
实现以下任务:
创建数据库taitan
创建乘客信息表
导入数据到表中
统计获救与死亡情况
统计舱位分布情况
统计港口登船人数分布情况
统计性别与生存率的关系
统计客舱等级与生存率的关系
统计登船港口与生存率的关系
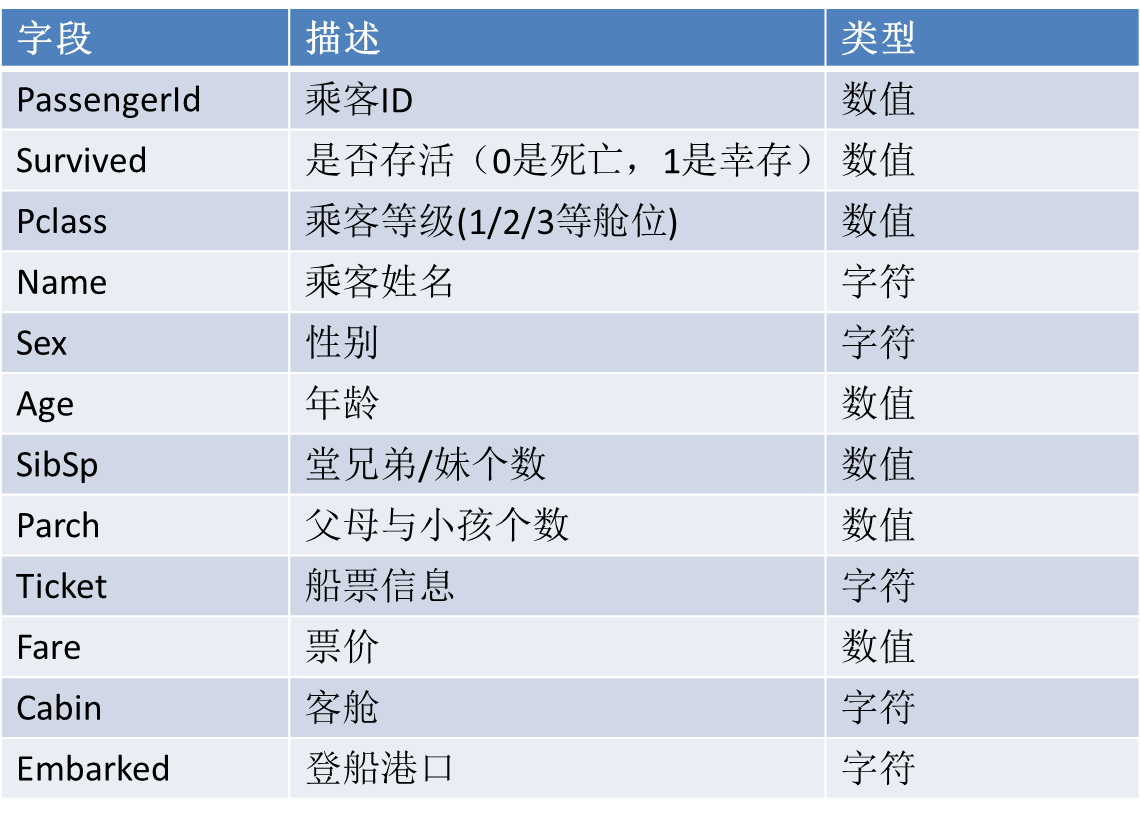
1.创建一个内/外部表,指定数据的存放路径。
(1)创建数据库taitan
create database taitan if not exists taitan;
(2)设置taitan为当前数据库
use taitan;
(3)
create table tidanic(
passengerid int,
survivied int,
pclass int,
name string,
sex string,
age int,
sibsp int,
parch int,
ticket string,
fare double,
cabin String,
embarked String)row format delimited fields terminated by ',';
2.通过HDFS命令导入数据到指定路径。
第一步:从windows将数据导入到虚拟机master某一目录下。
第二步:用“vi train.csv”命令删除第一行,因为第一行为字段名称。
第三步:把本地数据上传到hive中表tidanic的目录下,命令如下,记得修改为数据实际路径。
hdfs dfs -put train.csv /user/hive/warehouse/taitan.db/tidanic
第四步:查看前10行,检查是否导入成功。
select * from tidanic limit 10;
3.创建静态分区表tidanic_part,字段为passengerid,survived,pclass,name,
分区字段为gender,按照性别字段sex分区。
create table tidanic_part(
passengerid int,
survived int,
pclass int,
name string)
partitioned by(gender string)
row format delimited fields terminated by ','
tblproperties(“skip.header.line.count”=”1”);
4.导入数据到静态分区表tidanic_part。
insert overwrite table tidanic_part partition(gender='female')
select passengerid,survived,pclass,name from tidanic where sex='female';
insert overwrite table tidanic_part partition(gender='male')
select passengerid,survived,pclass,name from tidanic where sex='male';
5.创建动态分区表tidanic_dynamic_part,字段为passengerid,survived,name,
分区字段为passengerclass,按照pclass值进行分区。
create table tidanic_dynamic_part(
passengerid int,
survived int,
name string)
partitioned by(passengerclass string)
row format delimited fields terminated by ',';
6.设置动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrict;
7.往动态分区表中插入数据。
insert overwrite table tidanic_dynamic_part partition(passengerclass)
select passengerid,survived,name,pclass from tidanic;
8.创建一个tidanic子集。
(1)创建tidanic前10行数据的子表。
create table tidanic_10 as select * from tidanic limit 10;
(2)创建与tidanic表结构相同的表。
create table tidanic_like like tidanic_part;
9.创建桶表,按年龄将数据分到4个桶,抽取两个桶的数据创建一个新表tidannic_sample。
create table tidanic_bucket(
passengerid int,
name string,
age int)
clustered by (age) into 4 buckets
row format delimited fields terminated by ',';
10.修改桶表配置
set hive.enforce.bucketing=true;
11.往桶表中插入数据
insert overwrite table tidanic_bucket
select passengerid,name,age from tidanic;
