
文章目录
一:虚拟机安装
如果没安装VMware Workstation的同学,在这之前,需要下载安装VMware Workstation平台,链接地址:VMware下载地址
点击创建新的虚拟机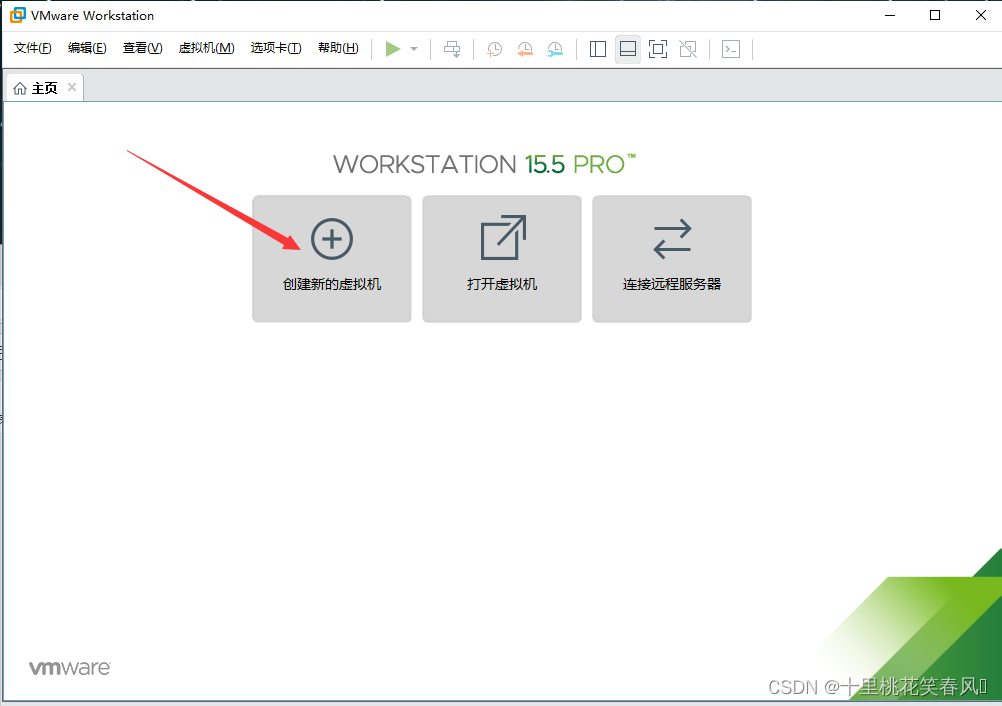
选择自定义,点击下一步!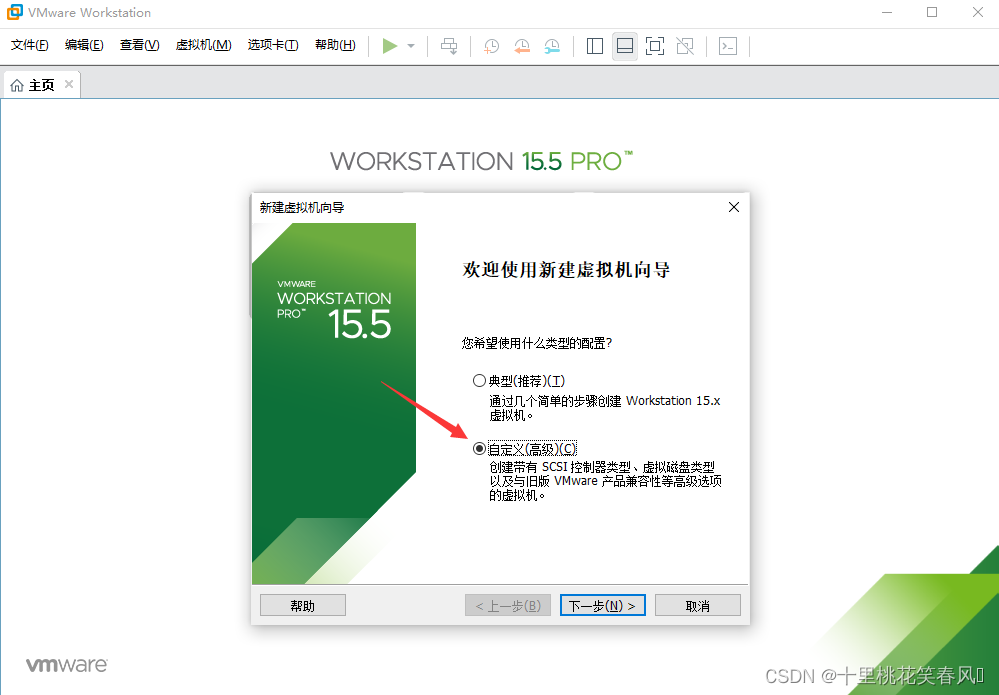
点击下一步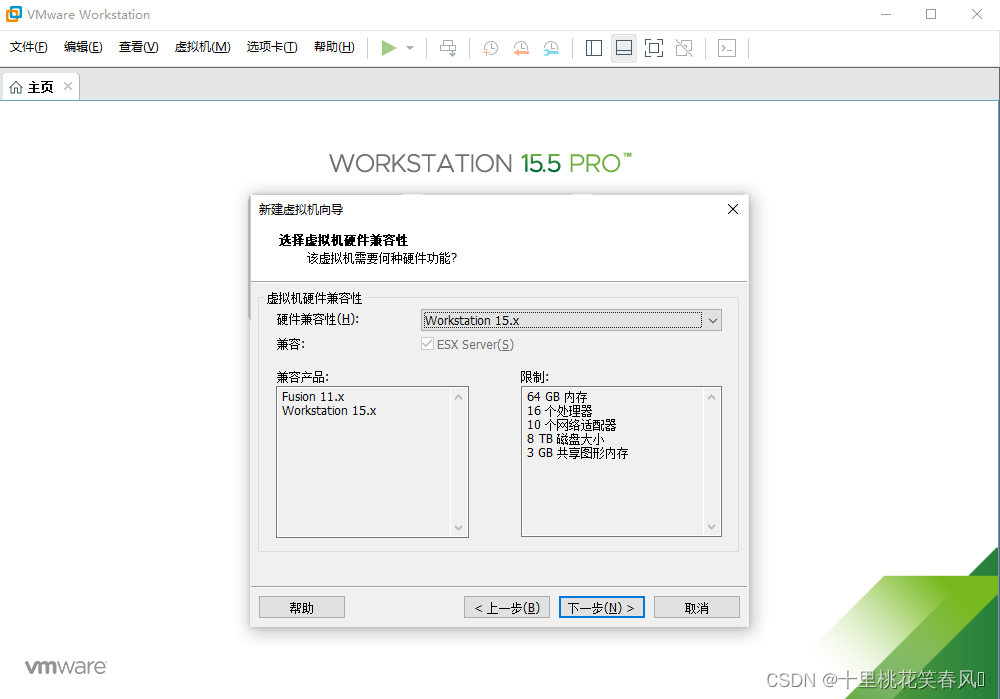 选择稍后安装操作系统,点击下一步
选择稍后安装操作系统,点击下一步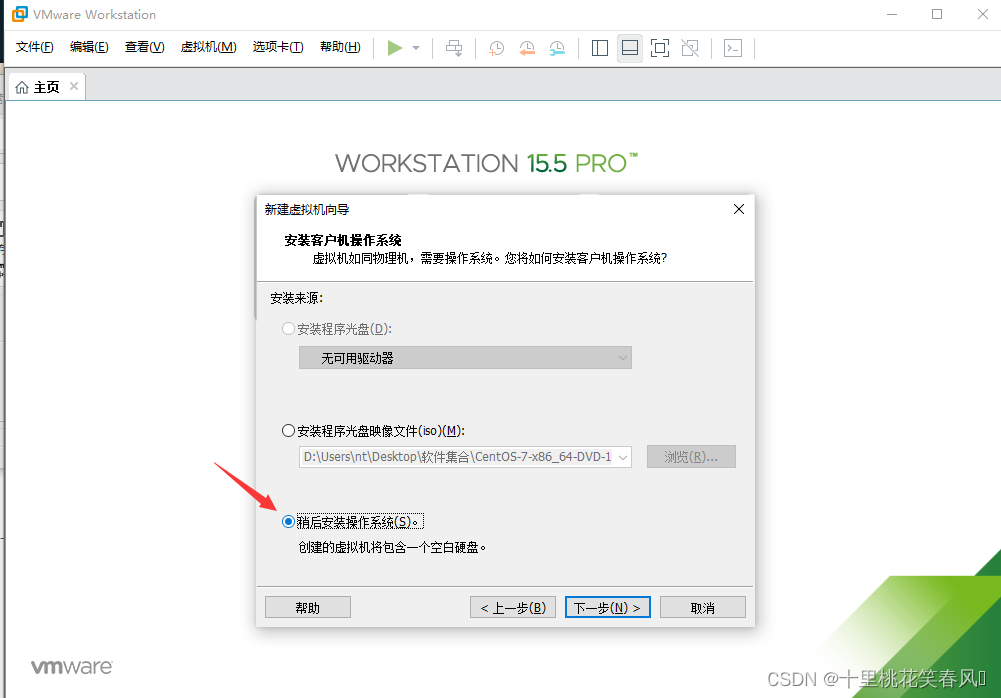
客户及操作系统选择Linux(L),版本(v)选择CentOS 7 64位,点击下一步
虚拟机名称可以改为master(表示主节点),安装位置自己选择(默认安装在c盘,建议选择磁盘内存较大的盘,这里选择安装路径尽量规范化,比如这台虚拟机名臣为master,我就创建了一个名称为master的文件夹,安装路径就选择它),点击下一步
处理器数量选择2就行了,每个处理器的内核数量选择1(一般来说够用,如果自身电脑配置较好,那么这里多选一两个也可以),点击下一步
此虚拟机的内存选择2G就行(一般够用,自己电脑内存足够大,可以多选一点),点击下一步
选择使用网络地址转换,点击下一步
选择LSI Logic(L),点击下一步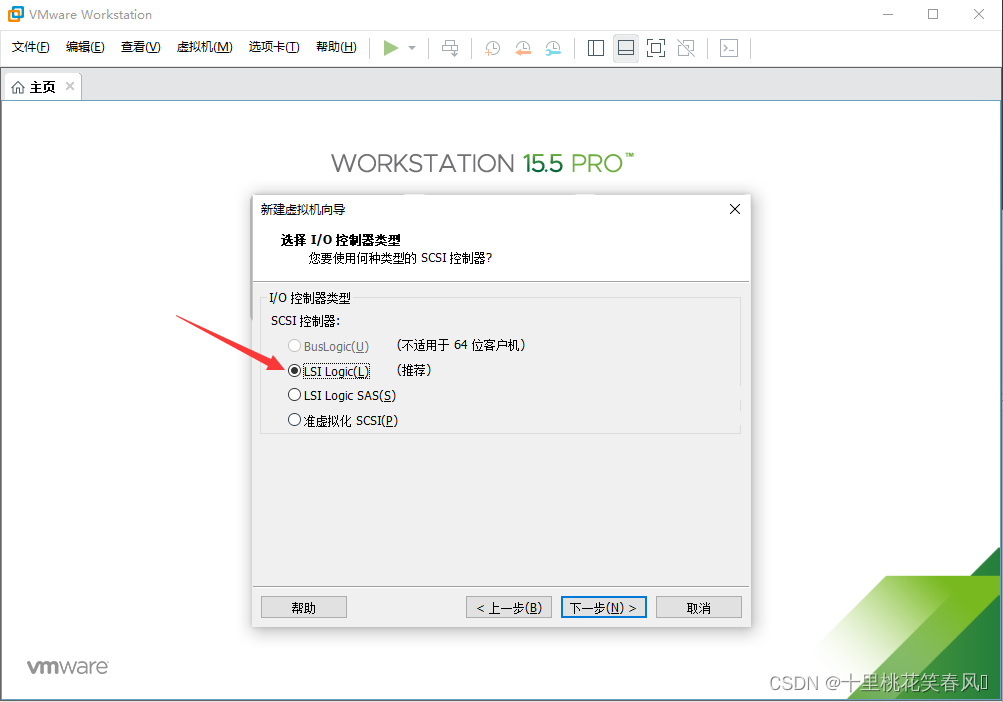
选择SCSI(S),点击下一步
选择创建新虚拟磁盘(V),点击下一步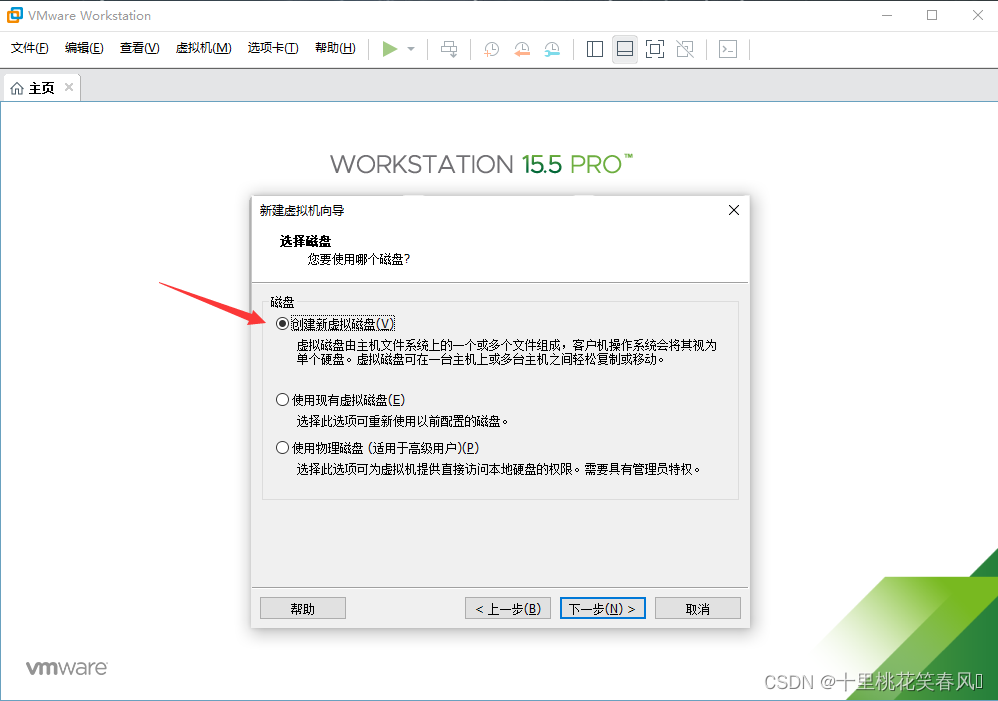
最大磁盘大小填30G(一般够用,自己电脑内存够大,可多填),选择将虚拟磁盘拆分成多个文件(M),点击下一步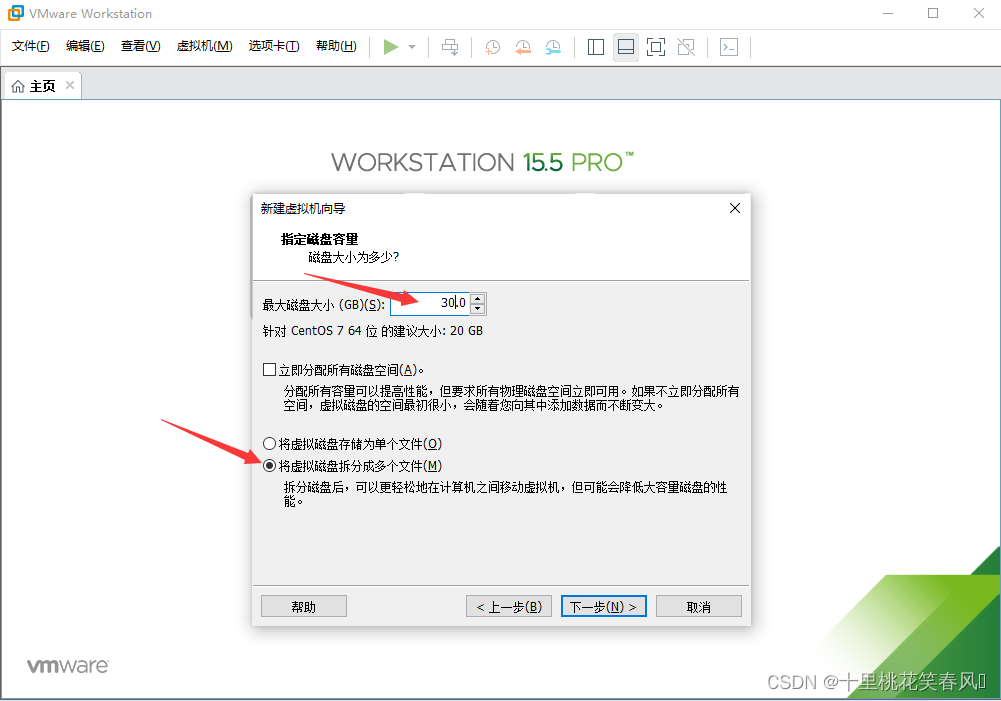
直接点击下一步
点击完成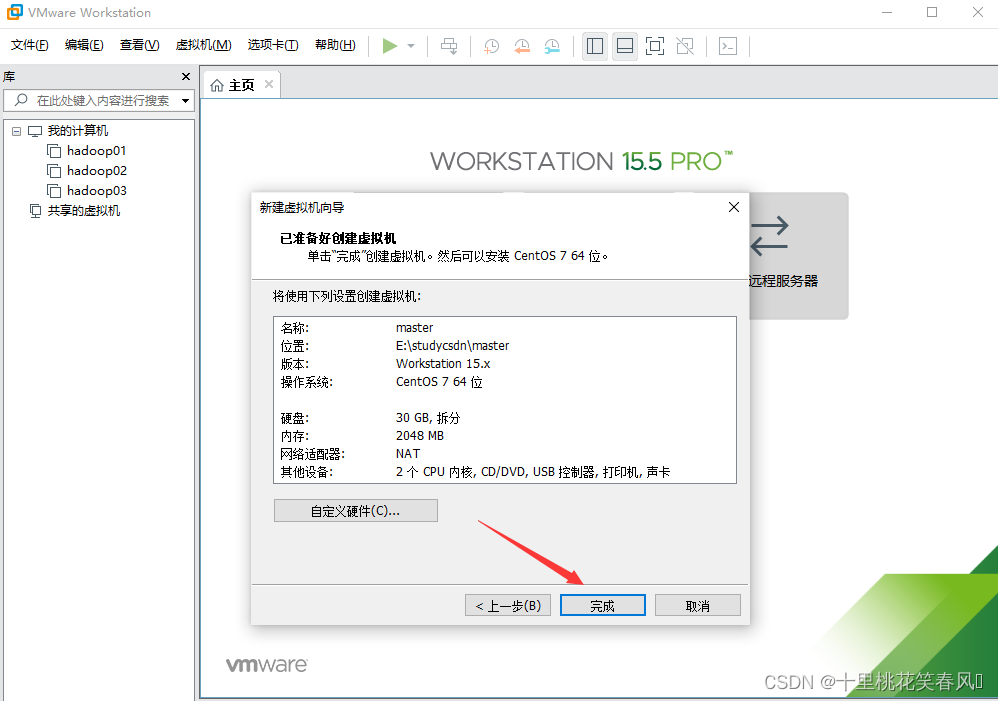
点击CD/DVD(IDE)
