
需要java安装包和hadoop安装包的可以选择这里下载
链接:https://pan.baidu.com/s/1sQQ-uiwmJvYFPgpVsftL6Q?
提取码:aubt
第一步,安装centos7并检查网络环境
为虚拟机导入centos7环境,centos7的安装这里不做赘述,直接上干货
注意VLAN设置: 虚拟机设置为NAT模式
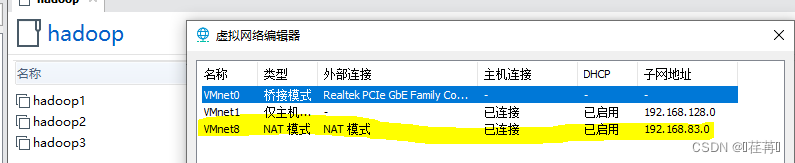
查看linux网络ip地址;
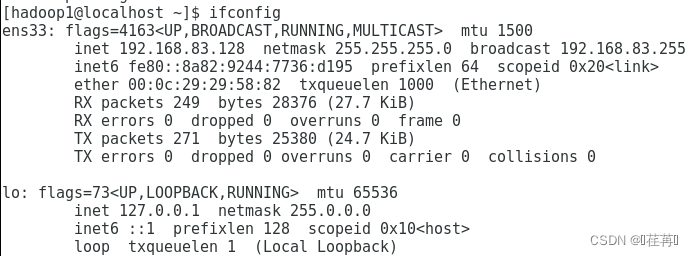
查看网络连接 ping www.baidu.com

如果Ping不通
打开网卡编辑

打开后 修改为

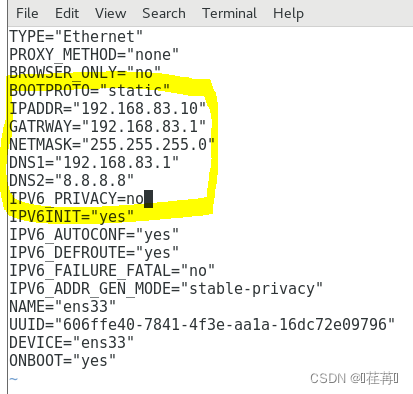
编辑完成后保存退出。
然后重启网络服务 service network restart

修改名字hostname 修改 vim /etc/hostname

重启计算机 reboot

第三步,上传java,hadoop安装包并完成环境配置
安装java的jdk
上传对应的安装包到虚拟机中,并解压
在虚拟机node1中新建两个目录software(安装包文件)和server(解压文件)
mkdir -p /develop/software
mkdir -p /develop/server

进入并导入安装包(我这里使用的xsheel传输本地文件)

查看java版本并完成卸载

检索java环境 rpm -qa | grep jdk 或者 rpm -qa | grep java (一样的)


卸载java环境 yum remove java.jdk
卸载完成后剩余

安装新的java
解压jdk的tar包到/develop/server目录
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /develop/server/(后面的为新建的文件夹)

解压hadoop安装包到/develop/server
tar -zxvf hadoop-2.7.5.tar.gz -C /develop/server/

查看java安装文件

修改文件夹root权限 chown -R root (rwx)(读写访问) 地址

修改文件名 mv 原文件名 修改文件名 (便于环境的配置)
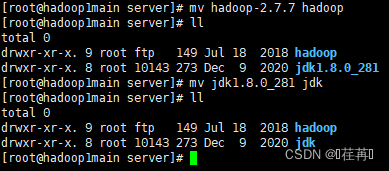
进入jdk目录,复制jdk的地址

配置环境变量
vim /etc/profile


刷新配置文件
source /etc/profile

第四步
修改hadoop配置文件
设置namenode作为java程序的入口
进入文件 core-site.xml

<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/develop/server/hadoop/temp</value>
</property>

配置hadoop的java路径
进入文件 vim Hadoop-env.sh

修改java路径

修改hdfs-site.xml文件 这里只有一个节点 replication设置为1

<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/develop/server/hadoop/temp/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/develop/server/hadoop/temp/data</value>
</property>

修改 vim mapred-site.xml.template 文件

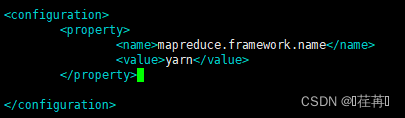
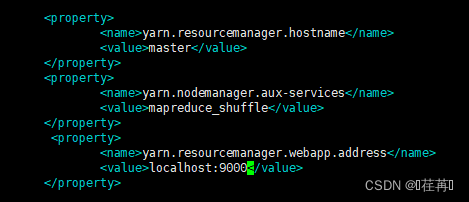
修改vim yarn-site.xml 文件

<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:9000</value>
</property>
切换到hadoop的etc/hadopp目录,修改hadoop-env.sh

**最后一步 **
启动和停止
进入hadoop的bin文件下 cd bin
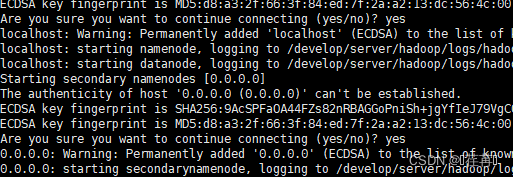
输入:: hdfs namenode -format

得到

代表格式化成功
启动hdfs和yarn
进入 sbin 文件夹 cd sbin
启动start-all.sh

得到
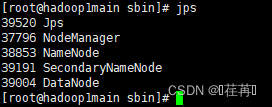
使用jsp查看
停止

得到

使用jps查看

在启动的情况下访问hadoop
浏览器中输入http://localhost:50070 访问hdfs 访问成功


版权归原作者 இ荏苒இ 所有, 如有侵权,请联系我们删除。