
Windows下的CUDA环境配置
一、查看自己电脑的显卡信息
- 使用
win+R打开运行窗口,在运行窗口中输入cmd打开命令行 - 在命令行中键入
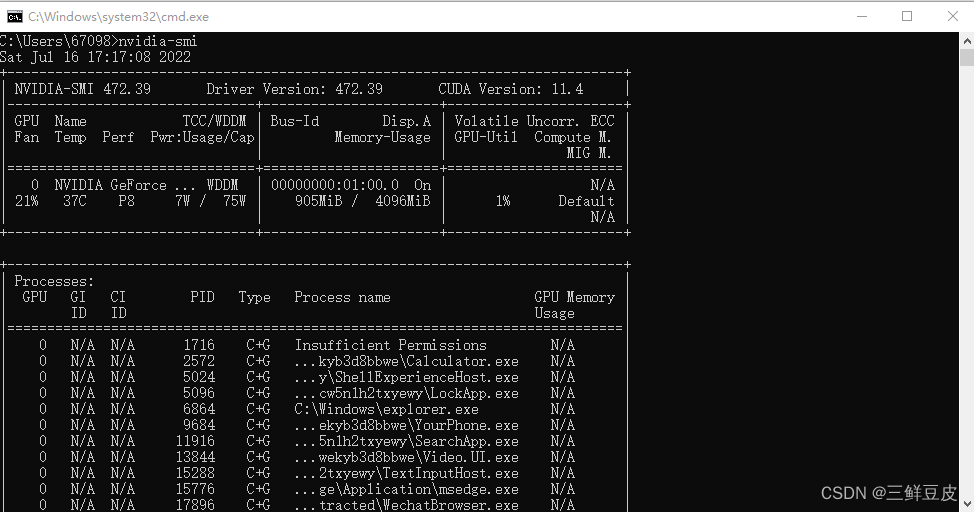
nvidia-smi查看显卡支持信息 - 从下图中可以看到,本机显卡的显卡驱动版本为:472.39;CUDA支持版本为:11.4
二、下载CUDA工具包
- 在查看完电脑的显卡信息后,需要对显卡驱动版本和CUDA版本对应的CUDA Toolkit工具包进行确认.
- 前往NVIDIA官网的官方文档:Release Notes :: CUDA Toolkit Documentation (nvidia.com)查看对应的信息.下载的CUDA Toolkit版本不能高于显卡自身的CUDA 版本.以笔者电脑为例则不能下载高于11.4版本的CUDA Toolkit工具包.除此之外,在官方文档(table 1;table 2)中核对本机的显卡驱动版本是否想要下载的CUDA Toolkit版本的要求
- 核对完成后,前往NVIDIA官网下载对应版本的CUDA工具包:CUDA Toolkit Archive | NVIDIA Developer
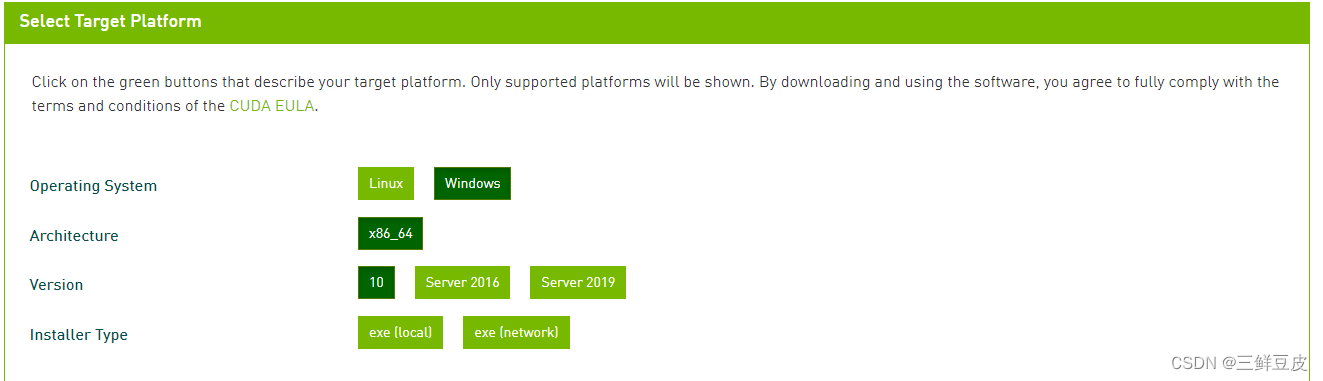 - 选择Windows环境下的CUDA安装包.安装包类型有两类:一类是
- 选择Windows环境下的CUDA安装包.安装包类型有两类:一类是local,另一类是network.-local版本包含了CUDA Toolkit中的所有组件,是一个离线安装包.-network版本是一个通过网络的安装程序,可以自由选择想要下载的CUDA Toolkit组件.- 联网环境下一般选择下载network版本的安装包 - 本文以
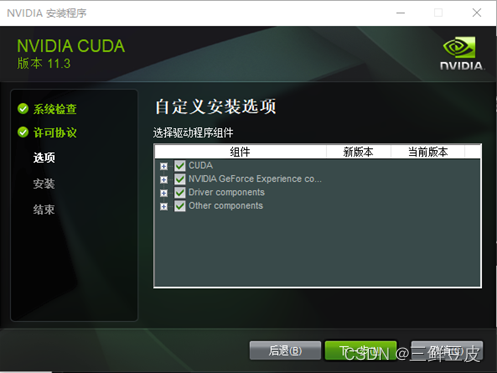
network版本的安装程序为例,下载完成后运行可执行程序,按照提示步骤进行安装即可 - 安装路径设置为默认路径
三、配置系统环境变量
- 安装完成后,以win10系统为例.右键:“此电脑”->“属性”,选择高级系统设置,如下图所示

- 选择"高级"中的"环境变量",开始设置环境变量
- 安装完成后,系统环境变量中自动被添加上了如下所示的两个环境变量(版本号对应用户所下载的版本号):
