
Selenium 的使用
Selenium
是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些
JavaScript
动态渲染的页面来说,此种抓取方式非常有效。
基本使用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
browser = webdriver.Edge(executable_path="msedgedriver.exe")try:
browser.get('https://www.baidu.com')input= browser.find_element_by_id('kw')input.send_keys('Python')input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))print(browser.current_url)print(browser.get_cookies())print(browser.page_source)
time.sleep(10)finally:
browser.close()
运行代码后发现,会自动弹出一个
Edge浏览器
。浏览器首先会跳转到百度,然后在搜索框中输入
Python
,接着跳转到搜索结果页
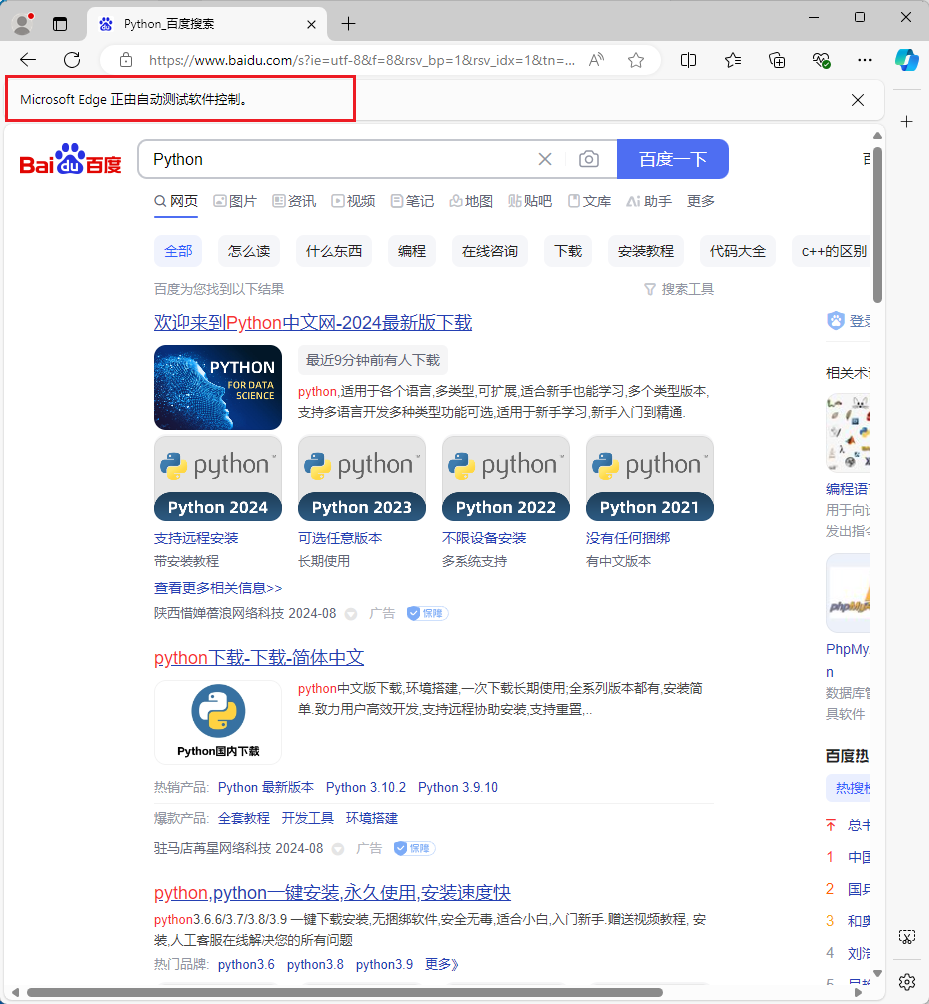
此时在控制台的输出结果如下:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Python&fenlei=256&rsv_pq=0xdbcfb43a003429a9&rsv_t=31cbuoEEKDf8sZW7evt6cGLKtK65yWOTbPzgAwIh%2B4V547pTsNBewlyZicS%2F&rqlang=en&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug2=0&rsv_btype=i&inputT=54&rsv_sug4=54
源代码过长,在此省略。可以看到,我们得到的当前 URL、Cookies 和源代码都是浏览器中的真实内容。
所以说,如果用 Selenium 来驱动浏览器加载网页的话,就可以直接拿到 JavaScript 渲染的结果了,不用担心使用的是什么加密系统。
Selenium 元素定位
Selenium有许多方法对页面的元素进行定位,你可以根据自己的需要选择最合适的一种。Selenium提供了下面的方法进行元素定位:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
寻找多个元素(下列方法会返回一个
list
,其余使用方式相同):
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name*
find_elements_by_css_selector
除了上面这些公有的方法,我们还有2个私有的方法来帮助页页面对象的定位。这两个方法就是
find_element
和
find_elements
:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH,'//button[text()="Some Text"]')
driver.find_elements(By.XPATH,'//button')
By
类的可用属性如下:
ID
“id”XPATH“xpath”LINK_TEXT“link text”PARTIAL_LINK_TEXT“partial link text”NAME“name”TAG_NAME“tag_name”CLASS_NAME“class name”CSS_SELECTOR“css selector”
实战使用Selenium爬取淘宝数据
导入要使用的库
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from urllib.parse import quote
from lxml import etree
import pandas as pd
访问淘宝商品搜索页面
url=f"https://uland.taobao.com/sem/tbsearch"
browser = webdriver.Edge(executable_path="msedgedriver.exe")
wait = WebDriverWait(browser,10)
browser.get(url)print(browser.page_source)
等待片刻会看到打开了selenium自动控制,并且跳转到taobao的url上面
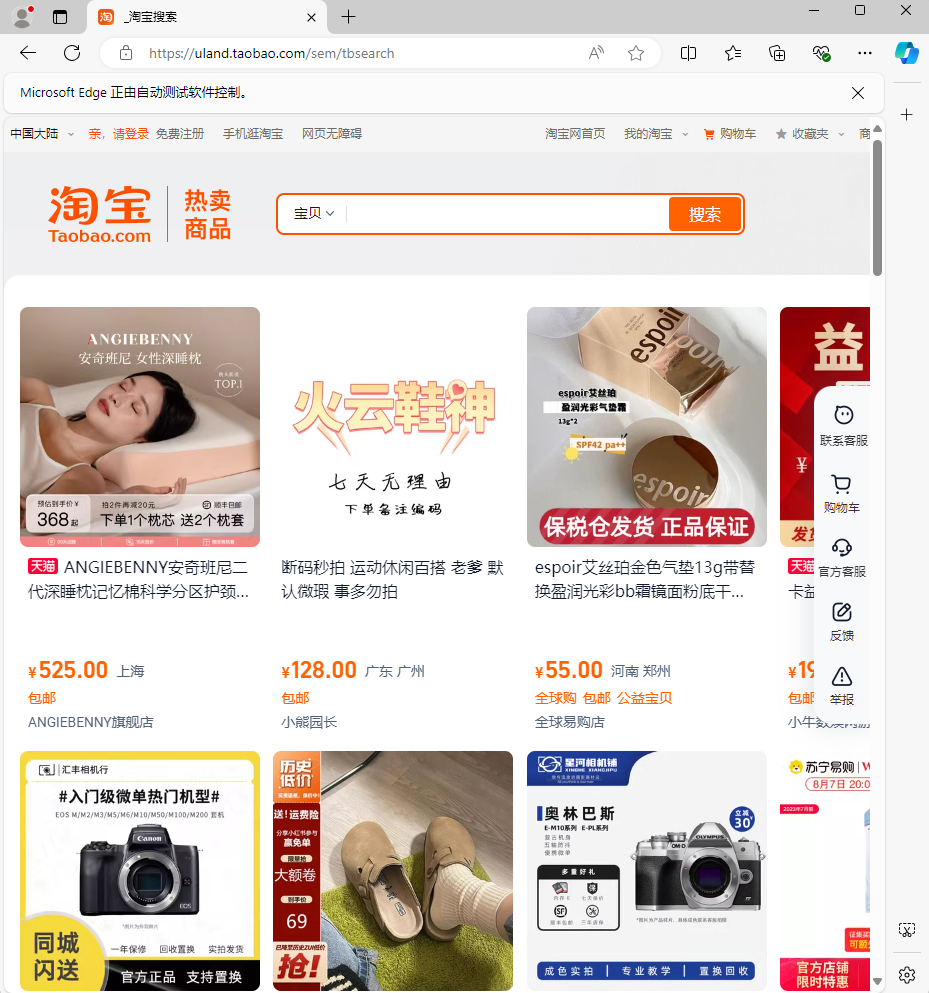
我们不要关闭打开的浏览器继续进行操作,使用代码在搜索框中输入我们想搜索的内容
keyword="笔记本"input= wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="q"]')))input.send_keys(keyword)
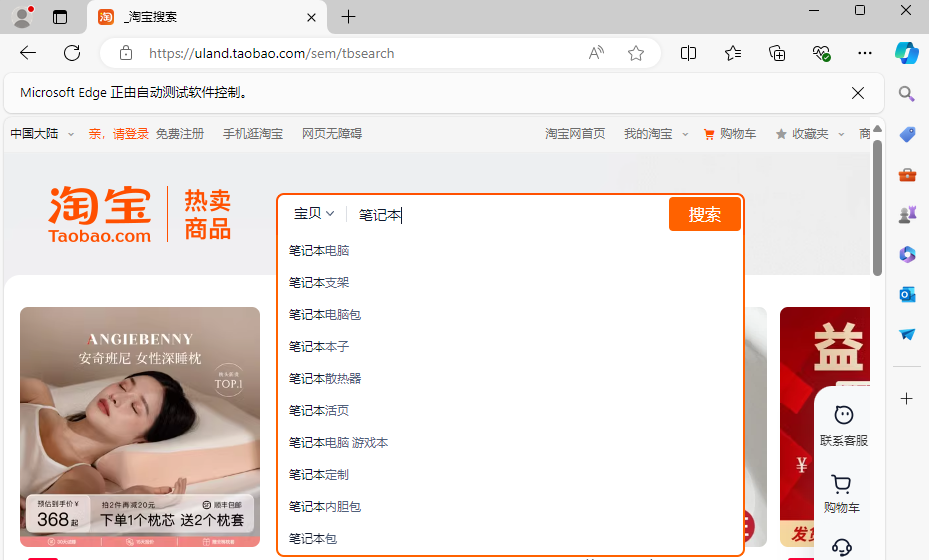
工具成功进行输入,接下来我们控制点击搜索按钮
sousu_btn=browser.find_element(By.CLASS_NAME,'btn-search')
sousu_btn.click()
浏览器成功进行搜索
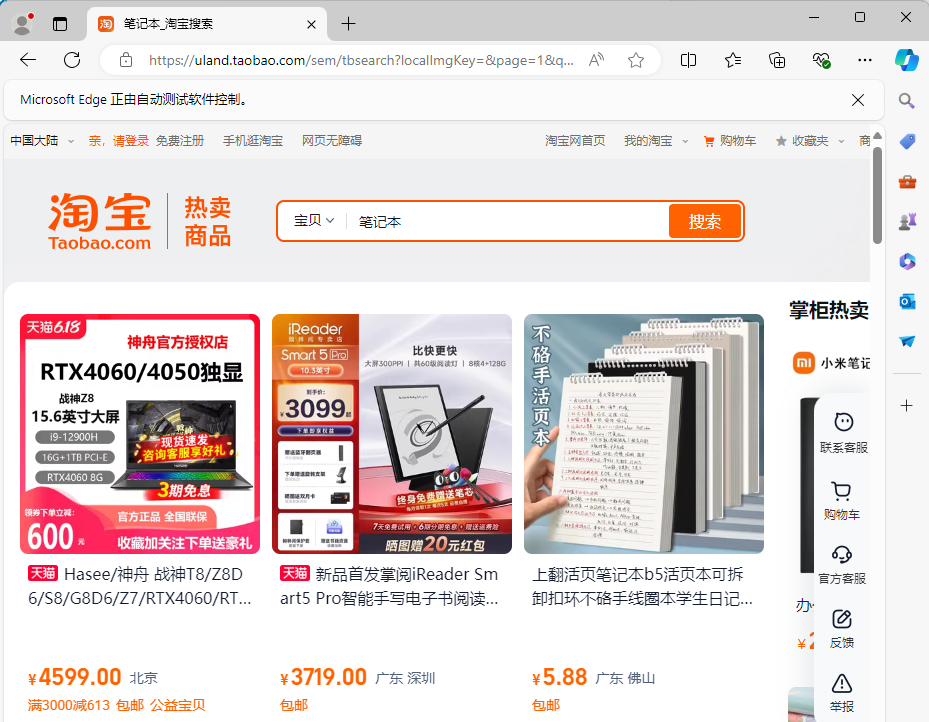
为了模拟人为进行操作,我们需要控制滚动条的移动,我们使用selenium执行js脚本的方法,来控制滚动条。
browser.execute_script("window.scrollTo(0, 6500)")
其中
window.scrollTo(0, 6500)
,0表示横坐标,6500表示纵坐标。
我们控制滚动条不断下移,然后界面自然会加载出对应的商品内容。现在我们只需要获得商品的信息就大功告成了。
在这里,我们使用上个教程所涉及到的lxml来分析网页
etree_html = etree.HTML(browser.page_source)
imgs=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[1]/img/@src')
