
一:doris基础介绍
1.1 doris介绍
1.1.1 定义
doris是一个基于mmp(massively parallel processing,即大规模并行处理)的交互式sql数据仓库,是一个面向多种数据分析场景的、兼容mysql协议的、高性能的、分布式关系型列式数据库,用于报告和分析。
1.1.2 具体的业务场景包括
- 数据仓库建设
- olap分析
- 用户行为分析
- 系统监控分析
1.1.3 Doris关键特性
- 支持mysql协议
- 按key排序
- 在线表结构变更
- 两层分区。分区:range partition; 分桶 hash bucket
- mpp查询引擎:基于impala
- 列式存储:按列存储,高压缩比,多种索引
- 高基数精准去重
- 元数据全内存访问,快速访问
- 高度内聚,不依赖第三方系统
二:Doris与其它数据库比较
特征
Hadoop
MPPDB
传统数据库
扩展能力
高
中(通过Hash计算数据行的物理机器,存储位置不透明
⚠️并行:数据通过Hash存储,但是任务没有,无论大小会在每个节点走一圈))
低
系统和系统管理成本
高
中(数据切分了,但是文件数没有变少,每个表在每个节点上一定有一到多个文件。同样节点数越多,存储的表就越多,导致每个文件系统上有上万甚至十万多个文件)
中
应用开发维护成本
高
中(只设置 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。)
中
SQL支持
中
高。在使用接口方面,Doris采用mysql协议,高度兼容mysql语法,支持标准sql。
高
数据规模
PB级别
准PB级别
TB级别
计算性能
对非关系型操作效率高
对关系型操作效率高
对关系型操作效率高
数据结构
结构化、半结构化和非结构化数据
结构化数据
结构化数据
特征总结
Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求
MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
Doris采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用io和cpu资源。
应用场景
Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
适合多维度数据自助分析、数据集市等
三:底层索引与读写流程
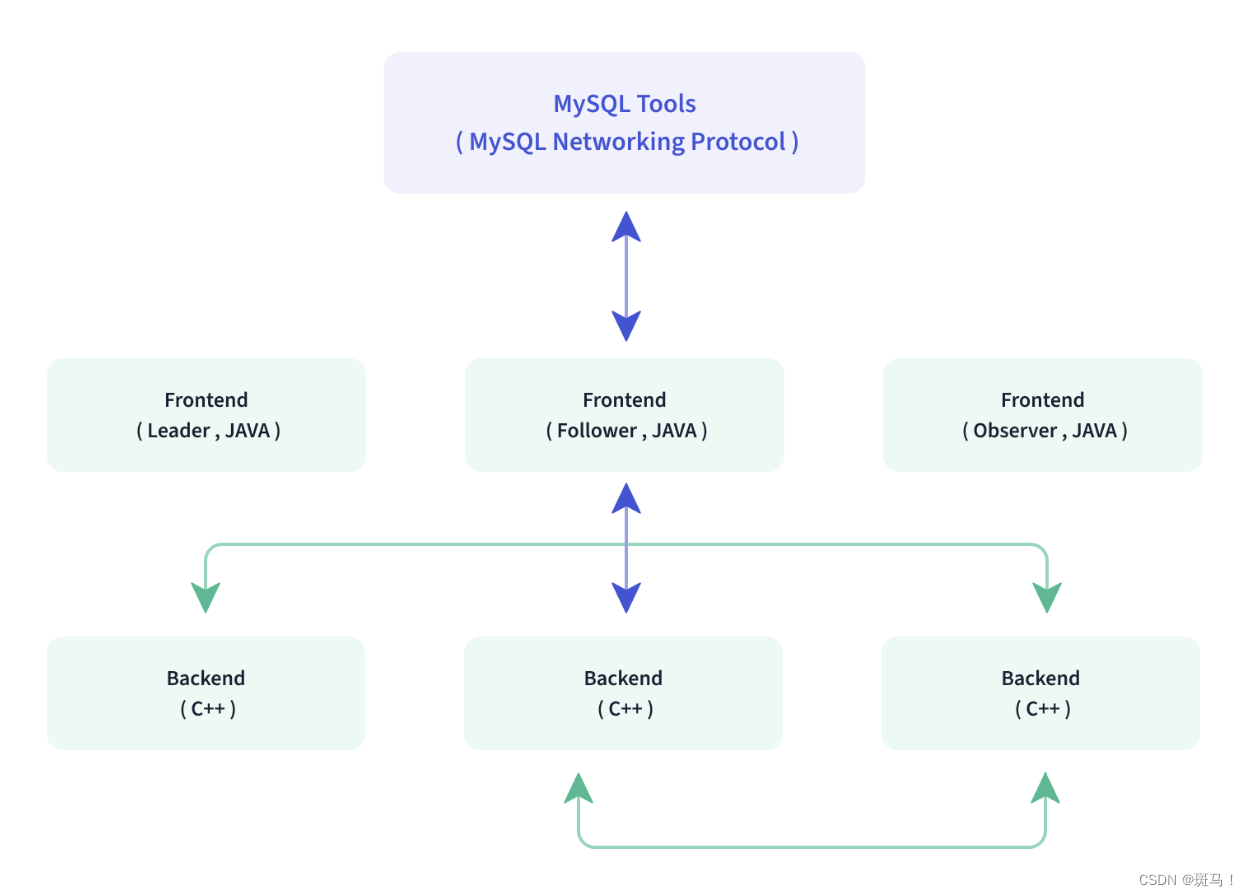
3.1 Doris整体架构
- Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- Backend(BE),主要负责数据存储、查询计划的执行
3.2 Doris存储设计目标
支持大数据量的分布式数据管理
支持事务
- 两阶段提交
- 数据多版本管理
对分析型友好
- 灵活的数据模型:aggregate、uniq、duplicate
- 高效的查询:列式存储、索引设计、预聚合rollupp
- 大批量的写入:索引&compation机制
高吞吐
四:数据划分(分区、分桶)
4.1 分区&分桶&表
在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
注意:一定要设置分桶,可以不设置分区;换句话说必须要有分桶。
4.2 分区分桶使用
Doris支持两层的数据划分。第一层是partition ,支持range和list的划分方式;第二层是bucket(tablet),仅支持hash的划分方式。也可以仅仅使用一层分区,使用一层分区的时候,仅仅支持bucket划分。
1.partition
- partition列可以指定一列或者多列,分区列必须为key列。另外还有多列分区的使用方式。
- 不论分区是什么类型,在写分区值时,都要加双引号。
- 分区数量理论没有上限。
- 当不使用partition by建表的时候,系统会自动生成一个和表名同名的,全值范围的partition,该partition对用户不可见,并且不可修改。
- 创建分区的时候不可叠加范围重叠的分区。
2.range分区
- 分区列通常为时间列,以方便管理新旧数据;
- Partition 支持通过 VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。同时,也支持通过 VALUES [...) 指定上下界,生成一个左闭右开的区间。