12.抽取桶1开始两个桶的数据到抽样表tidanic_sample中,
tablesample(bucket x out of y),x代表从哪个桶开始抽,
y代表抽取桶的个数为(桶数/y)个,y必须是桶数的倍数或因子。
create table tidanic_sample as
select * from tidanic_bucket tablesample(bucket 1 out of 2 on age);
13.从文件系统中导入数据到泰坦尼克乘客表中
(1)从本地导入
use taitan;
load data local inpath '/opt/train.csv' overwrite into table tidanic;
(2)从hdfs上导入
user taitan;
load data inpath 'user/root/train.csv' overwrite into table tidanic;
14.(1)查询tidanic前10行数据到tidanic_10中;
use tidanic;
show tables;
desc tidanic_10;
select * from tidanic_10
insert into table tidanic_10 select * from tidanic limit 10;
(2)查询tidanic表中的存活乘客数据到tidanic_save表;
create table tidanic_save like tidanic;
insert overwrite table tidanic_save select * from tidanic where survied=1;
(3)查询tidanic表中的死亡乘客数据到tidanic_died表。
create table tidanic_died like tidanic;
insert overwrite table tidanic_died select * from tidanic where survied=0;
15.导出数据表到文件系统:导出死亡名单到linux本地。
注意:如有local,则是导出到本地;如果没有local,则是导出到hdfs上。
insert overwrite local directory '/opt/tidanic_died'
row format delimited fields terminated by ',' select * from tidanic_died;
16.统计获救与死亡分布情况。
查看当前数据库
set hive.cli.print.current.db=true;
use taitan;
select count(*) as p_count,survived from tidanic group by survived;
17.统计舱位分布情况。
use taitan;
select count(*) as p_count,pclass from tidanic group by pclass;
18.统计港口登船人员分布情况。
use taitan;
select count(*) as p_count,embarked from tidanic group by embarked;
19.统计性别与生存率的关系。
use taitan;
select sex,count(*) as s_count from tidanic where survived=1 group by sex;
(1)总的生存人数:
select count(*) as all_count from tidanic where survived=1;
(2)实现需要用到嵌套,具体实现如下:
select sex,s_count/allcount as s_percent from
(select sex,count(*) as s_count from tidanic where survivied=1 group by sex) as a
join (select count(*) as all_count from tidanic where survivied=1) as b on 1=1;
20.统计客舱等级与生存率的关系。
select pclass,s_count/all_count as s_percent from
(select pclass,count(*) as s_count from tidanic where survivied=1 group by pclass) as a
join (select count(*) as all_count from tidanic where survivied=1) as b on 1=1;
21.统计登船港口与生存率的关系。
select embarked,s_count/all_count as s_percent from
(select embarked,count(*) as s_count from tidanic where survivied=1 group by embarked) as a
join (select count(*) as all_count from tidanic where survivied=1) as b on 1=1;
版权归原作者 cqiicq 所有, 如有侵权,请联系我们删除。