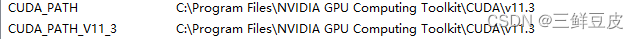
- 用户需要手动添加以下的环境变量:
CUDA_BIN_PATH=%CUDA_PAT%\bin
CUDA_LIB_PATH=%CUDA_PATH%\lib\x64
CUDA_SDK_BIN_PATH=%CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH=%CUDA_SDK_PATH%\common\lib\x64
CUDA_SKD_PATH=C:\ProgramData\NVIDIA Corporation\CUDA Sample\v11.3
- 添加上上述环境变量后,在系统环境变量
Path中添加下列路径:
%CUDA_BIN_PATH%
%CUDA_LIB_PATH%
%CUDA_SDK_BIN_PATH%
%CUDA_SDK_LIB_path%
四、查看CUDA是否安装成功
- 在命令行中输入:
nvcc --version查看nvcc编译器版本,如下图所示
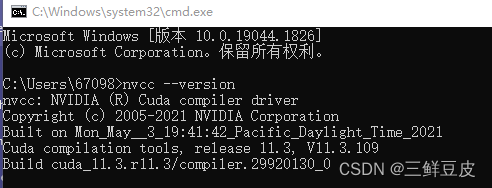
- 在命令行中输入
set cuda,查看设置的环境变量情况.如下所示:

- 验证
deviceQuery.exe与bandwidthTest.exe两个可执行程序是否能够正常运行.默认安装路径下,两个可执行程序的路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\extras\demo_suite. - 在命令行中运行上述两个可执行程序,运行结果为
result=PASS则说明CUDA安装成功,如下所示:


五、在VS2019下配置CUDA调试环境
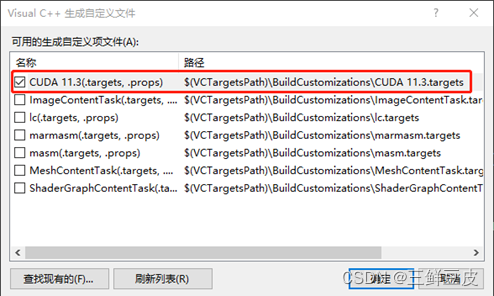
- 打开VS2019,新建空项目,右键项目,选择“生成依赖项”,选择“生成自定义”,在"生成自定义"中勾选"CUDA",如下所示:
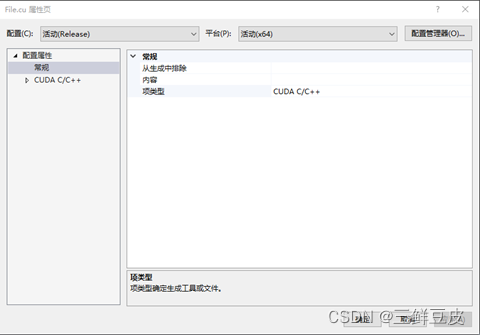
- 在空项目中新建后缀为
.cu的源文件.右键该文件,选择"属性"->“常规”->“项类型”.将"项类型设置为:CUDA C/C++.如下所示:
- 完成上述步骤后进行项目配置.右键项目,选择属性.配置选所有配置(即debug和Realise配置一致).