- 分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。通过 VALUES LESS THAN 语句增加分区时,分区的下界紧接上一个分区的上界。
- Range分区除了上述我们看到的单列分区,也支持多列分区,例如指定 date(DATE 类型) 和 id(INT 类型) 作为分区列。
3.list分区
- 分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
- List分区也支持多列分区
4.bucket
- 如果使用了partition,则distributed ... 语句描述的是数据在各个分区内的划分规则,如果不使用partition ,则描述的是对整个表的数据的划分规则。
- 分桶列可以是多列,但必须为key列,分桶列可以和partition列相同或者不同。
- 分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:- 如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。- 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
补充:吞吐量的定义:指对网络、设备、端口、虚电路或者其它设施,单位时间内成功地传送数据的数量。
4.3 partition和bucket的数量和数据量的建议
- 一个表的tablet总数量等于(partition num * bucket num)。
- 一个表的tablet数量,在不考虑扩容的情况下,推荐稍多于整个集群的磁盘数量。
- 单个tablet的数据量理论上没有上下界,但建议在1G--10G的范围内,如果单个tablet数据量过小,则数据的聚合效果不佳,且原数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加schema change或者rollup操作失败重试的代价(这些操作失败重试的粒度是tablet)。
- 当tablet的数据量原则和数量原则冲突的时候,建议优先考虑数据量原则。
- 在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
- 一个partition的Bucket数量一旦指定,不可更改。所以在确定Bucket数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
4.4 复合分区与单分区
复合分区
- 第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
以下场景推荐使用复合分区
- 有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做 HASH 分布
五:数据模型特性与选择
三种模型介绍与对比选择
注意:数据模型的选择建议(因为数据模型在建表的时候就已经确定,且无法修改,所以选择一个合适的数据模型非常重要)
aggregate模型
uniq模型
duplicate模型
优
势
通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。
目前有四种聚合方式:
- sum:求和,多行的value进行累加。
- replace:替代,下一批数据中的value会替换之前导入过的行中的value。
- max:保留最大值。
- min:保留最小值。
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。
在某些多维分析场景下,数据既没有主键,也没有聚合需求。引入 Duplicate 数据模型来满足这类需求
不受聚合模型的约束,可以发挥列模型的优势。
缺
点
该模型对count()查询很不友好。
扩展1(原理解释):在其它数据库中,类似于count(*)都会很快的返回结果,因为在实现上有方法1和方法2两种:
- 可以通过如“导入时对其进行计数”,来保存count的统计信息
- 查询时仅扫描某一列数据,获得count()值的方式,只需要很小的开销,即可获得查询结果。
- Doris:在doris中,必须扫描所有的的aggregate key列,并且聚合后,才能获得正确的语义结果,当聚合列非常多时,count(*)需要扫描大量的数据。(可以看到上面的方法1、方法2都得不到正确结果)
扩展2(解决方案):当业务上有count()的需求时候(例如表粒度是干预ID,要求干预总数这种),建议用户增加一个值恒为1(/0)的一列,然后使用聚合类型为sum的列来模拟count().
