

您可能会感到惊讶,但这是有效的。
最近,我阅读了arXiv平台上的Jonathan Frankle,David J. Schwab和Ari S. Morcos撰写的论文“Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs”。这个主意立刻引起了我的注意。到目前为止,我从未将批标准化(BN)层视为学习过程本身的一部分,仅是为了帮助深度网络实现优化和提高稳定性。经过几次实验,我发现我错了。在下文中,我将展示我复制的论文的结果以及从中学到的东西。
更详细地讲,我使用Tensorflow 2 Keras API成功复现了论文的主要实验,得出了相似的结论。也就是说,ResNets可以通过仅训练批标准化层的gamma(γ)和beta(β)参数在CIFAR-10数据集中获得不错的结果。从数字上讲,我使用ResNet-50、101和152架构获得了45%,52%和50%的Top-1精度,这远非完美,但也并非无效。
在下文中,我概述了批标准化概念以及其常见解释。然后,我分享我使用的代码以及从中获得的结果。最后,我对实验结果进行评论,并对其进行分析。
批标准化
简而言之,批标准化层估计其输入的平均值(μ)和方差(σ²),并产生标准化的输出,即平均值和单位方差为零的输出。在实验中,此技术可显着提高深度网络的收敛性和稳定性。此外,它使用两个参数(γ和β)来调整和缩放其输出。
x作为输入,z作为输出,z由以下公式给出:

图1:批标准化表达式
根据输入数据估算μ和σ²参数,而γ和β是可训练的。因此,反向传播算法可以利用它们来优化网络。
综上所述,已经发现此操作可以显着改善网络训练的速度以及其保留数据的性能。而且,它没有与其他网络层不兼容的地方。因此,大多数模型经常在所有Conv-ReLU操作之间频繁使用它,形成“ Conv-BN-ReLU”三重奏(及其变体)。然而,尽管这是最常出现的层之一,但其优势背后的原因在文献中却有很多争议。下面三个主要的说法:
内部方差平移:简单地说,如果输出的均值和单位方差为零,则下一层会在稳定的输入上训练。换句话说,它可以防止输出变化太大。这是最初的解释,但后来的工作发现了相互矛盾的证据,否定了这一假设。简而言之,如果训练VGG网络(1)不使用BN,(2)使用BN和(3)使用BN加上人工协方差平移。尽管进行了人工协方差平移,方法(2)和(3)仍然优于(1) 。
输出平滑化:BN被认为可以平滑化优化范围,减少损失函数的变化量并限制其梯度。较平滑的目标在训练时预测效果会更好,并且不易出现问题。
长度方向解耦合:一些作者认为BN是针对优化问题的改进公式,因此可以扩展到更传统的优化设置。更详细地说,BN框架允许独立优化参数的长度和方向,从而改善收敛性。
总之,所有这三种解释都集中在批标准化的标准化方面。下面,我们将看一下由γ和β参数实现的BN的平移和缩放点。
复制论文
如果这个主意是好的,它应该对实现方式和超参数的选择具有弹性。在我的代码中,我使用Tensorflow 2和我自己选择的超参数来尽可能短地重新复现了论文中的主要实验。更详细地,我测试了以下命题:
ResNet模型中,除了批标准化层的参数所有其他权重已经被锁定的情况下,模型仍然可以在CIFAR-10数据集上训练处良好的结果。
我将使用Keras的CIFAR-10和ResNet模块以及CIFAR-10数据集,并使用交叉熵损失和Softmax激活。我的代码下载了数据集和随机初始化的ResNet模型,冻结了不需要的图层,并使用1024张图像的batchsize大小训练了50个epoch。您可以查看以下代码:
# Reproducing the main findings of the paper "Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs"
# Goal: Train a ResNet model to solve the CIFAR-10 dataset using only batchnorm layers, all else is frozen at their random initial state.
