
进程和线程概念
什么进程
进程是系统运行的基本单位,通俗的理解我们计算机启动的每一个应用程序都是一个进程。如下图所示,在
Windows
中这一个个
exe
文件,都是一个进程。而在
JVM
下,每一个启动的
Main
方法都可以看作一个进程。

什么是线程
线程是比进程更小的单位,所以在进行线程切换时的开销会远远小于进程,所以线程也常常被称为轻量级进程。每一个进程中都会有一个或者多个线程,在
JVM
中每一个
Java
线程都会共享他们的进程的堆区和方法区。但是每一个进程都会有自己的程序计数器、虚拟机栈和本地方法栈。
Java
天生就是一个多线程的程序,我们完全可以运行下面这段代码看看一段
main
方法中会有那些线程在运行
public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
// 遍历线程信息,仅打印线程 ID 和线程名称信息
for (ThreadInfo threadInfo : threadInfos) {
System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
}
}
}
输出结果如下,所以
Java
程序在
main
函数运行时,还有其他的线程再跑。
[6] Monitor Ctrl-Break //这个线程是IDEA用来监控Ctrl-Break中断信号的线程
[5] Attach Listener //添加事件
[4] Signal Dispatcher // 方法处理Jvm信号的线程
[3] Finalizer //清除finalize 方法的线程
[2] Reference Handler // 清除引用的线程
[1] main // main入口
从JVM角度理解进程和线程的区别
图解两者区别
如下图所示,可以看出线程是比进程更小的单位,进程是独立的,彼此之间不会干扰,但是线程在同一个进程中共享堆区和方法区,虽然开销较小,但是资源之间管理和分配处理相对于进程之间要更加小心。
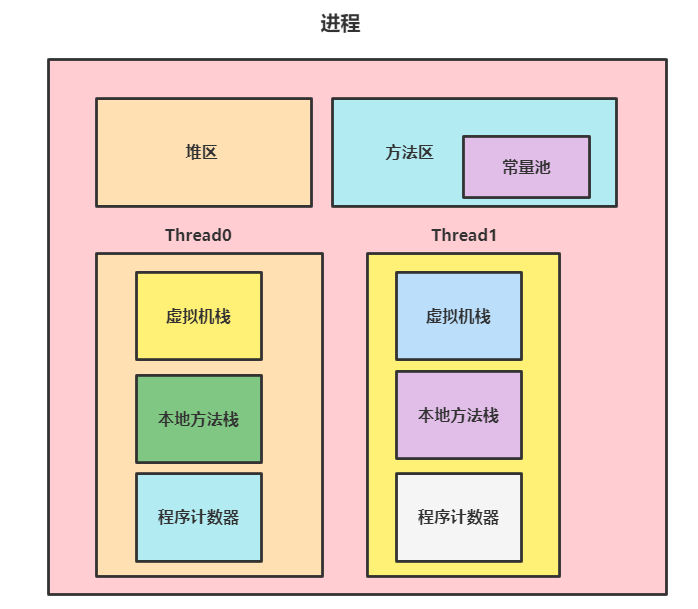
程序计数器、虚拟机栈、本地方法栈为什么线程中是各自独立的
- 程序计数器私有的原因:学过计算机组成原理的小伙伴应该都知晓,程序计数器用于记录当前下一条要执行的指令的单元地址,
JVM也一样,有了程序计数器才能保证在多线程的情况下,这个线程被挂起再被恢复时,我们可以根据程序计数器找到下一次要执行的指令的位置。 - 虚拟机栈私有的原因:每一个
Java线程在执行方法时,都会创建一个栈帧用于保存局部变量、常量池引用、操作数栈等信息,在这个方法调用到完成前,它对应的信息都会基于栈帧保存在虚拟机栈上。 - 本地方法栈私有的原因:和虚拟机栈类似,只不过本地方法栈保存的
native方法的信息。
所以为了保证局部变量不被别的线程访问到,虚拟机栈和本地方法栈都是私有的,这就是我们解决某些线程安全问题时,常会用到一个叫栈封闭技术。
关于栈封闭技术如下所示,将变量放在局部,每个线程都有自己的虚拟机栈,线程安全
public class StackConfinement implements Runnable {
//全部变量 多线操作会有现场问题
int globalVariable = 0;
public void inThread() {
//栈封闭技术,将变量放在局部,每个线程都有自己的虚拟机栈 线程安全
int neverGoOut = 0;
synchronized (this) {
for (int i = 0; i < 10000; i++) {
neverGoOut++;
}
}
System.out.println("栈内保护的数字是线程安全的:" + neverGoOut);//栈内保护的数字是线程安全的:10000
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
globalVariable++;
}
inThread();
}
public static void main(String[] args) throws InterruptedException {
StackConfinement r1 = new StackConfinement();
Thread thread1 = new Thread(r1);
Thread thread2 = new Thread(r1);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(r1.globalVariable); //13257
}
}
多线程常见面试题
并发和并行的区别是什么?