点击使用ISO映像文件(M),浏览选择CentOS的映像文件CentOS-7-x86_64-DVD-1708.iso(此文件需要自行下载)
下载链接:centos映像文件
USB控制器,声卡和打印机在这里用不上,可以选择他们点击移除,移除完点击确定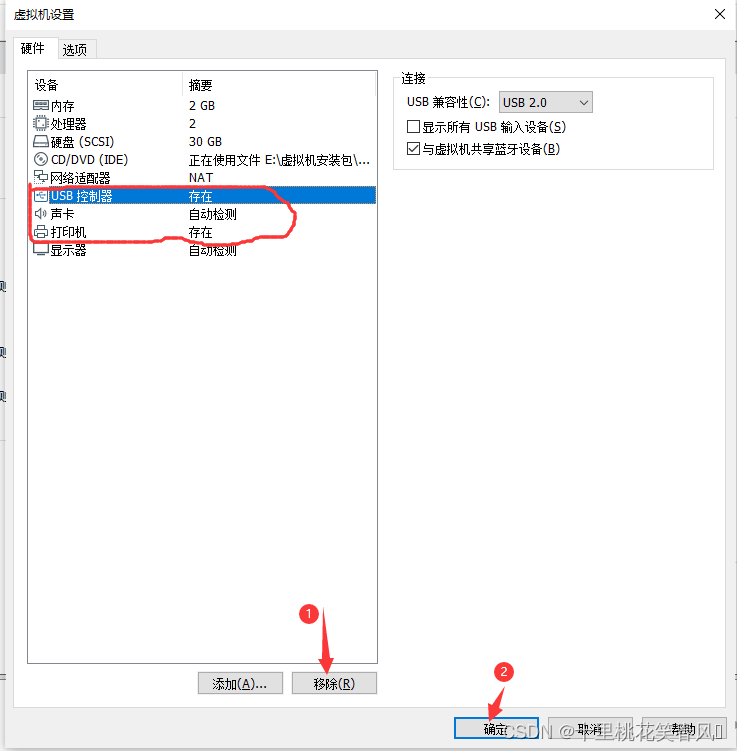
点击开启此虚拟机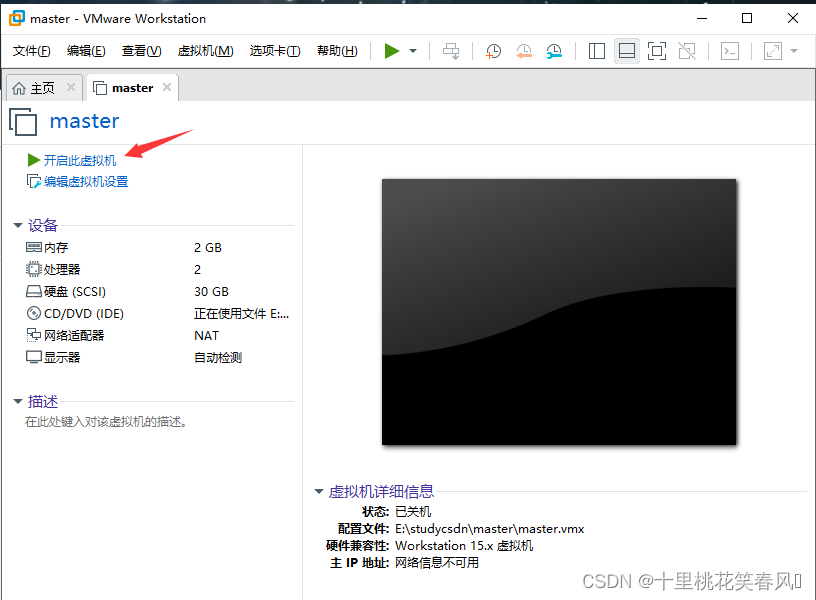
进入这个界面,鼠标点击这个界面,然后按上下键,选择第一个Install CentOS 7,然后按回车键即可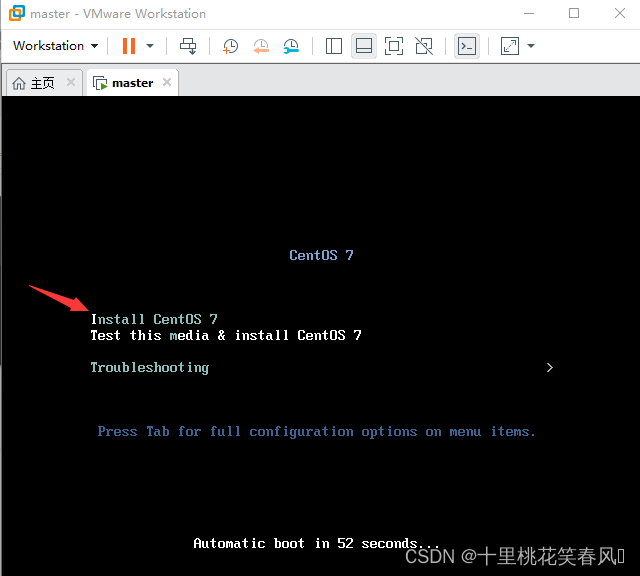
选择中文,然后点击继续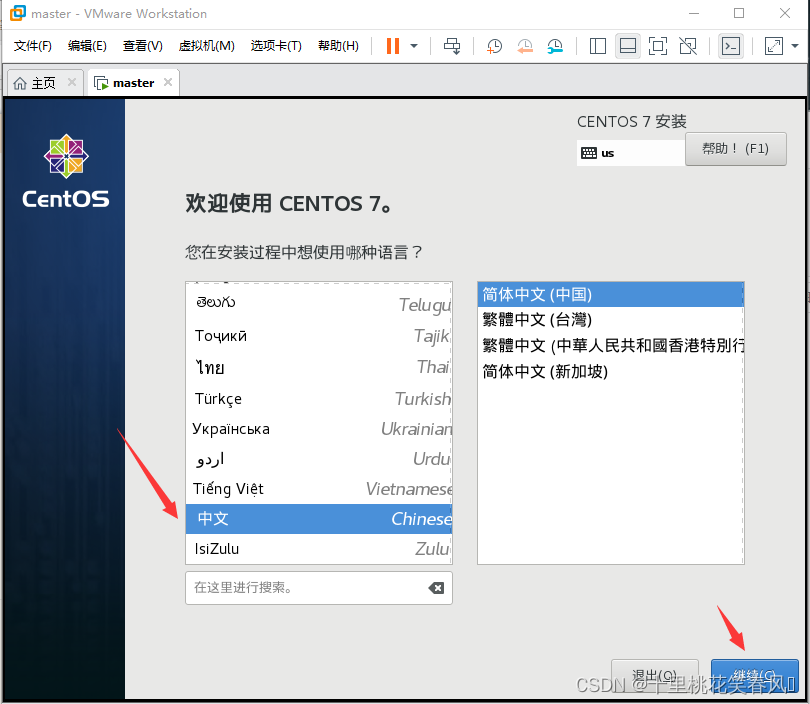
这个界面第一步点击日期和时间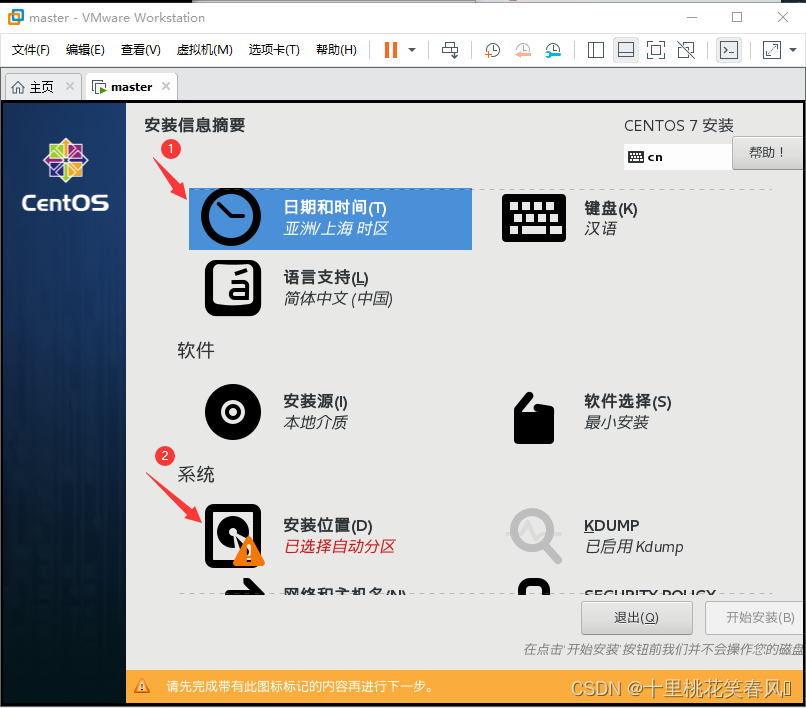
对比自己的windows系统的时间,设成一致,地区选择亚洲,城市选择上海,设置完成后,点击完成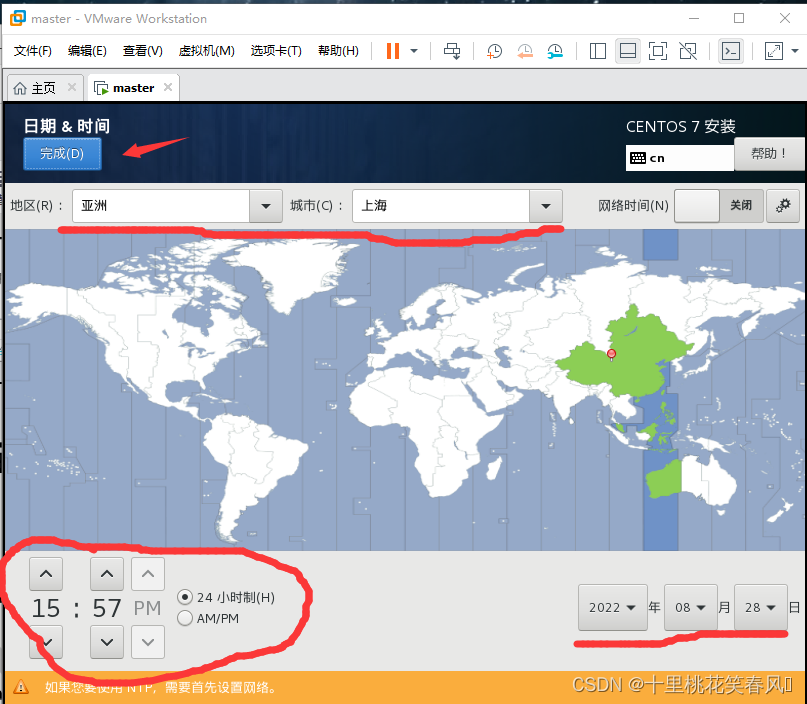
再进行第二步,点击安装位置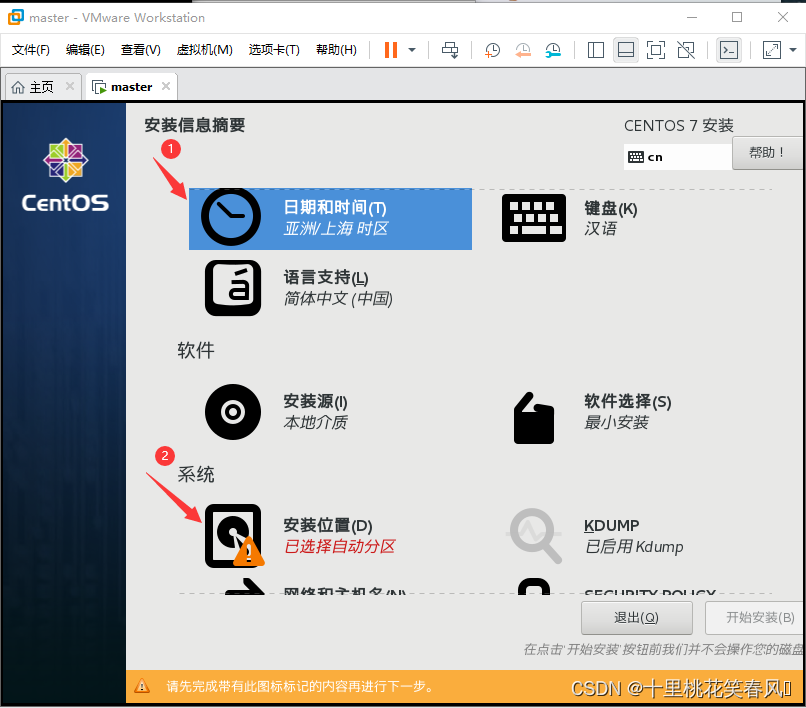
这个界面先点击我要配置分区,再点击完成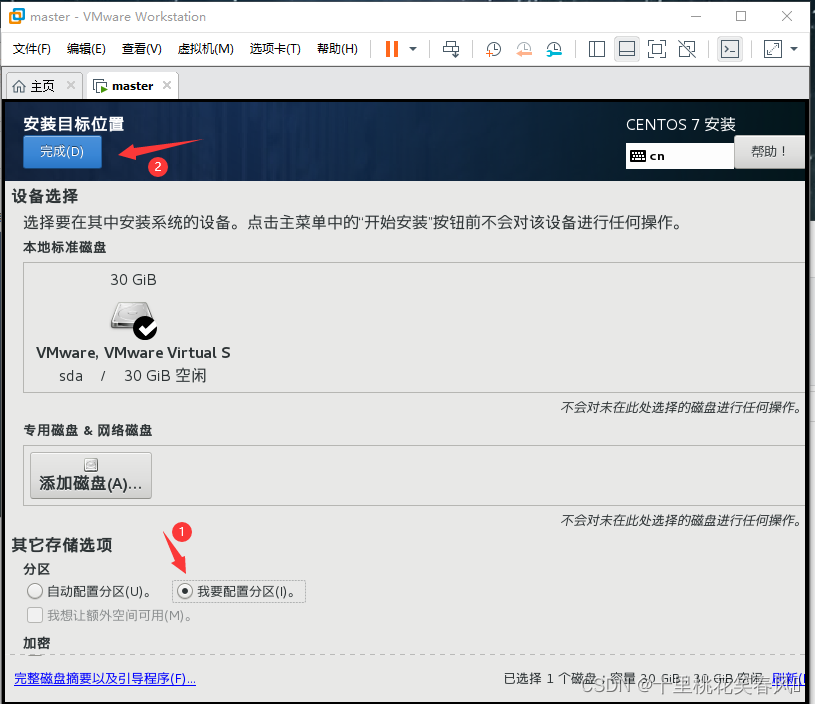
点击“+”添加挂载点
挂载点 /boot 期望容量512 ,然后点击添加挂载点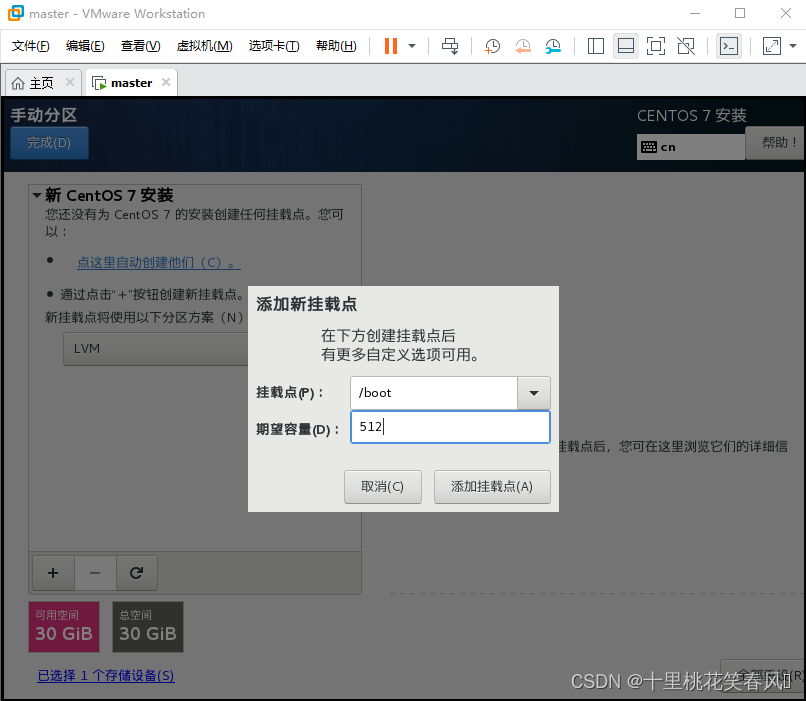
再次点击“+”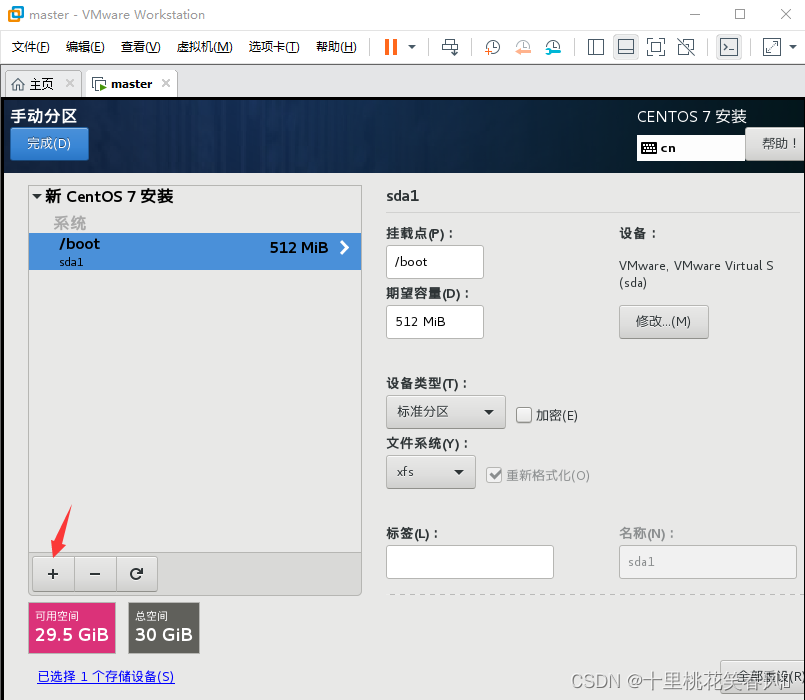
挂载点 swap 期望容量 4096 ,再点击添加挂载点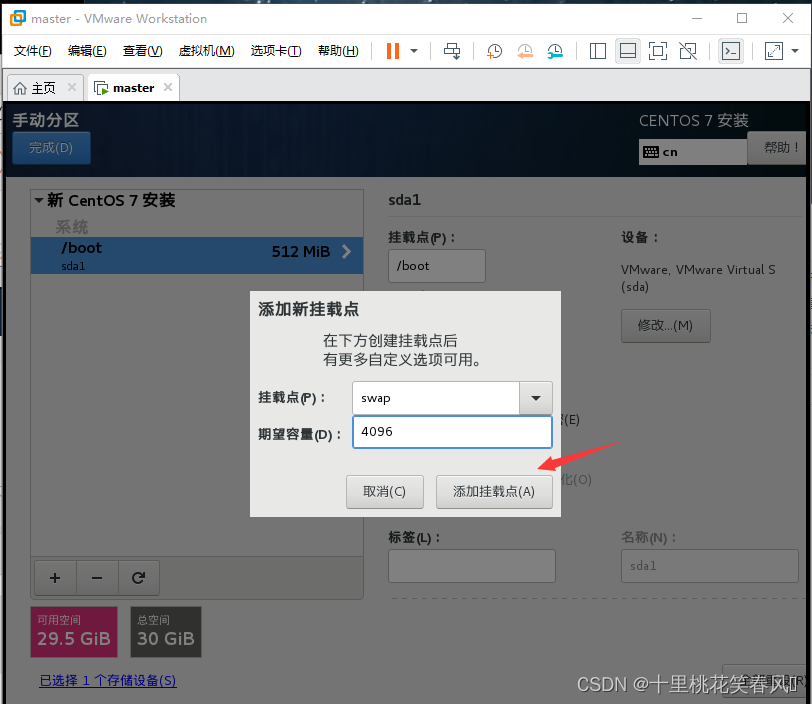
再点击“+”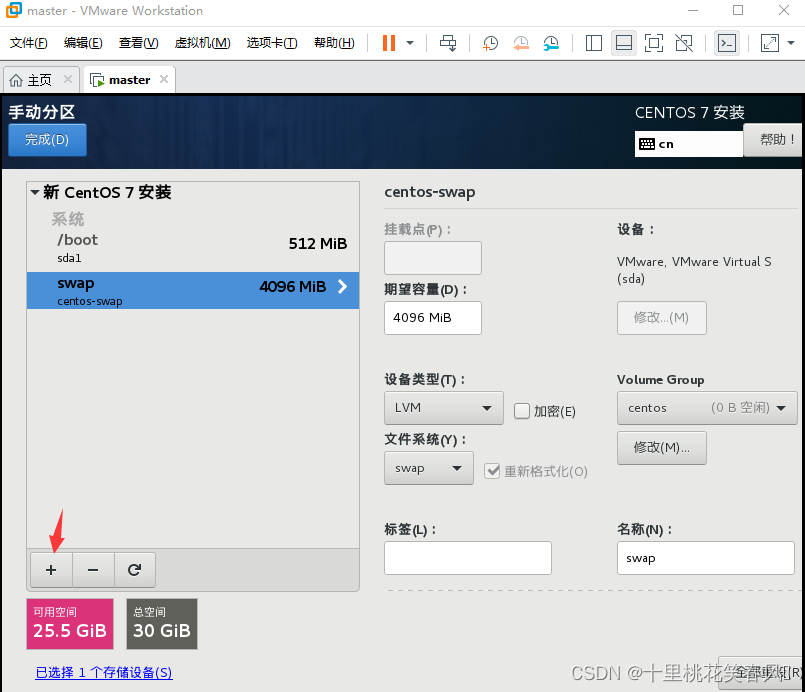
挂载点 / 期望容量不用填,直接点击添加挂载点
点击完成
点击接受更改
点击开始安装
点击ROOT密码
