
1.前言
最近在学习Spark Streaming,对流数据日志处理有了一些了解,加上学校近期开展了SSM框架的课程。一上头,就想把这东西给整和一下,源码我整合在Gitee上了,可自行取。
此项属于对前后端+Spark数据处理的一个整合,难度并不大,属于对Spark学习的横向扩展,适用于Spark Streaming的初学者。
考虑篇幅过长,先上源码:Spark流处理日志
2.实战内容
- python编写脚本定时生成伪随机日志
- SparkStream获取数据,将数据清洗过滤非法数据,然后分析日志中用户的访问量,统计访问课程数;访问搜索引擎,统计不同搜索引擎的点击量 - 将Spark Streaming处理的结果初步存入Mysql(可以缓存到Hbase中,取数可以更快)- Spark获取Mysql数据,统计课程和搜索引擎的点击量,存入Mysql
- 前端使用Spring, Spring Mvc, MyBatis展示数据
- 考虑到图像运用Echarts,所以使用Ajax异步传输数据给jsp
Spark工作流程图如下:

3.实战框架
实战工具:Intellij IDEA2021专业版( 因为社区版没有Tomcat,也没有具体试验过插件Smart Tomcat,其他功能社区版均能实现 ), PyCharm社区版,JDK版本1.8,Scala版本2.13
架构和涉及的技术栈:
- Python-3.9
- Spark-3.2.1
- Mybatis-3.5.9
- Spring Mvc-5.3.16
- Spring-5.3.16
- Echarts
4.项目实战
注意:本项目将Scala和Java板块合并在同一个工程中,所以只需要创建一个工程即可
1.环境搭建:
1)创建Maven工程,引入依赖pom.xml(源文件是完整的):
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>${mybatis.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis-spring -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-logging/commons-logging -->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-expression -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-expression</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring_mvc.vserion}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scala-lang/scala-library -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.13.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.13</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
2)下载Scala插件,再右键项目名添加框架支持,导入Scala模块
2.后端开发
1.在PyCharm创建python脚本,生成随机日志
一次脚本的完整运行,将会一次性产生2000条日志,以追加的方式平摊在文档中。根据脚本的编码,产生一条正确完整的Web日志的概率仅为20%,即一次运行,只有400条左右的日志会存入数据库中,详情可查看步骤2)

import random
import time
# 创建url访问数组class
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/500.html",
"class/250.html",
"class/131.html",
"learn/821",
"learn/823",
"learn/987",
"learn/500",
"course/list"
]
# 创建ip数组,随机选择4个数字作为ip如132.168.30.87
ip_slices = [132, 156, 124, 10, 29, 167, 143, 187, 30, 46, 55, 63, 72, 87, 98, 168, 192, 134, 111, 54, 64, 110, 43, 127, 12, 53, 99]
# 搜索引擎访问数组
# {query}
# 代表搜索关键字
http_referers = [
"http://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}",
]
# 搜索关键字数组
search_keyword = [
"Spark SQL",
"Hadoop",
"Storm",
"Spark Streaming",
"10 HoursCrash",
"Blink",
"SpringBoot",
"Linux",
"Vue.js",
"Hive",
"Flink",
]
# 状态码数组
status_codes = ["200", "504", "404", "403"]
# 随机选择一个url
def sample_url():
return random.sample(url_paths, 1)[0]
# 随机组合一个ip
def sample_ip():
slice = random.sample(ip_slices, 4)
return ".".join([str(item) for item in slice])
# 随机产生一个搜索url
def sample_referer():
# // 0.2的概率会产生非法url,用于模拟非法的用户日志
if random.uniform(0, 1) > 0.8:
return "-"
refer_str = random.sample(http_referers, 1)
query_str = random.sample(search_keyword, 1)
return refer_str[0].format(query=query_str[0])
# 随机产生一个数组
def sample_status_code():
return random.sample(status_codes, 1)[0]
def generate_log(count=10, index=10):
# 获取本机时间并将其作为访问时间写进访问日志中
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
indexes = str(index)
file = "./data/OfflineWareHouse/随即日志生成器" + indexes + ".log"
# 存储日志的目标文件(换成你自己的) w覆盖 a追加
f = open(file, "a")
# 组合用户日志
while count >= 1:
query_log = "{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status_code}\t{referer}".format(url=sample_url(),
ip=sample_ip(),
referer=sample_referer(),
status_code=sample_status_code(),
local_time=time_str)
f.write(query_log + "\n")
count = count - 1
f.close()
# 执行main,每次产生100*20条用户日志
counts = 20
while counts:
sleepTime = random.randint(6, 12)
time.sleep(sleepTime)
print("第%d个Web日志新增%d条数据" % (counts, 100))
generate_log(100, counts)
counts = counts - 1
2.SparkStreaming数据的初步清洗
Spark Streaming可整合多种输入数据源,如Kafka,Flume,HDFS,甚至是普通的TCP套接字流,本次是对本地模式中的固定目录进行监听,一旦发现有新的文件内容生成,Spark Streaming就会自动把文件内容读取出来,使用自定义的处理逻辑处理.
