
第一部分:Spark基础篇_奔跑者-辉的博客-CSDN博客
第二部分:Spark进阶篇_奔跑者-辉的博客-CSDN博客
第三部分:Spark调优篇_奔跑者-辉的博客-CSDN博客
第一部分:Flink基础篇_奔跑者-辉的博客-CSDN博客 (建议收藏)
实时数仓之 Kappa 架构与 Lambda 架构_奔跑者-辉的博客-CSDN博客(建议收藏)
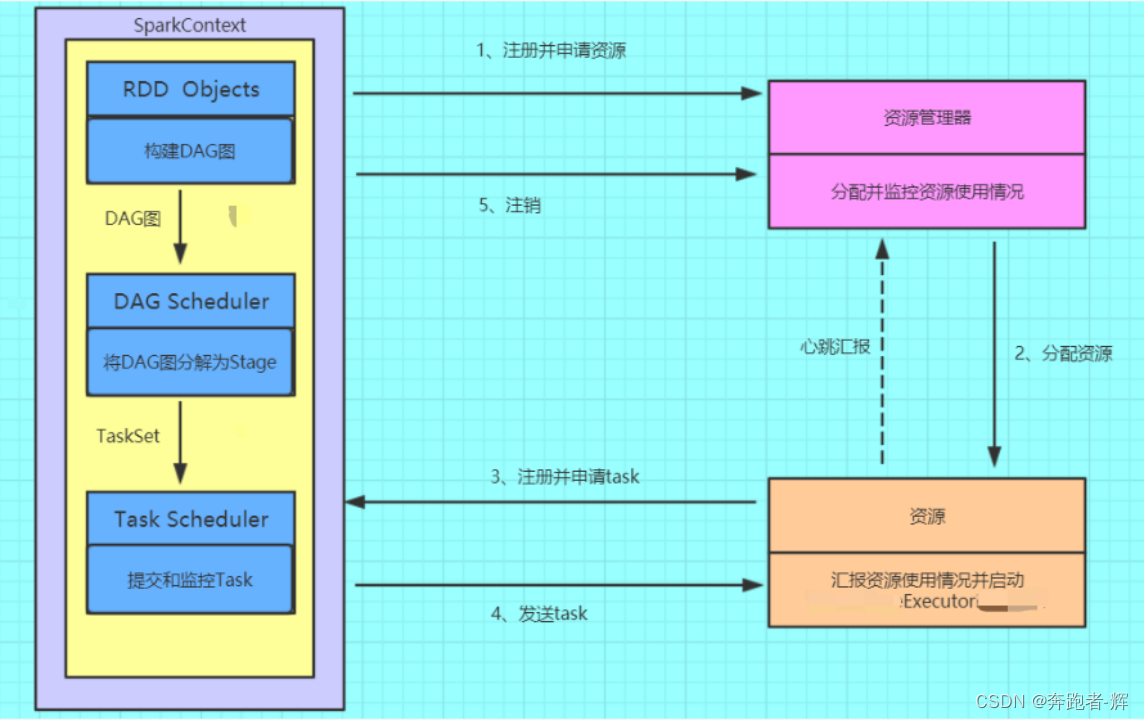
1 Spark作业运行流程
① 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(YARN)注册并申请运行Executor资源;
② 资源管理器分配并启动Executor,Executor的运行情况将随着心跳发送到资源管理器上;
③ SparkContext构建成DAG图,将DAG图分解成Stage(Taskset),并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task;
④ Task Scheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发放给Executor;
⑤ Task在Executor上运行,运行完毕释放所有资源。
2 任务提交四个阶段
① 构建DAG
用户提交的job将首先被转换成一系列RDD,并通过RDD之间的依赖关系构建DAG,然后将DAG提交到调度系统;
② DAG调度
DagSucheduler将DAG切分stage(切分依据是shuffle),将stage中生成的task以taskset的形式发送给TaskScheduler;
③ TaskScheduler调度Task(根据资源情况将task调度到Executors);
④ Executors接收task,然后将task交给线程池执行。
3 Spark运行原理
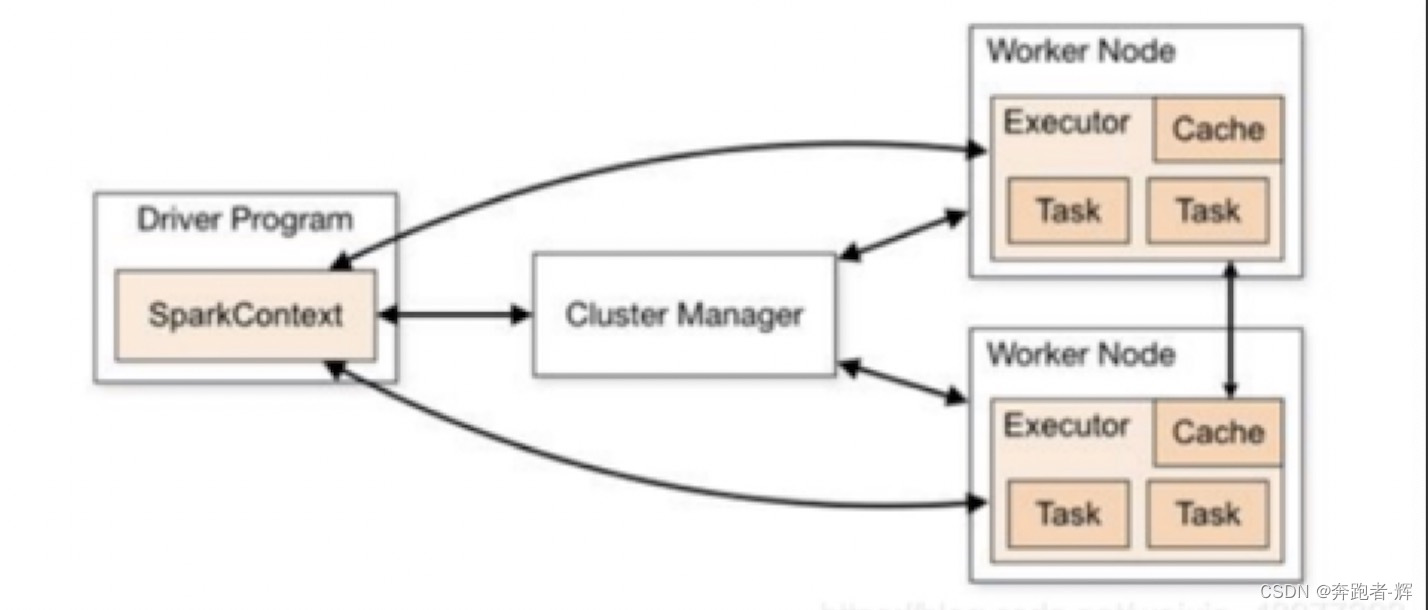
Spark应用程序以"进程集合"为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互的;
① Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等);
② Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor;
③ SparkContext将程序代码(jar包或python文件)和Task任务发送给Executor执行,并收集结果给Driver。
相关组件功能:
master: 管理集群和节点,不参与计算;
worker: 计算节点,进程本身不参与计算,和 master 汇报;
Driver: 运行程序的 main 方法,创建 spark context 对象;
spark context: 控制整个 application 的生命周期,包括 dagsheduler 和 task scheduler 等组件;
client: 用户提交程序的入口。
4 Spark 生态圈都包含哪些组件
如下图所示:
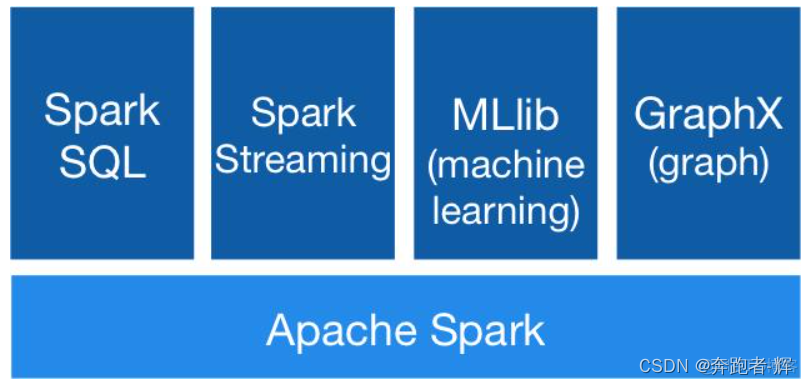
Spark Core:Spark 的核心模块,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等功能;
