
3 UDF 接口与富函数
3.1 使用 UDF 函数
Flink 作业的数据流中的主要操作大部分都需要 UDF(user defined functions,用户自定义函数)。
3.1.1 使用普通 UDF 接口
实现 UDF 最基本的方法是实现 Flink 提供的接口。在 Java 具体实现时,可以使用实现接口、匿名类或 lambda 语法实现。
样例|实现
MapFunction
接口,将字符串转化为整数,并在 DataStream API 中使用
// 实现 MapFunction 接口classMyMapFunctionimplementsMapFunction<String,Integer>{publicIntegermap(String value){returnInteger.parseInt(value);}}// 在 DataStream API 中使用实现接口的类
data.map(newMyMapFunction());
样例|在 DataStream API 中直接使用匿名类
data.map(newMapFunction<String,Integer>(){publicIntegermap(String value){returnInteger.parseInt(value);}});
样例|在 DataStream API 中使用 lambda 表达式语法
data.filter(s -> s.startsWith("http://"));
data.reduce((i1,i2)-> i1 + i2);
对于 UDF 接口的详细介绍,详见 3.2。
3.1.2 使用富函数
几乎所有
Function
接口的子接口,都有其富函数(Rich Function)版本;在富函数中,可以在获取运行状态的上下文,从而支持使用状态,从而支持实现更复杂的功能。
要使用富函数,只需要将实现
Function
子接口改为继承富函数版本的抽象类即可,在使用中,与使用非富函数一样,直接传给 DataStream API 即可。
样例|将非富函数版本的
MyMapFunction
替换为富函数版本
// 非 rich 版本classMyMapFunctionimplementsMapFunction<String,Integer>{publicIntegermap(String value){returnInteger.parseInt(value);}}// rich 版本classMyMapFunctionextendsRichMapFunction<String,Integer>{publicIntegermap(String value){returnInteger.parseInt(value);}}// 使用 UDF
data.map(newMyMapFunction());
样例|使用匿名类的方式定义富函数
data.map (newRichMapFunction<String,Integer>(){publicIntegermap(String value){returnInteger.parseInt(value);}});
对于富函数的详细介绍,详见 3.3。
3.2
Function
接口的源码
在 3.1.1 例中的
MapFunction
接口是
Function
接口的子接口。
Function
接口是所有 UDF 函数的父接口,在
Function
接口中没有任何方法,以便允许继承的扩展接口能够使用 Java 8 的 lambda 语法实现。
源码|Github|
org.apache.flink.api.common.functions.Function
@PublicpublicinterfaceFunctionextendsjava.io.Serializable{}
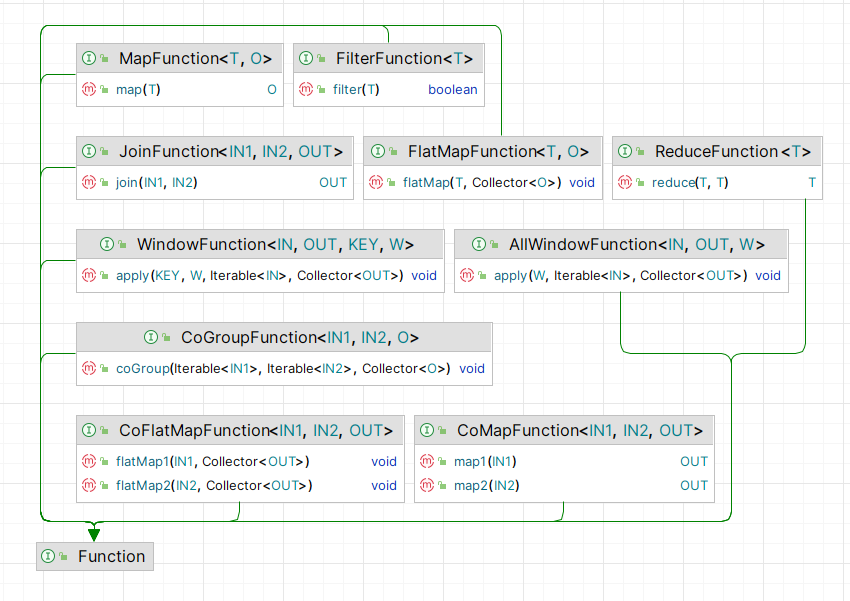
3.2.1 处理普通数据流
3.2.1.1
MapFunction
(1 个输入,1 个输出)
输入 1 个
T
类型的记录,输出 1 个
O
类型的记录。
源码|Github|
org.apache.flink.api.common.functions.MapFunction
@Public@FunctionalInterfacepublicinterfaceMapFunction<T,O>extendsFunction,Serializable{Omap(T value)throwsException;}
3.2.1.2
FlatMapFunction
(1 个输入,任意输出)
输入 1 个
T
类型的记录,输出 0 个、1 个或多个
O
类型的记录。
可以将调用
out.collect()
方法向输出流写入元素。
源码|Github|
org.apache.flink.api.common.functions.FlatMapFunction
@Public@FunctionalInterfacepublicinterfaceFlatMapFunction<T,O>extendsFunction,Serializable{voidflatMap(T value,Collector<O> out)throwsException;}
3.2.1.3