①.在主函数创建对应的工程包scala并标记为"源目录":

②.在数据清洗前,需要了解Web日志的规格设置,本日志数据与数据之间是通过"\t"也就是Tab键位分隔开的,下面是一条常规的Web日志,其规格如下,我们需要将method和url拆开,获取单独的GET,yahoo,Spark Streaming字段
userIp = 168.46.55.10
local_time = 2022-04-03 19:03:52
method = "GET /class/146.html HTTP/1.1"
status = 404
url = https://search.yahoo.com/search?p=Spark Streaming
③.Spark Streaming的代码如下:
SparkStreaming的数据抽象为DStream,不同的数据抽象有不同的函数方法,为了完成需求,、整个日志的RDD格式走向为DStream[String]->RDD[String]->DataFrame
package ssm
import org.apache.spark.sql.{SQLContext}
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WareHouseStreaming {
def main(args:Array[String]): Unit ={
val sparkConf = new SparkConf().setAppName("WareHouseStreaming").setMaster("local")
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "******")
prop.put("driver","com.mysql.jdbc.Driver")
val scc = new StreamingContext(sparkConf, Seconds(10))
val file = "file:///C:/Users/Lenovo/Desktop/Working/Python/data/OfflineWareHouse/"
val lineDStream = scc.textFileStream(file)
val lines = lineDStream.flatMap(_.split("\n"))
val line = lines.map(_.replaceAll("\"","")).map(_.split("\t"))
line.foreachRDD(rdd=>{
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
rdd
.map(x=>(x(0).trim,x(1).trim,x(2).trim,x(3).trim,x(4).trim))
.toDF("userIp","local_time","method","status","url")
.registerTempTable("speedtable")
val dataFrame = sqlContext.sql("select * from speedtable ")
//dataFrame.show(5)
//println(dataFrame.count())
//过滤状态码非200字段,过滤非法url字段
//状态码为200的概率为1/4,产生合法url字段的概率为4/5,即一条正确的日志概率为1/5
val d1 = dataFrame
.filter(x => x(3) == "200")
.filter(x => x(4) != "-")
val dfDetail = d1.map( row =>{
val methods = row.getAs[String]("method").split(" ")
val urls = row.getAs[String]("url").split("\\?")
val SE = urls(0)
val names = urls(1)
.split("=")
val name = names(1)
var map = Map("params" -> "null")
val method = methods(0)
val url = methods(1)
val agreement = methods(2)
(
row.getAs[String]("userIp"),
row.getAs[String]("local_time"),
map.getOrElse("method",method),
map.getOrElse("url",url),
map.getOrElse("agreement",agreement),
row.getAs[String]("status"),
map.getOrElse("SE",SE),
map.getOrElse("name",name)
)
}).toDF("userIp","local_time","method","url","agreement","status","SE","name")
dfDetail.show(5)
val url = "jdbc:mysql://localhost:3306/python_db"
println("开始写入数据库")
dfDetail.write.mode("Append").jdbc(url,"warehouse",prop)
println("完成写入数据库,新增"+dfDetail.count()+"条数据")
})
scc.start()
scc.awaitTermination()
}
}
** 3.统计课程点击量和搜索引擎的访问量**
相比较采用流数据处理问题,采用离线数据处理问题的方式简单快捷,程序可以独立运行,方便维护,缺点是计算量比流式计算模式大得多,因为会重复计算数据。但前端页面的刷新时间为10s,数据的时效性并不明显,10s对离线计算时间足以
课程点击量代码:
package ssm
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import java.util.Properties
object NameCount {
def main(args:Array[String]): Unit ={
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "******")
prop.put("driver", "com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/python_db"
while(true){
Thread.sleep(10000)
println("开始更新课程点击量")
lessCount(prop,url)
}
}
def lessCount(prop:Properties,url:String): Unit = {
