
上一讲,我们一起体验了 CLIP 这个多模态的模型。在这个模型里,我们已经能够把一段文本和对应的图片关联起来了。看到文本和图片的关联,想必你也能联想到过去半年非常火热的“文生图”(Text-To-Image)的应用浪潮了。相比于在大语言模型里 OpenAI 的一枝独秀。文生图领域就属于百花齐放了,OpenAI 陆续发表了 DALL-E 和 DALL-E 2,Google 也不甘示弱地发表了 Imagen,而市场上实际被用得最多、反馈最好的用户端产品是 Midjourney。
不过,在整个技术社区里,最流行的产品则是 Stable Diffusion。因为它是一个完全开源的产品,我们不仅可以调用 Stable Diffusion 内置的模型来生成图片,还能够下载社区里其他人训练好的模型来生成图片。我们不仅可以通过文本来生成图片,还能通过图片来生成图片,通过文本来编辑图片。
那么今天这一讲,我们就来看看如何使用 Stable Diffusion,做到上面这些事情。
使用 Stable Diffusion 生成图片
文生图
可能你还没怎么体验过文生图的应用,那我们先用几行最简单的代码体验一下。在这一讲里,我建议一定要用 Colab 或者其他的 GPU 环境,因为用 CPU 来执行的话,速度会慢到让人无法接受。
安装依赖包:
%pip install diffusers accelerate transformers
代码:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipeline.to("cuda")
image = pipeline("a photograph of an astronaut riding a horse").images[0]
image
输出结果:

