐量的数据流,比如日志收集、实时分析、流式计算或事件驱动架构,Kafka 的大规模数据处理能力和高吞吐量设计使其成为更优选择。如果你的应用更侧重于传统的消息队列需求,如任务调度、通知服务、工作流管理等,RabbitMQ 的灵活性和成熟的消息路由机制更为适用。
五、可靠性和可用性纬度
消息中间件的可靠性是指对消息不丢失的保障程度;而消息中间件的可用性是指无故障运行时间的百分比。
Kafka 通过将消息持久化到磁盘并支持多副本机制来保证消息的可靠性,而RabbitMQ 也支持消息持久化。在可靠性和可用性方面二者都做的不错。
六、运维管理
早期的 Kafka 版本依赖 Zookeeper 来管理集群及元数据,这让运维的难度增大,不过在 3.0版本中正式实现了不依赖 ZooKeeper 的 KRaft 模式。这一变化标志着 Kafka 在架构上的一个重要里程碑,提高了系统的简化程度和可扩展性。
监控告警方面 Kafka 提供了丰富的监控指标,可以通过第三方工具来进行监控和预警。而 RabbitMQ提供了一个用户友好的 Web 管理界面,使得查看队列状态、管理用户权限、监控消息流量等任务变得直观易行,降低了运维难度。
七、社区活跃度
由于其在大数据处理、流处理领域的广泛应用,Kafka 背后的 Apache 社区非常活跃,不断有新的特性被开发和优化。Kafka 的讨论和技术分享非常多。随着 Kafka 在云原生和事件驱动架构中扮演越来越重要的角色,其社区的活跃度持续增长。
RabbitMQ 基于 Erlang 语言开发,拥有一个成熟的社区,尤其在需要高可靠性和丰富消息模式的场景中有着广泛的应用。它提供了良好的文档、教程以及活跃的论坛和邮件列表支持。尽管相比 Kafka,RabbitMQ 可能在大数据和流处理领域的讨论热度略低,但它在传统企业级消息队列应用中仍然非常受欢迎,社区围绕其特性的讨论和问题解答依然频繁。
八、总结
在选择 Kafka 和 RabbitMQ 时要从功能、性能、可靠性、稳定性、社区活跃度、运维管理等方面进行综合考量,作为架构师要充分了解其特性,选择最贴近自己业务开箱即用的消息中间件。
往期经典推荐
高并发架构设计模板-CSDN博客
RabbitMQ 的高阶应用及可靠性保证-CSDN博客
Kafka消息流转的挑战与对策:消息丢失与重复消费问题_kafka消费者自动提交会丢消息吗-CSDN博客
决胜高并发战场:Redis并发访问控制与实战解析_redis 限制并发访问-CSDN博客
TiDB高手进阶:揭秘自增ID热点现象与高级调优技巧-CSDN博客
本文转载自: https://blog.csdn.net/qq_39209927/article/details/138396936
版权归原作者 超越不平凡 所有, 如有侵权,请联系我们删除。
版权归原作者 超越不平凡 所有, 如有侵权,请联系我们删除。