FilterFunction
(1 个输入,0 或 1 个输出)
输入 1 个
T
类型的记录,输出 0 条或 1 条
T
类型的记录。
Filter
为每一条元素执行一个返回布尔值的函数
filter(T value)
,并保留函数返回值为
true
的元素。
源码|Github|
org.apache.flink.api.common.functions.FilterFunction
@Public@FunctionalInterfacepublicinterfaceFilterFunction<T>extendsFunction,Serializable{booleanfilter(T value)throwsException;}
3.2.1.4
ReduceFunction
(多个输入,1 个输出)
输入 2 个
T
类型的记录,输出 1 个
T
类型的记录。
可以在数据流上滚动执行 reduce,不断将当前元素与最后一次 reduce 得到的值进行合并得到新值。
源码|Github|
org.apache.flink.api.common.functions.ReduceFunction
@Public@FunctionalInterfacepublicinterfaceReduceFunction<T>extendsFunction,Serializable{Treduce(T value1,T value2)throwsException;}
3.2.2 处理窗口
3.2.2.1
WindowFunction
(监控窗口)
适用于键控窗口(keyed / grouped windows)。输入 1 个或多个
IN
类型的记录,输出 0 个、1 个或多个
OUT
类型的元素。
WindowFunction
接口只有 1 个
apply()
方法,其中包含如下 4 个参数:当前键控窗口的
KEY
类型键值,
W
类型的窗口,窗口中的所有
IN
类型元素的迭代器,以及接收
OUT
类型的输出流元素的迭代器。
源码|Github|
org.apache.flink.streaming.api.functions.windowing.WindowFunction
@PublicpublicinterfaceWindowFunction<IN, OUT, KEY,WextendsWindow>extendsFunction,Serializable{voidapply(KEY key,W window,Iterable<IN> input,Collector<OUT> out)throwsException;}
3.2.2.2
AllWindowFunction
(全局窗口)
适用于全局窗口。输入 1 个或多个
IN
类型的记录,输出 0 个、1 个或多个
OUT
类型的元素。
AllWindowFunction
接口也只有 1 个
apply()
方法,其中包含 3 个参数,与
WindowFunction
中的含义一致。
源码|Github|
org.apache.flink.streaming.api.functions.windowing.AllWindowFunction
@PublicpublicinterfaceAllWindowFunction<IN, OUT,WextendsWindow>extendsFunction,Serializable{voidapply(W window,Iterable<IN> values,Collector<OUT> out)throwsException;}
3.2.3 处理多个数据流
3.2.3.1
JoinFunction
(以成功关联的记录为单位)
输入两个数据流中的各 1 个记录,其类型分别为
IN1
和
IN2
,输出 1 个
OUT
类型的元素。
使用
JoinFunction
关联 2 个数据流,当且仅当成功关联时,
JOIN
方法才会被调用。
JoinFunction
接口只有 1 个
apply()
方法,其中参数
first
为第 1 个数据流中的元素,参数
second
为第 2 个数据流中的元素,这 2 个元素是相互成功关联的。
源码|Github|
org.apache.flink.api.common.functions.JoinFunction
@Public@FunctionalInterfacepublicinterfaceJoinFunction<IN1, IN2, OUT>extendsFunction,Serializable{OUTjoin(IN1 first,IN2 second)throwsException;}
3.2.3.2
CoGroupFunction
(处理窗口为单位)
适用于键控窗口。输入 当前窗口中 第 1 个数据流中所有
IN1
类型元素的迭代器和第 2 个数据流中所有
IN2
类型元素的迭代器,输出 0 个、1 个或多个
OUT
类型的元素。
源码|Github|
org.apache.flink.api.common.functions.CoGroupFunction