代码非常简单,只有寥寥几行。这里,我们使用了 Huggingface 的 Diffusers 库,通过 DiffusionPipeline 加载了 RunwayML 的 stable-diffusion-v1-5 的模型。然后,指定了这个 Pipeline 使用 CUDA 也就是利用 GPU 来进行计算。最后向这个 Pipeline 输入了一段文本,通过这段文本我们就生成了一张图片。
这里,我们画的是在 Stable Diffusion 里非常经典的一张“宇航员在太空骑马”的图片。之所以画这么一张图片,是为了证明我们并不是通过“搜索”的方式找到一张已经存在的图片。比如,上一讲里我们介绍过 CLIP 模型,其实就可以完成从文本到图片的搜索功能。而 Stable Diffusion,是真的让 AI“画”出来一张新的图片。毕竟,以前宇航员也从来没有在太空骑过马,也不可能有人拍下过这样的照片。
Stable Diffusion 的基本原理
Stable Diffusion 生成的图片效果的确不错,相信你也很好奇这个事情的原理是什么。其实,Stable Diffusion 背后不是单独的一个模型,而是由多个模型组合而成的。整个 Stable Diffusion 文生图的过程是由这样三个核心模块组成的。
第一个模块是一个 Text-Encoder,把我们输入的文本变成一个向量。实际使用的就是我们上一讲介绍的 CLIP 模型。因为 CLIP 模型学习的是文本和图像之间的关系,所以得到的这个向量既理解了文本的含义,又能和图片的信息关联起来。
第二个是 Generation 模块,顾名思义是一个图片信息生成模块。这里也有一个机器学习模型,叫做 UNet,还有一个调度器(Scheduler),用来一步步地去除噪声。这个模块的工作流程是先往前面的用 CLIP 模型推理出来的向量里添加很多噪声,再通过 UNet+Scheduler 逐渐去除噪声,最后拿到了一个新的张量。这个张量可以认为是一个尺寸上缩小了的图片信息向量,里面隐含了我们要生成的图片信息。
最后一个模块,则是 Decoder 或者叫做解码器。背后也是一个机器学习的模型,叫做 VAE。它会根据第二步的返回结果把这个图像信息还原成最终的图片。
这个过程,可以结合 Stable Diffusion 相关论文里的一张模型架构图来看。
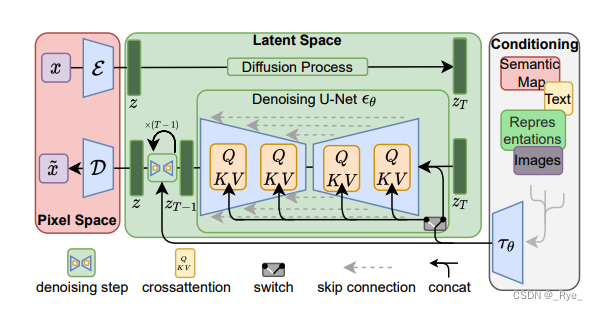
这样听起来可能有点太理论了,那我们还是看看具体的代码和图片生成的过程吧,这样就比较容易理解图片是怎么生成的了。
我们先把 DiffusionPipeline 打印出来,看看它内部是由哪些部分组成的。
pipeline
输出结果:
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.15.1",
"feature_extractor": [
"transformers",
"CLIPFeatureExtractor"
],
"requires_safety_checker": true,
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
这个对象里面有 3 部分。
Tokenizer 和 Text_Encoder,就是我们上面说的把文本变成向量的 Text Encoder。可以看到我们这里用的模型就是上一讲的 CLIP 模型。
UNet 和 Scheduler,就是对文本向量以及输入的噪声进行噪声去除的组件,也就是 Generation 模块。这里用的是 UNet2DConditionModel 模型,还把 PNDMScheduler 用作了去除噪声的调度器。
VAE,也就是解码器(Decoder),这里用的是 AutoencoderKL,它会根据上面生成的图片信息最后还原出一张高分辨率的图片。
剩下的 feature_extractor,可以用来提取图像特征,如果我们不想文生图,想要图生图,它就会被用来把我们输入的图片的特征提取成为向量。而 safety_checker 则是用来检查生成内容,避免生成具有冒犯性的图片。
接下来,我们就自己来组合一下这些模型,来把整个图片生成的过程给演示出来。首先,我们把上面 Stable Diffusion 1.5 需要的模型组件都加载出来。
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
vae = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
unet = UNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="unet")
scheduler = PNDMScheduler.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="scheduler")
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
注意,对应的 CLIPTokenizer 和 CLIPTextModel 的名字并不是 stable-diffusion-v1-5,如果使用 Diffusers 库的 Pipeline 的话,可以从模型里面对应模块的 config.json 读取到它们。
然后,我们把接下来生成图片的参数初始化一下,包括文本、对应的图片分辨率,以及一系列模型中需要使用的超参数。
import torch
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 25 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(42) # Seed generator to create the inital latent noise
batch_size = len(prompt)
然后,我们把对应的输入文本变成一个向量,然后再根据一个空字符串生成一个“无条件”的向量,最后把两个向量拼接在一起。我们实际生成图片的过程,就是逐渐从这个无条件的向量向输入文本表示的向量靠拢的过程。
text_input = tokenizer(
prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
)
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
然后,我们可以先生成一系列随机噪声。
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
latents = latents * scheduler.init_noise_sigma
接下来就是生成图片的代码了,我们先定义两个函数,它们会分别显示 Generation 模块生成出来的图片信息,以及 Decoder 模块还原出来的最终图片。
import PIL
import torch
import numpy as np
from PIL import Image
from IPython.display import display
def display_denoised_sample(sample, i):
image_processed = sample.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
display(f"Denoised Sample @ Step {i}")
display(image_pil)
return image_pil
def display_decoded_image(latents, i):
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
display(f"Decoded Image @ step {i}")
display(pil_images[0])
return pil_images[0]
最后,我们通过 Diffusion 算法一步一步来生成图片就好了。我们根据前面指定的参数,循环了 25 步,每一步都通过 Scheduler 和 UNet 来进行图片去噪声的操作。并且每 5 步都把对应去噪后的图片信息,以及解码后还原的图片显示出来。
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
denoised_images = []
decoded_images = []
for i, t in enumerate(tqdm(scheduler.timesteps)):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
if i % 5 == 0:
denoised_image = display_denoised_sample(latents, i)
decoded_image = display_decoded_image(latents, i)
denoised_images.append(denoised_image)
decoded_images.append(decoded_image)
输出结果:
Denoised Sample @ Step 0
Decoded Image @ step 0