Spark SQL:主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是 DataFrame,将其作为分布式 SQL 查询引擎,通过将 Spark SQL 转化为 RDD 来执行各种操作;
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API;
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能;
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法;
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算;
Structured Streaming:处理结构化流,统一了离线和实时的 API。
5 Spark 与 Mapreduce 的区别
spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别:
① spark把运算的中间数据(shuffle阶段产生的数据)存放在内存,减少低效的磁盘交互,迭代计算效率更高。mapreduce的中间结果需要落地,保存到磁盘;
② spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,mapreduce的容错只能重新计算;
③ spark是基于内存的分布式计算架构,提供更加丰富的数据集操作类型,主要分成transformation和action两类算子,数据分析更加快速,所以适合低时延环境下计算的应用;
④ spark与hadoop最大的区别在于迭代式计算模型:
mapreduce框架的Hadoop主要分为map和reduce两个阶段,两个阶段完了就结束了,所以在一个job里面能做的处理很有限;
spark计算模型是基于内存的迭代式计算模型,可以分为n个阶段,根据用户编写的RDD算子和程序,在处理完一个阶段后可以继续往下处理很多个阶段,而不只是两个阶段。所以spark相较于mapreduce,计算模型更加灵活,可以提供更强大的功能。
5.1 Spark效率 比 MR更高的原因
① 基于内存计算,减少低效的磁盘交互;
② 高效的调度算法,基于DAG;
③ 容错机制 Linage。
重点部分就是 DAG 和 Lingae
spark就是为了解决mr落盘导致效率低下的问题而产生的,原理还是mr的原理,只是shuffle放在内存中计算了,所以效率提高很多。
5.2 Spark 与 MR的Shuffle的区别
shuffle过程本质:都是将 Map 端获得的数据使用分区机制进行划分,并将数据发送给对应的Reducer 的过程;
相同点: 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer;
不同点:
mapReduce 默认是排序的,spark 默认不排序,除非使用 sortByKey 算子;
mr 落盘,spark 不落盘,spark 可以解决 mr 落盘导致效率低下的问题;
mapReduce 可以划分成 split,map()、spill、merge、shuffle、sort、reduce()等阶段,spark 没有明显的阶段划分,只有不同的 stage 和 算子操作。