- 然后分平台(x64和win32)分别进行配置
- x64平台下的配置- 包含目录配置- 项目->“属性”->“配置属性”->“VC++目录”->"包含目录- 添加包含目录:
$(CUDA_PATH)\include- 库目录配置- “VC++目录”->“库目录”- 添加库目录:$(CUDA_PATH)\lib\x64- 依赖项- “配置属性”->“链接器”->“输入”->“附加依赖项”- 添加库文件(库文件数量较多,默认存储路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64,可在该路径下自己添加依赖项):cublas.libcuda.libcudadevrt.libcudart.libcudart_static.libOpenCL.lib - Win32平台下的配置- 包含目录与x64相同- 库目录配置- 添加库目录:
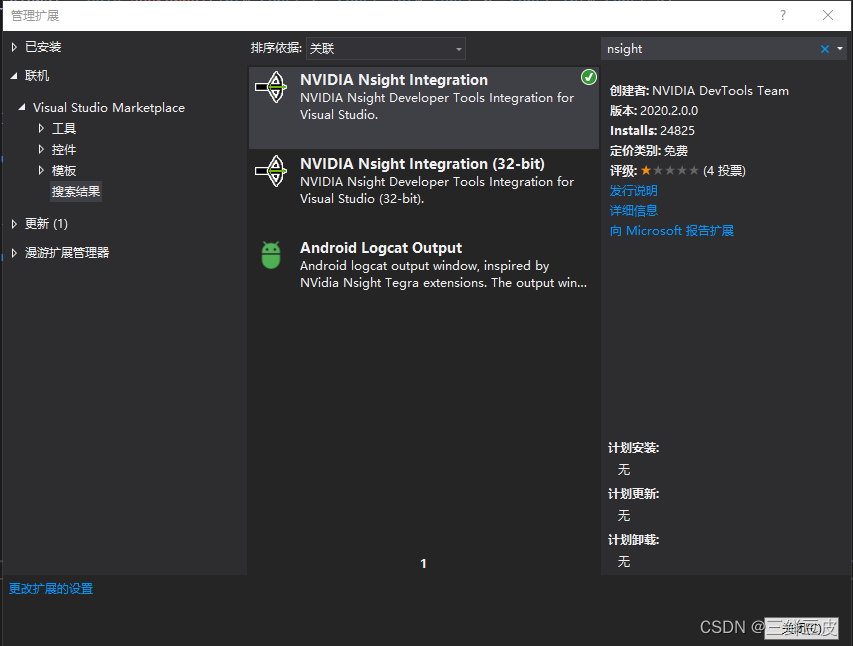
$(CUDA_PATH)\lib\Win32- 依赖项- 添加库文件(Win32平台与x64平台的库文件不相同):cuda.libcudadevrt.libcudart.libcudart_static.libOpenCL.lib - 配置VS2019下的NsightGPU代码编译器- 在VS2019的"扩展"->“管理扩展"中联机搜索"nsight”,下载"NVIDIA Nsight Intergration"的扩展组件,用于在VS中调试GPU代码.如下所示.
