
Python爬虫以及数据可视化分析之Bilibili动漫排行榜信息爬取分析
简书地址:https://www.jianshu.com/u/40ac87350697
简单几步,通过Python对B站番剧排行数据进行爬取,并进行可视化分析
源码文件可以参考Github上传的项目:https://github.com/Lemon-Sheep/Py/tree/master
下面,我们开始吧!
PS: 作为Python爬虫初学者,如有不正确的地方,望各路大神不吝赐教[抱拳]
本项目将会对B站番剧排行的数据进行网页信息爬取以及数据可视化分析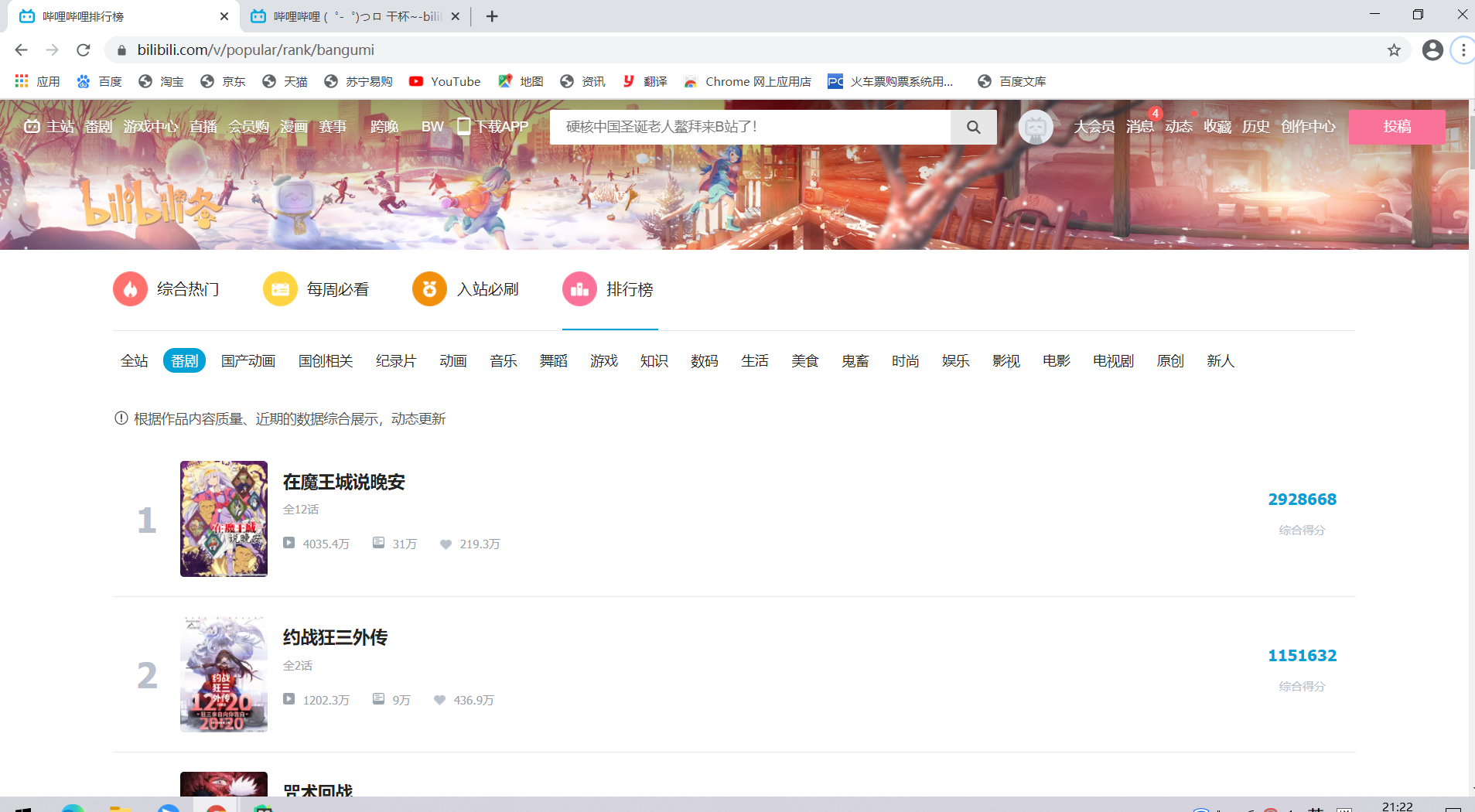
首先,准备好相关库
requests、pandas、BeautifulSoup、matplotlib等
因为这是第三方库,所以我们需要额外下载
下载有两种方法(以requests为例,其余库的安装方法类似):
(一)在命令行输入
前提:装了pip( Python 包管理工具,提供了对Python 包的查找、下载、安装、卸载的功能。 )
pip install requests
(二)通过PyCharm下载
第一步:编译器左上角File–>Settings…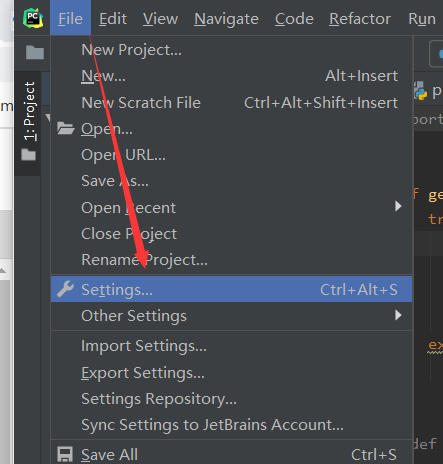
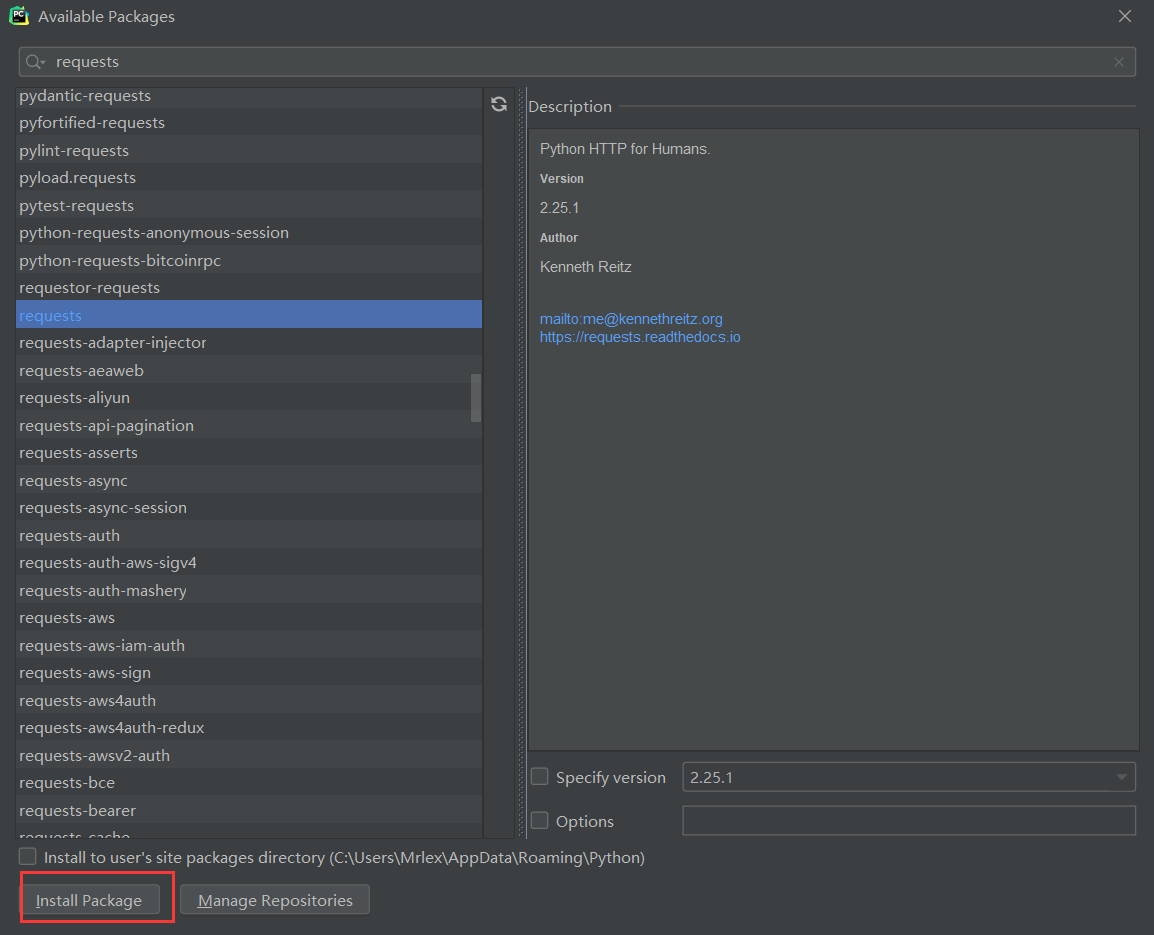
第二步:找到Project Interpreter 点击右上角加号按钮,弹出界面上方搜索库名:requests,点击左下角Install ,当提示successfully时,即安装完成。
准备工作做好后,开始项目的实行
一、获取网页内容
def get_html(url):
try:
r = requests.get(url) # 使用get来获取网页数据
r.raise_for_status() # 如果返回参数不为200,抛出异常