在这个界面自己设置一个密码,然后点击完成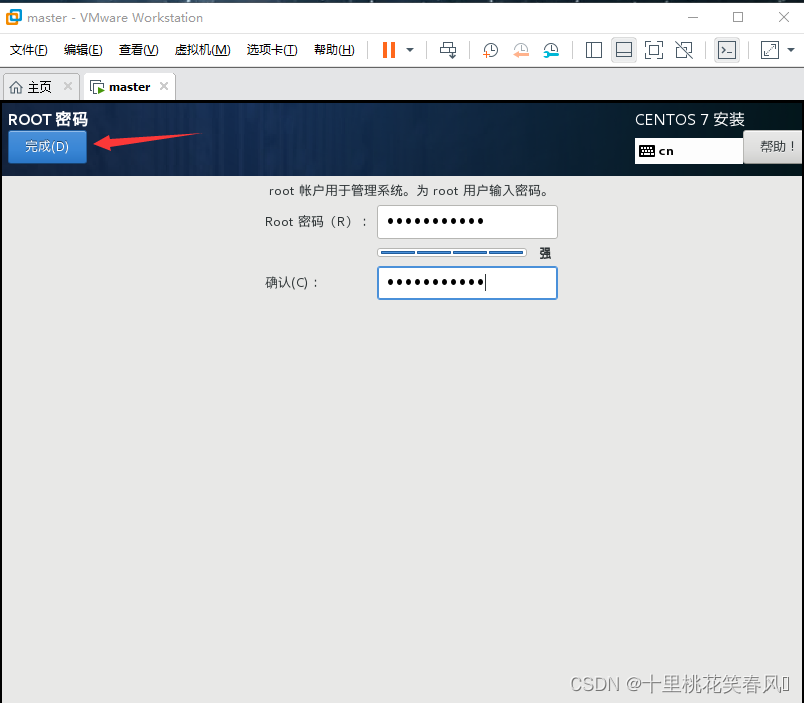
点击完成配置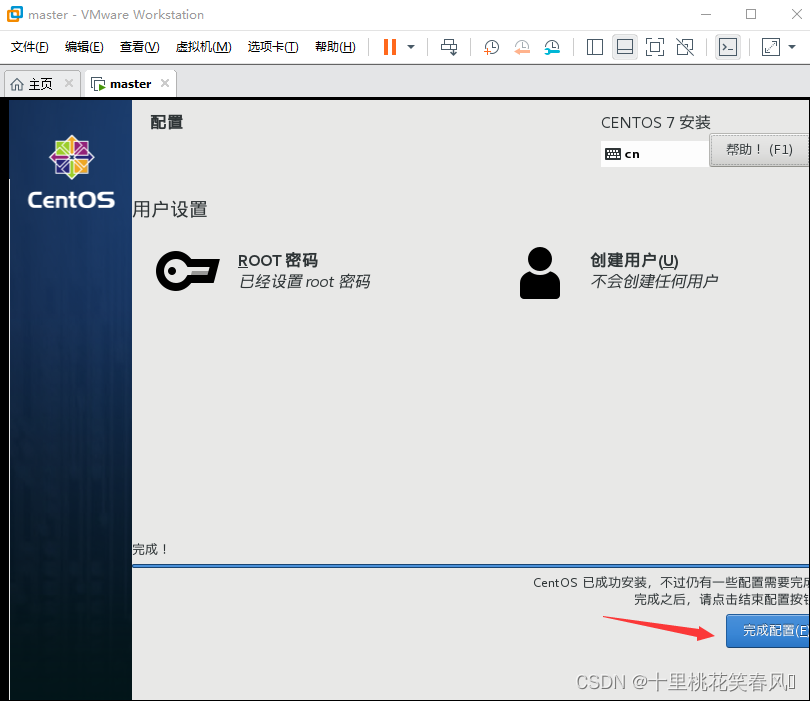
点击重启
到如下界面表示CentOS 7虚拟系统安装成功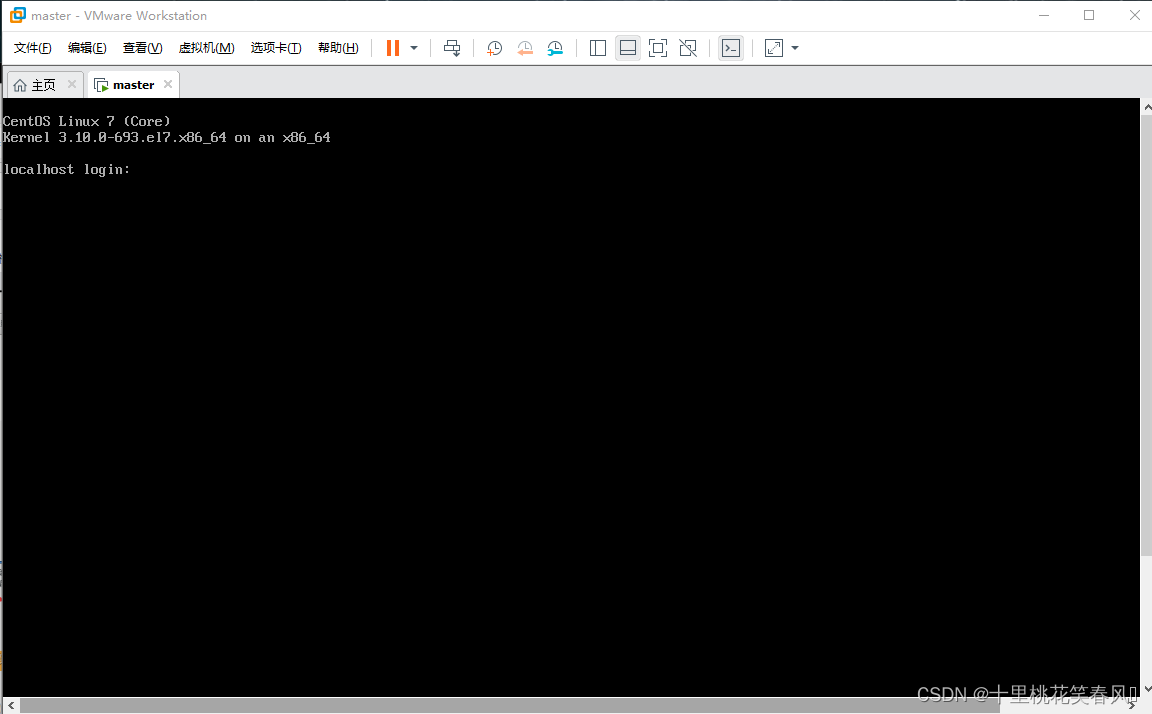
由于后面要搭建hadoop集群,需要三台服务器,所以我们需要克隆两台
鼠标指针移在虚拟机master上,单击鼠标右键,选择管理,再选择克隆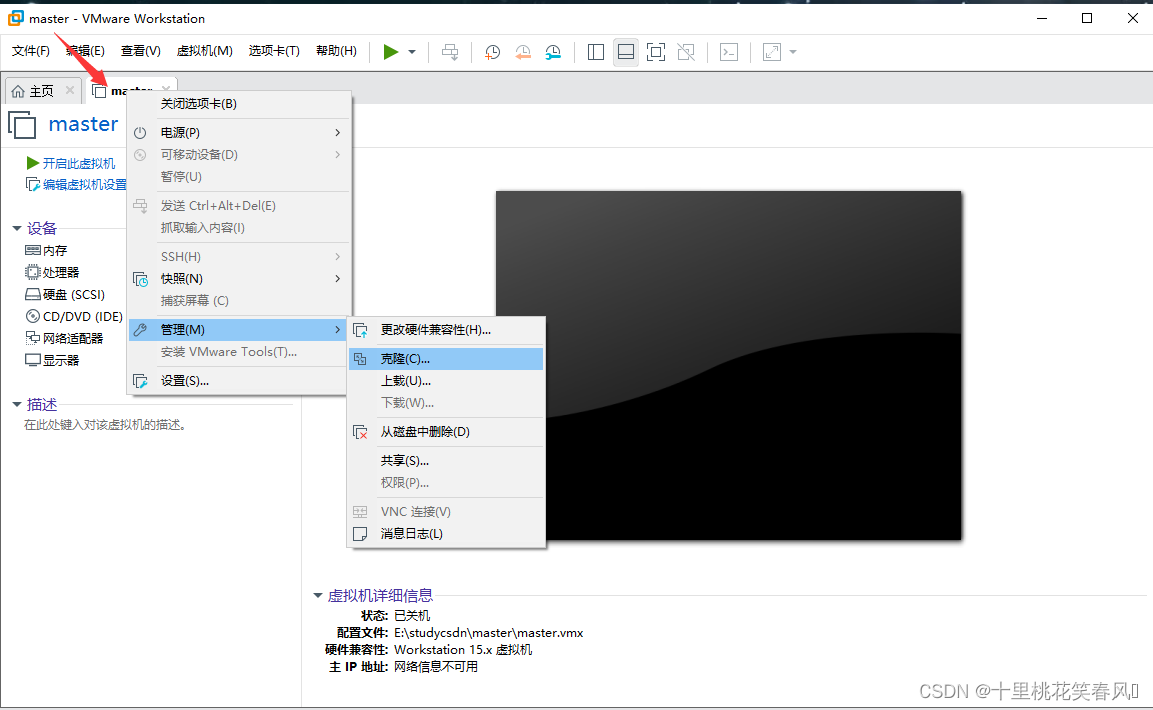
点击下一页
选择虚拟机中的当前状态,再点击下一页
选择创建完整克隆,再点击下一页
这里虚拟机名称填slave1(表示集群的从节点1),安装位置自己选择(默认安装在c盘,但不建议安装在c盘,自己最好文件夹分类,比如此节点为slave1,我安装的文件夹名称就为slave1),然后点击完成
重复上述克隆操作,克隆第二台虚拟机,名称为slave2(为hadoop集群的从节点2)
至此虚拟机的安装结束!
二:配网
1. 配置内网
点击编辑中的虚拟网络编辑器
选择VMnet8,再点击更改设置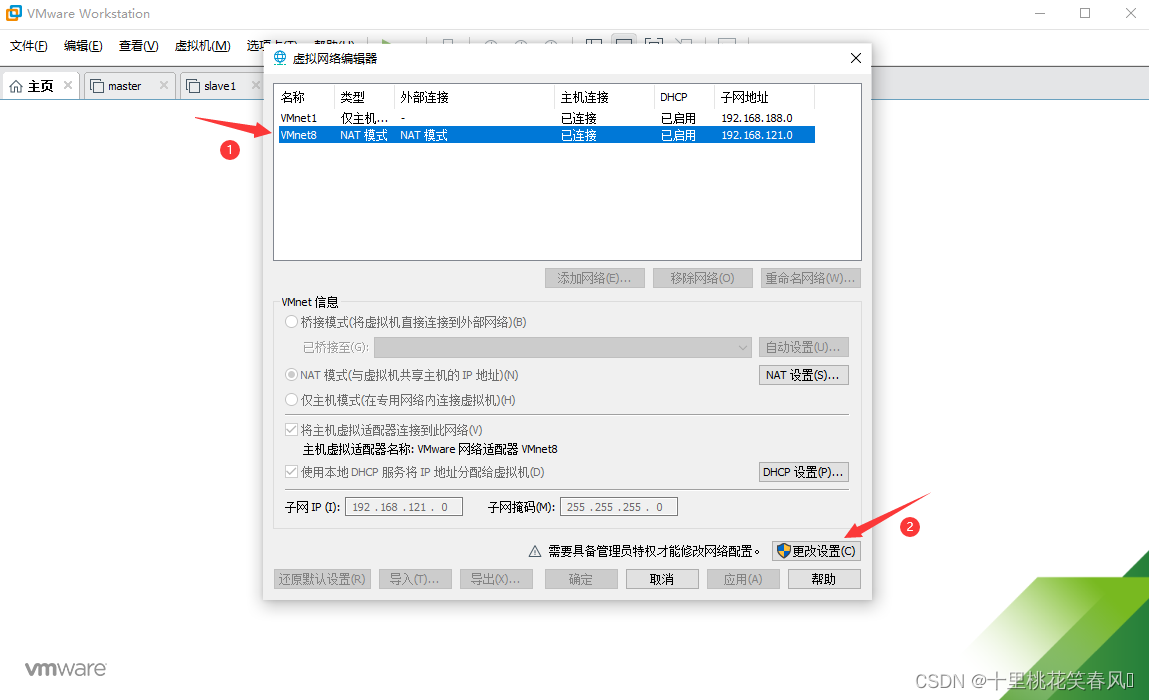
这个界面继续选择VMnet8,其余几个地方与标红处一样即可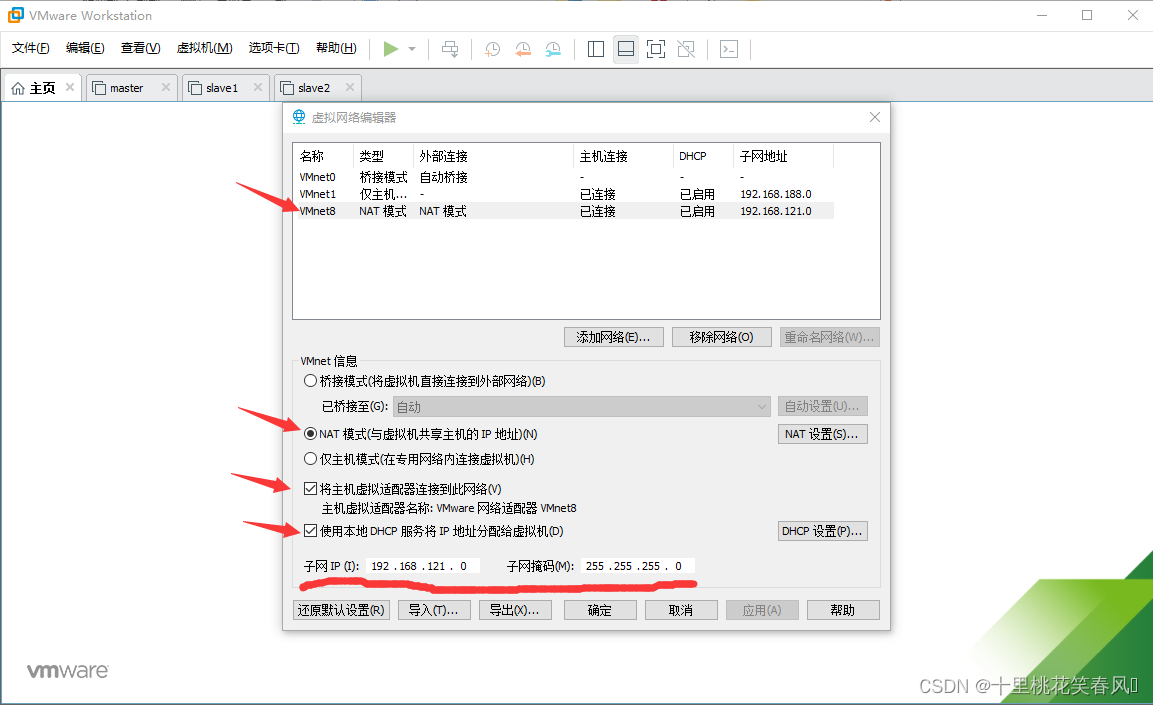
点击NAT设置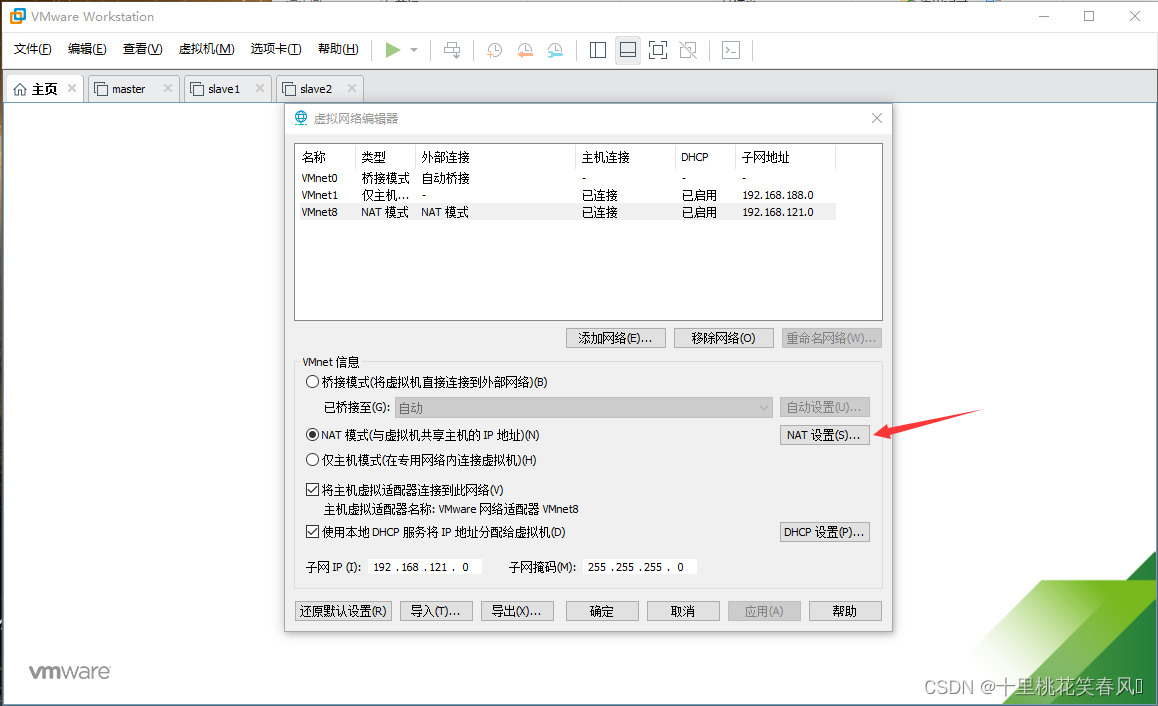
网关IP设置192.168.121.2 然后点击确定
点击DHCP设置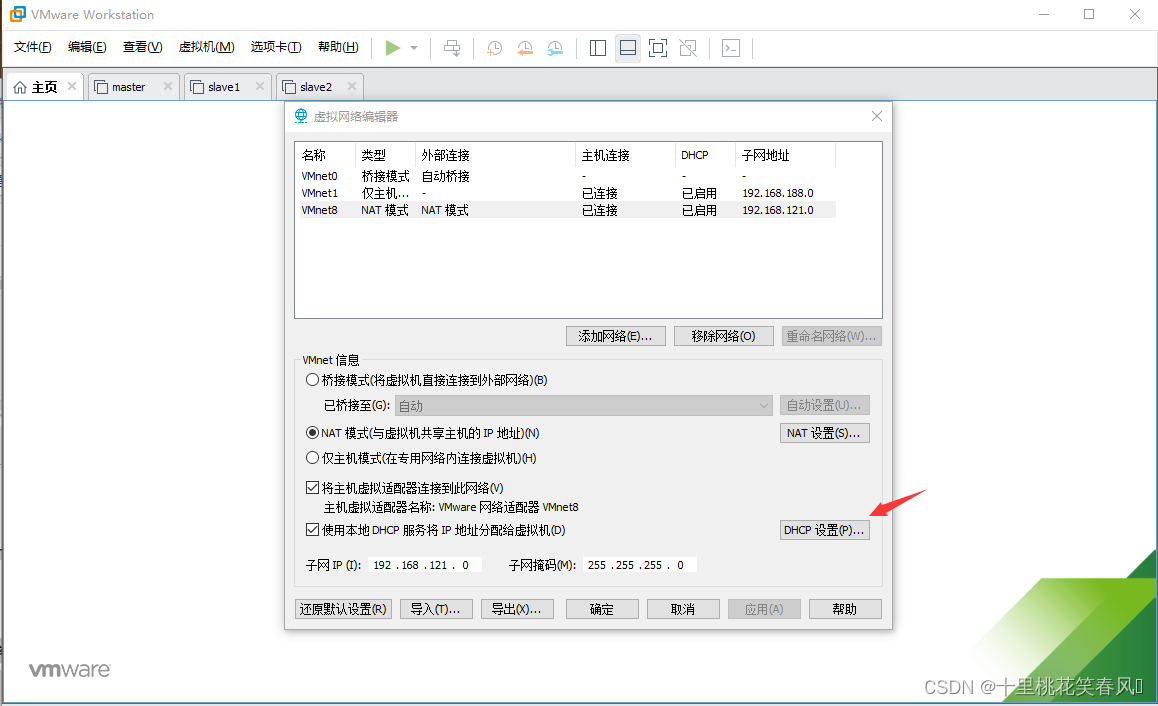
设置起始IP地址 192.168.121.128 结束IP地址 192.168.121.254(这里需要注意,后面使用虚拟机时,ip范围只能在128-254之间),然后点击确定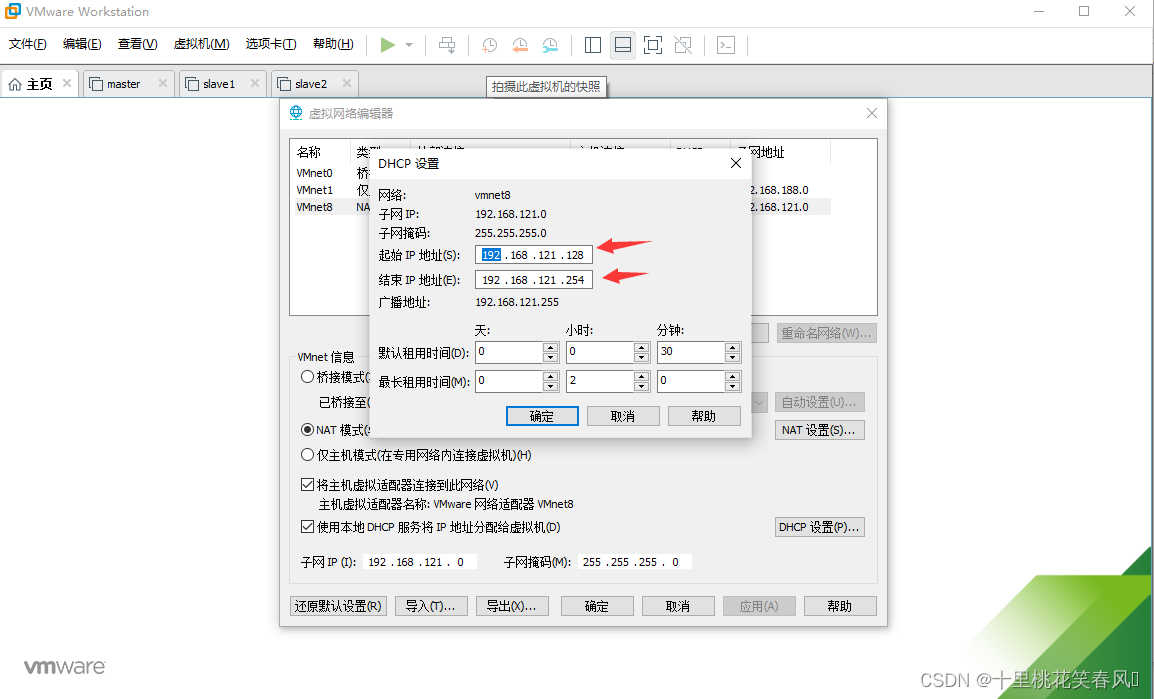
点击确定,至此内网已配置完毕!
