
只要思想不滑坡,办法总比困难多
昨天在写练习题的时候写到这点特别迷,一直绕不过这个弯,最后也算是成功实现吧,记录一下,防止下次再绕的出不来。
之前访问的的Github镜像站一直触发滥用检测机制,着实很烦人。
代码实现过程
- 编写敏感词词汇文件 filtered_words.txt
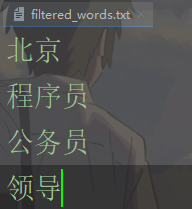 假设文件有四个敏感词汇,当输入的信息包含文件中的词汇时,进行替换
假设文件有四个敏感词汇,当输入的信息包含文件中的词汇时,进行替换 - 接受键盘输入,读取 filtered_words.txt 文件内容
words = input("请输入要检测的词语>>")
file_path = r'./assist/filtered_words.txt' # 文件保存路径
with open(file_path, 'r') as f:
# f.read() 原始格式为字符串
z = "".join(f.read()).split("\n") #将文本内件内容以换行符为界,转换为列表
注意,应该将词汇整体转换为一个列表对象,而不是逐字转换
z 的格式及内容
- 通过遍历列表 z,判断列表中的元素是否在 words 中,如果存在则转换为 len(z[i]) 长度的 *
for i in range(0, len(z)):
if z[i] in words:
words = words.replace(z[i], "*" * len(z[i]))
单独的‘北’和‘程序’并没有被装换
7. 综上,我认为程序功能已经实现,刚开始一直绕不出来的地方主要就在于字符串格式的转换,要不就是无法输出,要不就是逐字检测,要不就是单字逐行输出
若有纰漏,错误,不足之处,烦请不吝指正
标签:
python
本文转载自: https://blog.csdn.net/m0_51492762/article/details/120633425
版权归原作者 浅尝辄止_ 所有, 如有侵权,请联系我们删除。
版权归原作者 浅尝辄止_ 所有, 如有侵权,请联系我们删除。