并发:并发我们可以理解为,两个线程先后执行,但是从宏观角度来看,他们几乎是并行的。并行:并行我们可以理解为两个线程同一时间都在运行。
同步和异步是什么意思?
同步:同步就是一个调用没有结果前,不会返回,直到有结果的才返回。异步:异步即发起一个调用后,不等结果如何直接返回。
为什么需要多线程,多线程解决了什么问题
从宏观角度来看:线程可以理解为轻量级进程,切换开销远远小于进程,所以在多核
CPU
的计算机下,使用多线程可以更好的利用计算机资源从而提高计算机利用率和效率来应对现如今的高并发网络环境。
从微观场景下来说: 单核场景,在单核CPU情况下,假如一个线程需要进行IO才能执行业务逻辑,若只有单线程,这就意味着IO期间发生阻塞线程却只能干等。假如我们使用多线程的话,在当前线程IO期间,我们可以将其挂起,让出CPU时间片让其他线程工作。
多核场景下,假如我们有一个很复杂的任务需要进程各种IO和业务计算,假如只有一个线程的话,无论我们有多少个CPU核心,因为单线程的缘故他永远只能利用一个CPU核心,假如我们使用多线程,那么这些线程就会映射到不同的CPU核心上,做到最好的利用计算机资源,提高执行效率,执行事件约为单线程执行事件/CPU核心数。
创建线程方式有哪些(重点)
- 继承Thread 实现多线程
//继承Thread 然后startpublicclassTaskextendsThread{publicvoidrun(){for(int x =0; x <60; x++)System.out.println("Task run----"+ x);}publicstaticvoidmain(String[] args)throwsInterruptedException{Task d =newTask();//创建好一个线程。
d.start();//开启线程并执行该线程的run方法。
d.join();}}
- Runable接口实现多线程
//实现Runnable 方法publicclassTicketimplementsRunnable{privateint tick =100;publicvoidrun(){synchronized(Ticket.class){while(true){if(tick >0){System.out.println(Thread.currentThread().getName()+"....sale : "+ tick--);}}}}}publicclassTicketimplementsRunnable{privateint tick =100;publicvoidrun(){synchronized(Ticket.class){while(true){if(tick >0){System.out.println(Thread.currentThread().getName()+"....sale : "+ tick--);}else{break;}}}}}
- FutureTask+Callable
FutureTask<String> futureTask=new FutureTask<>(()-> "123");
new Thread(futureTask).start();
try {
System.out.println(futureTask.get());
} catch (Exception e) {
e.printStackTrace();
}
为什么需要Runnable接口实现多线程
由于
Java
的类只能单继承,当一个类已有继承类时,某个函数需要扩展为多线程这时候,
Runnable
接口就是最好的解决方案。
Thread和Runnable使用的区别
- 继承Thread:线程代码存放在
Thread子类的run方法中,调用start()即可实现调用。 - Runnable:线程代码存在接口子类的
run方法中,需要实例化一个线程对象Thread并将其作为参数传入,才能调用到run方法。
Thread类中run()和start()的区别
- run:仅仅是方法,在线程实例化之后使用
run等于一个普通对象的直接调用。 - start:开启了线程并执行线程中的