@Public@FunctionalInterfacepublicinterfaceCoGroupFunction<IN1, IN2,O>extendsFunction,Serializable{voidcoGroup(Iterable<IN1> first,Iterable<IN2> second,Collector<O> out)throwsException;}
3.2.3.3
CoMapFunction
(处理 2 个数据流,1 个输入,1 个输出)
适用于 “连接” 后的数据流。在 “连接” 后的数据流中,2 个数据流保留各自的类型,但允许两个流的处理逻辑之间共享状态。
输入来自第 1 个数据流的 1 个
IN1
类型元素或输入来自第 2 个数据流的 1 个
IN2
类型元素,输出 1 个
OUT
类型元素。
源码|Github|
org.apache.flink.streaming.api.functions.co.CoMapFunction
@PublicpublicinterfaceCoMapFunction<IN1, IN2, OUT>extendsFunction,Serializable{OUTmap1(IN1 value)throwsException;OUTmap2(IN2 value)throwsException;}
当接收到来自第 1 个数据流的记录时,
map1(IN1 value)
方法将被调用;当接收到来自第 2 个数据流的记录时,
map2(IN2 value)
方法将被调用。
3.2.3.4
CoFlatMapFunction
(处理 1 个数据流,1 个输出,任意输出)
与
CoMapFunction
类似,适用于 “连接” 后的数据流。与
CoMapFunction
区别类似于
FlatMapFunction
与
MapFunction
的区别。
源码|Github|
org.apache.flink.streaming.api.functions.co.CoFlatMapFunction
@PublicpublicinterfaceCoFlatMapFunction<IN1, IN2, OUT>extendsFunction,Serializable{voidflatMap1(IN1 value,Collector<OUT> out)throwsException;voidflatMap2(IN2 value,Collector<OUT> out)throwsException;}
3.3 富函数的源码
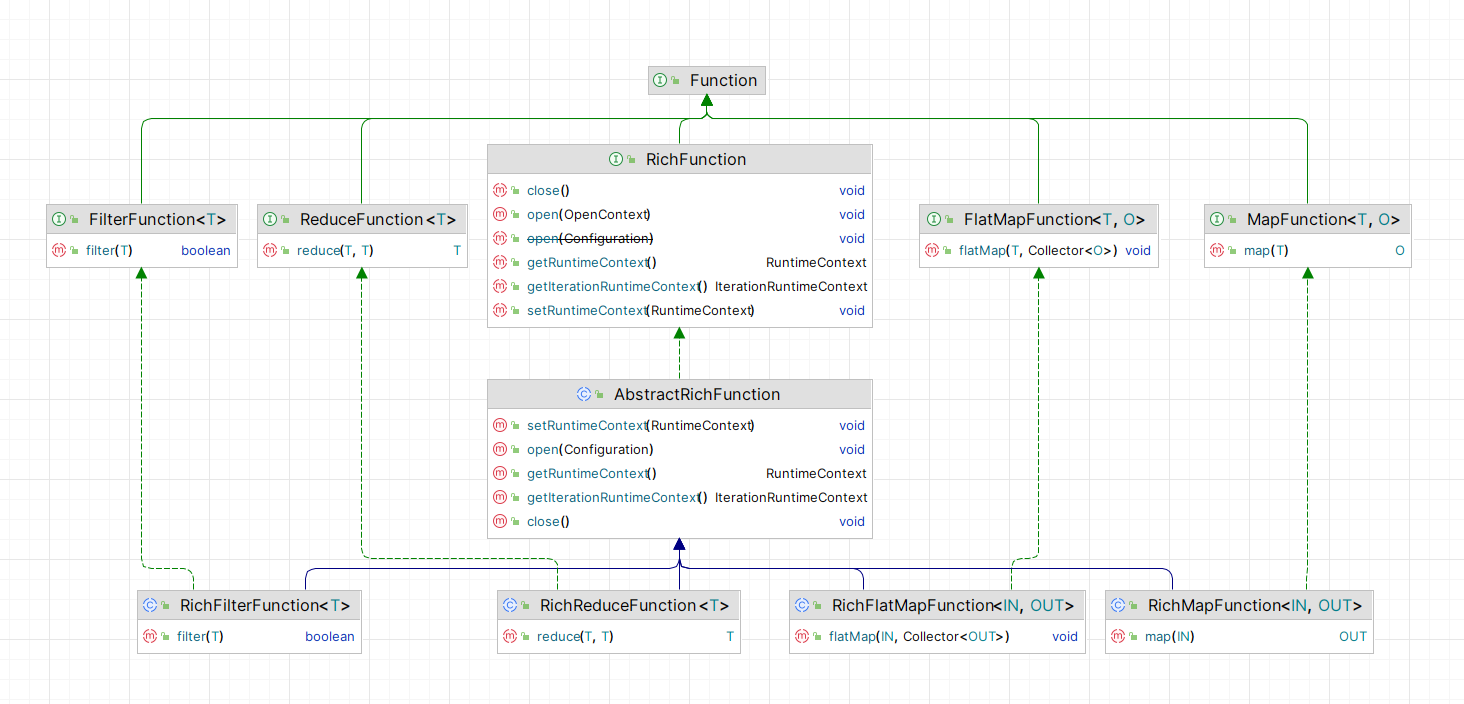
上图为仅包含
Mapfunction
、
FlatMapFunction
、
FilterFunction
和
RedeuceFunction
作为样例的 Rich Function 的 UML 图。每个
Function
子接口的 Rich 版本,都是实现了该接口的抽象类,同时,这些抽象类都继承了
AbstractRichFunction
。
下面我们逐个了解
RichFunction
接口、
AbstractRichFunction
抽象类以及
Function
子接口的 rich 版本。
3.3.1
RichFunction
接口
RichFunction
接口是用于所有 Rich UDF 的基础接口,其中定义了函数的生命周期方法以及访问函数执行上下文的方法。具体地,包含如下方法:
open(Configuration parameters):初始化Function的方法。这个方法将在类似于map、flatMap等主方法(working methods)之前被调用,适合于执行一次性的初始化工作,其参数parameters中包含着配置信息。open(OpenContext openContext):默认方法,与open(Configuration parameters)类似,但是其配置信息包含于openContext中。默认使用空的Configuration作为参数调用open(Configuration parameters)。close():关闭Function的方法。这个方法将在最后一次调用主方法之后被调用,适合于清理运行垃圾。getRuntimeContext():获取 UDF 当前运行的上下文信息对象RuntimeContext,例如当前Function的并行度,当前 subtask 的 index,当前 task 名称等。getIterationRuntimeContext():当且仅当当前Function是迭代(iteration)的一部分时可用,返回多个RuntimeContext的迭代器。setRuntimeContext(RuntimeContext t):设置 UDF 的上下文信息,仅被框架在创建Function的并行实例时调用。
对于
RuntimeContext
的介绍详见 3.4。
源码|Github|
org.apache.flink.api.common.functions.RichFunction
(无注释)
