
读数据流程

- 客户端向 Node1(协调节点) 发送获取请求。
- 节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。
- 为了负载均衡,可以轮询所有节点,最后它将请求转发到 Node 2 。
- Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端
写数据流程
新建索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。

- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。
- 一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功
consistency(一致性)
在默认设置下,即使仅仅是在试图执行一个写操作之前,主分片都会要求必须要有规定数量的分片副本处于活跃可用状态,才会去执行写操作(其中分片副本 可以是主分片或者副本分片)。这是为了避免在发生网络分区故障(network partition)的时候进行写操作,进而导致数据不一致。 规定数量即: **int((primary + number_of_replicas) / 2 ) + 1**
onsistency 参数的值可以设为:
- one :只要主分片状态 ok 就允许执行写操作。
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作。
- quorum:默认值为quorum , 即大多数的分片副本状态没问题就允许执行写操作。
修改数据流程
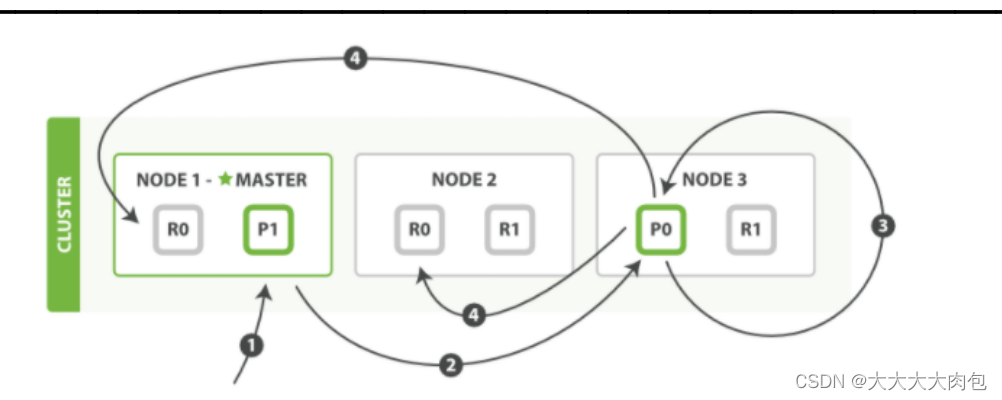
- 客户端向Node 1发送更新请求。
- 它将请求转发到主分片所在的Node 3 。
- Node 3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3 ,超过retry_on_conflict次后放弃。
- 如果 Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和 Node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
删除/更新数据底层原理
删除操作
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
更新操作
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
物理删除
buffer 每 refresh 一次,就会产生一个 segment file,所以默认情况下是 1 秒钟一个 segment file,这样下来 segment file 会越来越多。此时会定期执行 merge。每次 merge 的时候,会将多个 segment file 合并成一个同时这里会将标识为 deleted 的 doc 给物理删除掉,然后将新的 segment file 写入磁盘这里会写一个 commit point,标识所有新的 segment file,然后打开 segment file 供搜索使用,同时删除旧的 segment file。
标签:
elasticsearch
大数据
本文转载自: https://blog.csdn.net/qq_42456324/article/details/128302738
版权归原作者 大大大大肉包 所有, 如有侵权,请联系我们删除。
版权归原作者 大大大大肉包 所有, 如有侵权,请联系我们删除。