
数据仓库的诞生原因
随着互联网的普及,信息技术已经深入到各行各业,并逐步融入到企业的日常运营中。然而,当前企业在信息化建设过程中遇到了一些困境与挑战。
1、历史数据积存。
过去企业的业务系统往往是在较长时间内建设的,很少进行大面积的改造或者升级,历史数据留存在业务系统中。随着业务的不断增长,历史数据使用频率低,业务数据库中的历史数据越来越多,大量历史数据堆积,从而影响了业务数据库的性能。
2、信息系统分散。
企业各个部门自己建立的独立数据抽取系统会导致数据不一致,难以进行数据整合,不同系统的数据口径不统一、不规范。这导致了数据结构复杂,开发难度大,分析难以标准化,数据应用难度大。
业务数据库面向于业务系统,而数据仓库面向于业务分析。为了满足企业数据分析需要,数据仓库应运而生。
数据仓库的基本特点
数据仓库主要用来对寄存的历史数据进行存储和管理,并使用一些分析方法对数据进行分析和整理(如OLAP、数据分析),从而提供大量数据支持,为企业构建BI打下坚实基础。
数据仓库有以下特点:
1、集成的:原始数据是从多个数据源获得,如文件、数据库等。要将这些来源不同的原始数据整合到一个数据库中,就必须对这些源进行抽取、清洗、转换。
2、面向主题的:数据仓库为数据分析提供服务,根据主题将原始数据集合在一起。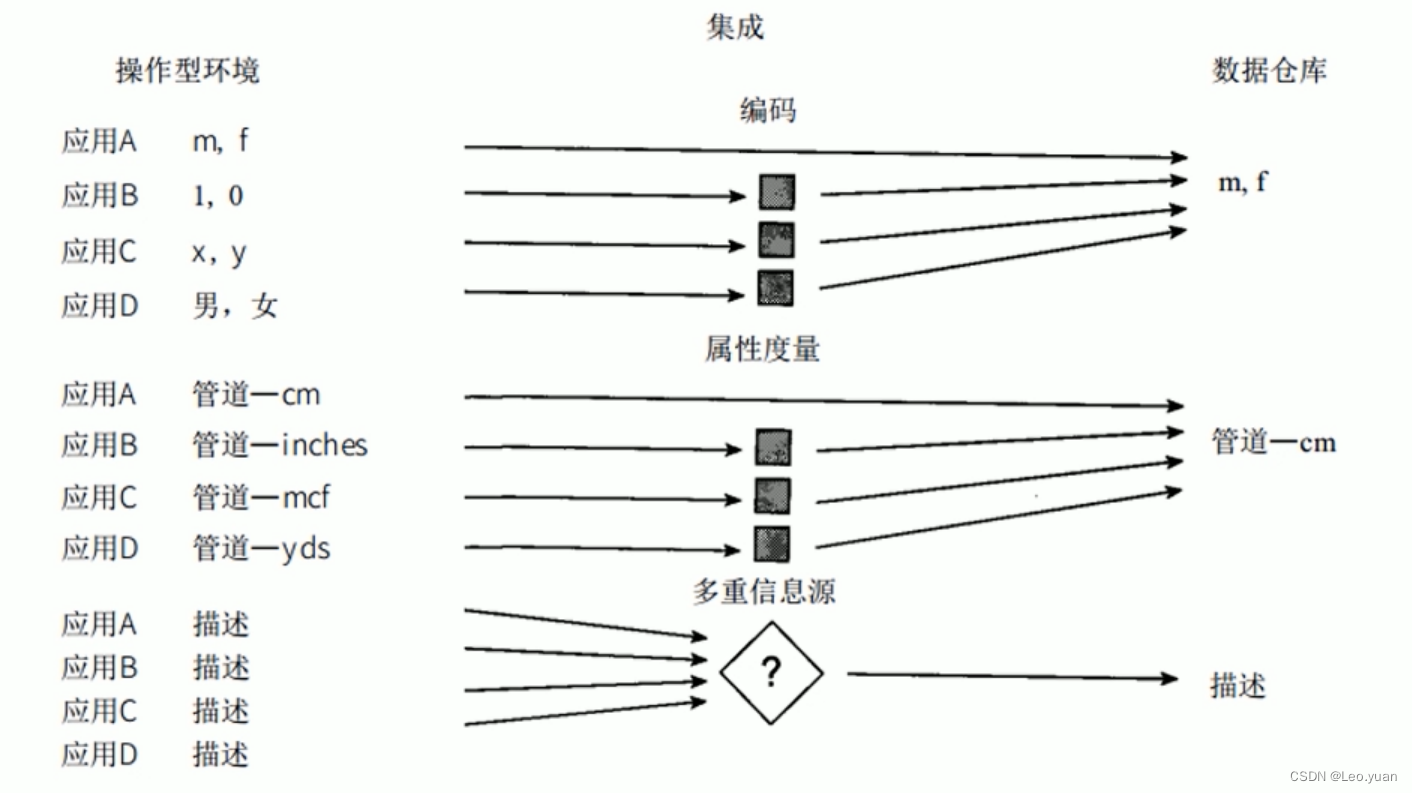
3、时变性:数据仓库会定期接受、集成新的数据,从而反映出数据的最新变化。
4、非易失性:数据仓库中保存的数据是一系列历史快照,一旦进入数据仓库,就不允许被修改。同时,对数据仓库中保存的数据进行查询、分析时,也只能通过专门的工具进行。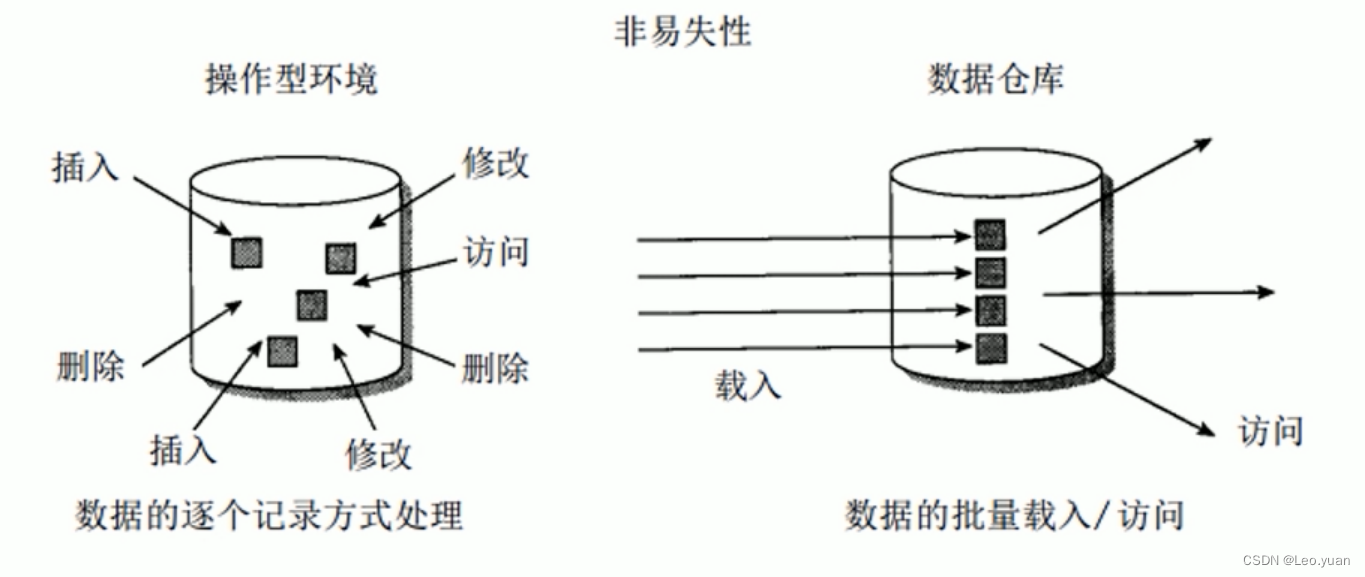
数据仓库和数据库的区别
数据库是面向事务设计的,主要操作是随机读写。在设计过程中,为了避免冗余,常采用符合范式的规范来设计。