@PublicpublicinterfaceRichFunctionextendsFunction{@Deprecatedvoidopen(Configuration parameters)throwsException;@PublicEvolvingdefaultvoidopen(OpenContext openContext)throwsException{open(newConfiguration());}voidclose()throwsException;RuntimeContextgetRuntimeContext();IterationRuntimeContextgetIterationRuntimeContext();voidsetRuntimeContext(RuntimeContext t);}
接口中需要实现的方法包括:
open(Configuration parameters)
、
close()
、
getRuntimeContext()
、
getIterationRuntimeContext()
和
setRuntimeContext(RuntimeContext t)
。
3.3.2
AbstractRichFunction
抽象类
AbstractRichFunction
抽象类实现了
RichFunction
接口,添加了存储上下文信息的、不参与系列化的私有对象属性
runtimeContext
,实现了接口中所有 5 个非默认方法:
open(Configuration parameters):不执行任何操作close():不执行任何操作getRuntimeContext()和getIterationRuntimeContext():检查表行返回对象属性runtimeContextsetRuntimeContext(RuntimeContext t):设置对象属性runtimeContext
源码|Github|
org.apache.flink.api.common.functions.AbstractRichFunction
(部分)
@PublicpublicabstractclassAbstractRichFunctionimplementsRichFunction,Serializable{privatetransientRuntimeContext runtimeContext;@OverridepublicvoidsetRuntimeContext(RuntimeContext t){this.runtimeContext = t;}@OverridepublicRuntimeContextgetRuntimeContext(){if(this.runtimeContext !=null){returnthis.runtimeContext;}else{thrownewIllegalStateException("The runtime context has not been initialized.");}}@OverridepublicIterationRuntimeContextgetIterationRuntimeContext(){if(this.runtimeContext ==null){thrownewIllegalStateException("The runtime context has not been initialized.");}elseif(this.runtimeContext instanceofIterationRuntimeContext){return(IterationRuntimeContext)this.runtimeContext;}else{thrownewIllegalStateException("This stub is not part of an iteration step function.");}}@Overridepublicvoidopen(Configuration parameters)throwsException{}@Overridepublicvoidclose()throwsException{}}
3.3.3
Function
子接口的 Rich 版本
因为
Function
子接口的 Rich 版本实现了非 Rich 版本的接口,并继承了
AbstractRichFunction
抽象类,所以通常不需要添加额外的方法,只需要将非 Rich 版本接口中的方法改写为抽象方法即可。例如
MapFunction
:
源码|Github|
org.apache.flink.api.common.functions.RichMapFunction
@PublicpublicabstractclassRichMapFunction<IN, OUT>extendsAbstractRichFunctionimplementsMapFunction<IN, OUT>{privatestaticfinallong serialVersionUID =1L;@OverridepublicabstractOUTmap(IN value)throwsException;}
3.4
RuntimeContext
每个并行的实例都会包含一个
RuntimeContext
。
RuntimeContext
接口包含函数执行的上下文信息,主要用于富函数,提供了如下功能:
- 访问静态上下文信息(例如当前并行度)
- 添加及访问累加器
- 访问外部资源信息
- 访问广播变量和分布式缓存
- 访问并编辑状态
下面,我们逐类介绍