2. 外网配置
点击WiFi中的网络和Internet设置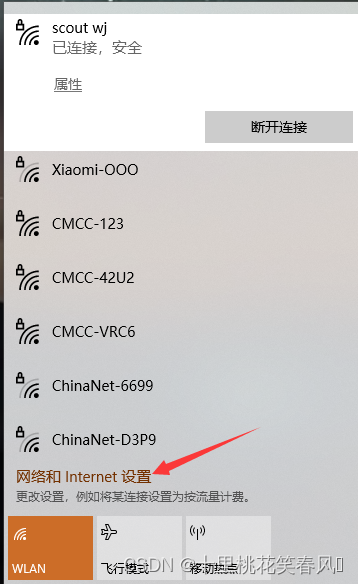
点击更改适配器选项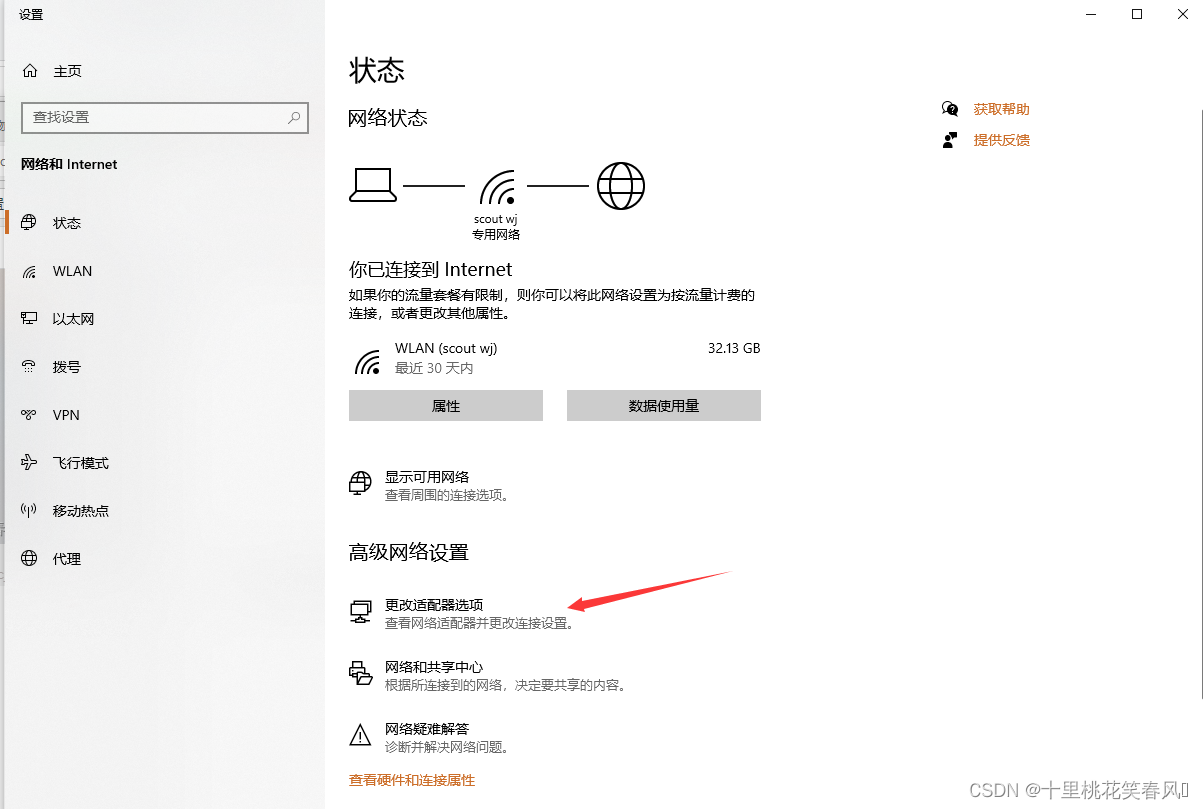
双击VMware Network Adapter VMnet8
点击属性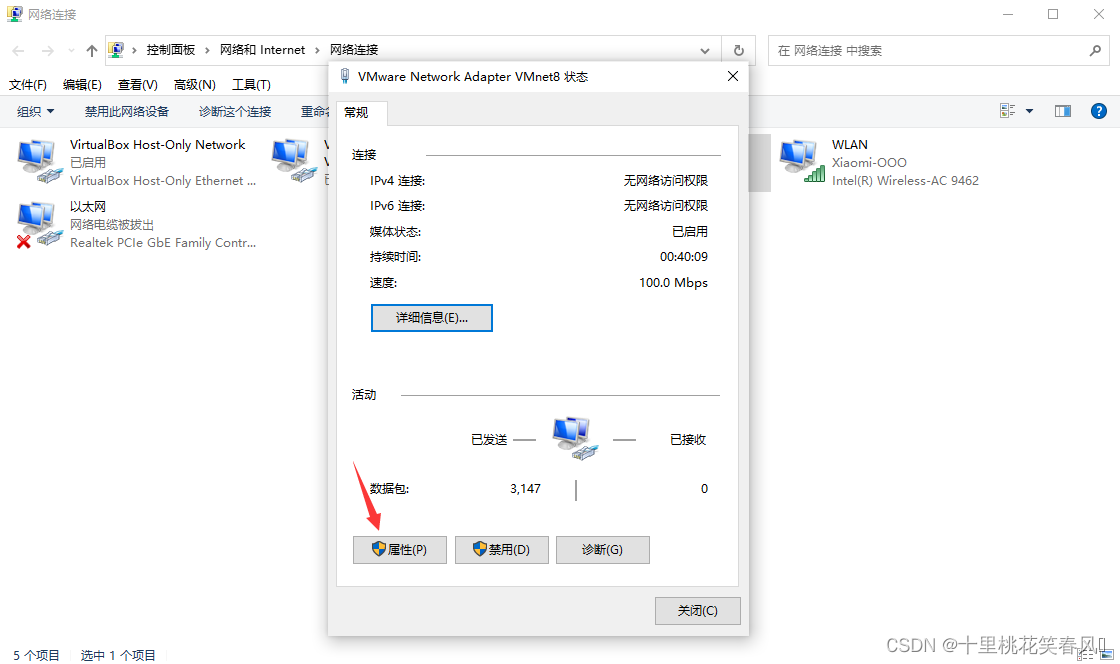
双击Internet协议版本4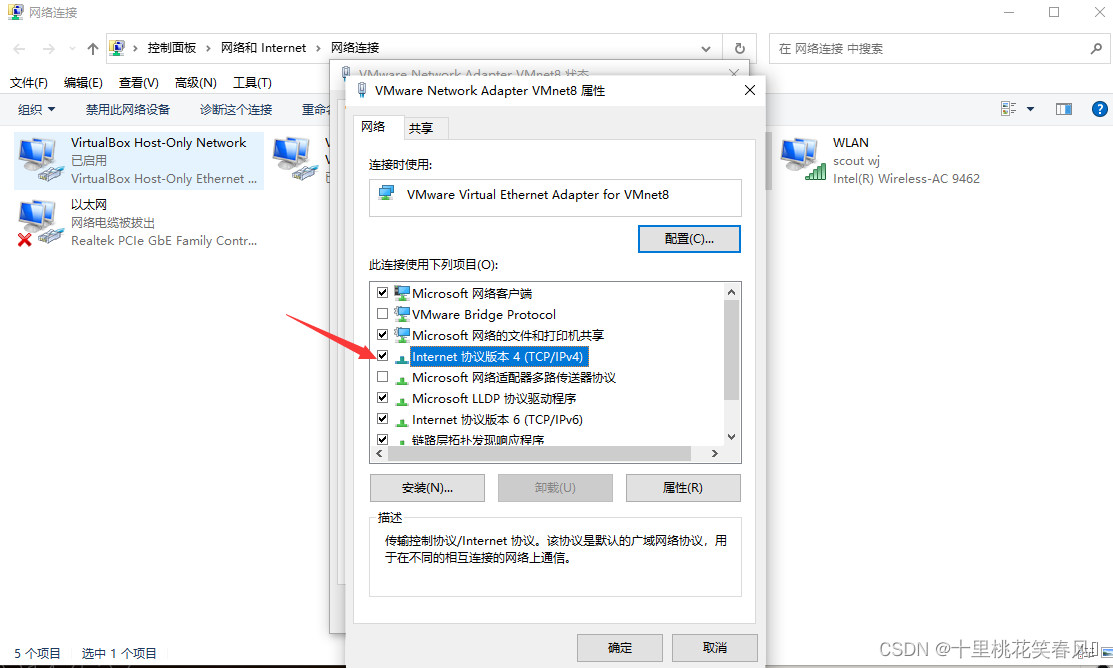
IP地址设置 192.168.121.1 子网掩码设置 255.255.255.0 默认网关设置 192.168.121.2
首选DNS服务器设置 8.8.8.8 如图所示设置,设置完后一次点击确定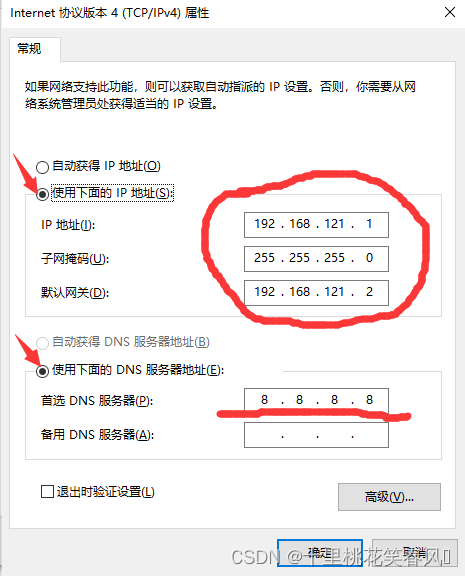
点击关闭,至此外网已经配置完毕
三:hadoop集群搭建
在这里先介绍两个软件,后面会用到
(1)xshell:简单说就是一个客户端,用于后续连接linux虚拟机,在xshell里面执行命令就等于在虚拟机内执行命令,基于xshell一些特定的功能,我们选择使用它。 下载链接:xshell下载
(2)xftp:简单说也是一个客户端,用于后续连接linux虚拟机,实现windows系统与linux系统的文件传输。 下载链接:xftp下载
上述都是官网下载,可能涉及到只能试用的情况,自己可以去百度下载破解版,或者直接找我共享。
1. 安装准备
1.1 准备工作
开启三台虚拟机
在localhost login后面输入
root
,然后敲回车键,再输入你的密码(这里输入密码时,密码不会显示),再敲回车键。(三台机子都执行)
来到这个界面,说明登录成功
输入
ifconfig
查看网络配置信息(三台机子都执行)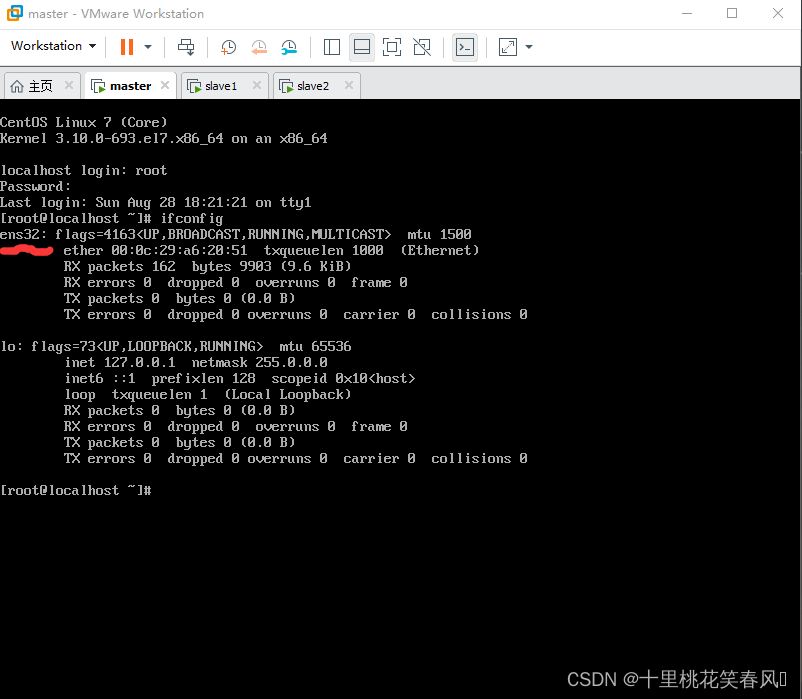
在主节点slave上输入
ifconfig ens32 192.168.121.141
,在从节点slave1上输入
ifconfig ens32 192.168.121.142
,在从节点slave2上输入
ifconfig ens32 192.168.121.143
,分别设置三台机子的临时IP(注意上一个图标红处是ens32就和上述代码一样,如果是ens33,那么就把代码中的ens32改成ens33,IP范围可随便设,但是不能超出128-254的范围,像我这样设置方便记忆)


至此,可以不用在VMware平台使用虚拟机执行命令了,我们将用到xshell远程连接虚拟机来执行命令
打开xshell软件,点击新建
为了方便操作,名称(N)处填写:master,主机(H)处填写主节点master的IP(就是我们上面所设置的临时IP:192.168.121.141)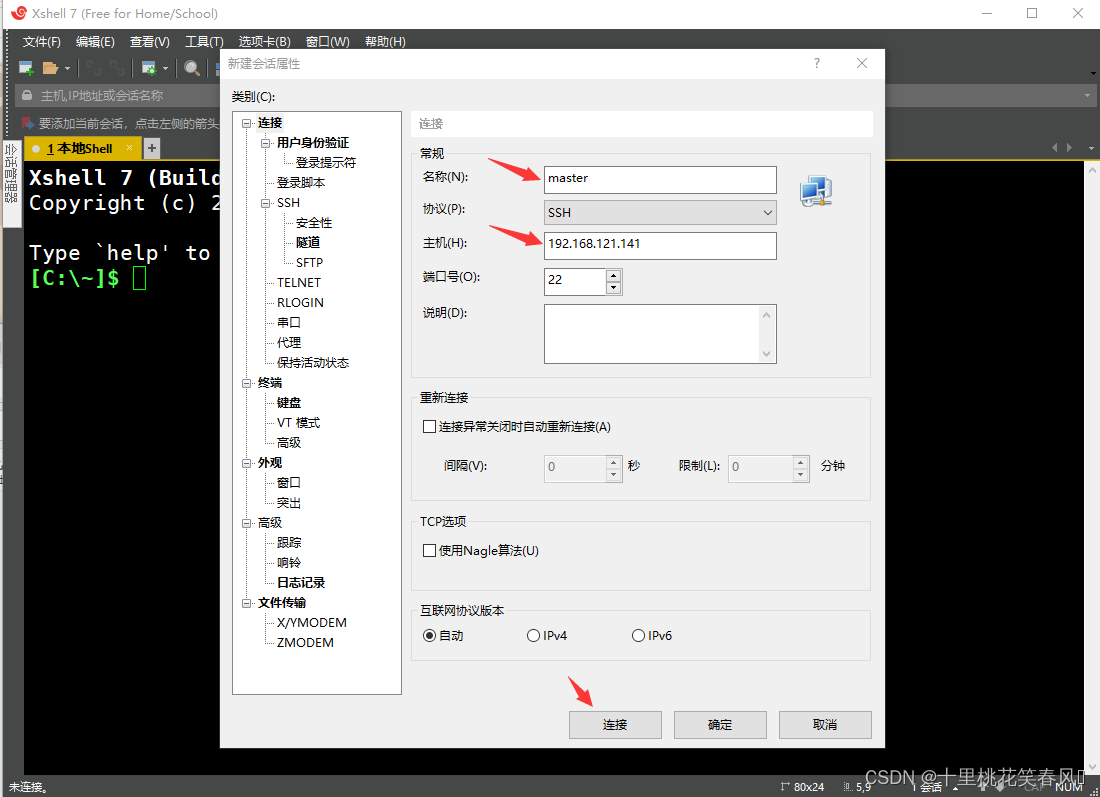
点击接受并保存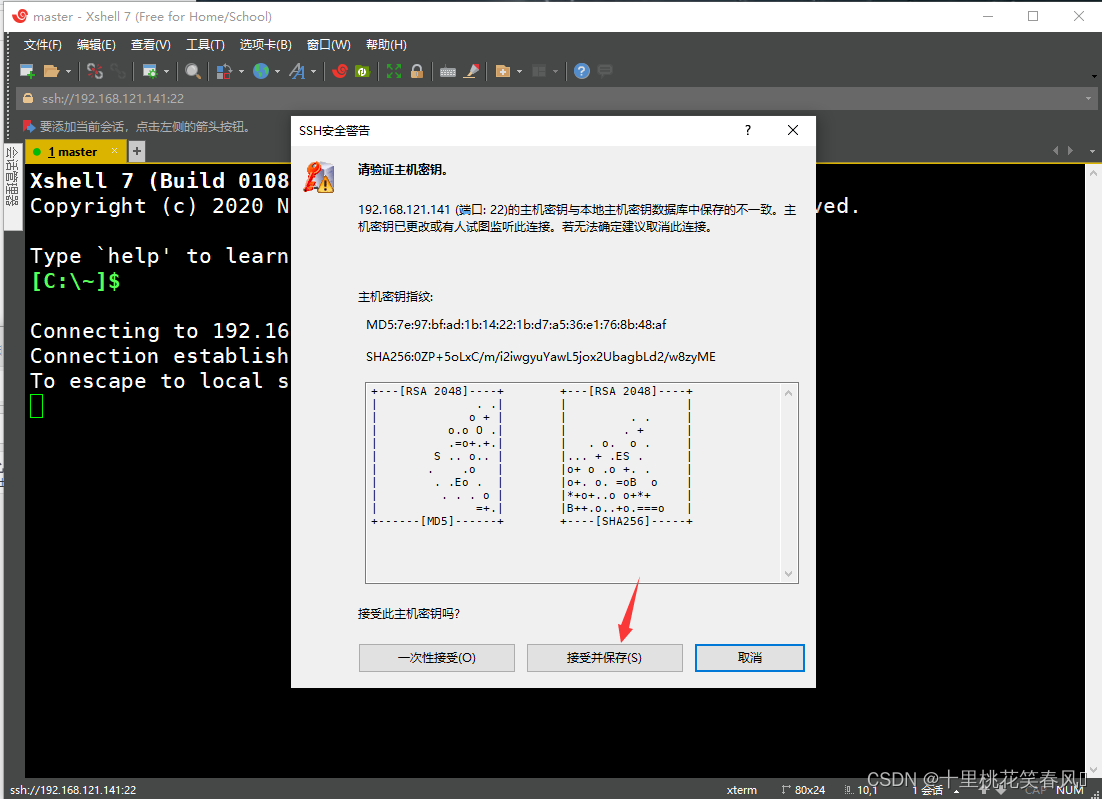
此处输入登录的用户名:root,下面记住用户名打上勾,然后点击确定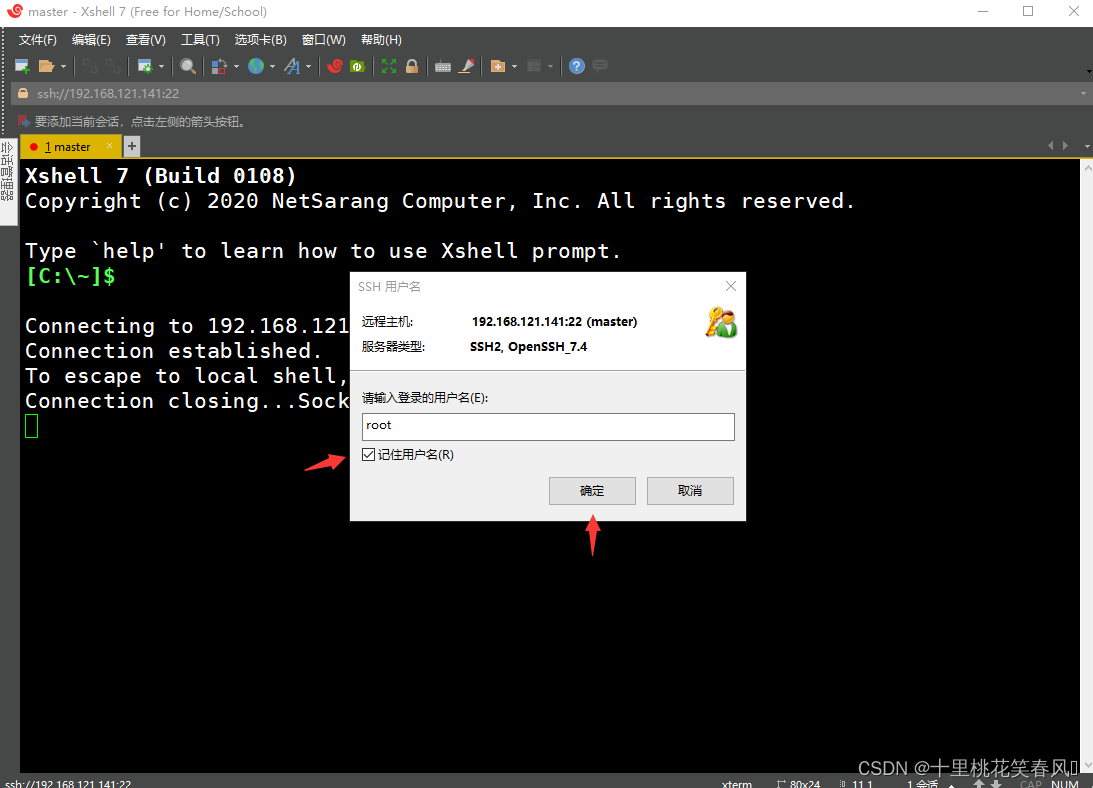
输入密码,下面记住密码打上勾,然后点击确定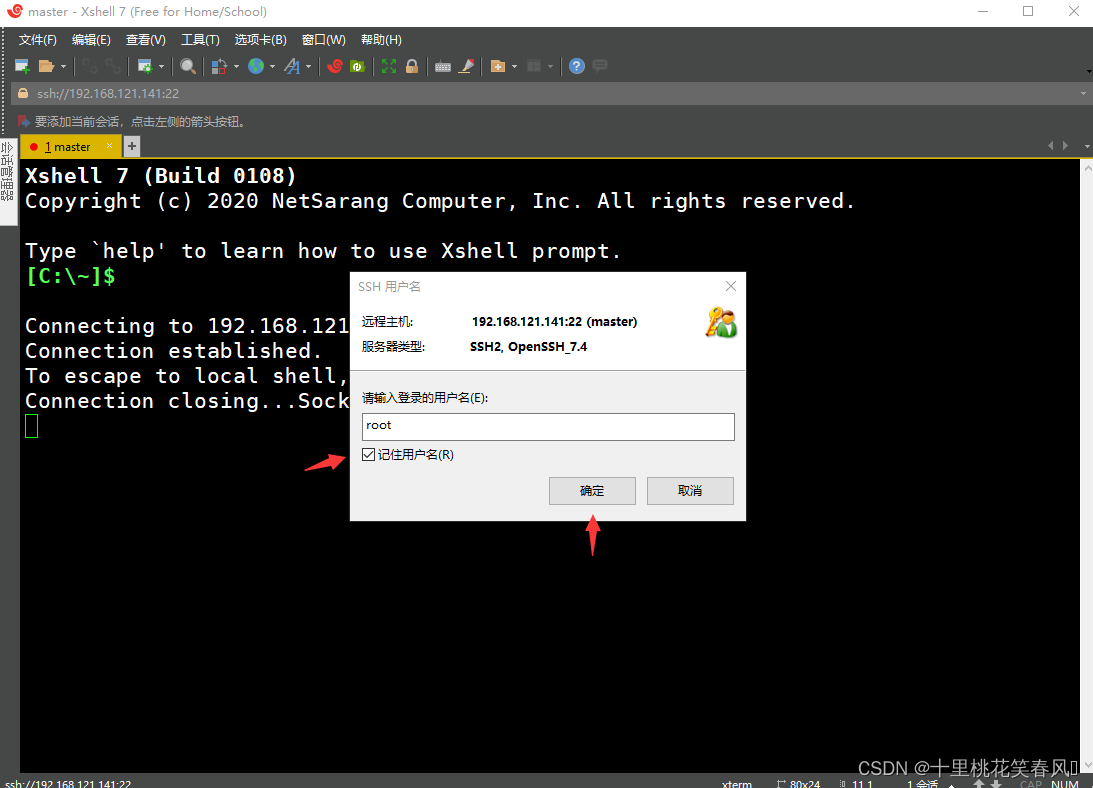
出现这个界面则表示远程连接成功
按照上述远程连接操作分别再新建两个对话,用于远程连接从节点slave1,slave2(注意:为了方便操作,名称为slave1,它对应的IP为:192.168.121.142,;名称为slave2,它对应的IP为:192.168.121.143)
1.2 配置网卡
这里我们点开VMware平台,先分别查看三台机子的MAC地址,并记录下来,后面设置要用到;右键虚拟机,选择设置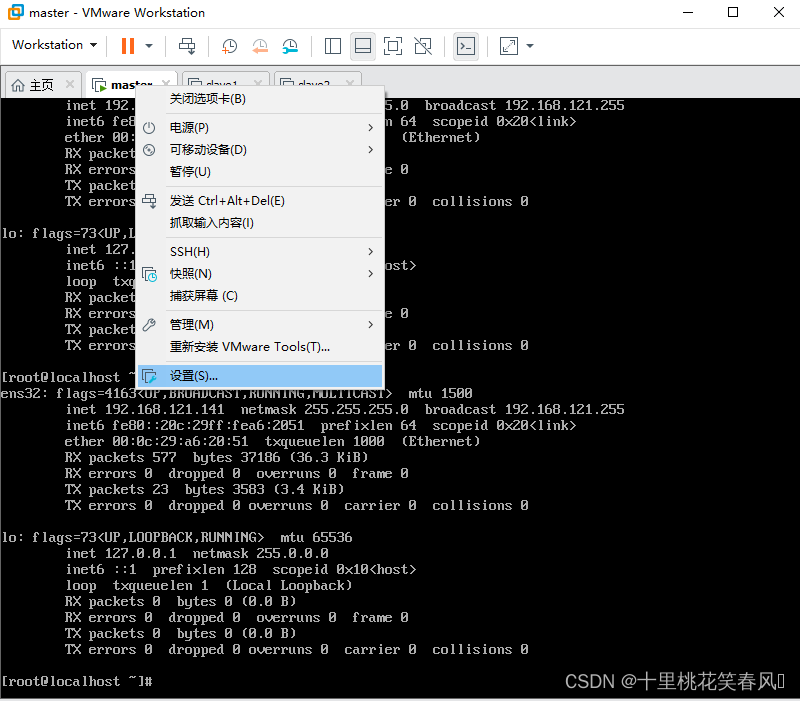
