
一、下载hadoop
1.官网下载:Apache Hadoophttps://hadoop.apache.org/release/3.1.3.html
2.百度云下载:链接:https://pan.baidu.com/s/1f28w-CIg7M2pViVp7Nj0tQ 提取码:g4un
二、下载winutils(hadoop在window运行的工具)
1.百度云下载:链接:https://pan.baidu.com/s/1Tvp7xQHAoWLHAVCblxJ5Iw 提取码:qato
三、安装hadoop
1.在D盘新建文件夹hadoop,并且把下载的hadoop-3.1.3.tar.gz压缩包拖到此目录.然后解压
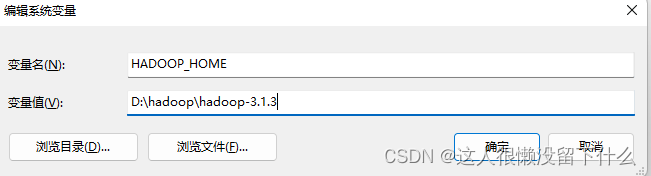
2.在系统的变量中创建变量HADOOP_HOME,变量值是D:\hadoop\hadoop-3.1.3
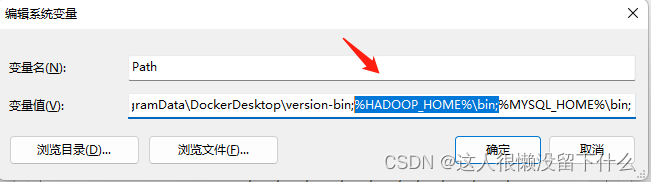
3.在path变量中添加hadoop的bin路径
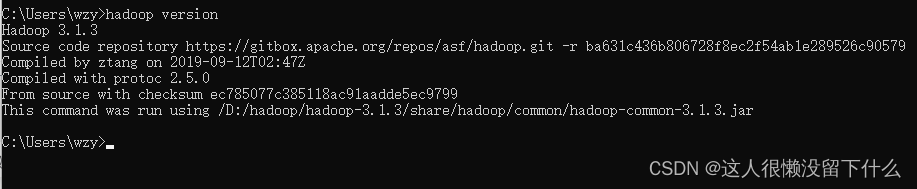
4.进入cmd,输入命令hadoop version查看hadoop是否安装成功
5.进入hadoop-3.1.3目录,创建data和temp文件夹
6.进入data目录,创建datanode和namenode文件夹
7.进入D:\hadoop\hadoop-3.1.3\etc\hadoop目录
8.编辑文件core-site.xml,添加
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
9.编辑文件hdfs-site.xml,添加
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop/hadoop-3.1.3/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop/hadoop-3.1.3/data/datanode</value> </property> </configuration>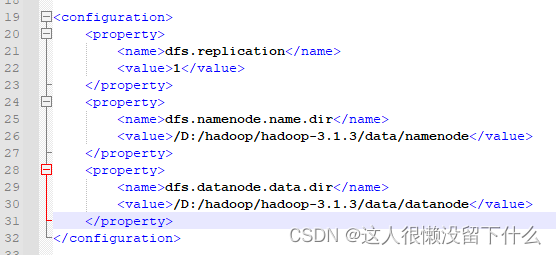