val spark = SparkSession.builder().appName("NameCount").master("local").getOrCreate()
val sc = spark.sparkContext
/**
整体流程的数据类型为Mysql->
DataFrame->{ RDD[Row]->RDD[String] }
->replace归并课程类型
->RDD[String,Int]统计点击量
->RDD[Row(String,Integer)]
->DataFrame->Mysql
*/
import spark.implicits._
val dataFrame = spark.read.jdbc(url, "warehouse", prop).select("name")
// DataFrame->{ RDD[Row]->RDD[String] }
val dataRDD = dataFrame.rdd.map(x=>x.mkString(""))
// dataRDD.foreach(println)
// ->replace归并课程类型
val word = dataRDD
.map(_.replaceAll("10 HoursCrash","Hadoop"))
.map(_.replaceAll("Spark Streaming","Spark"))
.map(_.replaceAll("Hive","Hadoop"))
.map(_.replaceAll("Spark SQL","Spark"))
.map(_.replaceAll("Blink","Flink"))
//word.foreach(println)
// ->RDD[String,Int]统计点击量
val wordCount = word.map((_,1))
.reduceByKey(_+_)
.sortBy(_._2,false)
//wordCount.foreach(println)
// ->RDD[Row(String,Integer)]
val dF = wordCount.map(x=>{Row(x._1,x._2)})
//dF.foreach(println)
// ->DataFrame->Mysql
val schema = StructType(Array(
StructField("lesson",StringType),
StructField("counts",IntegerType)
))
val orgDF = spark.createDataFrame(dF, schema)
orgDF.show()
println("开始写入数据库")
orgDF.write.mode("overwrite").jdbc(url,"lesson_counts",prop)
println("完成写入数据库,因为报错会中断进程")
sc.stop()
}
}
** 搜索引擎访问量统计代码如下:**
package ssm
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import java.util.Properties
object UrlCount {
def main(args:Array[String]): Unit ={
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "******")
prop.put("driver", "com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/python_db"
while(true) {
Thread.sleep(10000)
println("开始更新搜索点击量")
SECounts(prop, url)
}
}
def SECounts(prop:Properties,url:String): Unit ={
val spark = SparkSession.builder().appName("urlCount").master("local").getOrCreate()
val sc = spark.sparkContext
val SEFrame = spark.read.jdbc(url, "warehouse", prop).select("SE")
// dataFrame.show(5)
val SERdd = SEFrame.rdd.map(_.mkString(""))
val SE = SERdd
.map(_.split("[.]"))
.map(x=>x(1))
.map(_.replaceAll("baidu","百度"))
.map(_.replaceAll("sogou","搜狗"))
.map(_.replaceAll("bing","必应"))
.map(_.replaceAll("yahoo","雅虎"))
val seCount = SE.map((_,1))
.reduceByKey(_+_)
.sortBy(_._1)
.map(x=>{Row(x._1,x._2)})
seCount.foreach(println)
val schema = StructType(Array(
StructField("Se",StringType),
StructField("counts",IntegerType)
))
val detailDF = spark.createDataFrame(seCount,schema)
println("正在存入数据库")
detailDF.write.mode("Overwrite").jdbc(url,"se_counts",prop)
println("数据库存入完成")
sc.stop()
}
}
4.检验步骤
运行SparkStreaming代码挂后台
运行UrlCount和NameCount挂后台
运行Python脚本挂后台
前往Spark的窗口查看数据是否成功收集
Spark Streaming成功样例:
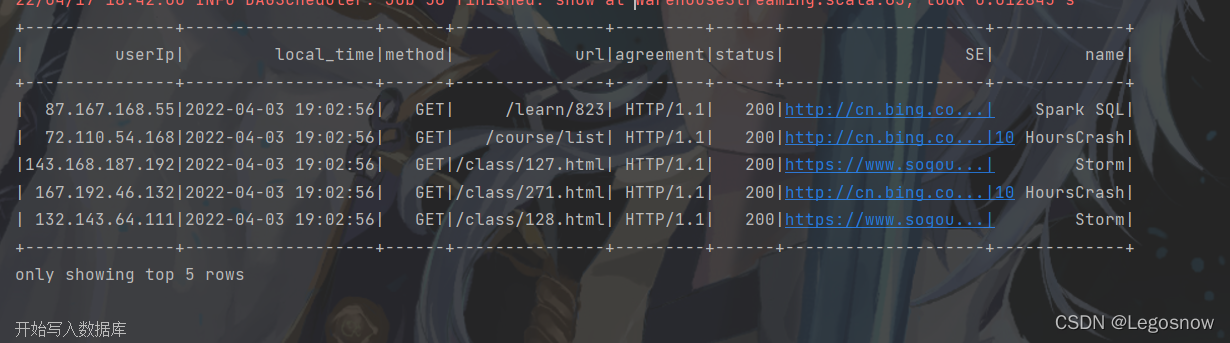
** NameCount成功样例:**

** urlCount成功样例:**

** 5.注意事项:**
①.Spark Streaming处理日志需要花费的时间最好不要超过一次检测(目前是10s)的时间,当Python一次性生成的数据量过大(目前是100)导致上述问题发生时,Spark的计算会出现严重问题,甚至可能会宕机。合理分配Spark检测时间和数据量很重要,这属于经验,具体要看后续其他业务的数据量的大小来调优。
---有一次作死,让python每5s产生1500条日志(总计一次3万),Spark检测时间也是5s,结果一次存入数据库的数据量也在3万上下(理论是6000)。后续发现当第一批数据读入还未计算完,第二批就进来了,结果就是第一批数据夹杂着第二批的数据一并存入数据库中,而当我意识到这个问题的时候,数据库中的数据量已经超过20多万了,我一气之下删库了.....