6 RDD
6.1 什么是RDD
RDD是弹性分布数据集,是Spark的基本数据结构,它是一个不可变的分布式对象集合,每个数据集被划分为逻辑分区,其可以在集群的不同节点上计算。
6.2 RDD五大属性
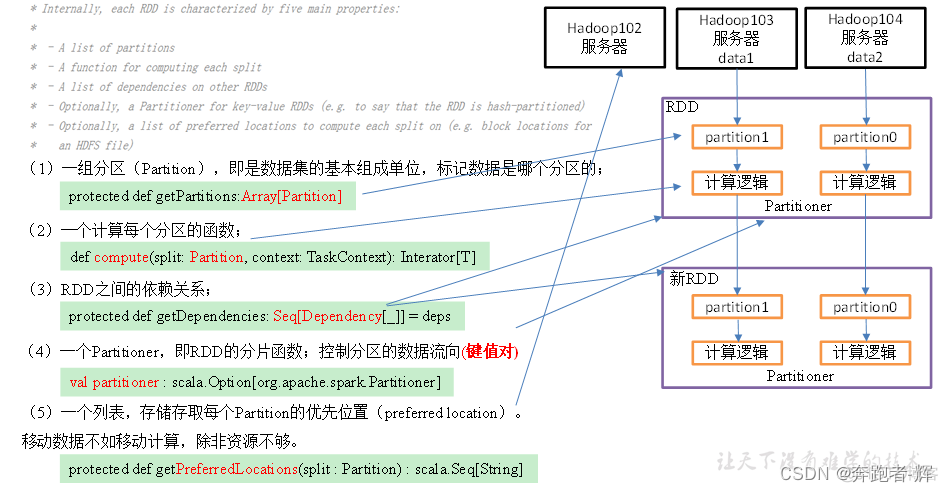
① 1个分区列表: 每一个数据集都对应一个分区,通过getPartitions获取;
② 1个分区计算函数: 真正获取分区数据的函数,函数作用在每一个partition(split)上;
③ 1组依赖关系: 业务逻辑转换,形成依赖表;
④ 1个分区器: 对数据如何分区,默认是hash分区器;
⑤ 1个最优位置列表: 数据在哪里,计算就在哪里。移动数据不如移动计算。(分区计算函数:MapPartition、getPartition)。
6.3 关于弹性
存储的弹性:内存与磁盘的自动切换
容错的弹性:数据丢失可以自动恢复
计算的弹性:计算出错重试机制
分片的弹性:可根据需要重新分片
6.4 RDD特点
① 弹性:可以基于内存、磁盘的存储,数据集可大可小 ;
② 可容错:容错性 (task容错:task失败重试 ,stage容错:stage失败重试 ,RDD本身容错。)
③ 并行处理:数据集可分区并行处理;
④ 不可变:RDD一旦创建是不能更新和删除的,但是可以基于RDD进行计算,获取新的RDD数据集。
6.5 RDD持久化原理
调用cache()和persist()方法即可。cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用persist()的无参版本persist(MEMORY_ONLY),将数据持久化到内存中;
如果需要从内存中清除缓存,可以使用unpersist()方法。RDD持久化是可以手动选择不同的策略的。在调用persist()时传入对应的StorageLevel即可。
6.6 RDD有哪些缺陷
① 不支持细粒度的写和更新操作,spark写数据是粗粒度的。所谓粗粒度,就是批量写入数据,为了提高效率;
② 不支持增量迭代计算,Flink支持。
6.7 区分RDD的宽窄依赖
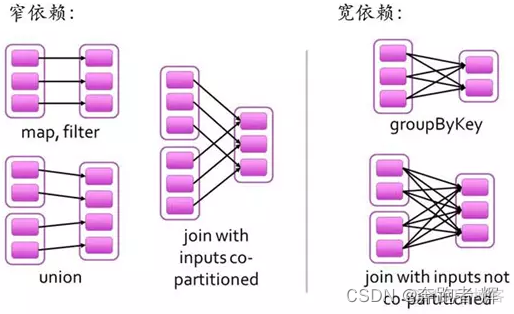
窄依赖:父RDD的一个分区只会被子rdd的一个分区依赖(一对一)。例如map、filter、union等这些算子;
宽依赖:父RDD的一个分区会被子rdd的多个分区依赖(会引起shuffle) (一对多)。例如groupByKey、 reduceByKey,sortBykey等算子。
6.8 为什么要设计宽窄依赖
① 对于窄依赖:
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
② 对于宽依赖:
划分 Stage(阶段)的依据: 对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
7 DAG
7.1 什么是DAG
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算。
7.2 DAG中为什么要划分 Stage
并行计算。