importtensorflowastf
importnumpyasnp
importpandasaspd
architectures = [
('ResNet-50', tf.keras.applications.resnet.ResNet50),
('ResNet-101', tf.keras.applications.resnet.ResNet101),
('ResNet-152', tf.keras.applications.resnet.ResNet152)]
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
n_train_images = X_train.shape[0]
n_test_images = X_test.shape[0]
n_classes = np.max(y_train) +1
X_train = X_train.astype(np.float32) /255
X_test = X_test.astype(np.float32) /255
y_train = tf.keras.utils.to_categorical(y_train, n_classes)
y_test = tf.keras.utils.to_categorical(y_test, n_classes)
forname, architectureinarchitectures:
input = tf.keras.layers.Input((32, 32, 3))
resnet = architecture(include_top=False, weights='imagenet', input_shape=(32, 32, 3), pooling='avg')(input)
output = tf.keras.layers.Dense(n_classes, activation='softmax')(resnet)
model = tf.keras.models.Model(inputs=input, outputs=output)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
he_normal = tf.keras.initializers.he_normal()
forlayerinmodel.layers[1].layers:
iflayer.name.endswith('_bn'):
new_weights = [
he_normal(layer.weights[0].shape), # Gamma
tf.zeros(layer.weights[1].shape), # Beta
tf.zeros(layer.weights[2].shape), # Mean
tf.ones(layer.weights[3].shape)] # Std
layer.set_weights(new_weights)
layer.trainable = True
else:
layer.trainable = False
model.summary()
model.compile(loss=loss_fn, optimizer=optimizer, metrics=['accuracy'])
print('Training '+name+'...')
history = model.fit(X_train, y_train, batch_size=1024, epochs=1, validation_data=(X_test, y_test), shuffle=True)
history_df = pd.DataFrame(history.history)
print('Dumping model and history...')
history_df.to_csv(name+'.csv', sep=';')
model.save(name+'.h5')
print('Testing Complete!')