至此Spark Streaming的开发已经完成了
3.前端开发(IDEA专业版)
创建工程文件搭建SSM框架
1.配置mapper和pojo目录文件
工程文件显示如下,其中SE为搜索引擎的类,Lesson为课程点击量的类
Lesson.java (SE.java同理,可以直接去发的源码查看)
package cn.pojo;
public class Lesson {
private String lesson = null;
private Integer lesson_count = null;
public String getLesson() {return lesson;}
public void setLesson(String lesson) {this.lesson = lesson;}
public Integer getLesson_count() {return lesson_count;}
public void setLesson_count(Integer lesson_count) {this.lesson_count = lesson_count;}
@Override
public String toString() {
return "Lesson{" +
" lesson= " + lesson +
" ,lesson_count= " + lesson_count +
'}';
}
}
接口LessonMapper.java (SEMapper.java同理)
package cn.mapper;
import org.apache.ibatis.annotations.Param;
import cn.pojo.Lesson;
import java.util.List;
public interface LessonMapper {
Integer selectLessonCount(Lesson user);
List<Lesson> selectAll();
}
接口的实现LessonMapper.xml (SE同理)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.mapper.LessonMapper">
<select id="selectLessonCount" resultType="int">
select counts from lesson_counts where lesson = CONCAT(#{lesson})
</select>
<!-- 左边为Lesson设置的参数名字,右边为MySQL表格的参数名字,如果是联表查询都可以resultMap为这个 -->
<resultMap type="cn.pojo.Lesson" id="userLesson">
<result property="lesson" column="lesson"/>
<result property="lesson_count" column="counts"/>
</resultMap>
<select id="selectAll" resultType="cn.pojo.Lesson" resultMap="userLesson">
select * from lesson_counts
</select>
</mapper>
2.util配置
在util下创建MybatisUtils.java用于Mybatis连接Mysql
package cn.util;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//获取SqlSession连接
public static SqlSession getSession(){
return sqlSessionFactory.openSession();
}
}
3.配置dao层和service层代码
DAO层代码
接口CourseClickDao.java (SE同理)
package cn.dao;
import cn.pojo.Lesson;
import java.util.List;
public interface CourseClickDao {
List<Lesson> selectLessonAll(Lesson user);
}
接口CourseClickDao.java的实现CourseDaoImpl.java
package cn.dao.Impl;
import cn.dao.CourseClickDao;
import cn.pojo.Lesson;