- 前提条件:用户需要自行保证,不会重复导入aggregate key列都相同的行(换句话说,每一行粒度要保证,要有主键)。
- 增加一个cnt列(值恒为1),则select count() from table的结果等价于*select sum(cnt) from table,而后者的查询效率将远高于前者。
- 当不满足前提条件的时候,select sum(cnt)只能表述原始导入的行数,而不是select count(*) from table。
1)无法利用rollup等预聚合带来的查询优势(因为本质是replace,没有sum这种聚合方式)
2)同左侧count()的缺点,解决方案也相同,因为uniq视作聚合模型的replace,但是此时就没有前提条件了,也就是说select sum(cnt)的结果一直等于select count(*) from table,即没有导入重复行的限制!
1)这种数据模型区别于 Aggregate 和 Unique 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。
2)Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。(优点)
备
注
- 一般而言,Doris中最终只会存储聚合后的数据,换句话说,即明细数据会丢失,用户不能够再查询聚合前的明细数据了。
- 当保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
uniq模型本质上上聚合模型的一个特例。完全可以使用聚合模型中的replace方式替代,其内部的实现方式和数据存储方式也完全一样
六:上卷
6.1 基本概念
- rollup在多维分析中是“上卷”的意思,即将数据按照某种指定的粒度进行进一步聚合。
- 在Doris中,我们将用户通过建表语句创建出来的表称为base表(base table)。base表中保存中按用户建表语句指定的方式存储的基础数据。
- 在base表之上,我们可以创建任意多个rollup表,这些rollup的数据是基于base表产生的,并且在物理上是独立存储的。
- rollup表的基本作用:在于base表的基础上,获得更粗粒度的聚合数据。
6.2 rollup使用说明
- rollup最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列以匹配前缀索引)。因此rollup的含义已经超出了“上卷”的范围。这也是为什么我们在源代码中,将其命名为materialized index(物化索引)的原因。
- rollup是附属base表的,可以看作是base表的一种辅助数据结构。用户可以在base表的基础上,创建或者删除rollup,但是不能在查询中显式的指定查询某rollup,是否命中rollup完全由doris系统自动决定。
- rollup的数据是独立物理存储的,因此创建的rollup越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的etl阶段会自动产生所有的rollup的数据),但是并不会降低查询效率(只会更好)。
- ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
- ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
- 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
- 某些类型的的查询,例如count(*)在任何条件下,都无法命中rollup。
七:索引
目前Doris主要支持两类索引:内建的智能索引,包括前缀索引和zonemap索引。用户创建的二级索引,包括bloom filter索引和bitmap倒排索引。其中 ZoneMap 索引是在列存格式上,对每一列自动维护的索引信息,包括 Min/Max,Null 值个数等等。这种索引对用户透明。
7.1 前缀索引
- 不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
- 本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
- 在 Aggregate、Unique 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
- 而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式
1)如何通过索引优化
创建表时:
在创建Doris表的时候,在字段配置处,可以通过调整字段先后的顺序,来达到提高索引命中的目的
rollup:
通过rollup来调整字段先后顺序,来达到加快查询效率。
补充:因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建rollup来人为的调整列的顺序。
2)索引优化的依据:
Doris将一行数据的前 32 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断;
{prediction_col} 中尽可能避免VARCHAR类型,如果存在VARCHAR类型,请尽量放在后面。
7.2 bloomfilter索引
1
7.3 bitmap索引
用户可以通过创建bitmap index加速查询,本文档主要介绍如何创建index作业,以及创建index的一些注意事项和常见问题。
定义:bitmap index:位图索引,是一种快速数据结构,能够加快查询速度,
原理介绍:创建和删除本质上是一个schema change的作业。
注意事项:
- 目前索引仅支持bitmp类型的索引。
- bitmap索引仅支持在单列上创建。
- bitmap索引能够应用在duplicate、uniq数据模型的所有列和aggregate模型的key列上
版权归原作者 斑马! 所有, 如有侵权,请联系我们删除。