run方法,这期间程序才真正执行从用户态到内核态,创建线程的动作。
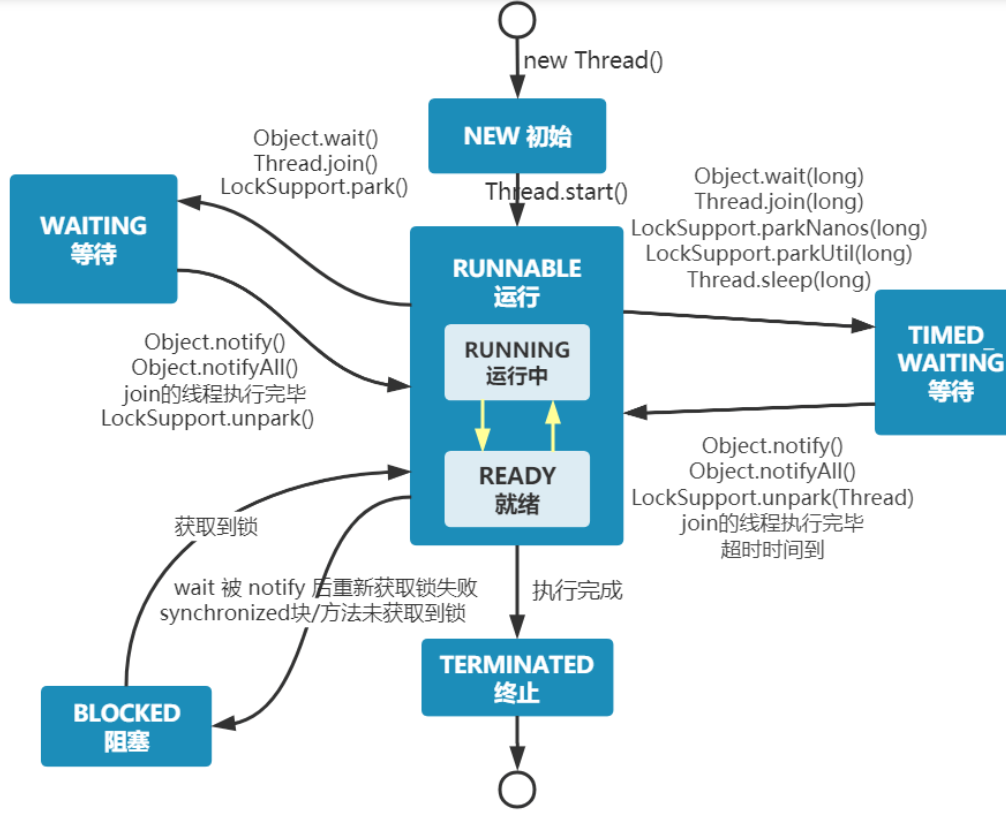
Java线程有哪几种状态(笔试)
新建(NEW):新创建的了一个线程对象,该对象并没有调用
start()
。
**可运行(RUNNABLE)**:线程对象创建后,并调用了
start
方法,等待分配
CPU
时间执行代码逻辑。
阻塞(BLOCKED):阻塞状态,等待锁的释放。当线程在
synchronized
中被
wait
,然后再被唤醒时,若
synchronized
有其他线程在执行,那么它就会进入
BLOCKED
状态。
**等待(WAITING)**:因为某些原因被挂起,等待其他线程通知或者唤醒。
超时等待(TIME_WAITING):等待时间后自行返回,而不像
WAITING
那样没有通知就一直等待。
**终止(TERMINATED)**:该线程执行完毕,终止状态了。
和操作系统的线程状态的区别
如下图所示,实际上操作系统层面可将
RUNNABLE
分为
Running
以及
Ready
,
Java
设计者之所以没有区分那么细是因为现代计算机执行效率非常高,这两个状态在宏观角度几乎无法感知。现代操作系统对多线程采用时间分片的抢占式调度算法,使得每个线程得到
CPU
在
10-20ms
处于运行状态,然后在让出
CPU
时间片,在不久后又会被调度执行,所以对于这种微观状态区别,
Java
设计者认为没有必要为了这么一瞬间进行这么多的状态划分。
什么是上下文切换
线程在执行过程中都会有自己的运行条件和状态,这些运行条件和状态我们就称之为线程上下文,这些信息例如程序计数器、虚拟机栈、本地方法栈等信息。当出现以下几种情况的时候就会从占用
CPU
状态中退出:
- 线程主动让出
CPU,例如调用wait或者sleep等方法。 - 线程的CPU 时间片用完 而退出
CPU占用状态(因为操作系统为了避免某些线程独占CPU导致其他线程饥饿的情况就设定的例如时间分片算法)。 - 线程调用了阻塞类型的系统中断,例如
IO请求等。 - 线程被终止或者结束运行。
上述的前三种情况都会发生上下文切换。为了保证线程被切换在恢复时能够继续执行,所以上下文切换都需要保存线程当前执行的信息,并恢复下一个要执行线程的现场。这种操作就会占用
CPU
和内存资源,频繁的进行上下文切换就会导致整体效率低下。
线程死锁问题
如下图所示,两个线程各自持有一把锁,必须拿到对方手中那把锁才能释放自己的锁,正是这样一种双方僵持的状态就会导致线程死锁问题。

翻译称代码就如下图所示
public class DeadLockDemo {
public static final Object lock1 = new Object();
public static final Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1){
System.out.println("线程1获得锁1,准备获取锁2");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2){
System.out.println("线程1获得锁2");
}
}
}).start();
new Thread(() -> {
synchronized (lock2){
System.out.println("线程2获得锁2,准备获取锁1");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1){
System.out.println("线程2获得锁1");
}
}
}).start();
}
}
输出结果
线程1获得锁1,准备获取锁2
线程2获得锁2,准备获取锁1
符合以下4个条件的场景就会发生死锁问题:
- 互斥:一个资源任意时间只能被一个线程获取。
- 请求与保持条件:一个线程拿到资源后,在获取其他资源而进入阻塞期间,不会释放已有资源。
- 不可剥夺条件:该资源被线程使用时,其他线程无法剥夺该线程使用权,除非这个线程主动释放。
- 循环等待条件:若干线程获取资源时,取锁的流程构成一个头尾相接的环,如上图。