import org.mybatis.spring.SqlSessionTemplate;
import java.util.List;
public class CourseDaoImpl implements CourseClickDao{
public SqlSessionTemplate session;
public SqlSessionTemplate getSession(){return session;}
public void setSession(SqlSessionTemplate session){this.session = session;}
@Override
public List selectLessonAll(Lesson user){
return session.selectList("cn.mapper.LessonMapper.selectAll");
}
}
4.resources配置
Spring配置文件beans.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.3.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.3.xsd"
default-autowire="byType">
<!-- 配置数据源 换成你的数据库url-->
<bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/python_db"/>
<property name="username" value="root"/>
<property name="password" value="******"/>
</bean>
<!-- 配置SessionFactory -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<!--内容可以不改动,配置sqlSessionTemplate -->
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"/>
</bean>
<bean id="clickDao" class="cn.dao.Impl.CourseDaoImpl">
<property name="session" ref="sqlSessionTemplate"/>
</bean>
<bean id="searchDao" class="cn.dao.Impl.SearchDaoImpl">
<property name="session" ref="sqlSessionTemplate"/>
</bean>
<bean id="clickService" class="cn.service.Impl.CourseServiceImpl">
<property name="dao" ref = "clickDao"/>
</bean>
<bean id="searchService" class="cn.service.Impl.SearchServiceImpl">
<property name="dao" ref = "searchDao"/>
</bean>
<bean id="Lesson" class="cn.pojo.Lesson"
p:lesson="Hadoop" p:lesson_count="1"/>
<bean id="SE" class="cn.pojo.SE"
p:lesson="百度" p:lesson_count="1"/>
<!-- 包扫描 -->
<context:component-scan base-package="cn.dao,cn.service" />
<!-- 事务管理器 -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 配置事务 -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED" isolation="DEFAULT"/>
</tx:attributes>
</tx:advice>
</beans>
Spring MVC配置文件dispatcher.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd">
<!-- 配置包扫描路径 -->
<context:component-scan base-package="cn.controller"/>
