
🌈键盘敲烂,年薪30万🌈
一、索引优化 回顾:
📕索引分类:
- 一般分类:主键索引、唯一索引、常规索引、全文索引
- 按存储分类:聚集索引、二级索引
注意:
主键索引只能有一个且必须有一个,二级索引可以有多个,如果没有主键,选唯一索引作为主键索引,如果没有唯一索引,那么mysql会创建一个隐藏字段rowid作为索引。
📕索引失效:
- 不满足最左前缀法则
- 索引列计算
- 字符串类型不加'' 导致类型转化
- 使用or连接了非索引的列
- %在最左边,>或<号
- 数据分布影响
📕设计原则:
尽量建立联合索引,针对于数据量大(超百万),查询多的表建索引,针对于where order by group by后的字段创建索引,如果字段很长,考虑前缀索引,如果索引列不能为NULL,须在数据库字段加上not null约束,这样优化器可以更好的选择更有效的索引。
📕SQL性能分析
- 执行频次
- 慢查询日志
- profile
- expplain执行计划
二、SQL优化 语句优化
📕 insert语句:
批量插入优化:
- 一次性插入多条数据,但是不建议超过1000条。
insert into user values(1, 'zhangsan'), (2,'lisi');
手动提交事务优化:
- 超过1000条,手动开启提交事务,减少与数据库的交互。
start transaction
insert into user values(1, 'zhagnsan'), (2, 'lisi'), ……
insert into user values(1000, 'wangwu'), (1001, 'zhaoliu') ……
……
commit
主键顺序插入优化:

大批量插入数据优化:
- load:插入百万数据到数据库
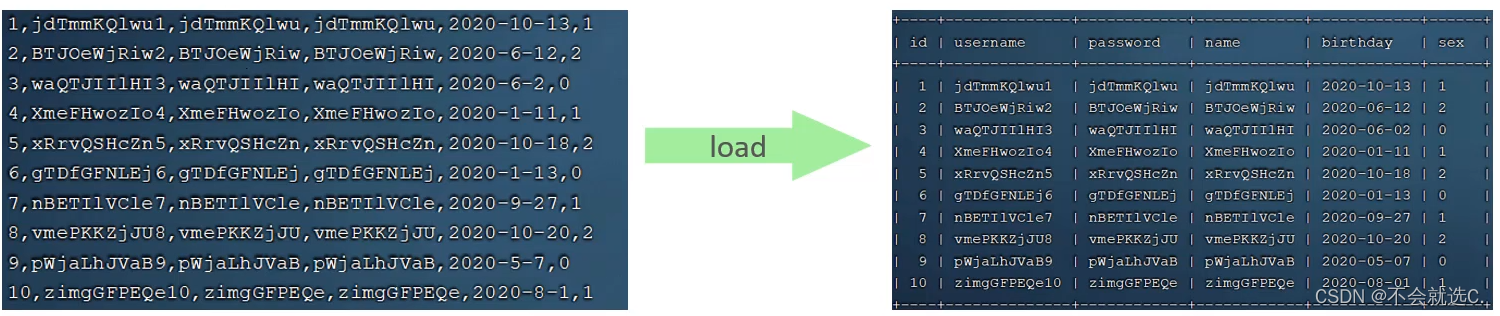
- load使用三步走:
1.连接数据库时加上:
--local-infile2.打开全局参数:
set global local infile = 1;3.插入数据的脚本:
load data local infile '/root/sql1.log' into table 'tb_user' fields terminated by ',' line terminated by '\n';
📕 主键优化:
前面提到了主键按顺序插入可提高性能,这里讲解原理。
(这里我不是很明白,摘自GPT的回答)
页分裂:
- 当在一个已满的页(节点)中插入一个新的键时,可能会导致该页不足以容纳新键,因此需要进行页分裂。
- 页分裂的过程涉及将原有的页分成两半,并将其中一半的部分移动到一个新的页中。这样就在原有页和新页之间创建了一个新的分隔键,用于指示两个页之间的分割。
- 页分裂的目的是确保树的平衡,并维护索引的有序性。它通常发生在B树或B+树中。
页合并:
- 与页分裂相反,页合并发生在删除操作后。当一个页的键减少到一个临界点以下时,可以考虑将其与相邻的页合并,从而减少索引树的高度。
- 页合并的过程涉及将两个相邻的页合并成一个,并且删除在合并过程中用于分隔的键。这有助于保持树的平衡,并且减少了树的高度,提高了检索效率。
- 页合并通常也发生在B树或B+树这样的平衡树结构中。
小结:
索引的设计原则:长度尽量短,尽量有序插入。
📕 order by优化:
优化准则:
- 如果创建索引的排序规则和要查询语句的排序规则相同,那么直接返回数据,效率高,如果不同,需要在缓冲区对相应的字段进行排序,效率不高。
注意:
创建索引默认是升序排序,asc
创建索引是指定排序规则
create index id_na_ty on tb_book(name asc, type asc);
例如:
一张tb_book表的索引
- 执行语句1(升序排序查询):
select id, name, type from tb_book order by name asc, type asc;
-- 直接返回索引下面挂的数据,效率高
查看执行过程:

- ** 执行语句2(name 升序 type 降序)**
select id, name, type from tb_book order by name asc, type desc;
-- 会在缓冲区进行排序,效率不高。
查看执行过程:

小总结:
order by 查询的字段要与建立索引时字段的排序规则相同,若不同,会在缓冲区排序然后返回数据,可以在创建索引时指定排序规则
📕 group by优化:
跟order by类似,建立好相应的索引,并且保证索引正确的使用规则,比如最左前缀法则。
📕 limit 优化
记住:覆盖索引加子查询:
原理:原本要对数据进行排序,在挑选50条数据,现在使用索引覆盖 + 子查询 先根据id排序,排完之后直接子查询就可以啦。
select * from user where limit 10000, 50;
-- 回表查询性能低
select t.* from user t, (select if from user where order by id limit 10000, 50) s where t.id = s.id;
-- 覆盖索引 + 子查询 性能略好
📕 count 优化
count统计非空字段数量,count无法优化,但是我们要区分count()括号里的字段的含义
- count(*):不取值,直接累加。
- count(主键):取出主键id,累加
- count(某个字段:有非空约束):取值,返回给服务层,服务层直接累加
- coutn(某个字段:无非空约束):取值,返回给服务层,服务层判断后累加。
- count(1):每行放一个1 并且累加,只要不是null都可以累加
小结:
尽量使用count(*)
📕 update 优化
- 更新的条件一定要有索引,否则行锁会标为表锁。
例如:user表 name字段带有索引
一个客户端执行:update user set name = 'Zhangsan' where name = 'Lisi';
一个客户端执行:update user set name = 'wangwu' where name = 'zhaoliu';
分析:
此时可以并发执行,因为索引对应的是行级锁,不会锁整张表,相反如果没有索引,或者索引失效,行级锁就会变为表锁,无法高并发。
本文转载自: https://blog.csdn.net/Panci_/article/details/134940278
版权归原作者 不会就选C. 所有, 如有侵权,请联系我们删除。
版权归原作者 不会就选C. 所有, 如有侵权,请联系我们删除。