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多 个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个pipeline 流水线,流水线内的多个平行的分区可以并行执行。
7.3 DAG的Stage如何划分
DAG叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系不同将DAG划分成不同的stage。
对于"窄依赖",partition的转换处理在stage中完成计算,不划分。
对于"宽依赖",由于shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要划分stage。且"宽依赖"是划分stage的依据。
7.4 DAG 划分为 Stage的算法了解吗
核心算法:回溯算法
从后往前回溯/反向解析,遇到窄依赖加入本 Stage,遇见宽依赖进行 Stage 切分。
8 算子类
8.1 Transformation算子
transformation变换/转换算子:用来将rdd进行转化,构建rdd的血缘关系,这种变换并不触发提交作业;
transformation有"惰性",操作是延迟计算的,Action触发的时候才会真正的计算;
(1) map:对RDD中所有元素施加一个函数映射,返回一个新RDD,该RDD有原RDD中的每个元素经过function转换后组成。 特点:输入一条,输出一条;
(2) filter:过滤符合条件的记录数,true保留,false过滤掉;
(3) flatmap:通过传入函数进行映射,对每一个元素进行处理。先map,后flat,与map相似,每个输入项可映射0到多个输出项;
(4) repartition:增加或减少分区,会产生shuffle (多分区到一个分区不会产生shuffle);
(5) MapPartitions:每次处理一个分区的数据,这个分区的数据处理完后,原RDD中分区数据才能释放,但是数据量大时会导致oom;
(6) MapPartitionsWithIndex:与MapPartition相似,除此之外还会带分区索引值;
(7) foreache:循环遍历数据集中每个元素,并运行相应的逻辑;
(8) sample:随机抽样算子,对传进去的数按比例放回或不放回的抽样;
(9) GroupByKey:对数据会按照key进行分组,key相同会在同一个分区里;
(10) ReduceByKey:将相同的key,将按照相应的逻辑进行处理。先进行本地聚合(分区聚合),在进行全局聚合;
(11) sortbykey:如果源RDD包含源类型(k,v)对,其中k可排序,则返回新RDD包含(k,v)对,并按照k排序;
(12) union:返回源数据集合参数数据的并集;
(13) distinct:返回对源数据集对元素去重后的新数据集;
还有intersection、aggregateBykey、join、cogroup、cartesian、pipe、coalesce、repartition、Repartition and SortWithPartition等算子。
8.2 Action算子
action算子会触发Spark提交作业(job),并将数据输出spark系统。
(1) reduce: 根据聚合逻辑聚合数据集中每个元素;
(2) take(n): 返回一个数据集包含前n个元素的集合;