<!-- 配置使用注解驱动 -->
<mvc:annotation-driven />
<mvc:default-servlet-handler/>
<!-- 配置视图解析器 -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/jsp"/>
<property name="suffix" value=".jsp"/>
</bean>
</beans>
Mybatis配置文件mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--这一部分的datasource可以不需要,只需要mappers-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--<property name="driver" value="com.mysql.jdbc.Driver"/>-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/python_db"/>
<property name="username" value="root"/>
<property name="password" value="******"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper class="cn.mapper.SEMapper"/>
<mapper class="cn.mapper.LessonMapper"/>
</mappers>
</configuration>
5.配置controller
配置MVC控制器CourseClickController.java如下(SearchClickController.java同理)
package cn.controller;
import cn.pojo.Lesson;
import cn.service.CourseClickService;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.List;
/**
* 课程点击Controller
*/
@Controller("COURSECLICK")
@RequestMapping("/")
public class CourseClickController {
//页面跳转
@RequestMapping("/courseClick")
public String toGetCourseClick(){
return "courseClick";
}
/**
* sponseBody注解的作用是将controller的方法返回的对象通过适当的转换器转
* 换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML
*/
@ResponseBody
@RequestMapping(value = "/getCourseClickCount",method = RequestMethod.GET)
public JSONArray courseClickCount(){
JSONArray json = new JSONArray();
// Lesson类有课程名name(String)和对应的人点击量count(int)
ApplicationContext context = new ClassPathXmlApplicationContext(
"beans.xml");
CourseClickService service = (CourseClickService) context.getBean("clickService");
Lesson use = (Lesson) context.getBean("Lesson");
List<Lesson> lessons = service.selectLessonALlSer(use);
for(Lesson les : lessons){
JSONObject jo = new JSONObject();
jo.put("name",les.getLesson());
jo.put("count",les.getLesson_count());
json.add(jo);
}
// list有多个课程名和对应的点击量
//封装JSON数据
return json;
}
}
6.配置webapp
创建webapp,添加Web框架支持