RuntimeContext
接口的方法。

3.4.1 访问静态上下文信息
RuntimeContext
的包括如下获取静态上下文信息的方法:
getJobId():获取当前作业的 ID。getTaskName():获取执行 UDF 的 task 名称。getMetricGroup():获取当前 subtask 的指标组。getNumberOfParallelSubtasks():获取执行 UDF 的 task 的并行度。getMaxNumberOfParallelSubtasks():获取执行 UDF 的 task 的最大并行度。getIndexOfThisSubtask():获取执行 UDF 的 subtask 的编号(编号从 0 开始)。getAttemptNumber():获取执行 UDF 的 subtask 的尝试次数(第一次尝试的次数是 0)。getTaskNameWithSubtasks():获取执行 UDF 的 subtask 的名称。这个名称如下{任务名称} ({subtask的编号}/{并行度})#{尝试次数},例如MyTask (3/6)#1,其中{任务名称}为getTaskName()的返回值,{subtask的编号}为getIndexOfThisSubtask() + 1,{并行度}为getNumberOfParallelSubtasks()的返回值,{尝试次数}为getAttemptNumber()的返回值。getExecutionConfig():获取当前作业的执行配置。createSerializer(TypeInformation<T> typeInformation):获取指定类型的序列化器。getGlobalJobParameters():获取作业的全局参数。isObjectReuseEnabled():获取对象重用是否开启。getUserCodeClassLoader():获取用户类(不在系统 classpath 的类)的加载器。registerUserCodeClassLoaderReleaseHookIfAbsent(String releaseHookName, Runnable releaseHook):在用户类加载器中注册自定义 hook。
大概可以归纳为如下几种类型
- 作业、task、subtask 的基本信息及尝试次数
- 指标组信息
- 包括序列化器和类加载器在内的配置信息
源码|Github|
org.apache.flink.api.common.functions.RuntimeContext
(部分)
JobIDgetJobId();StringgetTaskName();@PublicEvolvingOperatorMetricGroupgetMetricGroup();intgetNumberOfParallelSubtasks();@PublicEvolvingintgetMaxNumberOfParallelSubtasks();intgetIndexOfThisSubtask();intgetAttemptNumber();StringgetTaskNameWithSubtasks();@DeprecatedExecutionConfiggetExecutionConfig();@PublicEvolving<T>TypeSerializer<T>createSerializer(TypeInformation<T> typeInformation);@PublicEvolvingMap<String,String>getGlobalJobParameters();@PublicEvolvingbooleanisObjectReuseEnabled();ClassLoadergetUserCodeClassLoader();@PublicEvolvingvoidregisterUserCodeClassLoaderReleaseHookIfAbsent(String releaseHookName,Runnable releaseHook);
3.4.2 添加及访问累加器
RuntimeContext
的包括如下累加器相关的方法:
addAccumulator(String name, Accumulator<V, A> accumulator):添加累加器Accumulator<V, A> getAccumulator(String name):获取基础类型的累加器getIntCounter(String name):获取IntCounter类型的累加器getLongCounter(String name):获取LongCounter类型的累加器getDoubleCounter(String name):获取DoubleCounter类型的累加器getHistogram(String name):获取直方图类型的累加器
源码|Github|
org.apache.flink.api.common.functions.RuntimeContext
(部分)