(3) first: first=take(1)意思是返回数据集中的第1个元素;
(4) count: 返回数据集中元素的个数。会在结果计算完成后回收到Driver端;
(5) collect:将计算结果回收到Driver端;
(6) foreach: 循环遍历数据中每个元素,运行相应的逻辑;
(7) foreachPartition:遍历每个partition里边的数据;
还有takeSample、saveAsTextfile、takeOrdered、Save As SequenceFile、SaveAsObjectFile、countByKey等算子。
8.3 groupByKey与reduceByKey的区别
groupByKey: 主要实现分组,key相同会在同1个分区里,没有预聚合作用;
reduceByKey:分局部聚合(每个分区的聚合) + 全局聚合(每个分区的汇总聚合),具有预聚合操作;
reduceByKey效率更高些,尽量避免使用groupByKey
相同点:都是transformation类型的算子,所有的算子都是根据key进行分组,都会发生shuffle过程。
8.4 map和mapPartitions区别
map:每次处理一条数据,对每一个元素作遍历;
mapPartitions:每次处理一个分区数据,这个分区数据处理完后,原RDD中分区数据才能释放,但是数据量大时可能导致ooM;
开发指导: 当内存空间比较大的时候,建议使用mapPartition(),以提高效率。
相同点: 都是基于分区数据的计算。
8.5 updateStateBykey与mapwithState区别
updateStateBykey:统计全局key的状态,但是就算没有数据出入,它也会返回之前key的状态;
缺点: 如果数据量太大的话,我们需要checkpoint数据会占用较大的存储,而且效率也不高。
mapwithState(效率更高,生产中建议使用):用户统计全局key的状态,但是它如果没有数据输入,便不会返回之前key的状态。我们可以只是关心那些已经发生变化的key,对于没有数据输入,则不会返回那些没有变化key的数据;
优点: 即使数据量很大,checkpoint也不会像updateStateBykey那样,占用较大的存储。
相同点: 对实时数据进行全局的汇总,有状态的计算。
8.6 Repartition和Coalesce区别
① 关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
② 区别:
repartition一定会发生shuffle,coalesce根据传入的参数来判断是否发生shuffle;
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce。
8.7 HashPartitioner 与 RangePartitioner区别
HashPartitioner:使用key计算其hashCode,除以分区的个数取余,得到的值作为分区ID,其结果可能导致分区中的数据量不均匀,产生数据倾斜;
RangePartitioner:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,但是分区内的元素是不能保证有序的,即就是将一点范围的数据映射到某一个分区内。
版权归原作者 奔跑者-辉 所有, 如有侵权,请联系我们删除。