点击网络适配器,再点击右边的高级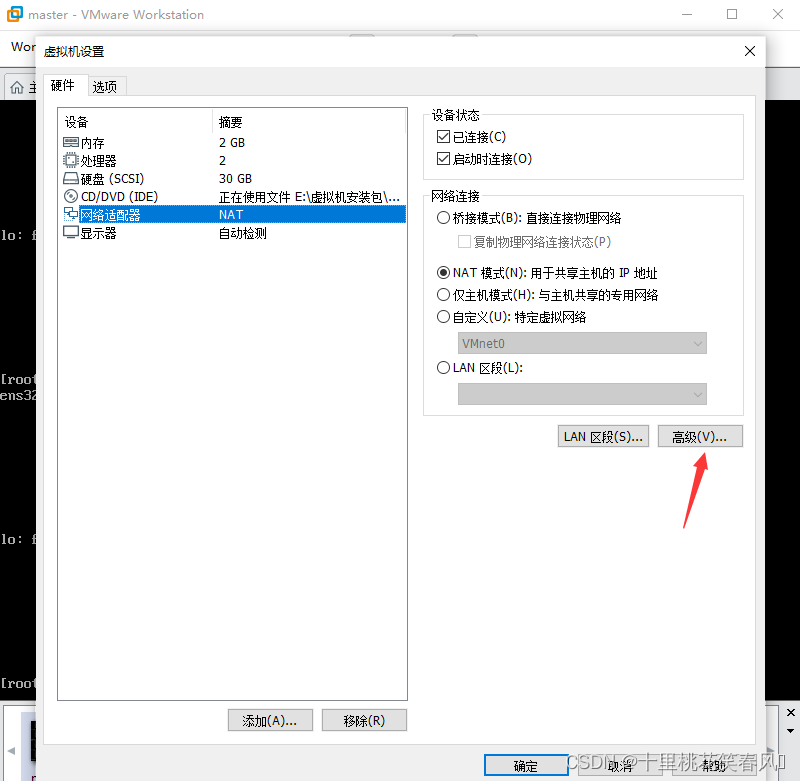
记住这个MAC地址(三台机子都要查看,每台的MAC地址都不一样)
在xshell中输入代码
vi /etc/sysconfig/network-scripts/ifcfg-ens32
(如果自己的是ens33,代码的最后就写ens33),进入文本模式,按下按键i,进入编辑模式,这里需要改一些参数,(1)dhcp改为static,(2)增加HWADDR=你的虚拟机的MAC地址,就是上面事先查看的MAC地址,注意每台机子必须对应,我们在主节点master上面操作的,那么就填的是master节点的MAC,在slave1上面操作的就填slave1的MAC,在slave2上面操作的,就填slave2的MAC。(3)no改为yes,(4)增加IPADDR=192.168.121.141(注意,如果之前的每一步操作都和我一样,那么这里按照我的步骤来就行,如果IP设置不一样,那么就按照自己设置的IP来。(4)NETMASK=255.255.255.0,GATEWAY=192.168.121.2,DNS1=8.8.8.8(这三行都是一样的)
修改完后先按Esc退出编辑模式,再输入:wq保存退出
输入代码
service network restart
,重启网络
输入代码
ping www.baidu.com
,出现这种情况,说明网络已配通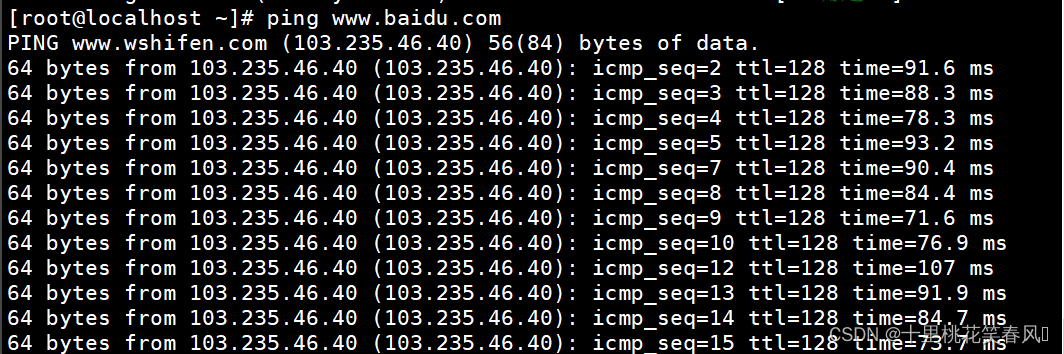
上述配置网卡操作都是在主节点master上操作的,从节点slave1,slave2,也需要配置,重复上述操作即可(注意,需要更改的地方就是MAC地址和IP,因为三台机子的MAC和IP都不一样,其余地方都一样)
1.3 修改主机名
在主节点master上输入代码
hostnamectl set-hostname master
修改主机名为master
在从节点slave1上输入代码
hostnamectl set-hostname slave1
,修改主机名为slave1
在从节点slave2上输入代码
hostnamectl set-hostname slave2
,修改主机名为slave2
然后可以在每台机子上输入代码
hostname
,查看主机名


1.4 设置主机名与IP地址映射
输入代码
vi /etc/hosts
,进入文本模式,按下按键i进入编辑模式,修改文档,在里面添加代码:
192.168.121.141 master
192.168.121.142 slave1
192.168.121.143 slave2
然后按Esc退出编辑模式,在输入:wq保存退出(三台机子都要这样操作)
做到这里我们可以断开一次远程连接,再从新连接,这样我们在对话框中才能看见改过之后的主机名

1.5 ssh免密
分别在三台节点输入命令
ssh-keygen -t rsa
,连按4次回车。出现如下图案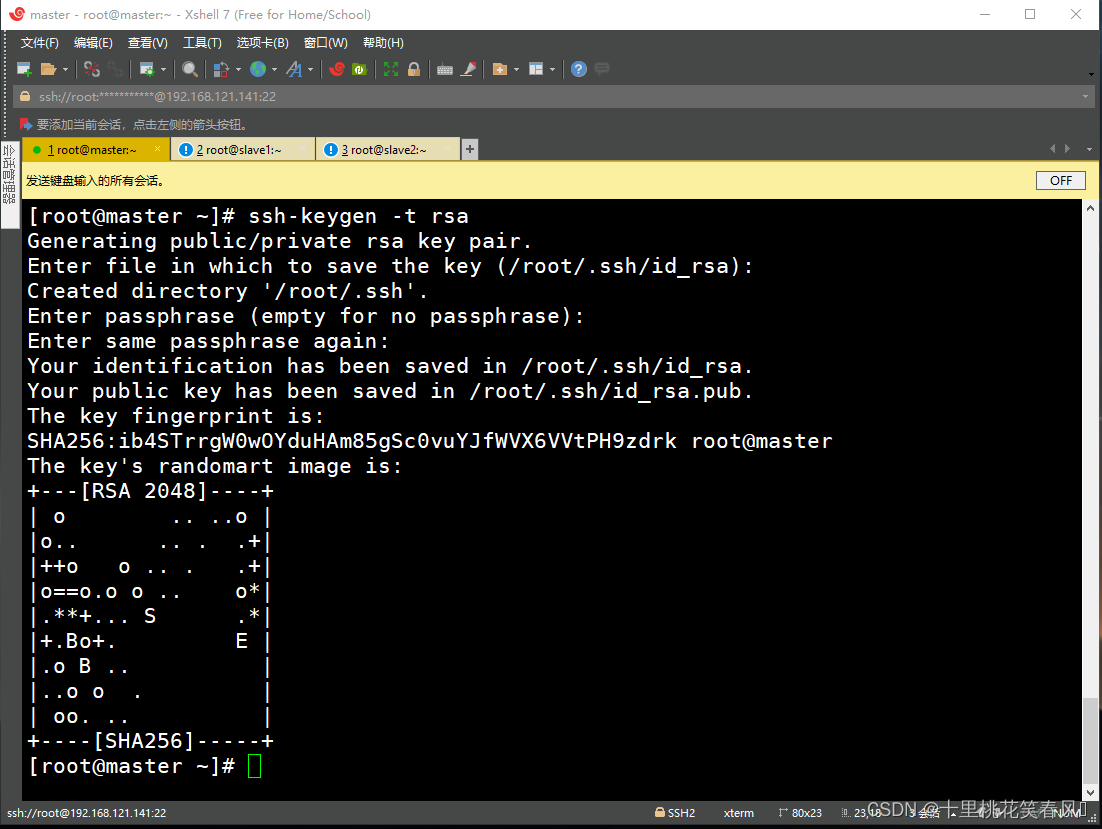
分别在三台节点输入代码
ssh-copy-id master
,敲一次回车,输入yes,再敲一次回车,输入密码(密码不会显示),再敲一次回车即可
分别在三台节点输入代码
ssh-copy-id slave1
,敲一次回车,输入yes,再敲一次回车,输入密码(密码不会显示),再敲一次回车即可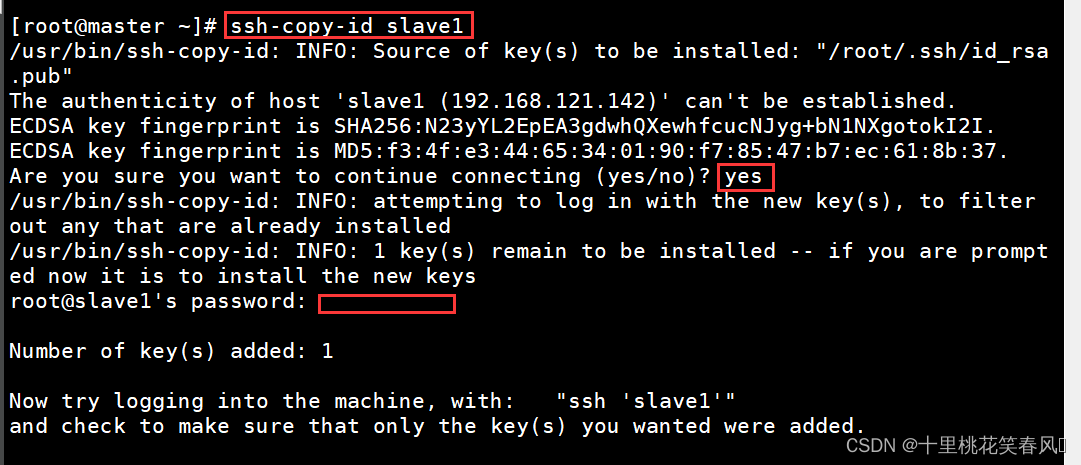
分别在三台节点输入代码
ssh-copy-id slave2
,敲一次回车,输入yes,再敲一次回车,输入密码(密码不会显示),再敲一次回车即可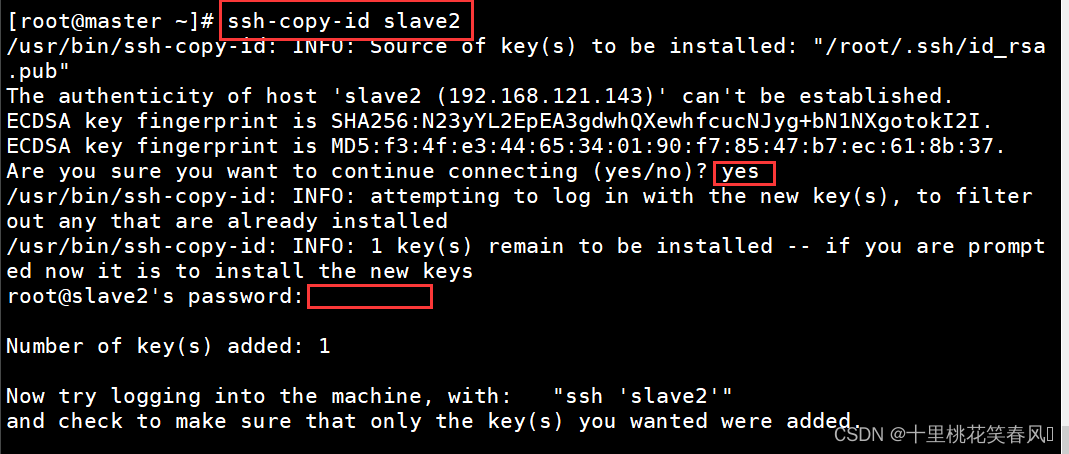
到这里节点之间的免密通信已经完成,可以通过输入代码
ssh 主机名
,来检验是否免密成功,如下进行节点之间的切换不需要输入密码则表示免密成功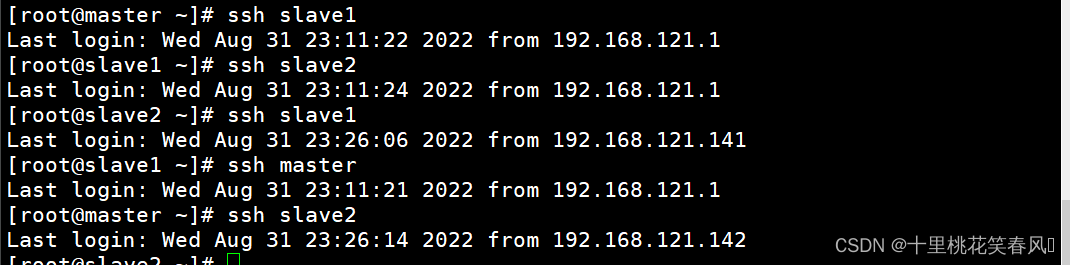