上面的代码中应注意以下几点:
- Keras API仅具有ResNet-50、101和152模型。为简单起见,我只使用了这些模型。
- ResNet模型对γ参数使用“单一”初始化策略。在我们有限的训练过程中,这过于对称所以无法通过梯度下降进行训练。而是按照论文中的建议,使用“ he_normal”初始化。为此,我们在训练之前手动重新初始化“批标准化”的权重。
- 作者使用128的batchsize训练了160个epoch,并使用了动量为0.9的SGD优化器。最初将学习率设置为0.01,然后在第80和120个阶段将其设置为0.001和0.0001。这样是一个初始的想法,我发现这太具体了。取而代之的是,我使用了50个epoch,batchsize大小为1024,优化器为vanilla Adam,固定学习率为0.01。如果这个设想是有用的,这些改变都不会成为问题。
- 作者还使用了数据增强,而我没有使用。再说一次,如果这个想法有用,那么这些改变都不应该是一个重大问题。
结果
这是我通过上述代码获得的结果:
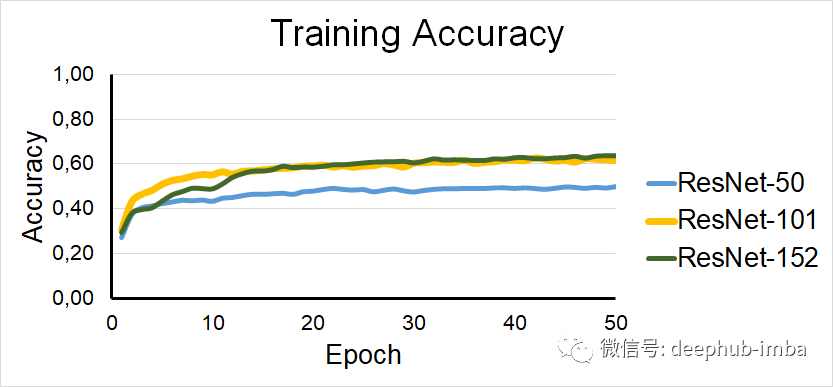
仅训练批标准化层的ResNet模型的训练集准确性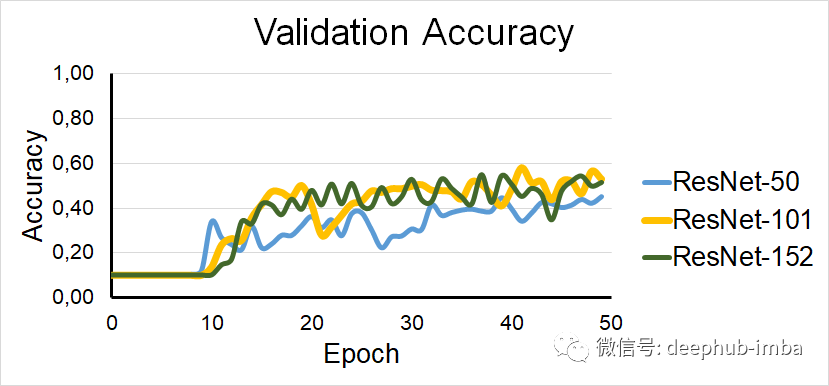
仅训练批标准化层的ResNet模型的验证集准确性
在数值上,这三个模型达到了50%,60%和62%的训练准确度以及45%,52%和50%的验证准确度。
为了对模型的性能有一个很好的了解,我们应该始终考虑随机猜测的性能。CIFAR-10数据集有十个类。因此,随机地,我们有10%的可能正确。以上方法比随机猜测要好大约五倍。因此,我们可以认为模型具有良好的性能。
有趣的是,验证准确性花了10个epoch才开始增加,这清楚地表明,对于前十个epoch,网络只是尽可能地拟合数据。后来,准确性大大提高。但是,它每五个epoch变化很大,这表明该模型不是很稳定。
在论文中,图2显示他们达到了〜70,〜75和〜77%的验证精度。考虑到作者进行了一些调整,使用了自定义的培训方式并采用了数据增强,这似乎非常合理,并且与我的发现一致,从而证实了这一假设。
使用866层的ResNet,作者的准确度几乎达到了约85%,仅比训练整个体系结构可达到的约91%少几个百分点。此外,他们测试了不同的初始化方案,体系结构,并测试了解冻最后一层并跳过全连接,这带来了一些额外的性能提升。
除了准确性之外,作者还研究了γ和β参数的直方图,发现该网络学会了通过将γ设置为接近零的值来抑制每个BN层中所有激活的三分之一。
讨论
此时,您可能会问:为什么要做这些?首先,这很有趣:)其次,BN层很平常,但是我们对其作用仍然只有一个肤浅的了解。我们只知道他的好处。第三,这种调查使我们对模型的运行方式有了更深入的了解。
我认为这本身并没有实际应用。没有人会冻结所有网络层而只保留BN层。但是,这可能会激发不同的培训时间表。也许像这样在几个时期内训练网络,然后训练所有权重可能会导致更高的性能。而且这种技术可能对微调预训练的模型很有用。我还可以看到这个想法被用于修剪大型网络。
这项研究使我最困惑的是,我们都多少忽略了这两个参数。我记忆中只有一次关于它的讨论,该讨论认为在ResNet块上用“零”初始化γ很好,以迫使反向传播算法在早期时期更多地跳过连接。
我的第二个问题是关于SELU和SERLU激活函数,它们具有自归一化属性。这两个功能都会在“批标准化”层经过时自然会标准化其输出。现在,我要问自己是否获得了批标准化层的全部特征。
最后,该假设仍然有点原始。它仅考虑CIFAR-10数据集和相当深的网络。如果它可以扩展到其他数据集或解决不同的任务(例如,仅使用Batchnorm的GAN),则会增加它的实用性。同样,对γ和β在完全训练的网络中的作用的后续文章更感兴趣。
作者:Ygor Rebouças Serpa
deephub翻译组 孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********