r.encoding = r.apparent_encoding # 获取网页编码方式
return r.text # 返回获取的内容
except:
return '错误'
我们来看爬取情况,是否有我们想要的内容:
def main():
url = 'https://www.bilibili.com/v/popular/rank/bangumi' # 网址
html = get_html(url) # 获取返回值
print(html) # 打印
if __name__ == '__main__': #入口
main()
爬取结果如下图所示:
成功!
二、信息解析阶段:
第一步,先构建BeautifulSoup实例
soup = BeautifulSoup(html, 'html.parser') # 指定BeautifulSoup的解析器
第二步,初始化要存入信息的容器
# 定义好相关列表准备存储相关信息
TScore = [] # 综合评分
name = [] # 动漫名字
play= [] # 播放量
review = [] # 评论数
favorite= [] # 收藏数
第三步,开始信息整理
我们先获取番剧的名字,并将它们先存进列表中
# ******************************************** 动漫名字存储
for tag in soup.find_all('div', class_='info'):
# print(tag)
bf = tag.a.string
name.append(str(bf))
print(name)
此处我们用到了beautifulsoup的find_all()来进行解析。在这里,find_all()的第一个参数是标签名,第二个是标签中的class值(注意下划线哦(class_=‘info’))。
我们在网页界面按下F12,就能看到网页代码,找到相应位置,就能清晰地看见相关信息: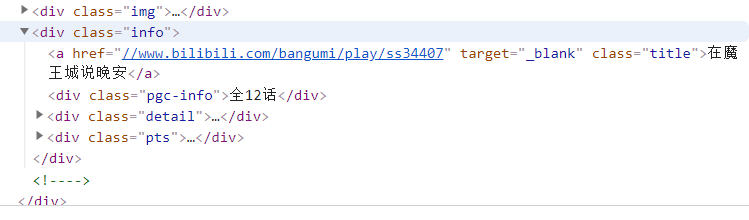
