
Spark on Yarn安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
1、从宿主机/opt目录下将文件spark-3.1.1-bin-hadoop3.2.tgz复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将Spark包解压到/opt/module路径中(若路径不存在,则需新建),将完整解压命令复制粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
步骤1:复制和解压Spark安装包
解压文件:将Spark安装包解压到/opt/module目录中。
tar-zxvf /opt/software/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module

2、修改容器中/etc/profile文件,设置Spark环境变量并使环境变量生效,在/opt目录下运行命令spark-submit --version,将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
编辑profile文件:使用vi或nano编辑器打开/etc/profile文件。
vim /etc/profile
设置环境变量:在文件末尾添加Spark环境变量。
exportSPARK_HOME=/opt/module/spark-3.1.1-bin-hadoop3.2
exportPATH=$PATH:$SPARK_HOME/bin
使环境变量生效:运行以下命令使环境变量立即生效。
source /etc/profile
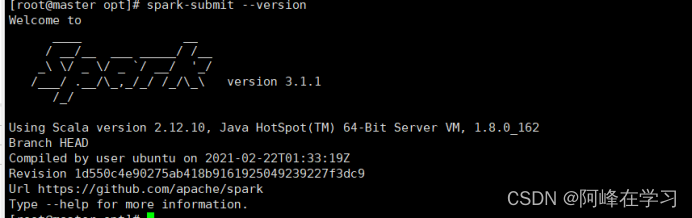
验证环境变量:在/opt目录下运行spark-submit --version命令,并截图。
cd /opt
spark-submit --version
-----运行截图
3、完成on yarn相关配置,使用spark on yarn 的模式提交$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar 运行的主类org.apache.spark.examples.SparkPi,将运行结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下(截取Pi结果的前后各5行)。
(运行命令为:spark-submit --master yarn --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar)
集群模式来运行一个示例程序。Yarn是Hadoop的一个组件,它用于作业调度和集群资源管理。在Spark中,当使用Yarn模式时,Spark应用程序的调度和资源管理由Yarn来处理。
以下是步骤3的详细解释:
1、提交作业:
使用spark-submit命令来提交作业。这个命令是用来启动Spark应用程序的。
–master yarn参数指定了作业应该以Yarn模式运行。这意味着Spark应用程序将使用Yarn来管理资源。
–class org.apache.spark.examples.SparkPi参数指定了包含应用程序主类的jar文件。在这个例子中,主类是org.apache.spark.examples.SparkPi,它是一个计算Pi值的示例程序。
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar是包含示例程序的jar文件路径。
查看运行结果:
一旦作业提交,Yarn将负责启动必要的Spark驱动程序和执行器进程。
SparkPi程序将运行,并计算Pi的近似值。
程序运行完成后,会在控制台输出计算结果。通常,结果会包括Pi的近似值以及计算所需的时间。
使用spark-submit命令以Yarn模式提交SparkPi示例程序。
spark-submit --masteryarn--class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar
运行结果
版权归原作者 阿峰在学习 所有, 如有侵权,请联系我们删除。