
什么是规则引擎
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
规则引擎能做什么
降低复杂业务逻辑组件复杂性、降低应用程序的维护和可扩展成本。
常见应用场景
1.风控配置
2.用户积分
3.离线计算
4.商品等级
应用规则引擎带来哪些好处
1.逻辑和数据隔离
2.可扩展性高
3.可维护性高
4.知识集中化
5.提高业务灵活性
6.业务透明度增强
7.减少系统频繁迭代升级风险
8.简化系统架构
核心组件
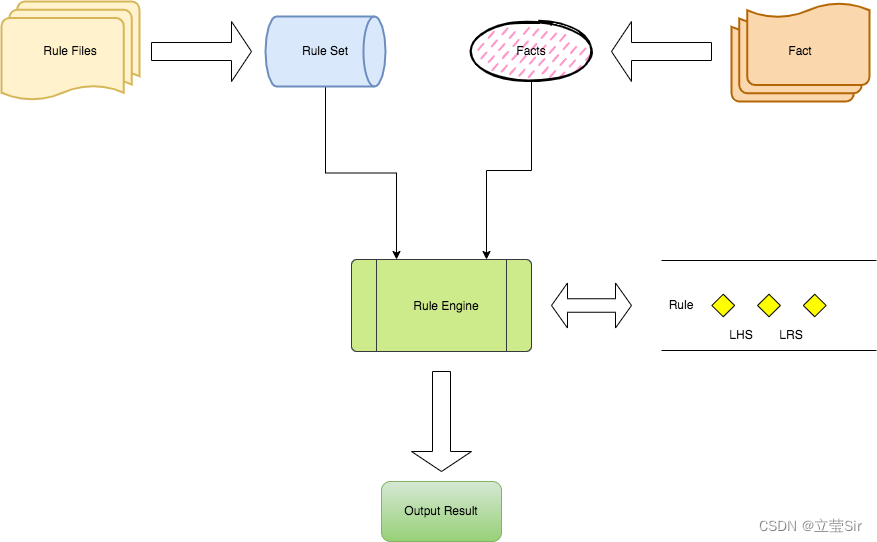
Fact
事实对象,对于真实事物或者事实的承载对象,例如:登录事实对象,可能包含:登录ip,用户id,登录设备,近一一小时内登录成功次数,近一小时登录失败次数,可以理解为规则引擎所需要的输入参数。规则引擎会基于Fact对象和规则,构造DAG。
Rule
规则,由条件构成和结论构成的推理语句。例如:if ... then ... else .....,if 登录ip in 黑产ip列表内,then 命中登录黑名单 else 放行。这里的规则通指,if..then...else...的原子规则,而非多条件多关系的规则集。
LHS
规则的左半部分,通常指规则的if.... 部分。进一步细化,一般是指,具体的左半边因子,操作符,右半边因子。例如:if 登录ip in 黑产ip列表内。左半边因子即登录ip,操作符即in,右半边因子即黑产ip列表。
RHS
规则的右半部分,通常指规则的then以及else部分。一般是指具体的action,因为then以及else,往往是对应具体的动作,例如:或者给其他参数赋值(赋值动作),执行其他的函数(执行方法动作)。
知识包,知识包是打包了,某一个业务场景下,所有的规则,所有的库文件(Fact元数据描述库,动作库,常量库,枚举库),甚至包括评分卡,决策流等。一个知识包往往是一个业务场景下大的集合,知识包都有版本概念,可以发布新版本的知识包,当有新的知识包发布,所有依赖某个业务规则的客户端,都会更新为最新知识包下的规则。
Session
kiesession代表一次回话,一个回话往往对应一个工作区,即包括整体流程的执行。
Workmemory
工作区,即执行规则的内存空间,一个workmemory对应一次回话,对应一次规则的执行。
Rete
由LHS部分构成的规则网络,通常是DAG图。
Rete算法_yin__ren的博客-CSDN博客_rete算法
漫话规则引擎(2): 模式匹配算法 - 心内求法 - 博客园
Agenda
议程,决定执行哪些RHS的Action。
Action
动作,RHS部分对应的具体动作,例如:赋值,打印参数,执行方法等。
技术选型
名称
场景
核心技术
优点
缺点
应用案例
难度
Drools
1、业务代码和业务规则分离
2、适用于大型应用系统
模式匹配:Rate OO 算法
1、将初始数据(fact)输入Working Memory。