接着,我们用几乎相同的方法来对综合评分、播放量,评论数和收藏数来进行提取
# ******************************************** 播放量存储
for tag in soup.find_all('div', class_='detail'):
# print(tag)
bf = tag.find('span', class_='data-box').get_text()
# 统一单位为‘万’
if '亿' in bf:
num = float(re.search(r'\d(.\d)?', bf).group()) * 10000
# print(num)
bf = num
else:
bf = re.search(r'\d*(\.)?\d', bf).group()
play.append(float(bf))
print(play)
# ******************************************** 评论数存储
for tag in soup.find_all('div', class_='detail'):
# pl = tag.span.next_sibling.next_sibling
pl = tag.find('span', class_='data-box').next_sibling.next_sibling.get_text()
# *********统一单位
if '万' not in pl:
pl = '%.1f' % (float(pl) / 10000)
# print(123, pl)
else:
pl = re.search(r'\d*(\.)?\d', pl).group()
review.append(float(pl))
print(review)
# ******************************************** 收藏数
for tag in soup.find_all('div', class_='detail'):
sc = tag.find('span', class_='data-box').next_sibling.next_sibling.next_sibling.next_sibling.get_text()
sc = re.search(r'\d*(\.)?\d', sc).group()
favorite.append(float(sc))
print(favorite)
# ******************************************** 综合评分
for tag in soup.find_all('div', class_='pts'):
zh = tag.find('div').get_text()
TScore.append(int(zh))
print('综合评分', TScore)
其中有个.next_sibling是用于提取同级别的相同标签信息,如若没有这个方法,当它找到第一个’span’标签之后,就不会继续找下去了(根据具体情况来叠加使用此方法);
还用到了正则表达式来提取信息(需要导入库‘re’)
最后我们将提取的信息,存进excel表格之中,并返回结果集
# 存储至excel表格中
info = {'动漫名': name, '播放量(万)': play, '评论数(万)': review,'收藏数(万)': favorite, '综合评分': TScore}
dm_file = pandas.DataFrame(info)
dm_file.to_excel('Dongman.xlsx', sheet_name="动漫数据分析")
# 将所有列表返回
return name, play, review, favorite, TScore
我们可以打开文件看一看存储的信息格式(双击打开)
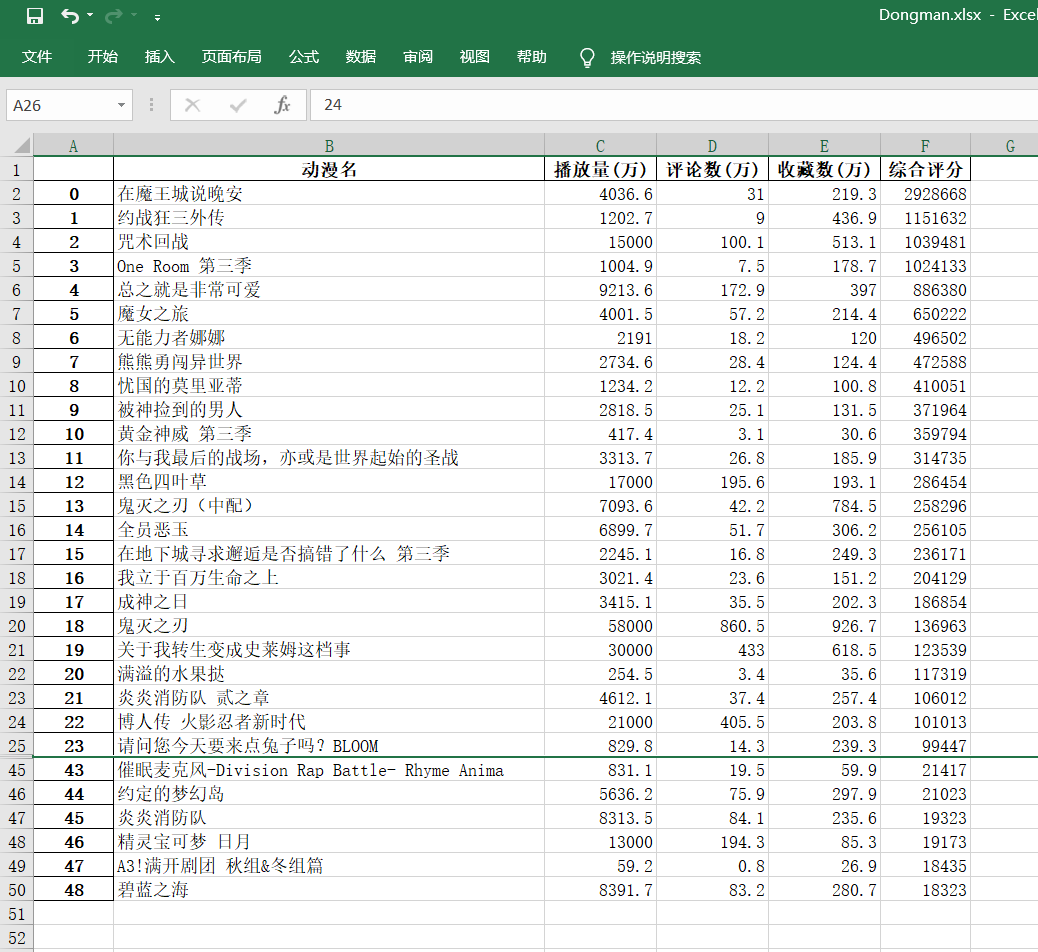
成功!