10.编辑文件mapred-site.xml,添加
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
11.编辑文件yarn-site,xml,添加
<configuration><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>

12.在cmd命令控制台输入hdfs namenode -format格式化节点

13.进入D:\hadoop\hadoop-3.1.3\bin,把之前下载的winutils里面的bin覆盖到这里
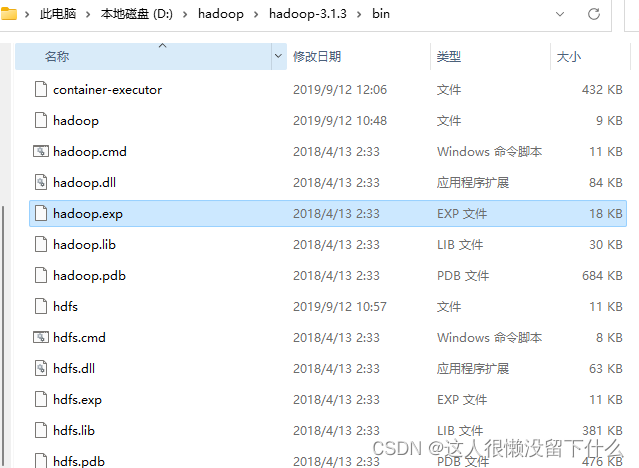
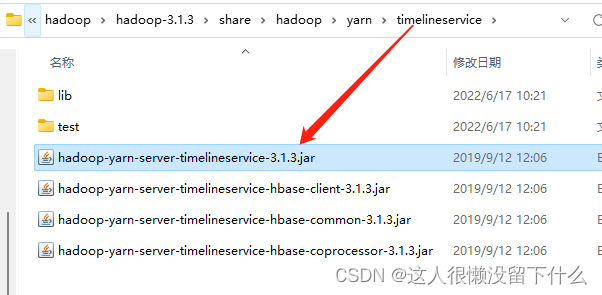
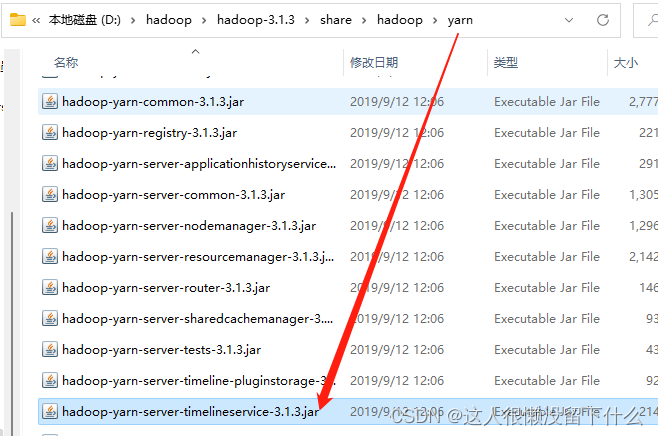
14.进入D:\hadoop\hadoop-3.1.3\share\hadoop\yarn\timelineservice,复制一份到D:\hadoop\hadoop-3.1.3\share\hadoop\yarn
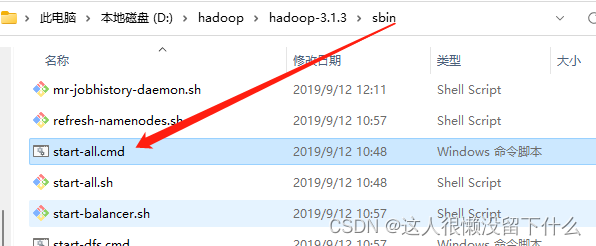
15.进入D:\hadoop\hadoop-3.1.3\sbin,运行start-all.cmd
16.浏览器访问http://localhost:9870/
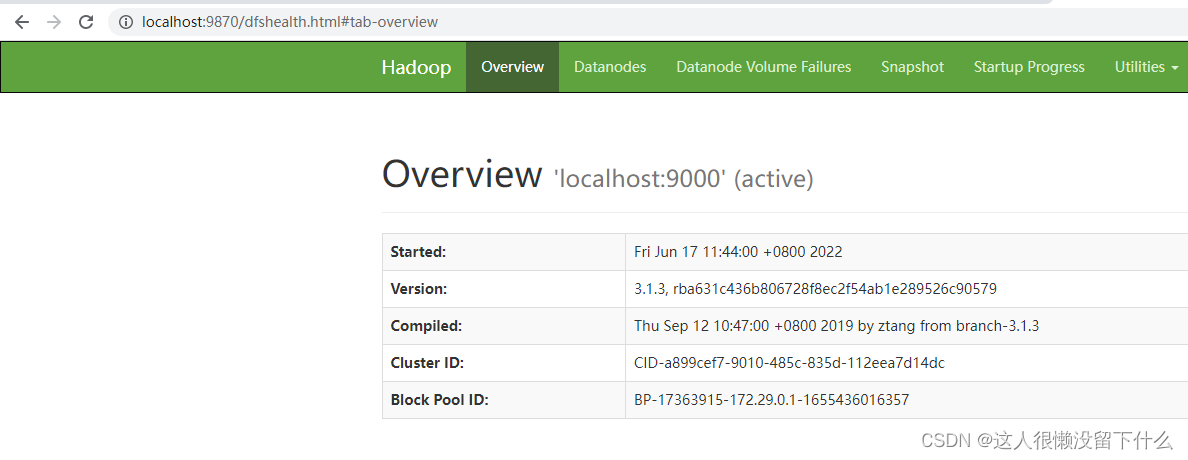
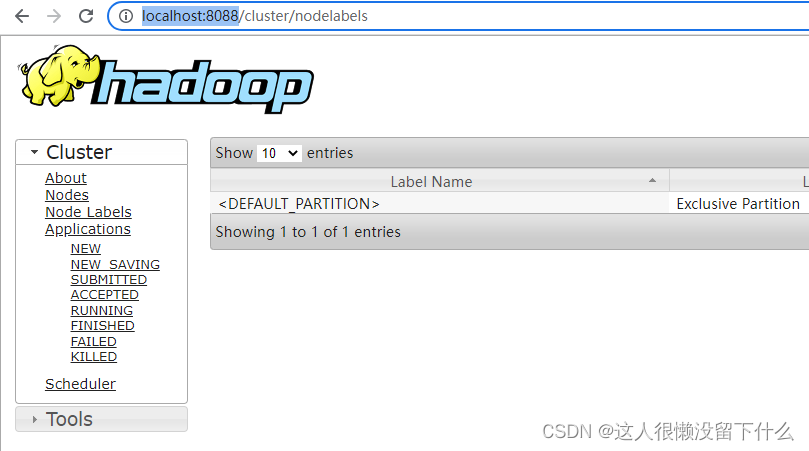
17.浏览器访问http://localhost:8088/
版权归原作者 这人很懒没留下什么 所有, 如有侵权,请联系我们删除。