title=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[2]/div/span/text()')
priceInt=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[1]/span[1]/text()')
priceFloat=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[1]/span[2]/text()')
place1=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[2]/span/text()')
place2=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[3]/span/text()')
storename=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[3]/div/a/text()')
storename
使用xpath路径来获取商品相关的内容
最后一步我们点击下一页来进行翻页
next_page=browser.find_element(By.XPATH,'//*[@id="pageContent"]/div[1]/div[2]/div[2]/div[1]/div/button[2]')
next_page.click()
将上述分析整理为函数
import time
defcraw_keyword(keyword,page_num):# 获取page_num页的keyword物品信息input= wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="q"]')))input.send_keys(keyword)
sousu_btn=browser.find_element(By.CLASS_NAME,'btn-search')
sousu_btn.click()
time.sleep(2)
flag=True
count=0
imgs=[]
titles=[]
priceInts=[]
priceFloats=[]
place1s=[]
place2s=[]
storenames=[]while flag:# 模拟人进行浏览for i inrange(1,8):
browser.execute_script(f'window.scrollTo(0,{i*1000-500})')
time.sleep(0.5)
etree_html = etree.HTML(browser.page_source)# 获取信息
img=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[1]/img/@src')
title=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[2]/div/span/text()')
priceInt=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[1]/span[1]/text()')
priceFloat=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[1]/span[2]/text()')
place1=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[2]/span/text()')
place2=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[1]/div[4]/div[3]/span/text()')
storename=etree_html.xpath('//*[@id="pageContent"]/div[1]/div[2]/div[1]/div/div/a/div/div[3]/div/a/text()')
imgs.extend(img)
titles.extend(title)
priceInts.extend(priceInt)
priceFloats.extend(priceFloat)
place1s.extend(place1)
place2s.extend(place2)
storenames.extend(storename)# 点击下一页
next_page=browser.find_element(By.XPATH,'//*[@id="pageContent"]/div[1]/div[2]/div[2]/div[1]/div/button[2]')
next_page.click()
time.sleep(5)
count+=1if count>=page_num:
flag=Falsebreakreturn imgs,titles,priceInts,priceFloats,place1s,place2s,storenames
获取信息并进行保存
keyword="笔记本电脑"# 关键词
pages=5# 获取几页的数据
imgs,titles,priceInts,priceFloats,place1s,place2s,storenames=craw_keyword(keyword,pages)
data=pd.DataFrame({"img_url":imgs,"titles":titles,"preceInt":priceInts,"priceFloats":priceFloats,"place1s":place1s,"storenames":storenames,})
data.to_csv('taobao.csv',index=False,encoding='utf-8')
data

创作不易,请关注GZH【阿欣Python与机器学习】,发送【爬虫】获取代码及数据。欢迎关注,共同探讨,共同进步!
本代码仅供编程科普教学、科研学术等非盈利用途。
请遵守国家相关法律法规和互联网数据使用规定。
请勿用于商业用途,请勿高频长时间访问服务器,请勿用于网络攻击,请勿恶意窃取信息,请勿用于作恶。
任何后果与作者无关。
版权归原作者 阿欣Python与机器学习 所有, 如有侵权,请联系我们删除。