三、数据可视化分析
我们先做一些基础设置
要先准备一个文件: STHeiti Medium.ttc [注意存放在项目中的位置]
my_font = font_manager.FontProperties(fname='./data/STHeiti Medium.ttc') # 设置中文字体(图表中能显示中文)
# 为了坐标轴上能显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
dm_name = info[0] # 番剧名
dm_play = info[1] # 番剧播放量
dm_review = info[2] # 番剧评论数
dm_favorite = info[3] # 番剧收藏数
dm_com_score = info[4] # 番剧综合评分
# print(dm_com_score)
然后,开始使用matplot来绘制图形,实现数据可视化分析
文中有详细注释,这里就不再赘述了,聪明的你一定一看就懂了~
# **********************************************************************综合评分和播放量对比
# *******综合评分条形图
fig, ax1 = plt.subplots()
plt.bar(dm_name, dm_com_score, color='red') #设置柱状图
plt.title('综合评分和播放量数据分析', fontproperties=my_font) # 表标题
ax1.tick_params(labelsize=6)
plt.xlabel('番剧名') # 横轴名
plt.ylabel('综合评分') # 纵轴名
plt.xticks(rotation=90, color='green') # 设置横坐标变量名旋转度数和颜色
# *******播放量折线图
ax2 = ax1.twinx() # 组合图必须加这个
ax2.plot(dm_play, color='cyan') # 设置线粗细,节点样式
plt.ylabel('播放量') # y轴
plt.plot(1, label='综合评分', color="red", linewidth=5.0) # 图例
plt.plot(1, label='播放量', color="cyan", linewidth=1.0, linestyle="-") # 图例
plt.legend()
plt.savefig(r'E:1.png', dpi=1000, bbox_inches='tight') #保存至本地
plt.show()
来看看效果
有没有瞬间就感觉高大上~~了(嘿嘿~)
然后我们用相同的方法来多绘制几个对比图:
# **********************************************************************评论数和收藏数对比
# ********评论数条形图
fig, ax3 = plt.subplots()
plt.bar(dm_name, dm_review, color='green')
plt.title('番剧评论数和收藏数分析')
plt.ylabel('评论数(万)')
ax3.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******收藏数折线图
ax4 = ax3.twinx() # 组合图必须加这个
ax4.plot(dm_favorite, color='yellow') # 设置线粗细,节点样式
plt.ylabel('收藏数(万)')
plt.plot(1, label='评论数', color="green", linewidth=5.0)
plt.plot(1, label='收藏数', color="yellow", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:2.png', dpi=1000, bbox_inches='tight')
# **********************************************************************综合评分和收藏数对比
# *******综合评分条形图
fig, ax5 = plt.subplots()
plt.bar(dm_name, dm_com_score, color='red')
plt.title('综合评分和收藏数量数据分析')
plt.ylabel('综合评分')
ax5.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******收藏折线图
ax6 = ax5.twinx() # 组合图必须加这个
ax6.plot(dm_favorite, color='yellow') # 设置线粗细,节点样式
plt.ylabel('收藏数(万)')
plt.plot(1, label='综合评分', color="red", linewidth=5.0)
plt.plot(1, label='收藏数', color="yellow", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:3.png', dpi=1000, bbox_inches='tight')
# **********************************************************************播放量和评论数对比
# *******播放量条形图
fig, ax7 = plt.subplots()
plt.bar(dm_name, dm_play, color='cyan')
plt.title('播放量和评论数 数据分析')
plt.ylabel('播放量(万)')
ax7.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******评论数折线图
ax8 = ax7.twinx() # 组合图必须加这个
ax8.plot(dm_review, color='green') # 设置线粗细,节点样式
plt.ylabel('评论数(万)')
plt.plot(1, label='播放量', color="cyan", linewidth=5.0)