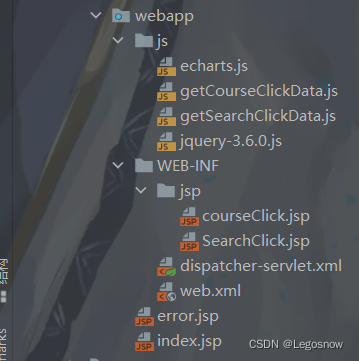
以上文件的代码如下:
1.WEB-INF文件代码如下
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!-- 指定spring的配置文件beans.xml -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:dispatcher-servlet.xml</param-value>
</context-param>
<!-- 确保web服务器启动时,完成spring的容器初始化 -->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!-- 配置分发器 -->
<servlet>
<servlet-name>dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
courseClick.jsp
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<!-- 设置每隔10秒刷新一次页面-->
<meta http-equiv="refresh" content="10">
<script type="text/javascript" src="<c:url value="/js/echarts.js"/>"></script>
<script src="<c:url value="/js/jquery-3.6.0.js"/>"></script>
</head>
<body>
<div id="main1" style="width: 600px;height:500px;float: left;margin-top:100px"></div>
<div id="main2" style="width: 600px;height:500px;float: right;margin-top:100px"></div>
</body>>
<script src="<c:url value="/js/getCourseClickData.js"/>"></script>
</html>
2.js文件代码如下
** echarts和jquery源文件有,或者自行在官网下载**
getCourseClickData.js
function addScript(url){
document.write("<script language=javascript src="+echarts+"></script>");
}
var scources = [];
var scources2 = [];
var scources3 = [];
var scources4 = [];
//获得url上参数date的值
function GetQueryString()
{
var reg = new RegExp("(^|&)=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);//search,查询?后面的参数,并匹配正则
if(r!=null)return unescape(r[2]); return null;
}
var date = GetQueryString();
$.ajax({
type:"GET",
url:"/getCourseClickCount",
dataType:"json",
async:false,
success:function (result) {
if(scources.length != 0){
scources.clean();
scources2.clean();
scources3.clean();
scources4.clean();
}
for(var i = 0; i < result.length; i++){//饼图外侧所有数据
scources3.push({"value":result[i].count,"name":result[i].name});
}
for(var i = 0; i < 5; i++){//柱状图前五数据
scources.push(result[i].name);
scources2.push(result[i].count);
}
for(var i = 0; i < 3; i++){//内测饼图前三数据
scources4.push({"value":result[i].count,"name":result[i].name});