Denoised Sample @ Step 5
Decoded Image @ step 5

Denoised Sample @ Step 10
Decoded Image @ step 10

Denoised Sample @ Step 15
Decoded Image @ step 15

Denoised Sample @ Step 20
Decoded Image @ step 20

Denoised Sample @ Step 25

Decoded Image @ step 25

运行完程序,你就可以看到我们的图片是如何一步步从完全的噪点还原成一张图片的了。而且你仔细观察,还可以看到 Generation 生成的图像信息,类似于 Decoder 还原出来的图像信息的轮廓。这是因为 U-Net 其实是一个图片语义分割的模型。
而如果我们打印一下生成的图片的维度,你也可以看到,Generation 生成的图像信息分辨率只有 64x64,而我们还原出来的图片分辨率是 512x512。
print(latents.shape)
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
print(image.shape)
输出结果:
torch.Size([1, 4, 64, 64])
torch.Size([1, 3, 512, 512])
图生图
相信你已经理解了这个 Stable Diffusion 生成图片的过程,以及过程里每个模块的工作了。那你应该比较容易理解如何通过 Stable Diffusion 实现图生图了,我们下面就来具体看一看。
当然,这一次我们就不用自己一步步调用各个模块来实现图生图了。我们可以直接使用 Diffusers 库里自带的 Pipeline。
import torch
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionImg2ImgPipeline
device = "cuda"
model_id_or_path = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe = pipe.to(device)
image_file = "./data/sketch-mountains-input.jpg"
init_image = Image.open(image_file).convert("RGB")
init_image = init_image.resize((768, 512))
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
display(init_image)
display(images[0])
输出结果:


对应的代码也非常简单,我们把 Pipeline 换成了 StableDiffusionImg2ImgPipeline,此外除了输入一段文本之外,我们还提供了一张草稿图。然后,你可以看到对应生成的图片的轮廓,就类似于我们提供的草稿图。而图片的内容风格,则是按照我们文本提示语的内容生成的。
StableDiffusionImg2ImgPipeline 的生成过程,其实和我们之前拆解的一步步生成图片的过程是相同的。唯一的一个区别是,我们其实不是从一个完全随机的噪声开始的,而是把对应的草稿图,通过 VAE 的编码器,变成图像生成信息,又在上面加了随机的噪声。所以,去除噪音的过程中,对应的草稿图的轮廓就会逐步出现了。而在一步步生成图片的过程中,内容又会向我们给出的提示语的内容来学习。
而如果我们换一下提示语,就能更改生成的具体内容。比如我们想换成宫崎骏的风格,并且希望后面高耸的不是山,而是城堡,出现的图片还是相同的轮廓,但是用不同的内容。在下面给出了一个代码示例,可以自己看一看。
prompt = "ghibli style, a fantasy landscape with castles"
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
display(init_image)
display(images[0])
输出结果:


更多使用方法
理解了 Stable Diffusion 的基本框架,你可以试一试更多相关的 Pipeline 的用法。比如,除了引导内容生成的提示语,我们还可以设置一个负面的提示语(negative prompt),也就是排除一些内容。
prompt = "ghibli style, a fantasy landscape with castles"
negative_prompt = "river"
images = pipe(prompt=prompt, negative_prompt=negative_prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
display(images[0])
输出结果:

可以看到,我们希望在图片里面尽量排除“River”。而新生成的图片,右边就没有了任何类似于河流的内容,而中间蓝色的部分也更像一个排水渠而不是自然的河流。负面提示语并不会改变模型的结构。它其实就是把原先的“无条件”向量,替换成了负面提示语的向量。这样,模型就尽可能从负面的提示语文本内容中向我们正面的提示语文本内容学习,也就是尽量远离负面提示语的内容。
同样,我们还可以通过 Stable Diffusion 来提升图片的分辨率,只不过需要一个单独的模型。这个模型就是专门在一个高低分辨率的图片组合上训练出来的。对应的 UNet 和 VAE 的模型是和原始的 Stable Diffusion 不一样的。
from diffusers import StableDiffusionUpscalePipeline
# load model and scheduler
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(
model_id, revision="fp16", torch_dtype=torch.float16
)
pipeline = pipeline.to("cuda")
# let's download an image
low_res_img_file = "./data/low_res_cat.png"
low_res_img = Image.open(low_res_img_file).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
prompt = "a white cat"
upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
low_res_img_resized = low_res_img.resize((512, 512))
display(low_res_img_resized)
display(upscaled_image)
输出结果:


如果我们打印一下 pipeline,对应的模型的组件还是相同的。
pipeline
输出结果:
StableDiffusionUpscalePipeline {
"_class_name": "StableDiffusionUpscalePipeline",
"_diffusers_version": "0.15.1",
"low_res_scheduler": [
"diffusers",
"DDPMScheduler"
],
"max_noise_level": 350,
"scheduler": [
"diffusers",
"DDIMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
但是如果去看对应模型的配置文件,可以看到 VAE 和 UNet 里使用的模型都是不一样的。
使用社区里的其他模型
在这个过程中,你可以看到 Stable Diffusion 并不是指某一个特定的模型,而是指一类模型结构。因为 Stable Diffusion 是完全开源的,所以你大可以利用自己的数据去训练一个属于自己的模型。事实上,市面上开源训练出来的 Stable Diffusion 的模型非常多,也已经有了像 CIVITAI 这样的分享 Stable Diffusion 模型的平台。
CIVITAI 里有用户们自己训练的各种风格的模型
我们可以去 CIVITAI 的网站,找到我们喜欢的模型。比如我们专门找一个二次元的模型 counterfeit-V2.5。在对应的模型页面,我们可以看到它直接就包含了 Huggingface 里面的模型。

所以我们就可以直接通过 Diffuers 库来调用这个模型。
pipeline.to("cuda")
prompt = "((masterpiece,best quality)),1girl, solo, animal ears, rabbit, barefoot, knees up, dress, sitting, rabbit ears, short sleeves, looking at viewer, grass, short hair, smile, white hair, puffy sleeves, outdoors, puffy short sleeves, bangs, on ground, full body, animal, white dress, sunlight, brown eyes, dappled sunlight, day, depth of field"
negative_prompt = "EasyNegative, extra fingers,fewer fingers,"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt).images[0]
image
输出结果:

当然,不是所有 CIVITAI 里的模型都在 Huggingface 上提供了自己的模型版本。默认 CIVITAI 的模型,往往只是提供了一个模型权重文件。你可以使用现在最流行的 Stable-Diffusion-Web-UI 应用来使用这个模型权重文件。你可以把 Web-UI 在本地部署起来,它会提供一个图形界面让你不用写代码就可以直接调整各种参数来生成图片。
来自 stable-diffusion-web-ui 的图形界面
CIVITAI 的 Wiki里面也详细提供了在 Stable-Diffusion-Web-UI 里面使用模型的步骤,可以照着这个步骤多拿几个模型试试看。
小结
这一讲,体验了一下 Stable Diffusion 这个图片生成的开源模型。我们不仅通过 Diffusers 这个封装好的 Python 库,体验了文生图、图生图、提升图片分辨率等一系列应用,也深入到 Stable Diffusion 的模型内部,理解了整个模型的结构,还看到我们是如何一步步从一张全是噪点的图片,逐渐去除噪声变成一张可用的图片的。
在体验了基础的模型之后,我们也一起尝试了一下其他爱好者自己生成的模型。这也是下一讲我们要介绍的重点内容。我们会了解到如何通过 LoRa 这样的算法进行模型微调,以及如何通过 ControlNet 让我们生成的图片更加可控。
思考题
最后,按照惯例还是留一道思考题。除了今天演示的这些应用之外,HuggingFace 还提供了很多实战场景。比如,就可以通过 StableDiffusionInpaintPipeline,用一个遮照图片和一段提示语来修改图片画面中的某一部分元素。
可以照着官方文档,体验一下这个功能,研究一下源代码,想想这个功能是如何通过 Stable Diffusion 的模型结构实现的。
推荐阅读
这一讲里,我们只是简单介绍了一下 Stable Diffusion 的模型结构。其实,无论是 DALL-E 2 还是 Imagen,采用的图片生成方式都是和 Stable Diffusion 类似的。如果想要深入了解一下这些模型的结构,可以去看一下 B 站里面“跟李沐学 AI”里面对于 DALL-E 2 论文的讲解。
版权归原作者 _Rye_ 所有, 如有侵权,请联系我们删除。