plt.plot(1, label='评论数', color="green", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:4.png', dpi=1000, bbox_inches='tight')
plt.show()
我们来看看最终效果
Nice!很完美~ 大家可以根据自己的想法按照相同的方法进行数据组合分析。
最后,附上全部代码
import re
import pandas
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
from matplotlib import font_manager
def get_html(url):
try:
r = requests.get(url) # 使用get来获取网页数据
r.raise_for_status() # 如果返回参数不为200,抛出异常
r.encoding = r.apparent_encoding # 获取网页编码方式
return r.text # 返回获取的内容
except:
return '错误'
def save(html):
# 解析网页
soup = BeautifulSoup(html, 'html.parser') # 指定Beautiful的解析器为“html.parser”
with open('./data/B_data.txt', 'r+', encoding='UTF-8') as f:
f.write(soup.text)
# 定义好相关列表准备存储相关信息
TScore = [] # 综合评分
name = [] # 动漫名字
bfl = [] # 播放量
pls = [] # 评论数
scs = [] # 收藏数
# ******************************************** 动漫名字存储
for tag in soup.find_all('div', class_='info'):
# print(tag)
bf = tag.a.string
name.append(str(bf))
print(name)
# ******************************************** 播放量存储
for tag in soup.find_all('div', class_='detail'):
# print(tag)
bf = tag.find('span', class_='data-box').get_text()
# 统一单位为‘万’
if '亿' in bf:
num = float(re.search(r'\d(.\d)?', bf).group()) * 10000
# print(num)
bf = num
else:
bf = re.search(r'\d*(\.)?\d', bf).group()
bfl.append(float(bf))
print(bfl)
# ******************************************** 评论数存储
for tag in soup.find_all('div', class_='detail'):
# pl = tag.span.next_sibling.next_sibling
pl = tag.find('span', class_='data-box').next_sibling.next_sibling.get_text()
# *********统一单位
if '万' not in pl:
pl = '%.1f' % (float(pl) / 10000)
# print(123, pl)
else:
pl = re.search(r'\d*(\.)?\d', pl).group()
pls.append(float(pl))
print(pls)
# ******************************************** 收藏数
for tag in soup.find_all('div', class_='detail'):
sc = tag.find('span', class_='data-box').next_sibling.next_sibling.next_sibling.next_sibling.get_text()
sc = re.search(r'\d*(\.)?\d', sc).group()
scs.append(float(sc))
print(scs)
# ******************************************** 综合评分
for tag in soup.find_all('div', class_='pts'):
zh = tag.find('div').get_text()
TScore.append(int(zh))
print('综合评分', TScore)
# 存储至excel表格中
info = {'动漫名': name, '播放量(万)': bfl, '评论数(万)': pls, '收藏数(万)': scs, '综合评分': TScore}
dm_file = pandas.DataFrame(info)
dm_file.to_excel('Dongman.xlsx', sheet_name="动漫数据分析")
# 将所有列表返回
return name, bfl, pls, scs, TScore
def view(info):
my_font = font_manager.FontProperties(fname='./data/STHeiti Medium.ttc') # 设置中文字体(图标中能显示中文)
dm_name = info[0] # 番剧名
dm_play = info[1] # 番剧播放量
dm_review = info[2] # 番剧评论数
dm_favorite = info[3] # 番剧收藏数
dm_com_score = info[4] # 番剧综合评分
# print(dm_com_score)
# 为了坐标轴上能显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# **********************************************************************综合评分和播放量对比
# *******综合评分条形图
fig, ax1 = plt.subplots()