}
}
})
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main1'));
// 指定图表的配置项和数据
var option = {
title: {
text: '学习网实时实战课程访问量',
subtext: '课程点击数',
x:'center'
},
tooltip: {
legend: {
data: ['点击数']
}
},
xAxis: {
data: scources
},
yAxis: {},
series: [{
name: '点击数',
type: 'bar',
data: scources2
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
var myChart = echarts.init(document.getElementById('main2'));
// 指定图表的配置项和数据
var option = {
title: {
text: '学习网实时实战课程访问量',
subtext: '课程点击数',
x:'center'
},
tooltip: {
trigger: 'item',
formatter: "{a} <br/>{b}: {c} ({d}%)"
},
legend: {
type: 'scroll',
orient: 'vertical',
right: 50,
top: 20,
data: scources
},
series: [
{
name: 'Access From',
type: 'pie',
selectedMode: 'single',
radius: [0, '30%'],
label: {
position: 'inner',
fontSize: 20
},
labelLine: {
show: false
},
data: scources4
},
{
name: 'Access From',
type: 'pie',
radius: ['40%', '55%'],
labelLine: {
length: 30
},
label: {
formatter: '{a|{a}}{abg|}\n{hr|}\n {b|{b} :}{c} {per|{d}%} ',
backgroundColor: '#F6F8FC',
borderColor: '#8C8D8E',
borderWidth: 1,
borderRadius: 5,
rich: {
a: {
color: '#6E7079',
lineHeight: 20,
align: 'center'
},
hr: {
borderColor: '#8C8D8E',
width: '100%',
borderWidth: 1,
height: 0
},
b: {
color: '#4C5058',
fontSize: 15,
fontWeight: 'bold',
lineHeight: 30
},
per: {
color: '#fff',
backgroundColor: '#4C5058',
padding: [3, 4],
borderRadius: 5
}
}
},
data: scources3
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
7.配置tomcat服务器
先去官网下载tomcat服务器,这里使用的时8.5版本
一般此时IDEA会提醒你发现Web,是否配置Web框架,点击配置,前往“项目结构”,为Web配置工件,将右边SSMWork的与SSM相关的元素带入SSMWork_Web war中
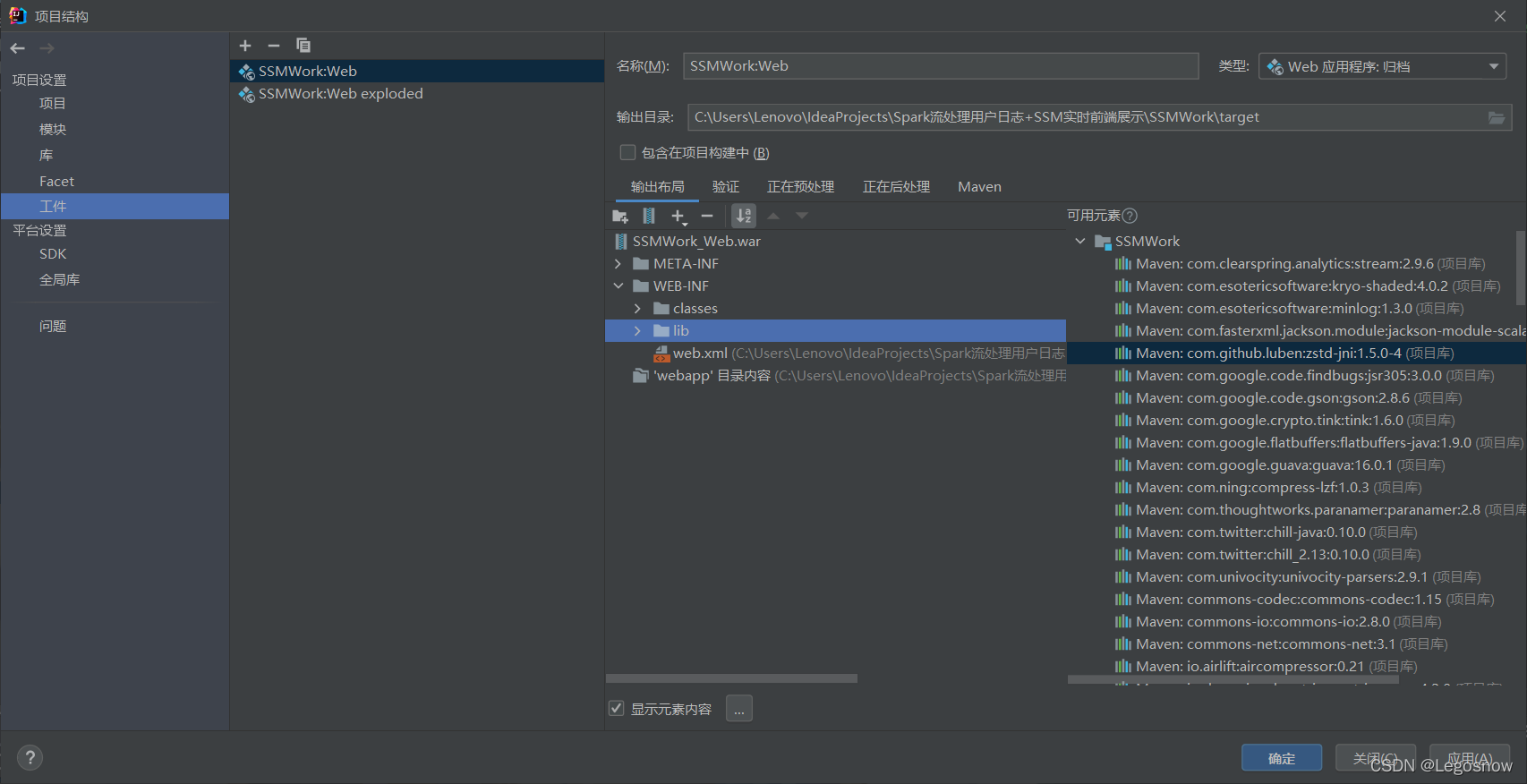
进入编辑配置,添加工件,大致配置如下,删除“部署”中“应用程序上下文”的地址

5.效果展示
运行tomcat服务器后,默认先打开index.jsp网页,显示内容则表示tomcat配置没问题

在url地址栏输入/courseClcik或者/searchClick显示如下
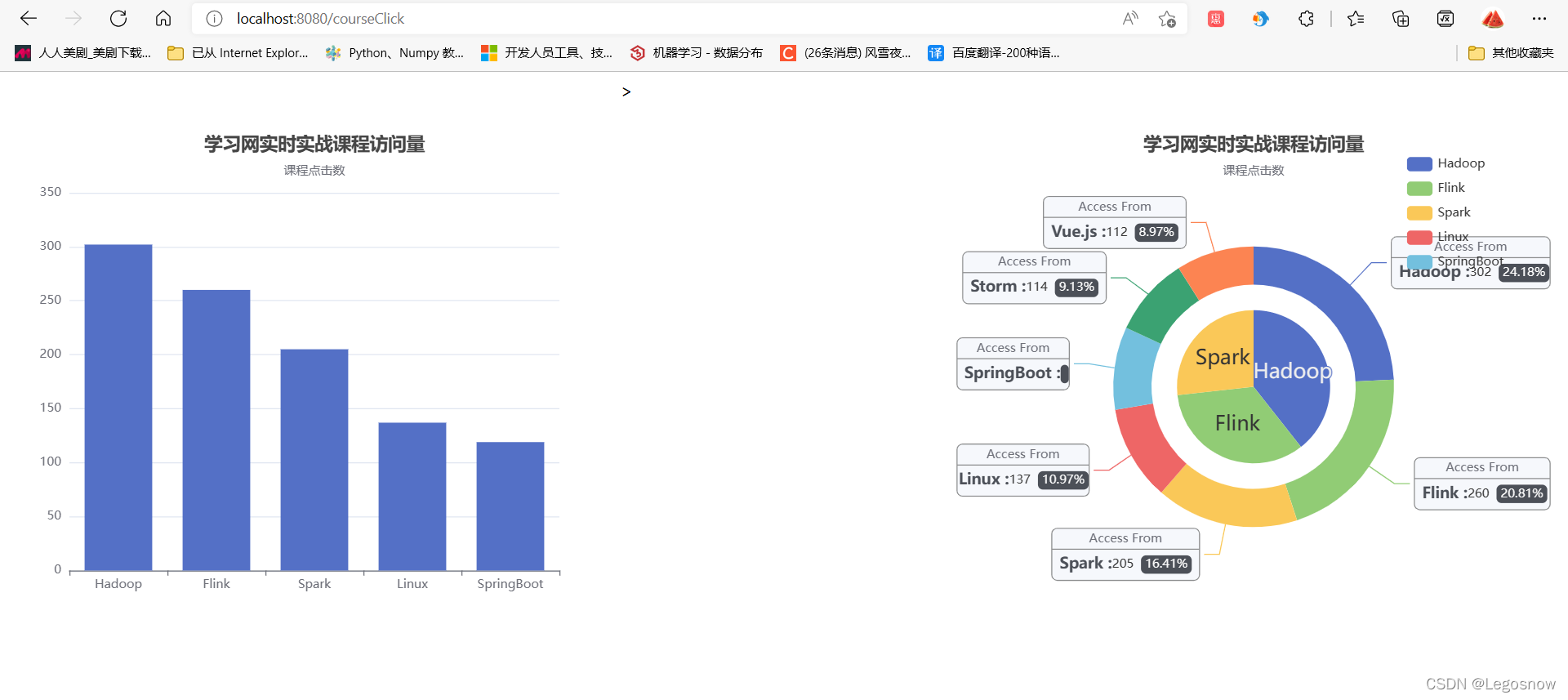
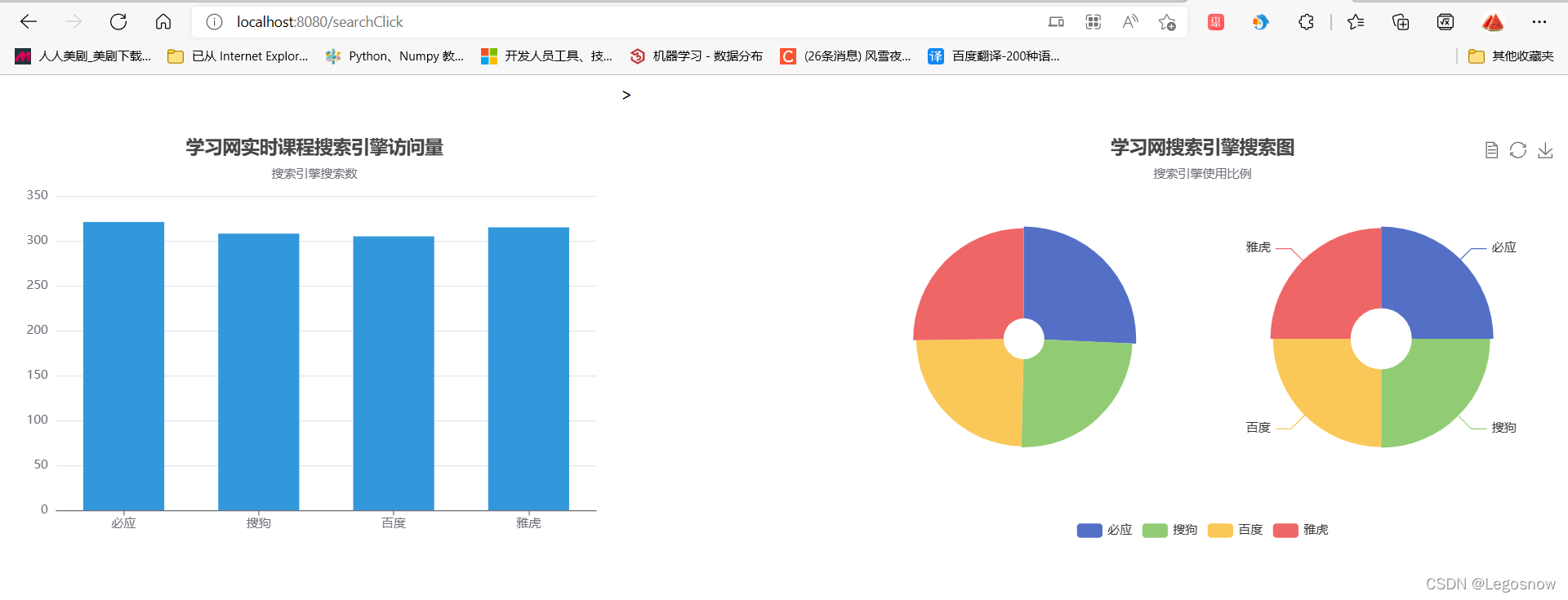
网站默认10s刷新一次,此时开启scala目录的三个进程,再开启python脚本,页面便可以10秒更新一次数据,从而达到实时数据的展示
版权归原作者 Legosnow 所有, 如有侵权,请联系我们删除。