2. hadoop集群搭建
2.1 准备工作
到相应网站下载JDK和Hadoop安装包
JDK安装包下载链接JDK下载链接;Hadoop安装包下载链接hadoop下载链接
使用xftp上传JDK,Hadoop安装包至linux系统
打开xftp软件,点击新建
名称处填写master;主机处填写master对应的IP,也就是之前设置的192.168.121.141;用户名处填写root;再填写密码,然后点击连接(同样以此方法再新建两个对话,连接slave1,slave2,,连接时注意IP就行,slave1对应IP为192.168.121.142,;slave2对应IP为192.168.121.143)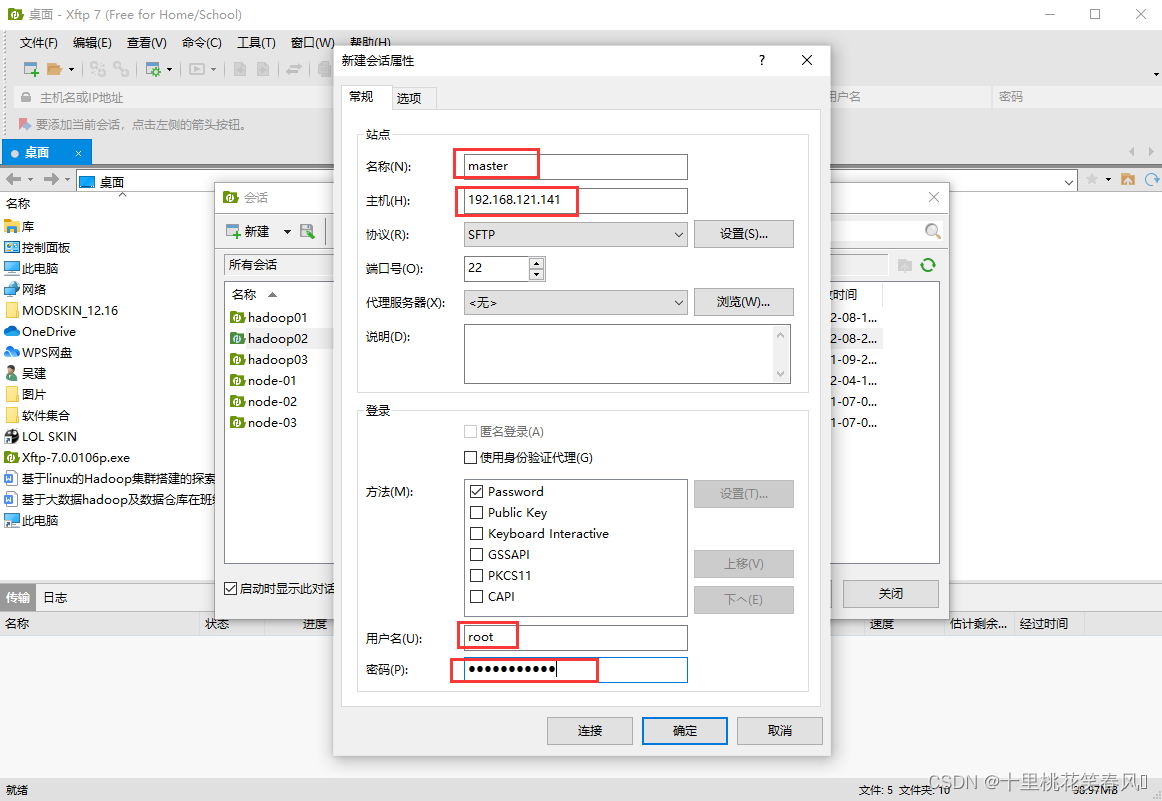
这个界面,左边表示windows文件路径,右边表示linux文件路径,这里可以实现windows系统与linux系统之间的文件传输(比如我们在windows系统下载的文件,在左边找到该文件路径,在右边选择想要传输的文件路径,然后在左边双击需要传输的文件就能传输到右边)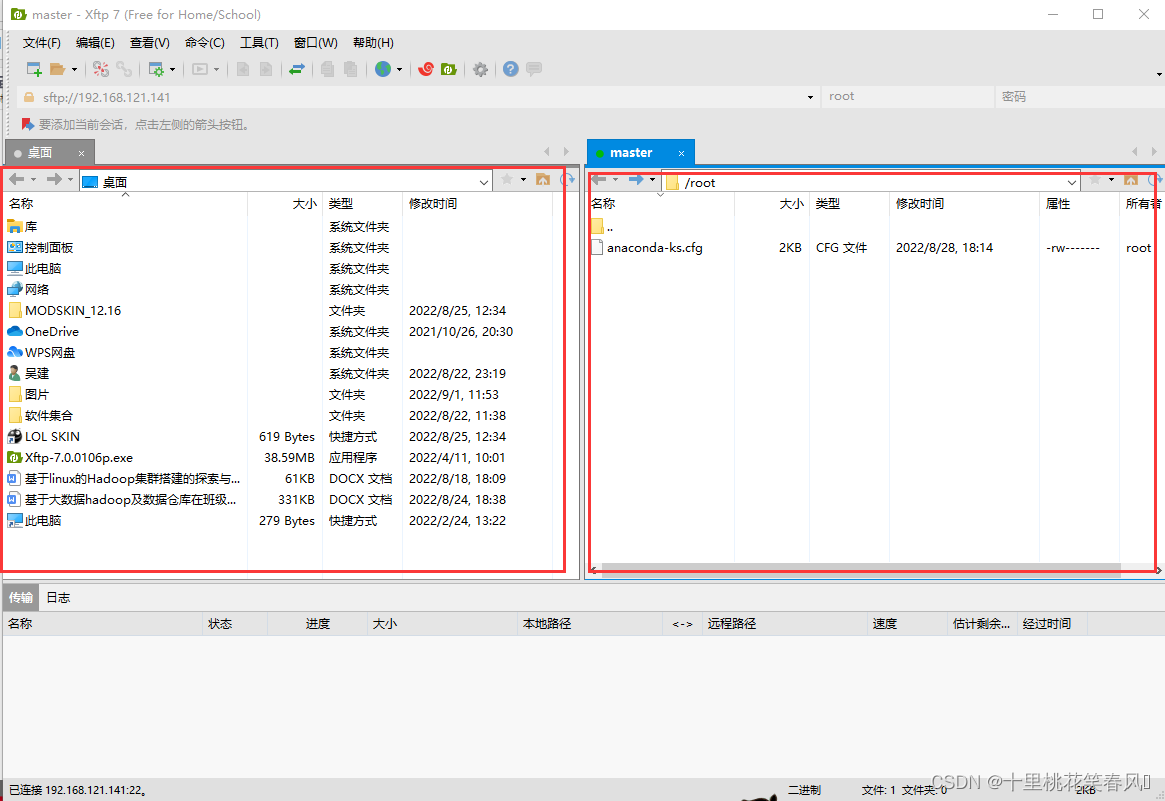
2.2 JDK和Hadoop的安装
在根目录下,右边空白处点击鼠标右键新建文件夹,命名为export,再在export文件下创建子文件software用于存放各类安装包,再创建一个子文件servers用于存放解压后的文件(此创建方式也可以在客户端内通过代码创建,只不过这种创建文件方式个人觉得更为方便)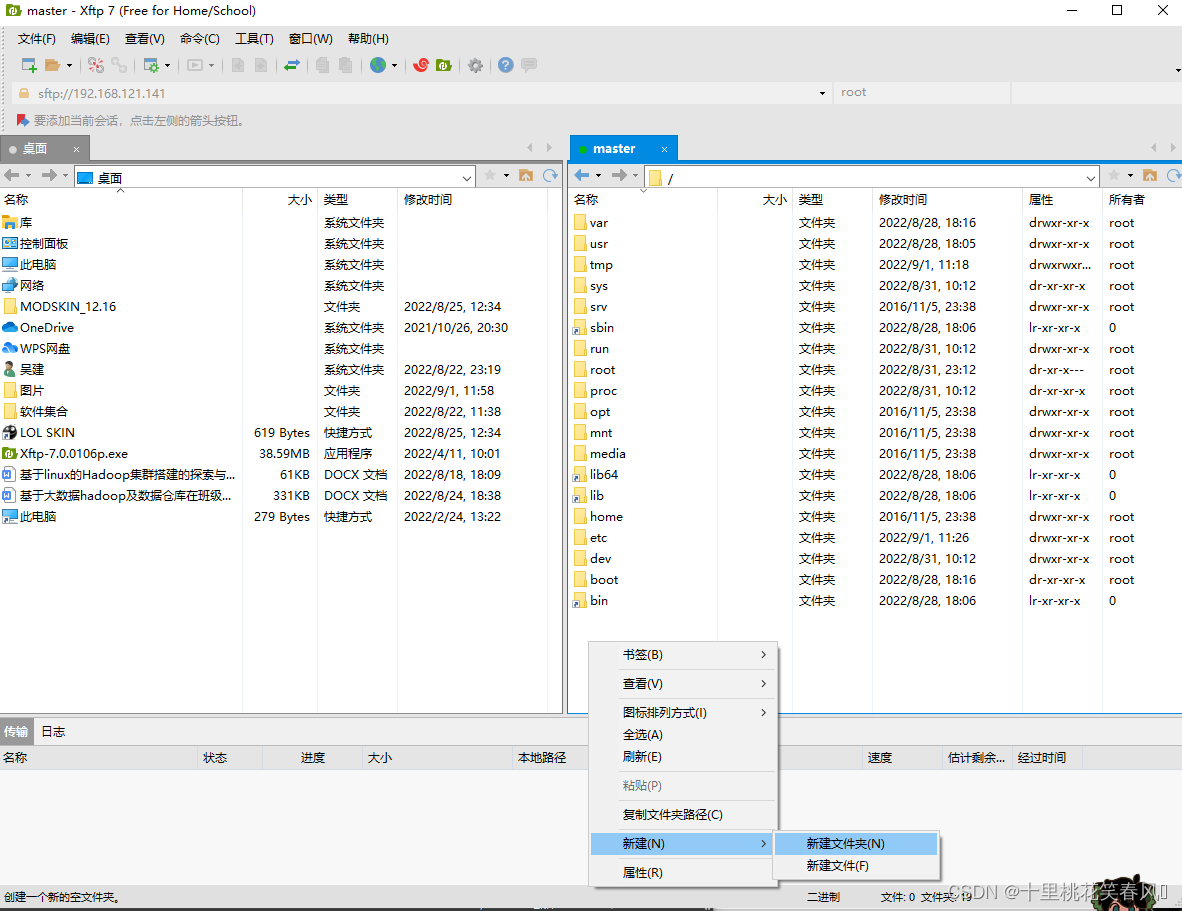
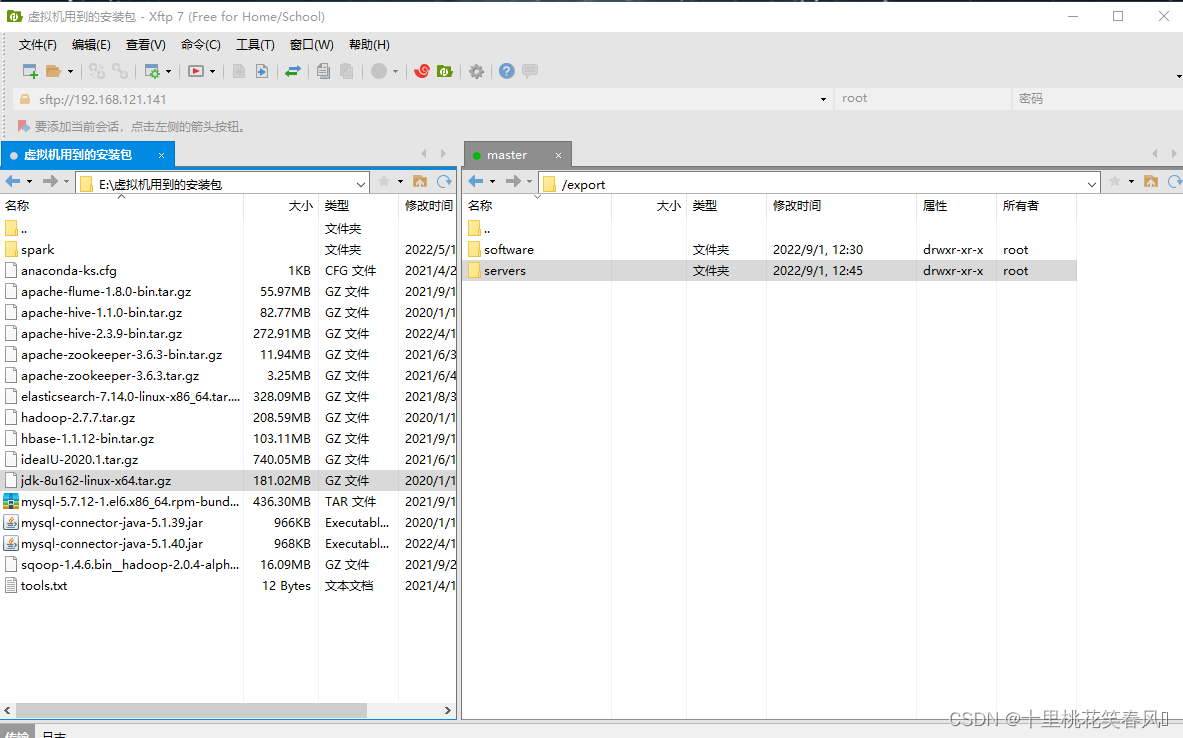
将windows系统下的JDK和Hadoop安装包上传至linux系统下的/export/software路径。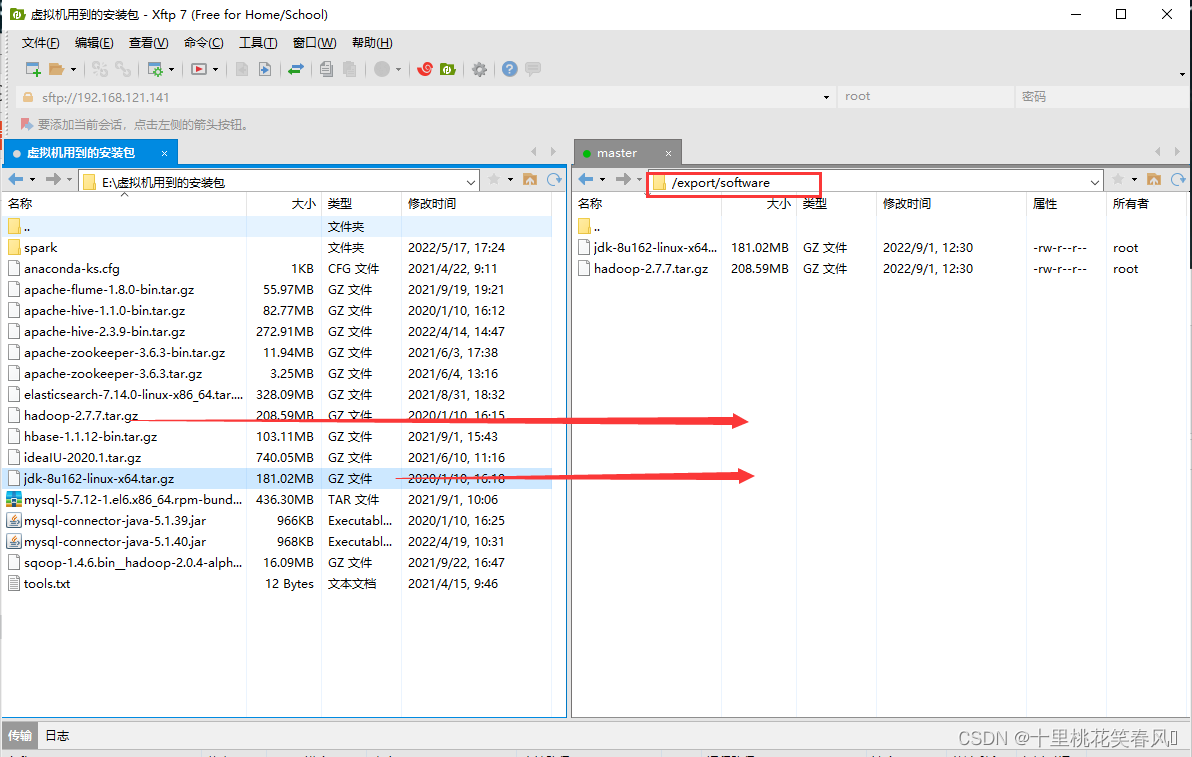
2.2.1 解压
解压JDK安装包至指定路径/export/servers(解压安装包时,需要先进入安装包所在路径,否则在执行解压命令时,要写安装包的绝对路径,因为linuv系统搜索文件路径是一级一级搜索的)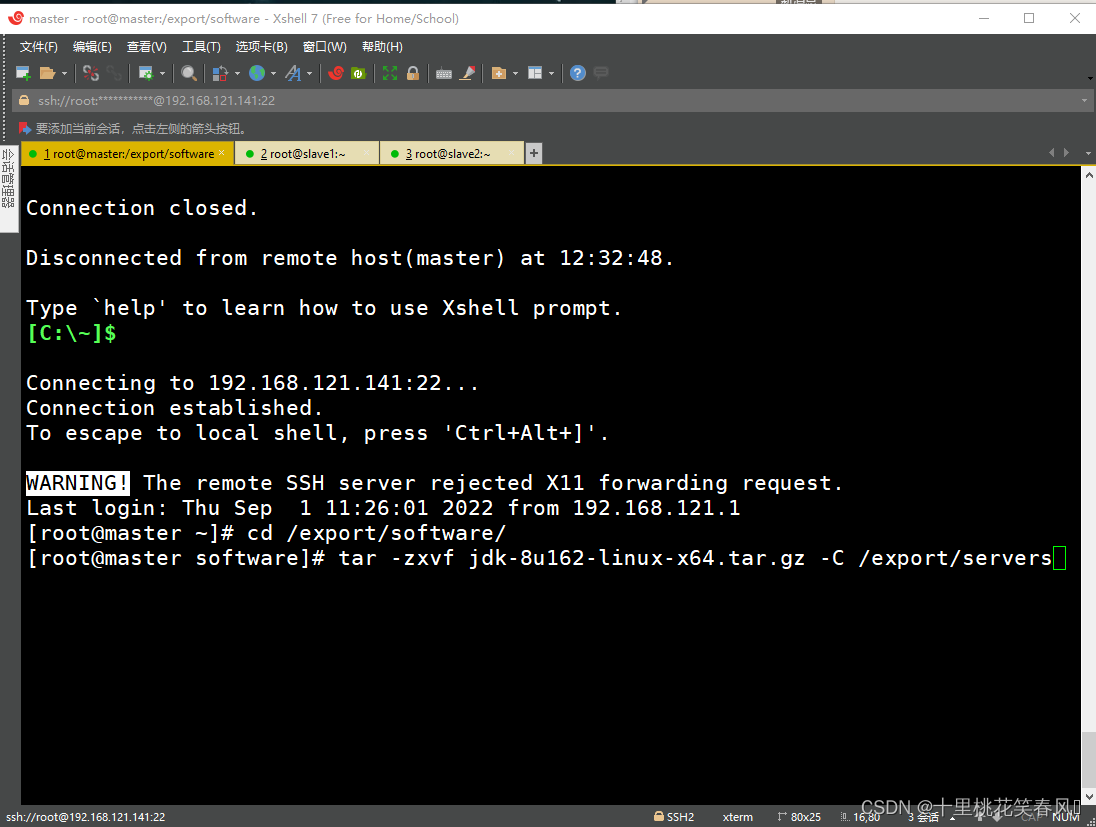
解压Hadoop安装包至指定路径/export/servers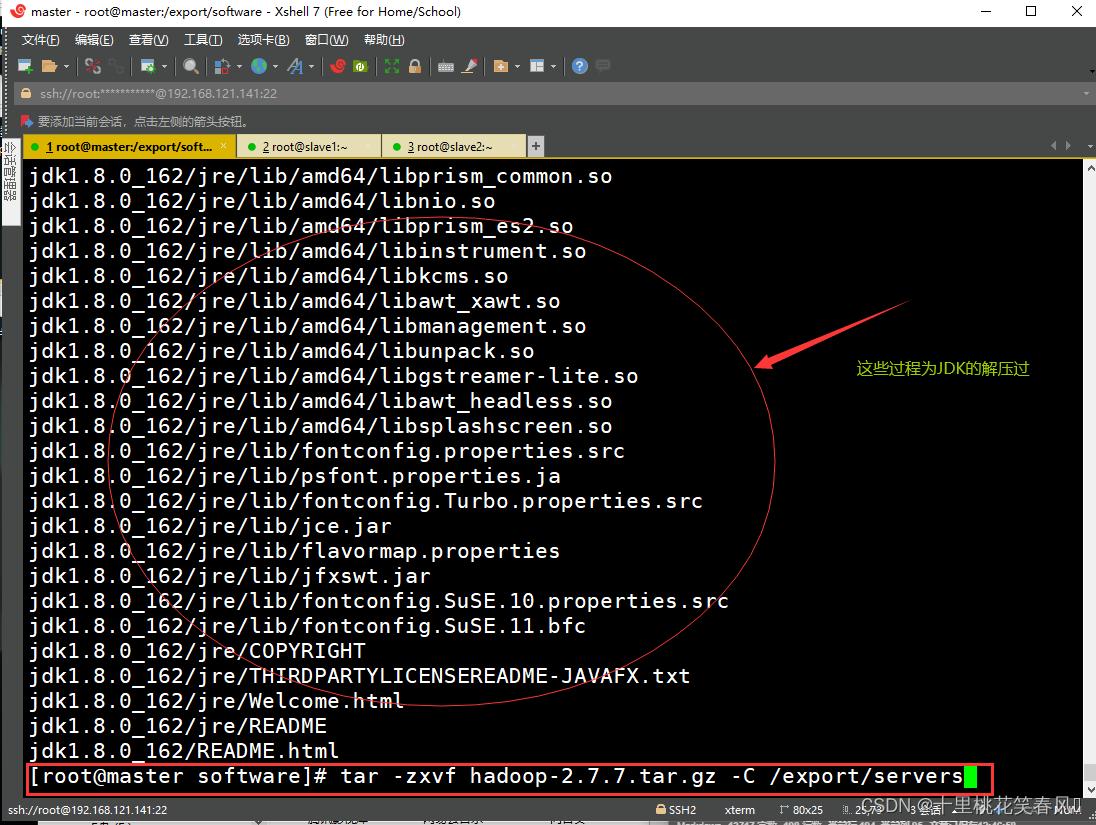
2.2.2 改名
解压后的文件名带有版本号,后续使用起来不太方便,所以我们执行mv命令对JDK和Hdoop进行改名(注意改名命令的执行,也需要进入文件所在路径)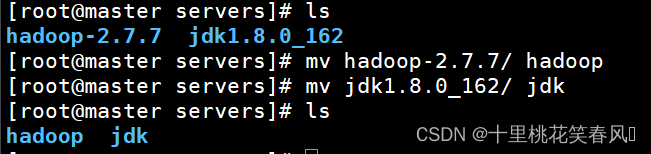
2.2.3 配置系统环境变量
执行命令
vi /etc/profile
编辑文档,在最后添加JDK和Hadoop的环境变量,内容如下:
# jdk环境变量
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# hadoop环境变量
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
编辑完后,保存退出,再执行命令
source /etc/profile
使环境变量生效(此命令一定要执行,否则所配置环境变量无效)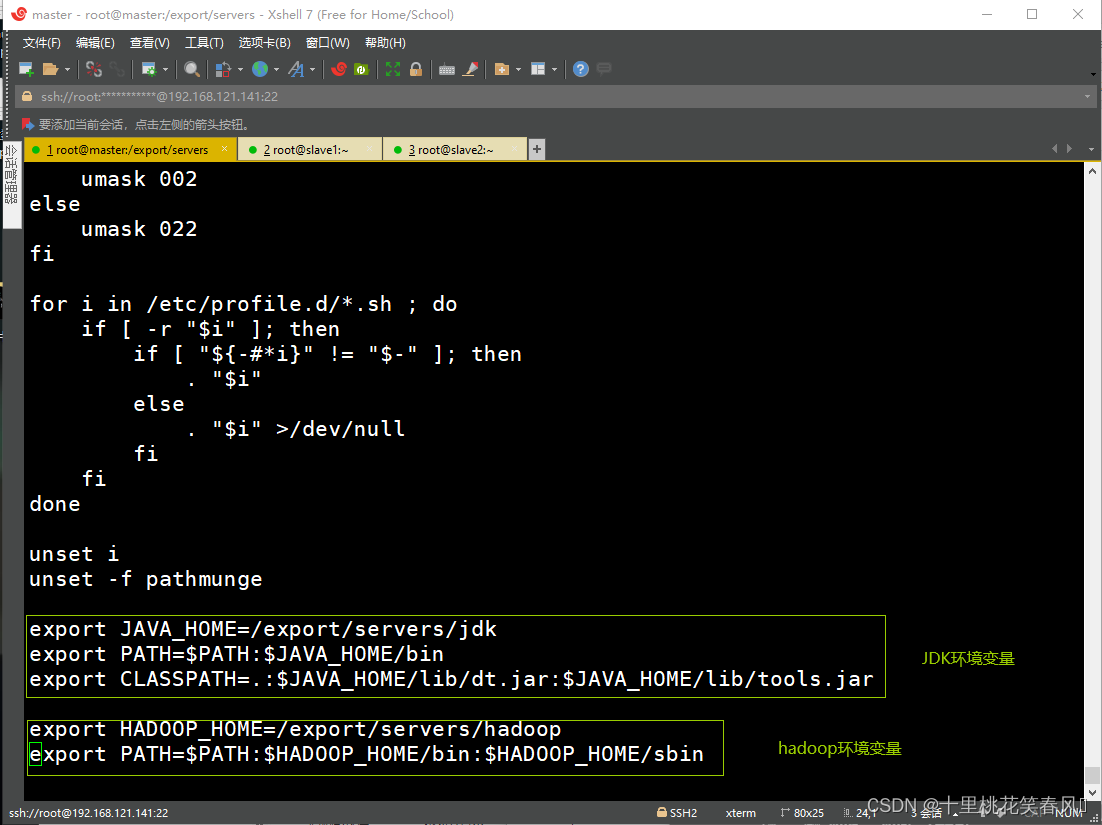

2.2.4 JDK和Hadoop环境验证
执行命令
java -version
验证java环境,执行命令
hadoop version
验证hadoop环境,出现如下情况说明JDK和Hadoop安装和配置成功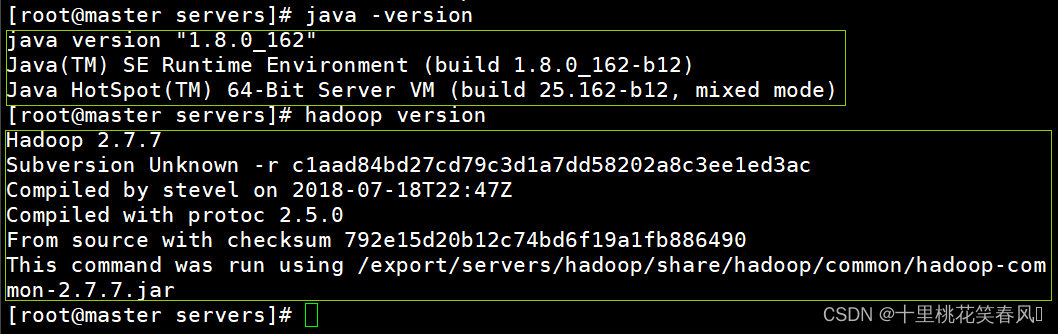
2.3 Hadoop集群配置
2.3.1 配置hadoop集群主节点
(1)修改hadoop-env.sh文件