- 拓展下载完成后,可以使用该扩展对GPU代码进行编程. - 在GPU的核函数中添加断点,点击"Start CUDA Debugging(Next-Gen)"便可进入GPU代码的调试,调试过程与VS调试CPU代码相同- 使用"CUDA Debugging"只能对GPU部分的代码进行调试,即只能对核函数进行调试,不能对CPU代码进行调试- 使用VS2019中的"本地Windows调试器"**只能对CPU部分的代码进行调试,无法调试GPU部分的代码
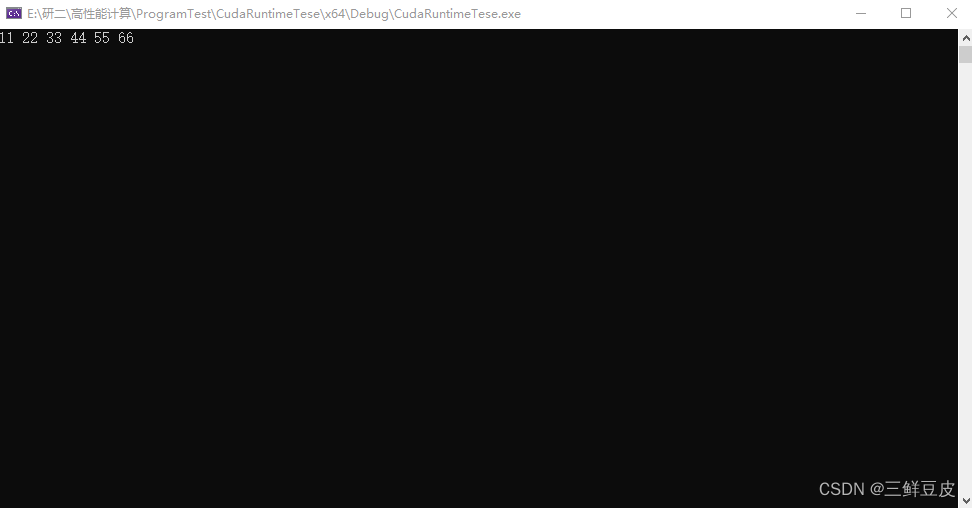
- 使用下面给出的测试程序进行测试,查看能否正常运行.- 运行结果如下所示
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<iostream>
#include <stdio.h>
using namespace std;
constexpr size_t MAXSIZE = 20;
__global__ void addKernel(int* const c, const int* const b, const int* const a)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
constexpr size_t length = 6;
int host_a[length] = { 1,2,3,4,5,6 };
int host_b[length] = { 10,20,30,40,50,60 };
int host_c[length];
//为三个向量在GPU上分配显存
int* dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_c, length * sizeof(int));
cudaMalloc((void**)&dev_a, length * sizeof(int));
cudaMalloc((void**)&dev_b, length * sizeof(int));
//将主机端的数据拷贝到设备端
cudaMemcpy(dev_a, host_a, length * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, host_b, length * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_c, host_c, length * sizeof(int), cudaMemcpyHostToDevice);
//在GPU上运行核函数,每个线程进行一个元素的计算
addKernel << <1, length >> > (dev_c, dev_b, dev_a);
//将设备端的运算结果拷贝回主机端
cudaMemcpy(host_c, dev_c, length * sizeof(int), cudaMemcpyDeviceToHost);
//释放显存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
for (int i = 0; i < length; ++i)
cout << host_c[i] << " ";
cout << endl;
getchar();
system("pause");
return 0;
}
//释放显存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
for (int i = 0; i < length; ++i)
cout << host_c[i] << " ";
cout << endl;
getchar();
system("pause");
return 0;
}
本文转载自: https://blog.csdn.net/weixin_43788327/article/details/125823507
版权归原作者 三鲜豆皮 所有, 如有侵权,请联系我们删除。
版权归原作者 三鲜豆皮 所有, 如有侵权,请联系我们删除。