
环境说明
- centos7
- flume1.9.0(flume-ng-sql-source插件版本1.5.3)
- jdk1.8
- kafka 2.1.1
- zookeeper(这个我用的kafka内置的zk)
- mysql5.7
- xshell
准备工作
1.安装Flume
这个参考博主的另一篇安装flume的文章
flume简介
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储。在大数据生态圈中,flume经常用于完成数据采集的工作。

其实时性很高,延迟大约1-2s,可以做到准实时。
又因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例子。要了解flume如何采集数据,首先要初探其架构:
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
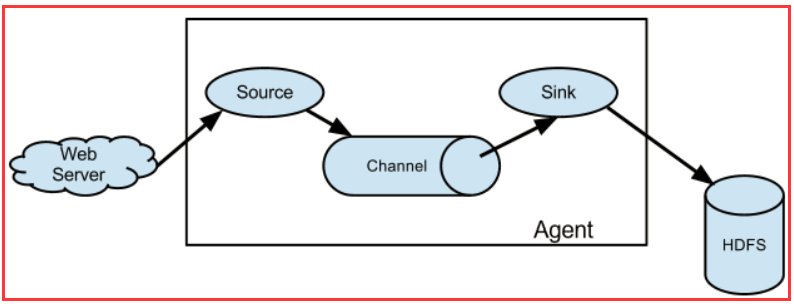
三大组件
source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等。如果内置的Source无法满足需要, Flume还支持自定义Source。
可以看到原生flume的source并不支持sql source,所以我们需要添加插件,后续将提到如何添加。
channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
- MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
- FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
sink
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
这个例子中,我使用了kafka作为sink
下载flume-ng-sql-source插件
到这里下载flume-ng-sql-source,最新版本是1.5.3。
下载完后解压,我通过idea运行程序,使用maven打包为jar包,改名为
flume-ng-sql-source-1.5.3.jar
编译完的jar包要放在放到FLUME_HOME/lib下,FLUME_HOME是自己linux下flume的文件夹,比如我的是
/opt/install/flume
jdk1.8安装
kafka安装
zookeeper安装
kafka安装
我们使用flume将数据采集到kafka, 并启动一个kafak的消费监控,就能看到实时数据了
kafka单机搭建及操作--做个记录_Alex_81D的博客-CSDN博客
mysql5.7.24安装
超详细的yum方式安装mysql_Alex_81D的博客-CSDN博客_yum下载mysql
flume抽取mysql数据到kafka实战
新建一个数据库和表
在完成上述的安装工作后就可以开始着手实现demo了
首先我们要抓取mysql的数据,那么必然需要一个数据库和表,并且要记住这个数据库和表的名字,之后这些信息要写入flume的配置文件。
创建数据库:
create database test
创建表:
-- ----------------------------
-- Table structure for fk
-- ----------------------------
DROP TABLE IF EXISTS `fk`;
CREATE TABLE `fk` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
新增配置文件(重要)
cd 到flume的conf文件夹中,新增一个文件mysql-flume.conf
注:mysql-flume.conf本来是没有的,是我生成的,具体配置如下所示
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
# 采集间隔时间
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# 配置关系
a1.sources.src-1.channels = ch-1
a1.sinks.k1.channel = ch-1
添加mysql驱动到flume的lib目录下
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.35.tar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动zookeeper
由于我用的是kafka自带的zk,所以这步是这样的
./zookeeper-server-start.sh ../config/zookeeper.properties &
启动kafka
xshell中打开一个新窗口,cd到kafka目录下,启动kafka
bin/kafka-server-start.sh config/server.properties &
新建一个topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic就是你使用的topic名称,这个和上文mysql-flume.conf里的内容是对应的。
注2:可以使用
bin/kafka-topics.sh --list --zookeeper localhost:2181
来查看已创建的topic。
启动flume
xshell中打开一个新窗口,cd到flume目录下,启动flume
../bin/flume-ng agent -n a1 -c ../conf -f mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新建的test数据库和fk表。


实时采集数据
flume会实时采集数据到kafka中,我们可以启动一个kafak的消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时就可以查看数据了,kafka会打印mysql中的数据
然后我们更改数据库中的一条数据,新读取到的数据也会变更
before:

修改后

本文对相关内容进行了改动,操作中遇到的坑都已经规避
版权归原作者 Alex_81D 所有, 如有侵权,请联系我们删除。