进入hadoop安装目录下的etc/hadoop/目录下(下面的配置文件都是在这个目录下),执行命令
vi hadoop-env.sh
编辑文档,找到JAVA_HOME参数位置进行修改,具体如下:
export JAVA_HOME=/export/servers/jdk
修改完,保存退出

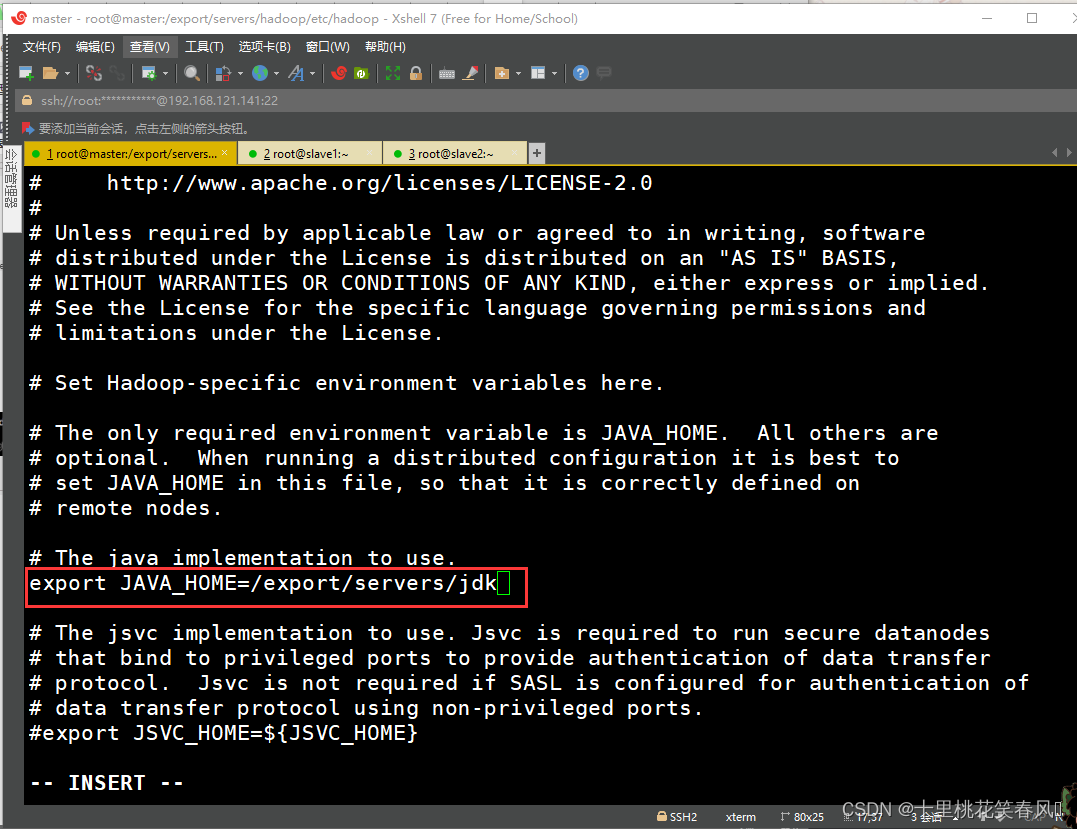
(2)修改core-site.xml文件
编辑文件core-site.xml,向文档末尾添加如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/tmp</value>
</property>
</configuration>
编辑完,保存退出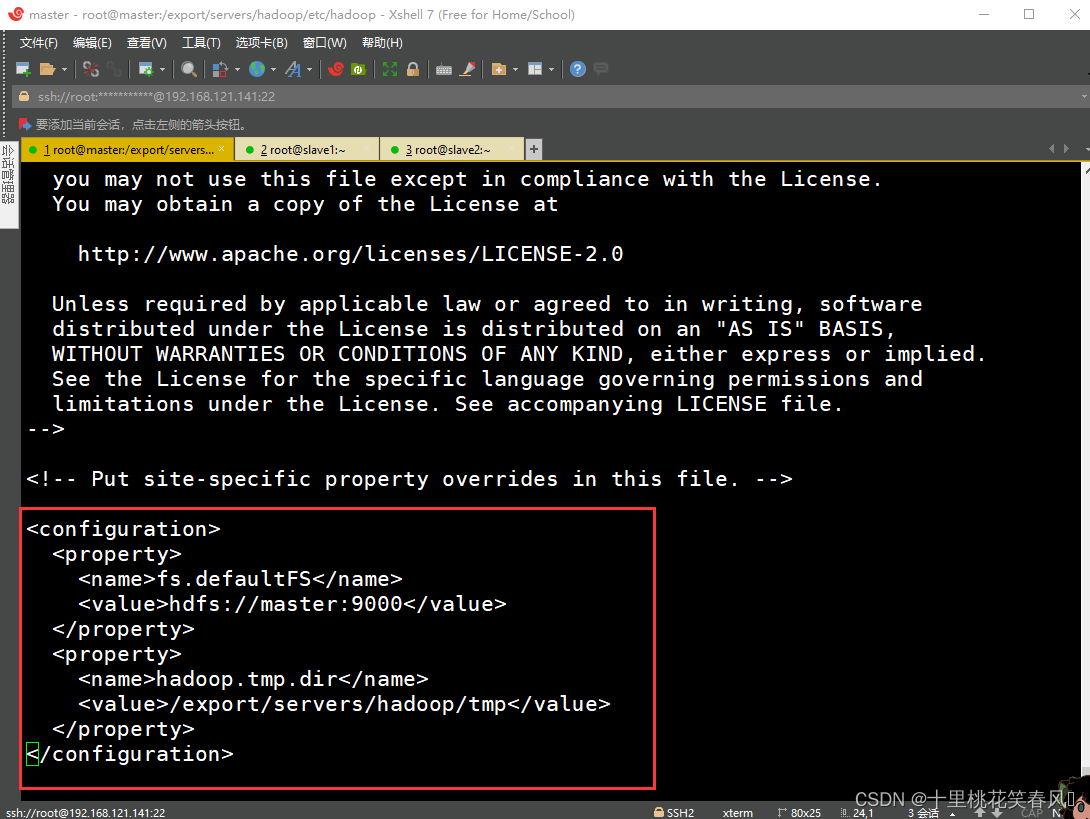
(3)修改hdfs-site.xml文件
编辑文件hdfs-site.xml,向文档末尾添加如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
编辑完,保存退出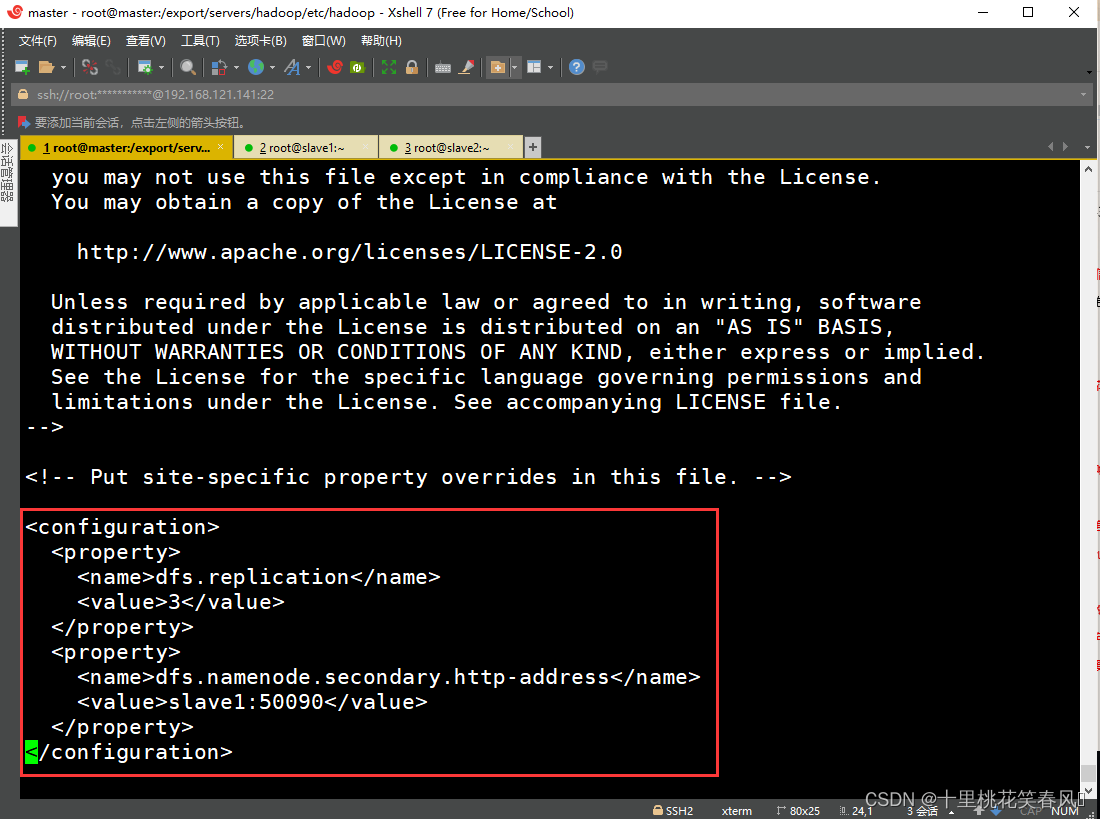
(4)修改mapred-site.xml文件
在该目录下原本是没有此文件的,我们需要先执行命令
cp mapred-site.xml.template mapred-site.xml
复制一个mapred-site.xml文件,再进入该文件进行编辑,向文档末尾添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改完后,保存退出
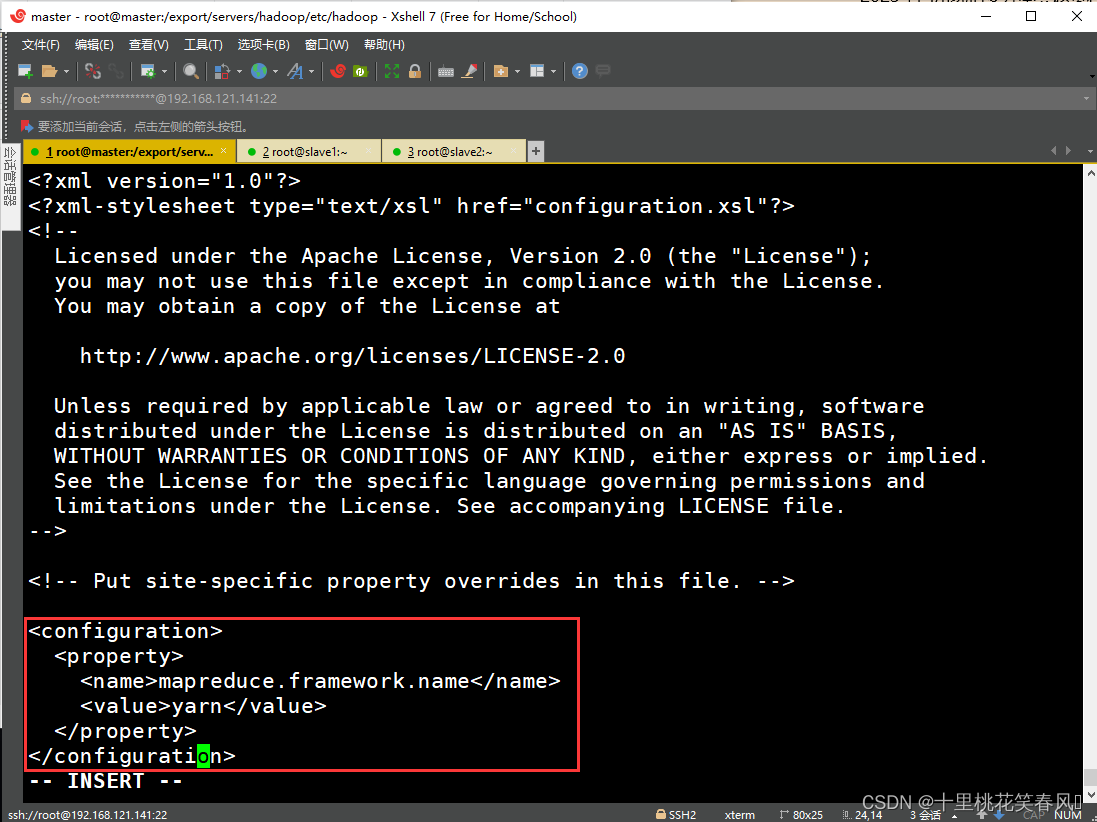
(5)修改yarn-site.xml文件
编辑该文档,向文档末尾添加如下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
编辑完,保存退出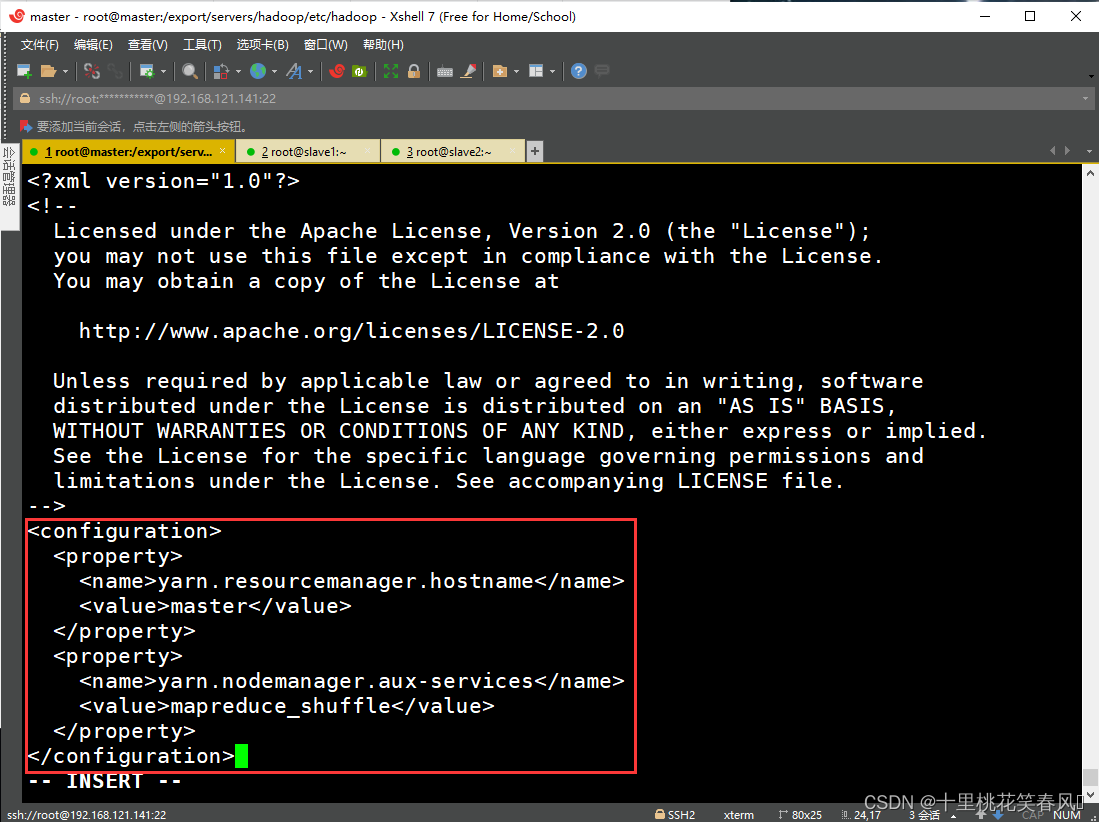
(6)修改slaves文件
该文件里面默认是localhost,把它删除,再添加如下内容:
master
slave1
slave2
编辑完,保存退出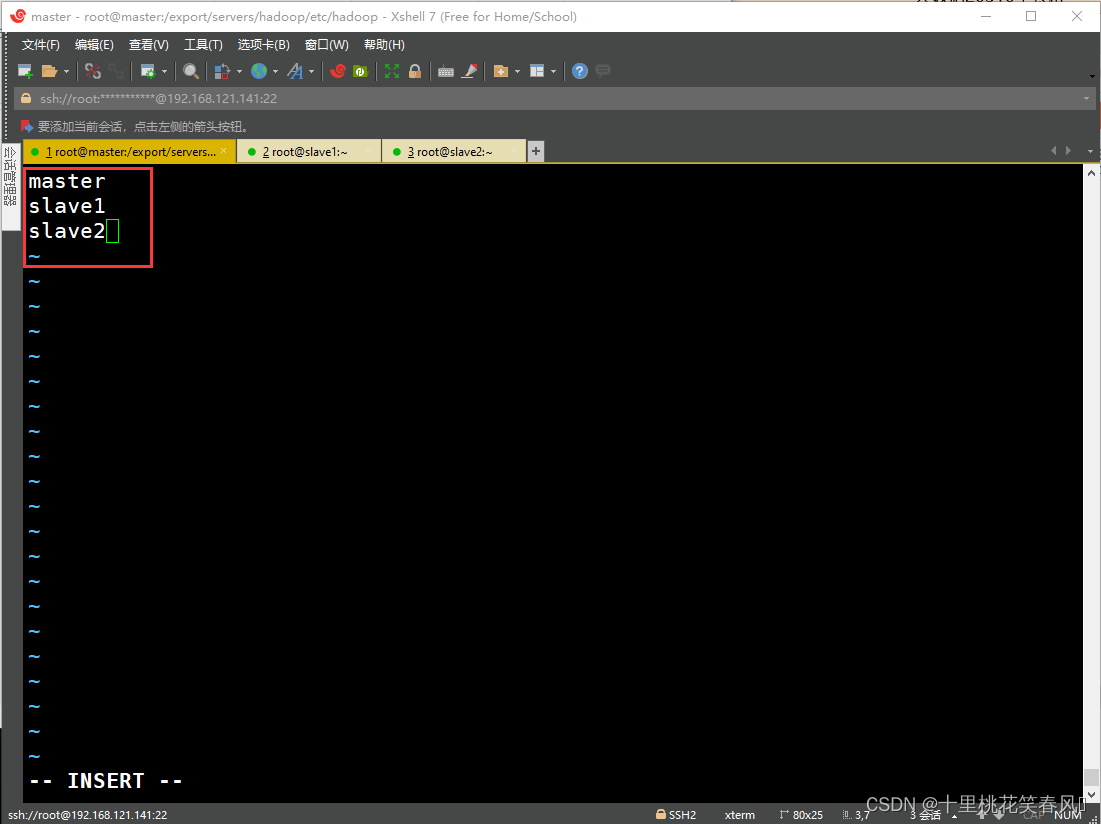
2.3.2 将集群主节点的配置文件分发到从节点slave1,slave2
(1)将系统环境配置文件分发到从节点slave1,slave2,执行如下命令:
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile

(2)将JDK安装目录和Hadoop安装目录分发到从节点slave1,slave2,执行如下命令:
scp -r /export/ slave1:/
scp -r /export/ slave2:/

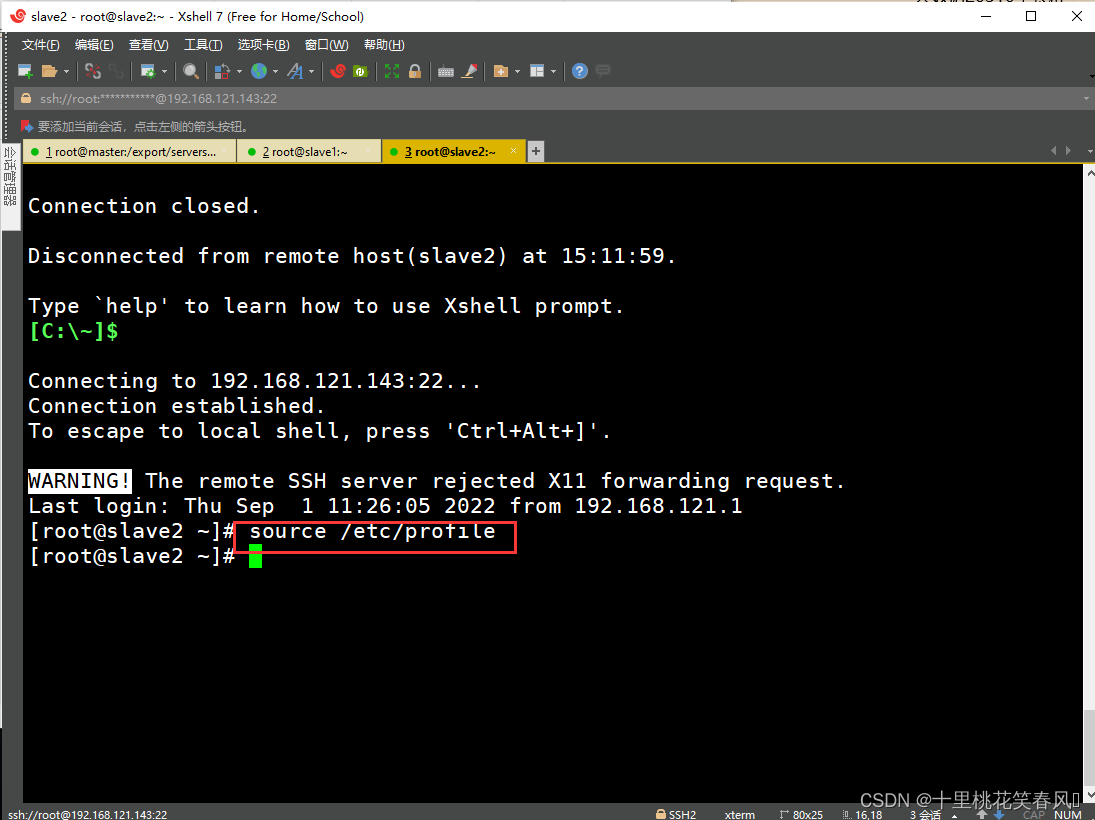
最后在从节点slave1,slave2上分别执行命令
source /etc/profile
,刷新配置文件,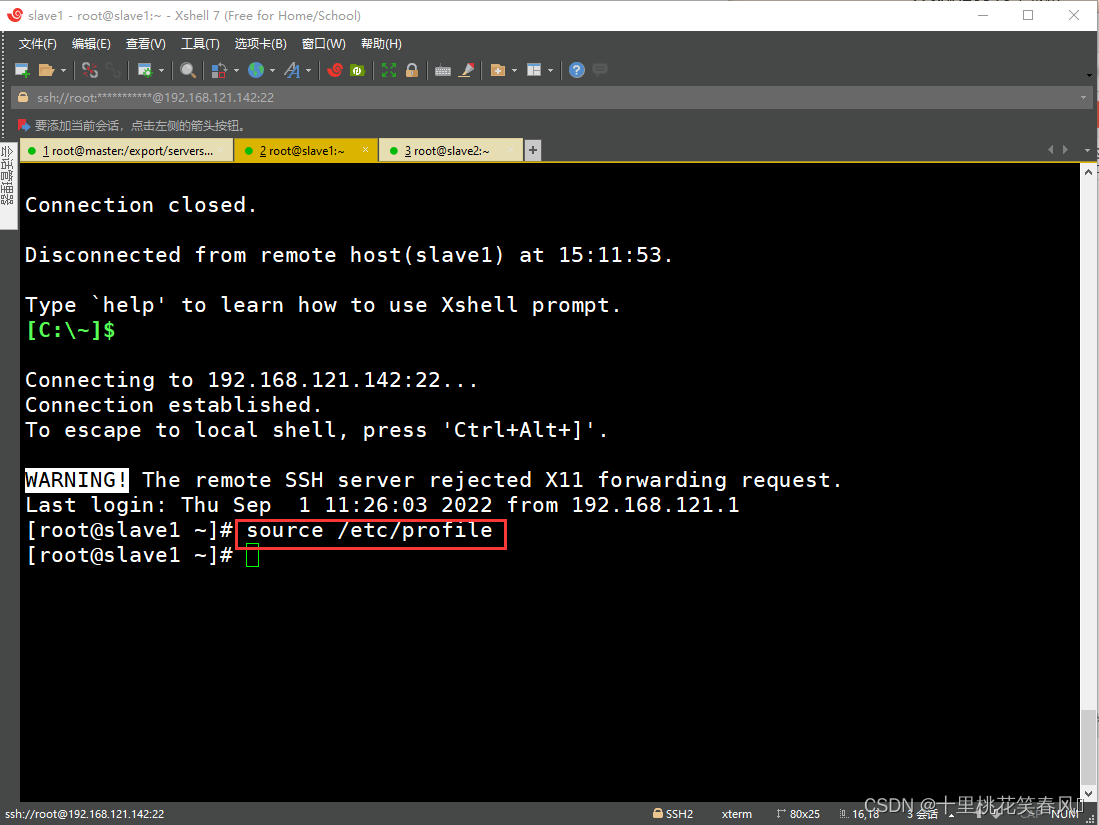
2.4 Hadoop集群测试
2.4.1 格式化文件系统
初次启动HDFS集群时,必须对主节点master进行格式化处理,执行如下命令:
hdfs namenode -format
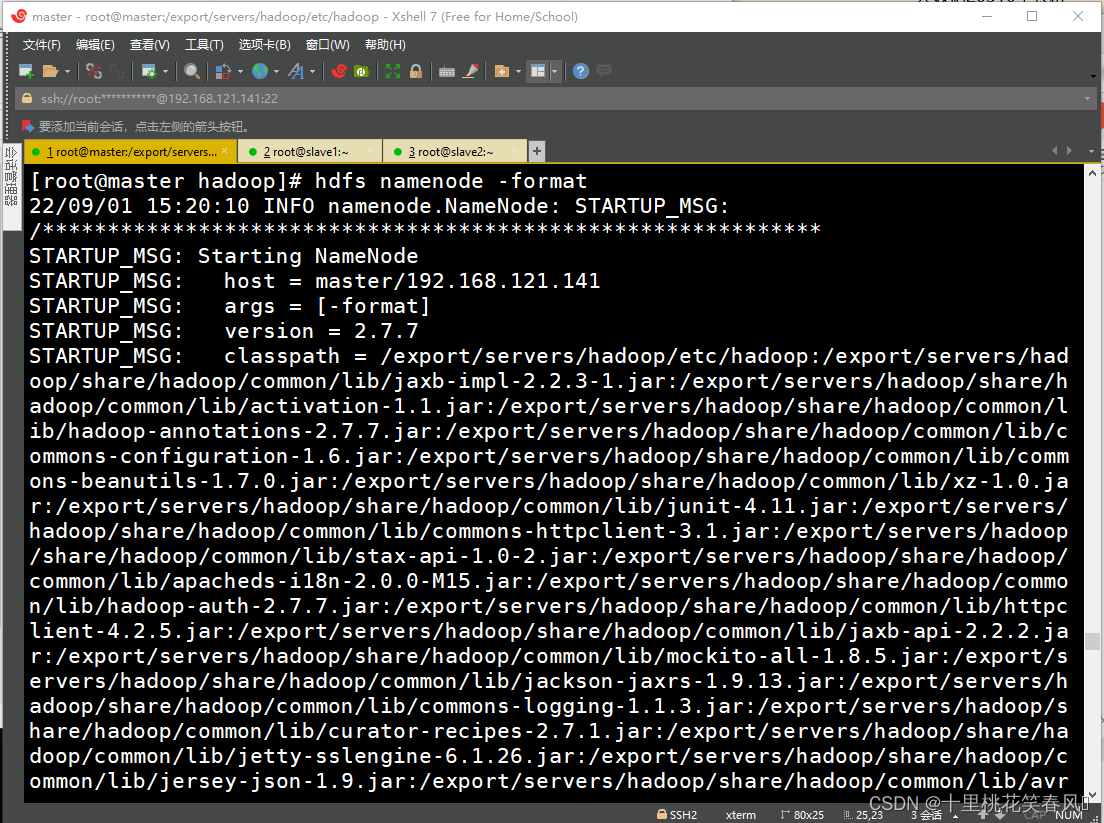
出现successfully说明格式化成功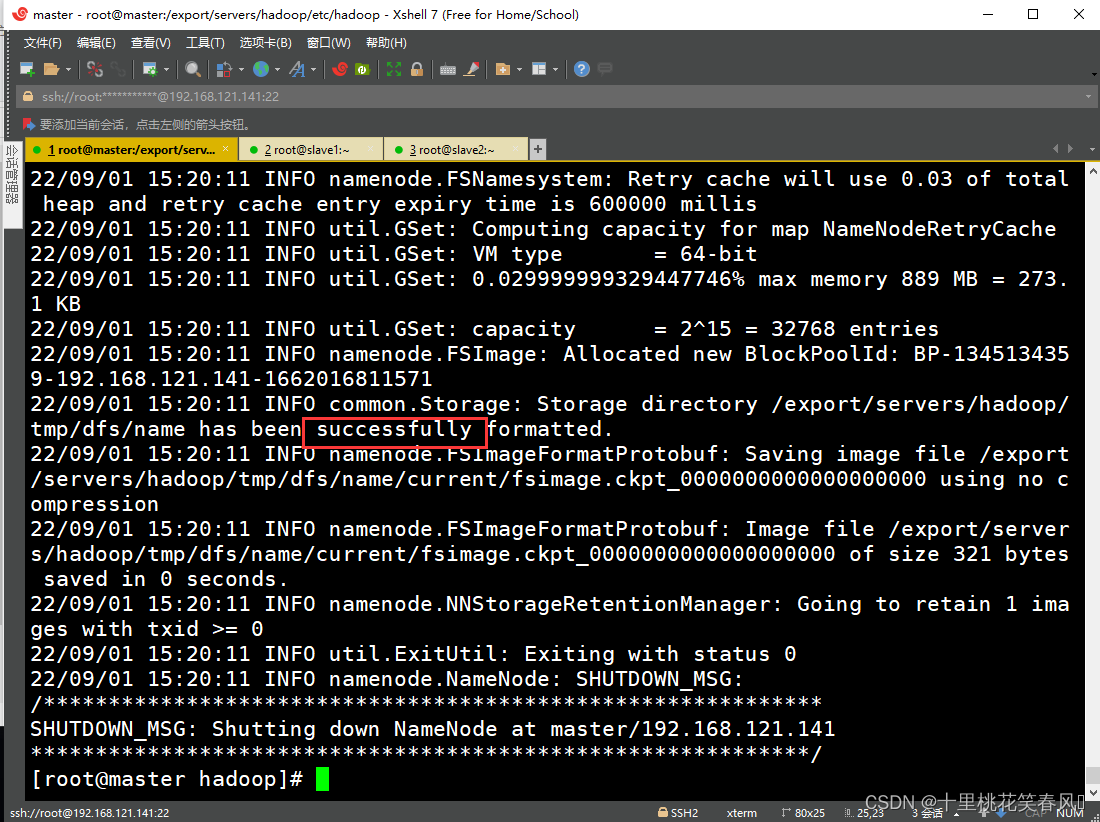
2.4.2 启动集群
在主节点master上执行命令
start-all.sh
,一键启动集群(停止进程则为
stop-all.sh
)
此时可通过在三台节点上分别输入命令
jps