预防死锁的3种方式
- 破坏请求与保持条件:以上面代码为例,我们要求所有线程必须一次性获得两个锁才能进行业务处理。即要求线程一次性获得所有资源才能进行逻辑处理。
- 破坏不可剥夺:资源被其他线程获取时,我们可以强行剥夺使用权。
- 破坏循环等待:这个就比较巧妙了,例如我们上面lock1 id为1,lock2id为2,我们让每个线程取锁时都按照lock的id顺序取锁,这样就避免构成循环队列。
- 操作系统思想(银行家算法):这个就涉及到操作系统知识了,大抵的意思是在取锁之前对资源分配进行评估,如果在给定资源情况下不能完成业务逻辑,那么就避免这个线程取锁,感兴趣的读者可以
sleep和wait方法区别
sleep不会释放锁,只是单纯休眠一会。而wait则会释放锁。sleep单纯让线程休眠,在给定时间后就会苏醒,而wait若没有设定时间的话,只能通过notify或者notifyAll唤醒。sleep是Thread的方法,而wait是Object的方法wait常用于线程之间的通信或者交互,而sleep单纯让线程让出执行权。
为什么sleep会定义在Thread
因为
sleep
要做的仅仅是让线程休眠,所以不涉及任何锁释放等逻辑,放在
Thread
上最合适。
为什么wait会定义在Object 上
我们都知道使用
wait
时就会释放锁,并让对象进入
WAITING
状态,会涉及到资源释放等问题,所以我们需要将
wait
放在
Object
类上。
可以直接调用 Thread 类的 run 方法吗?
若我们编写run方法,然后调用
Thread
的
start
方法,线程就会从用户态转内核态创建线程,并在获取
CPU
时间片的时候开始运行,然后运行
run
方法。
若直接调用
run
方法,那么该方法和普通方法没有任何差别,它仅仅是一个名字为
run
的普通方法。
假如在进程中, 已经开辟了多个线程, 其中一个线程怎么中断其它线程?
找到线程对应线程组即可定位到线程,然后调用interrupt将其打断即可。但如果想精确定位线程,我们还是建议使用ThreadLocal对线程做个标记。
ThreadGroup threadGroup =Thread.currentThread().getThreadGroup();if(threadGroup !=null){Thread[] threads =newThread[(int)(threadGroup.activeCount()*1.2)];int count = threadGroup.enumerate(threads,true);for(int i =0; i < count; i++){if(threads[i].getId()== threadId){return threads[i];}}}returnnull;
IO阻塞的线程会占用CPU资源吗?如何避免线程霸占CPU?
由于讲述问题的篇幅比较大,笔者专门写了一篇文章来讨论这两个问题,感兴趣的朋友可以看看:来聊聊IO阻塞与CPU任务调度
参考文章
Java并发编程:volatile关键字解析:https://www.cnblogs.com/dolphin0520/p/3920373.html
我是一个线程:https://mp.weixin.qq.com/s/IkNfuE541Mqqbv2iLIhMRQ
Java 并发常见面试题总结(上):https://javaguide.cn/java/concurrent/java-concurrent-questions-01.html#什么是线程和进程
创建线程几种方式_线程创建的四种方式及其区别:https://cloud.tencent.com/developer/article/2135189#:~:text=创建线程的几种方式: 方式1:通过继承Thread类创建线程 步骤:1.定义Thread类的子类,并重写该类的run方法,该方法的方法体就是线程需要执行的任务,因此run,()方法也被称为线程执行体 2.创建Thread子类的实例,也就是创建了线程对象 3.启动线程,即调用线程的start ()方法
版权归原作者 shark-chili 所有, 如有侵权,请联系我们删除。