plt.bar(dm_name, dm_com_score, color='red') #设置柱状图
plt.title('综合评分和播放量数据分析', fontproperties=my_font) # 表标题
ax1.tick_params(labelsize=6)
plt.xlabel('番剧名') # 横轴名
plt.ylabel('综合评分') # 纵轴名
plt.xticks(rotation=90, color='green') # 设置横坐标变量名旋转度数和颜色
# *******播放量折线图
ax2 = ax1.twinx() # 组合图必须加这个
ax2.plot(dm_play, color='cyan') # 设置线粗细,节点样式
plt.ylabel('播放量') # y轴
plt.plot(1, label='综合评分', color="red", linewidth=5.0) # 图例
plt.plot(1, label='播放量', color="cyan", linewidth=1.0, linestyle="-") # 图例
plt.legend()
plt.savefig(r'E:1.png', dpi=1000, bbox_inches='tight') #保存至本地
# plt.show()
# **********************************************************************评论数和收藏数对比
# ********评论数条形图
fig, ax3 = plt.subplots()
plt.bar(dm_name, dm_review, color='green')
plt.title('番剧评论数和收藏数分析')
plt.ylabel('评论数(万)')
ax3.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******收藏数折线图
ax4 = ax3.twinx() # 组合图必须加这个
ax4.plot(dm_favorite, color='yellow') # 设置线粗细,节点样式
plt.ylabel('收藏数(万)')
plt.plot(1, label='评论数', color="green", linewidth=5.0)
plt.plot(1, label='收藏数', color="yellow", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:2.png', dpi=1000, bbox_inches='tight')
# **********************************************************************综合评分和收藏数对比
# *******综合评分条形图
fig, ax5 = plt.subplots()
plt.bar(dm_name, dm_com_score, color='red')
plt.title('综合评分和收藏数量数据分析')
plt.ylabel('综合评分')
ax5.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******收藏折线图
ax6 = ax5.twinx() # 组合图必须加这个
ax6.plot(dm_favorite, color='yellow') # 设置线粗细,节点样式
plt.ylabel('收藏数(万)')
plt.plot(1, label='综合评分', color="red", linewidth=5.0)
plt.plot(1, label='收藏数', color="yellow", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:3.png', dpi=1000, bbox_inches='tight')
# **********************************************************************播放量和评论数对比
# *******播放量条形图
fig, ax7 = plt.subplots()
plt.bar(dm_name, dm_play, color='cyan')
plt.title('播放量和评论数 数据分析')
plt.ylabel('播放量(万)')
ax7.tick_params(labelsize=6)
plt.xticks(rotation=90, color='green')
# *******评论数折线图
ax8 = ax7.twinx() # 组合图必须加这个
ax8.plot(dm_review, color='green') # 设置线粗细,节点样式
plt.ylabel('评论数(万)')
plt.plot(1, label='播放量', color="cyan", linewidth=5.0)
plt.plot(1, label='评论数', color="green", linewidth=1.0, linestyle="-")
plt.legend()
plt.savefig(r'E:4.png', dpi=1000, bbox_inches='tight')
plt.show()
def main():
url = 'https://www.bilibili.com/v/popular/rank/bangumi' # 网址
html = get_html(url) # 获取返回值
# print(html)
info = save(html)
view(info)
if __name__ == '__main__':
main()
关于图表的分析和得出的结论,这里就不描述了,一千个读者就有一千个哈姆雷特,每个人有每个人的分析描述方法,相信你们能有更加透彻的见解分析。
以上就是关于爬虫以及数据可视化分析的内容,希望能帮到你们!
伙伴们可以到github上查看源码文件:https://github.com/Lemon-Sheep/Py/tree/master
喜欢记得点个赞哦~
版权归原作者 三秋树&二月花 所有, 如有侵权,请联系我们删除。