,来查看各节点的进程启动情况,主节点master上启动了DataNode、NameNode、ResourceManager和NodeManager四个进程;从节点slave1上启动了DataNode、SecondaryNameNode和NodeManager三个进程;从节点slave2上启动了DataNode和NodeManager两个进程;下图依次为主节点master效果图,从节点slave1,slave2效果图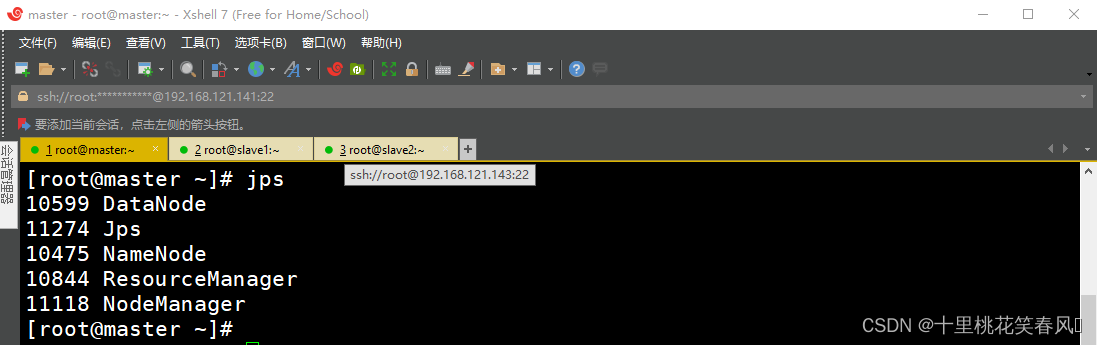

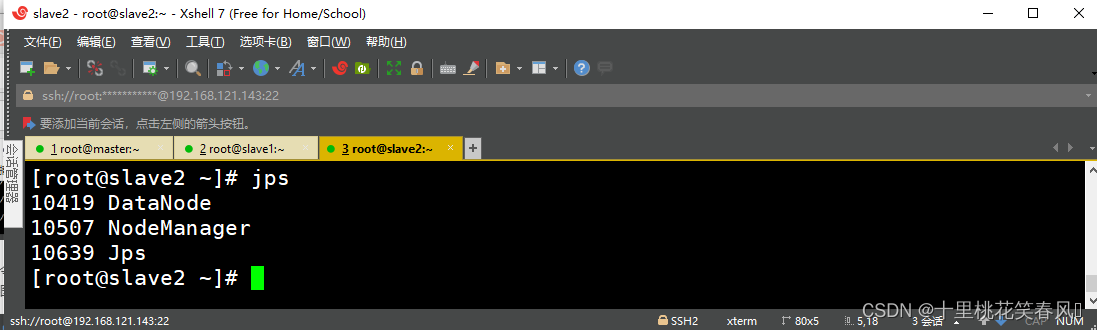
2.4.3 通过UI界面查看Hadoop运行状态
hadoop集群正常启动后,他默认开放了50070和8088两个端口,分别用于监控HDFS集群和YARN集群的运行状态,通过UI可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应端口号即可访问
首先我们需要进入windows系统下的路径:C:\Windows\System32\drivers\etc,修改文件hosts,设置windows浏览器与虚拟机的映射关系,文档末尾添加如下内容:
192.168.121.141 master
192.168.121.142 slave1
192.168.121.143 slave2
修改完,保存即可。(这里保存的时候可能会出现限权问题,自己百度去修改该文件的限权)
要想通过windows系统下的浏览器访问虚拟机,那么我们还需要关闭虚拟机的防火墙,在三台节点上分别执行代码
systemctl stop firewalld
,关闭防火墙,再分别执行代码
systemctl disable firewalld
,禁止开机自动启动防火墙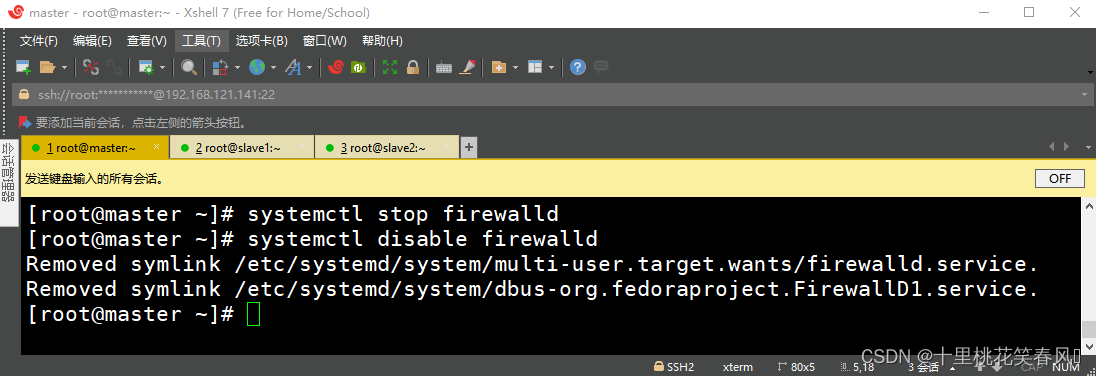
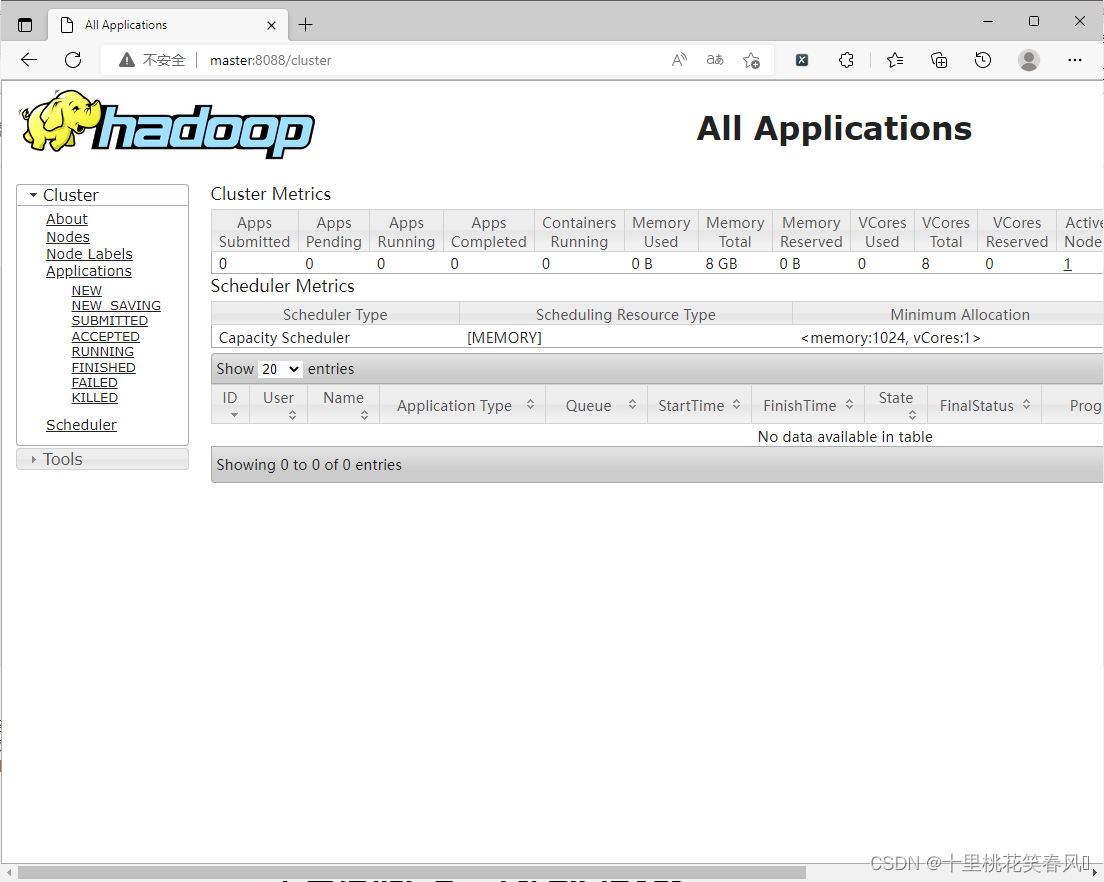
此时我们就可以通过浏览器访问http://master:50070和http://master:8088查看HDFS和YARN集群状态,如下图: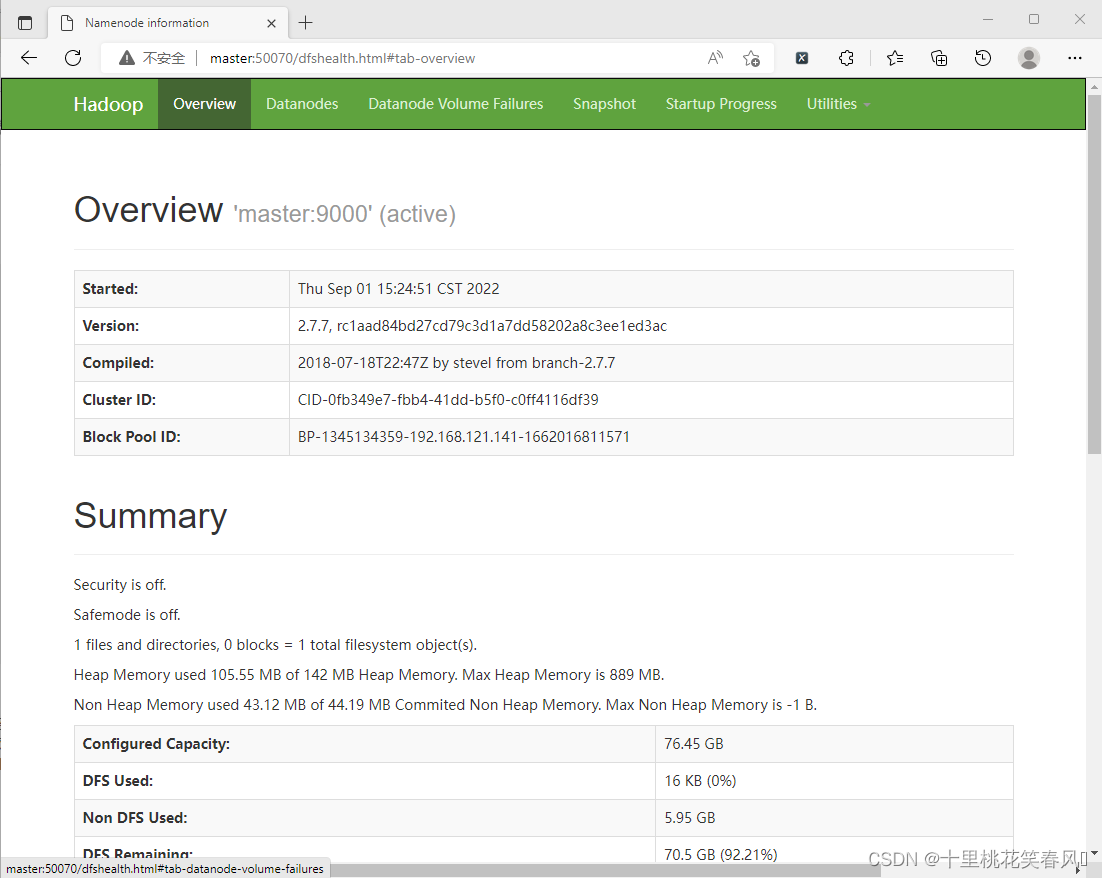
四: 附加教程
centos 7 常用命令集合
命令含义cd /home进入 ‘/home’ 目录cd …返回上一级目录cp file1 file2将file1复制为file2cp -a dir1 dir2复制一个目录ls显示文件信息pwd显示工作路径mkdir dir1创建 ‘dir1’ 目录mkdir dir1 dir2同时创建两个目录mv dir1 dir2移动/重命名一个目录rm -f file1删除 ‘file1’rm -rf dir1删除 ‘dir1’ 目录及其子目录内容cat file1从第一个字节开始正向查看文件的内容vi file打开并浏览文件find / -name file1从 ‘/’ 开始进入根文件系统查找文件和目录find / -user user1查找属于用户 ‘user1’ 的文件和目录tar -xvf archive.tar解压一个包tar -xvf archive.tar -C /tmp把压缩包释放到 /tmp目录下
五: 结语
通过自己的学习与理解,整理了hadoop集群的配置详细过程;该文章主要讲述了虚拟机的安装、配网以及hadoop集群搭建的详细过程,每一步都非常详细,其中有不清楚的地方,欢迎大家提出,我会尽自己最大努力去帮大家解决。学习此门课程,是个漫长的过程,是一个积累的过程,对于刚学的人来说,可能是有点难,但是只要自己用心,细心的去学,定会有收获。后面我会继续分享有关大数据的文章,对分布式协调服务zookeeper和hive数据仓库感兴趣的可以去看看这两篇文章,这两篇文章主要讲了zookeeper集群的部署以及hive数据仓库的本地/远程模式的搭建:zookeeper集群搭建,数据仓库hive本地/远程模式搭建
版权归原作者 吴糖气泡水~ 所有, 如有侵权,请联系我们删除。