数据仓库是面向主题设计的,主要操作为批量读取和写入。数据仓库关注数据整合和分析,会引入冗余,采用反范式的方式进行设计。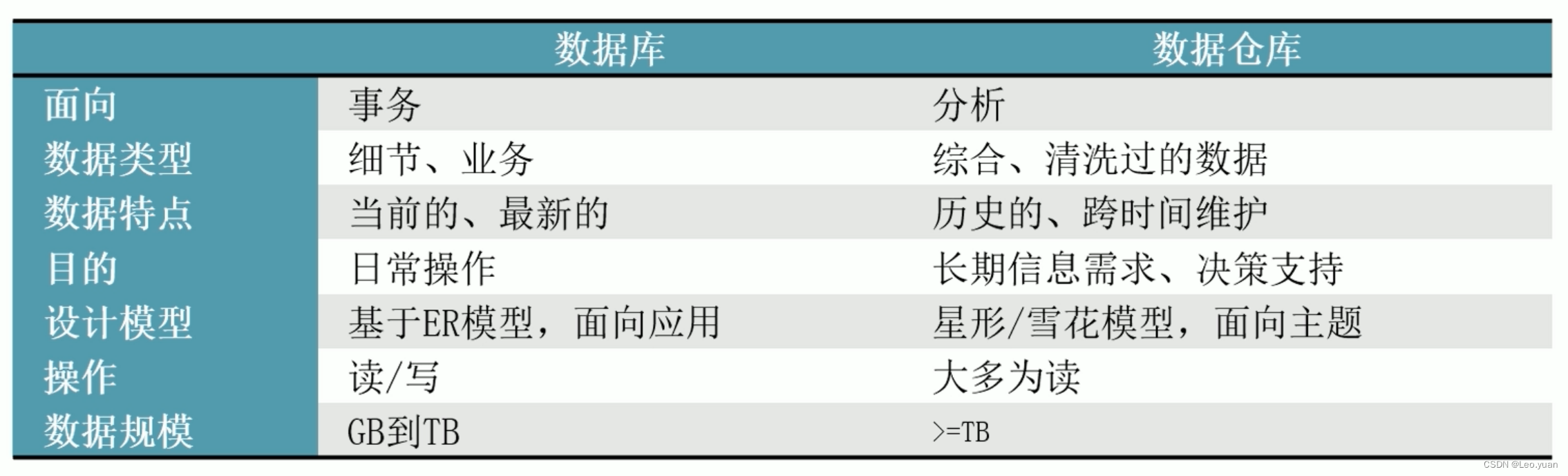
数据仓库建设方案
传统数据仓库和大数据数据仓库是两种不同类型的数据仓库,需要采用不同的建设方案。
传统数据仓库通常是由关系型数据库组成的 MPP (大规模并行处理)集群来进行数据存储和运算,采用一定的数据模型,如星型模型、雪花模型等,来设计数据仓库的结构。但是,随着应用系统的发展,其扩展性受到了很大限制,并且随着业务应用的不断增加,也逐渐产生了一些热点问题。
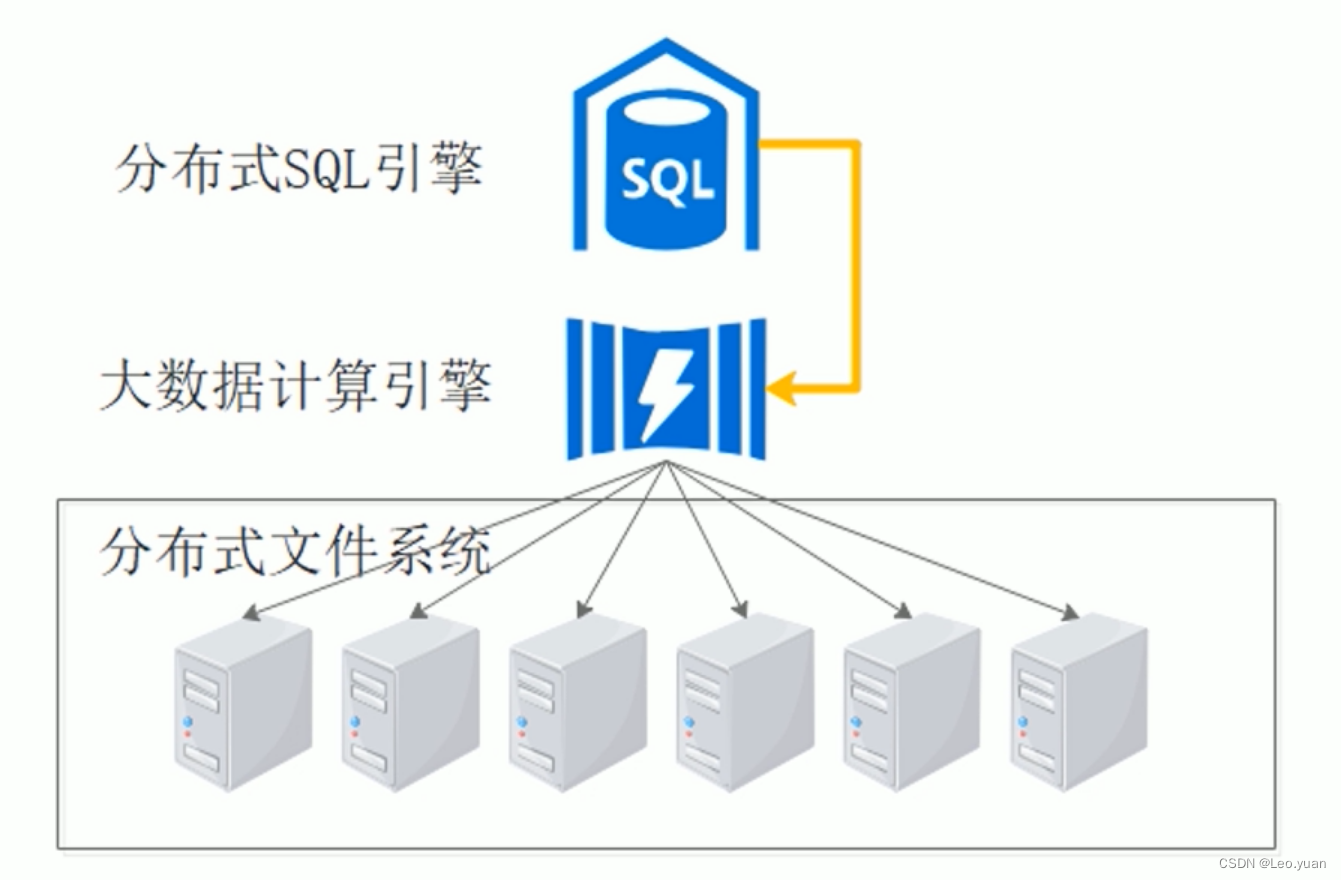
大数据数据仓库通常采用分布式计算技术,如Hadoop、Spark等作为存储和计算引擎,使用工具或编程语言设计处理逻辑,实现对不同数据源的汇聚、清洗、计算和分析。大数据数据仓库利用了大数据天然的扩展性来完成海量数据的存放,同时也把SQL转换成了针对大数据计算引擎的任务,实现数据的分析。虽然大数据数据仓库具有很多优点,但是仍然存在一些挑战和问题:
- SQL的支持率比较低。大数据计算引擎有自己的语言和逻辑,所以有些SQL查询无法很好地转换成它们能够理解的任务。
- 缺少事务支持。因为大数据计算引擎本质上是分布式的,并且数据分散在多个节点上,所以很难实现完整的事务支持。
- 数据量较少时计算速度可能比较慢。大数据数据仓库可以通过计算资源的横向扩展来提高计算速度,所以当数据量较少时,可能需要较长的时间来完成分析。
现在企业的信息化建设和数据仓库的构建面临很多挑战,需要根据企业的现状和需要解决的问题,选择合适的方案,不能一蹴而就。很显然在目前的信息时代,借助类似于FineDataLink的这些工具,可以让企业加速融入企业数据集成和分析的趋势。
[数据仓库建设方案:免费获取]
数据仓库扫盲系列共12篇内容,记得点关注~
版权归原作者 Leo.yuan 所有, 如有侵权,请联系我们删除。