2、使用Pattern Matcher比较规则(rule)和数据(fact)。
3、如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
4、解决冲突,将激活的规则按顺序放入Agenda。
5、使用规则引擎执行Agenda中的规则。重复步骤2至5,直到执行完毕所有Agenda中的规则。
1、功能完善
2、具有监控
3、操作平台等功能
4、支持DMN
5、文档完善
1、学习成本高
2、比较重,复杂度高
3、独立系统很难进行二次开发
4、以内存实现时间窗功能,无法支持较长跨度的时间窗
5、不二次开发很难融入京东技术生态
携程
🌟🌟🌟🌟🌟
EasyRules
1、业务代码和业务规则分离
2、适用于大型应用系统
表达式语言(MVEL/SpEL)
1、使用MVEL表达式模式开发时,可以直接编写java代码直接编译执行,更好的支持扩展
2、使用SpEL,模式时可以进行yml文件编写,更好支持脚本模式开发,yml格式文件更加易读
1、 轻量
2、 易学
3、支持复合规则
4、定义规则方式多样
5、支持复杂业务场景
6、可集成至京东技术生态
1、不支持DMN
2、活跃度较低
3、文档较少
Apache Nifi
🌟🌟🌟
Aviator
1、各种表达式的动态求值
Aviator会将表达是编程字节码,交给JVM去执行。 AviatorEvaluator(执行器)支持两种模式进行表达式执行: 1、以执行速度优先: AviatorEvaluator.setOptimize(AviatorEvaluator.EVAL); 2、编译速度优先,这样不会做编译优化: AviatorEvaluator.setOptimize(AviatorEvaluator.COMPILE); AviatorEvaluator在执行表达式执行结果,可以进行对表达式缓存,使用了LRU算法,进行缓存淘汰。
1、轻量级
2、高性能
3、文档完善
4、社区活跃
5、可扩展
6、易学
7、可集成至京东技术生态
1、不支持DMN
2、支持业务场景较简单
美团酒旅实时数据规则引擎
🌟🌟
URule
1、业务代码和业务规则分离
2、适用于大型应用系统
1、应用Rete算法做为核心算法,生成可视化Rete树,规则文件校验,模型版本控制
2、使用JSR 170进行规则内容存储管理
1、功能完善
2、支持规则集,决策树,决策表
3、文档完备(有视频教程)
4、易集成
5、易改造
1、社区不活跃
2、应用案例较少
3、源码应用技术栈相对落后
中小公司
🌟🌟🌟
**最终选择 **考虑对接系统:微应用制作,仓配相关业务系统等,大多应用场景为:页面组件校验规则,计算规则,频繁变更因子表示,多数属于表达式规则,故选择更加轻量级,高效的表达式引擎,Aviator。
AviatorScript 文档 · 语雀
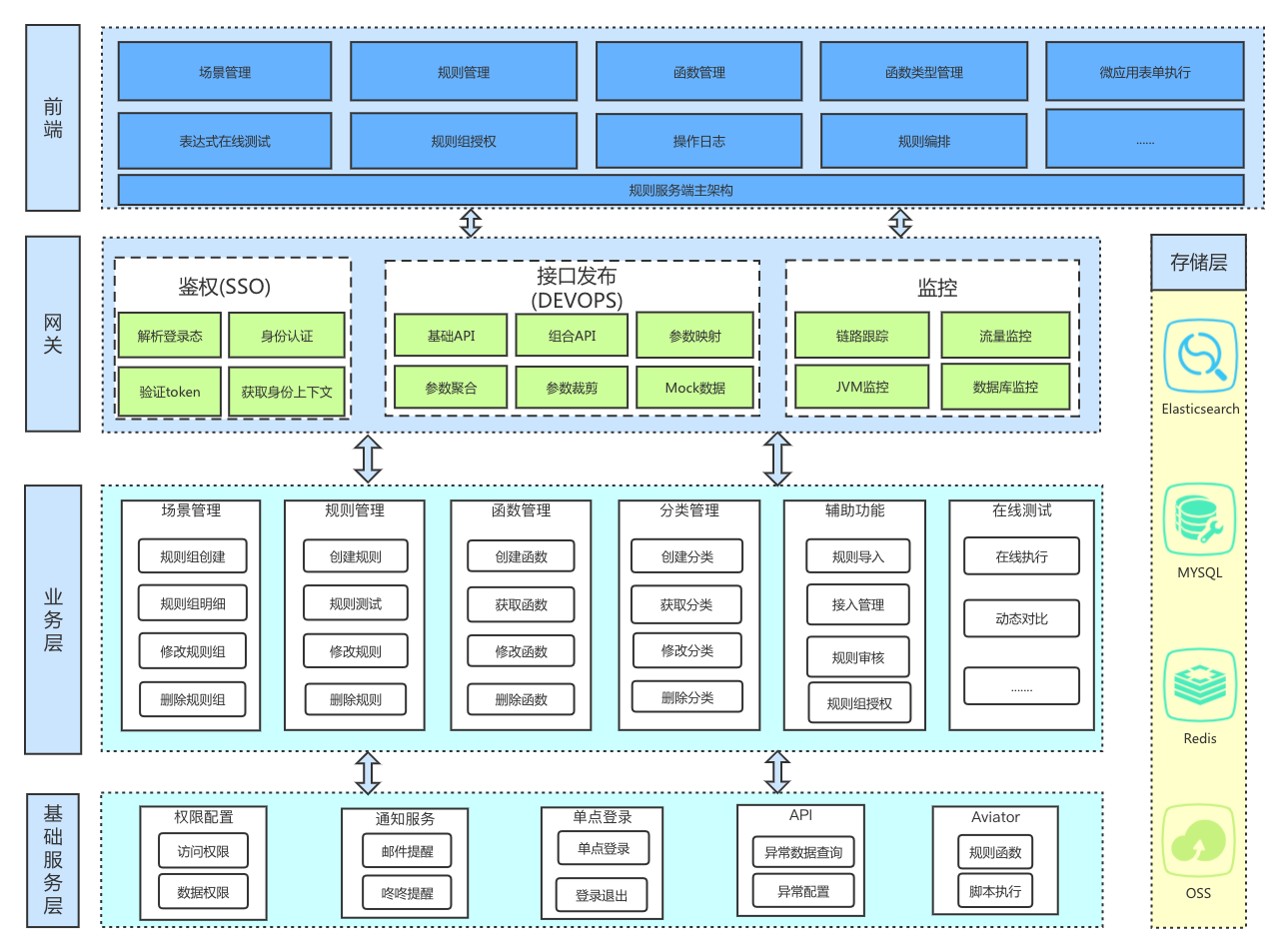
微应用规则引擎
架构设计
规则依赖流程

版权归原作者 抱抱果ゝ 所有, 如有侵权,请联系我们删除。