<V,AextendsSerializable>voidaddAccumulator(String name,Accumulator<V,A> accumulator);<V,AextendsSerializable>Accumulator<V,A>getAccumulator(String name);@PublicEvolvingIntCountergetIntCounter(String name);@PublicEvolvingLongCountergetLongCounter(String name);@PublicEvolvingDoubleCountergetDoubleCounter(String name);@PublicEvolvingHistogramgetHistogram(String name);
3.4.3 访问外部资源
RuntimeContext
提供了
getExternalResourceInfos(String resourceName)
外部资源信息。
源码|Github|
org.apache.flink.api.common.functions.RuntimeContext#getExternalResourceInfos
@PublicEvolvingSet<ExternalResourceInfo>getExternalResourceInfos(String resourceName);
3.4.4 访问广播变量
RuntimeContext
提供了如下访问广播变量的方法:
hasBroadcastVariable(String name):检查是否包含名称为name的广播变量getBroadcastVariable(String name):返回名称为name的广播变量getBroadcastVariableWithInitializer(String name, BroadcastVariableInitializer<T, C> initializer):返回名称为name的广播变量,并使用initializer初始化。getDistributedCache():访问分布式缓存。
源码|Github|
org.apache.flink.api.common.functions.RuntimeContext
(部分)
@PublicEvolvingbooleanhasBroadcastVariable(String name);<RT>List<RT>getBroadcastVariable(String name);<T,C>CgetBroadcastVariableWithInitializer(String name,BroadcastVariableInitializer<T,C> initializer);DistributedCachegetDistributedCache();
3.4.5 访问并编辑状态
RuntimeContext
提供了如下方法用于获取不同类型的状态对象,在获取到状态对象后,可以对状态对象进行编辑:
getState(ValueStateDescriptor<T> stateProperties):获取ValueState类型的状态对象getListState(ListStateDescriptor<T> stateProperties):获取ListState类型的状态对象getReducingState(ReducingStateDescriptor<T> stateProperties):获取ReducingState类型的状态对象getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT> stateProperties):获取AggregatingState类型的状态对象getMapState(MapStateDescriptor<UK, UV> stateProperties):获取MapState类型的状态对象
源码|Github|
org.apache.flink.api.common.functions.RuntimeContext
(部分)
@PublicEvolving<T>ValueState<T>getState(ValueStateDescriptor<T> stateProperties);@PublicEvolving<T>ListState<T>getListState(ListStateDescriptor<T> stateProperties);@PublicEvolving<T>ReducingState<T>getReducingState(ReducingStateDescriptor<T> stateProperties);@PublicEvolving<IN, ACC, OUT>AggregatingState<IN, OUT>getAggregatingState(AggregatingStateDescriptor<IN, ACC, OUT> stateProperties);@PublicEvolving<UK, UV>MapState<UK, UV>getMapState(MapStateDescriptor<UK, UV> stateProperties);
参考文献
- 《Flink 官方文档:应用开发 - DataStream API - 用户自定义 Functions》
版权归原作者 长行 所有, 如有侵权,请联系我们删除。