
1. Hadoop 生态圈组件介绍
Hadoop 生态系统包含多个组件,每个组件都有不同的功能。以下是一些核心组件的介绍:
- HDFS(Hadoop Distributed File System):用于存储大规模数据的分布式文件系统。它将数据分成块并在集群中的多个节点上进行存储。
- MapReduce:分布式计算框架,用于处理大规模数据集。它将任务分为 Map 阶段和 Reduce 阶段,适合离线数据处理。
- YARN(Yet Another Resource Negotiator):资源管理器,负责集群资源的分配和调度。
- Hive:基于 Hadoop 的数据仓库工具,用于查询和分析大规模数据。
- Pig:高级脚本语言,用于数据分析和转换。
- HBase:分布式 NoSQL 数据库,适用于实时读写大量数据。
- Spark:快速、通用、内存计算的大数据处理框架。

2. MapReduce 概述
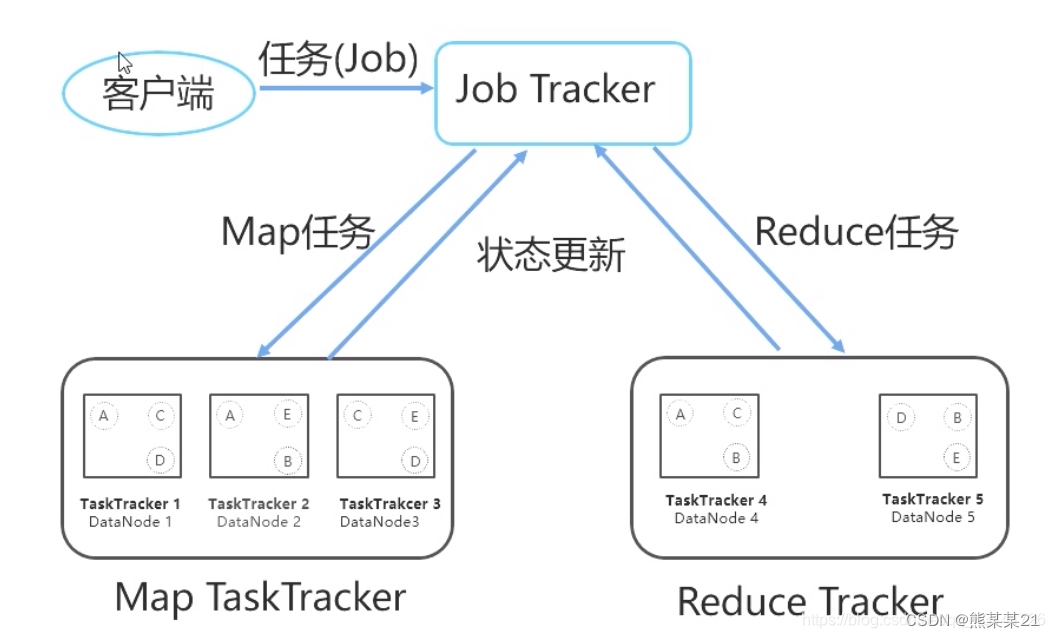
- MapReduce 是一种编程模型,用于处理大规模数据集。
- 它将任务分为两个阶段:Map 阶段和 Reduce 阶段。
- Map 阶段将输入数据拆分成键值对,然后应用用户定义的函数进行处理。
- Reduce 阶段将 Map 阶段的输出进行合并和汇总。
- MapReduce 适用于离线数据处理,但不适合实时数据处理。
3. Spark 技术特点和概述
- Spark 是一个通用的大数据处理框架,具有以下特点: -

4. MapReduce 和 Spark 的区别
- 速度:Spark 的运行速度通常比 MapReduce 更快。在处理相同的数据和实验环境下,如果在内存中运行,Spark 要比 MapReduce 快 100 倍;在磁盘中运行时,Spark 要比 MapReduce 快 10 倍1。这主要是因为 Spark 优化了数据处理过程,尤其是在进行迭代计算时,Spark 可以将数据保存在内存中,从而避免了频繁的磁盘 I/O 操作
- 数据处理范式:MapReduce 主要适用于批处理,而 Spark 不仅支持批处理,还支持实时数据处理和迭代分析4。Spark 的 DAG(有向无环图)计算模型使得它在处理迭代和低延迟问题时表现优秀
- 易用性:Spark 提供了更友好的编程接口,支持多种语言,如 Java、Scala、Python 和 R3。而 MapReduce 主要是用 Java 编写的,编程难度相对较大
- 容错性:Spark 的 RDD(弹性分布式数据集)具有高效的容错性。当某个环节出现问题时,只需按照数据的血缘关系追溯到相应的父 RDD 即可,而无需从头开始全流程计算。相比之下,MapReduce 的容错可能只能重新计算,成本较高
- 生态系统集成:Spark 拥有一个庞大的生态系统,包括 Spark SQL、Spark Streaming、MLlib 等组件,这些组件提供了丰富的数据处理和分析功能。而 MapReduce 的生态系统相对较小,这可能会限制其应用范围

5. 结构化数据与非结构化数据
- 结构化数据: 结构化数据是具有标准化格式的数据,可供软件和人类高效访问。它通常以表格形式呈现,其中行和列清楚地定义数据属性。 结构化数据对于所有数据值拥有相同的属性。例如,每个预订记录都可以拥有这些属性:预订名称、活动名称、活动日期和预订金额。 结构化数据表具有将不同数据集链接在一起的公共值。例如,可以使用 customer id 和 booking id 字段将客户数据与预订数据关联起来。 结构化数据有助于进行数学分析。例如,您可以计算和测量属性的频率,并对数值数据执行数学操作。 您可以在关系数据库中存储结构化数据,并使用结构化查询语言(SQL)对其进行管理。SQL 允许您定义一个称为 架构 的数据模型,并在该模型下为您的数据确定预设规则(如字段、格式和值)。
- 非结构化数据: 非结构化数据指未按照所设计的模型或结构进行组织的数据。非结构化数据通常被分类为定性数据,可由人类或机器生成。 非结构化数据是可供使用的数据量最大的一类数据,对其进行分析后,它可用来引导业务决策并在很多其他用例中实现业务目标。 非结构化数据通常以其原生格式进行存储。这进一步加大了将该数据转换为行之有效的见解的挑战。 尽管与结构化数据相比,使用非结构化数据更具有挑战性,但它通常包含结构化数据所不提供的丰富、详尽的信息。 非结构化数据的示例包括:文本文件、视频文件、报告、电子邮件、图像等。企业正在以指数级的速度创建数据,而绝大多数数据(80%-90%)是非结构化的。由于是定性数据,需要不同的技术和策略来进行有效分析。例如,您将非结构化数据存储在 NoSQL 数据库和数据湖中。
6. Linux简单操作命令实训练习
pwd 命令
ls命令

ls -a /命令

ls -l / 命令
cd /etc/sysconfig/network-scripts/命令到网洛配置文件夹下

mkdir 命令创建文件夹

rm -rf /xxxx/ 删除某个文件夹需要绝对路径

cp 命令复制某个文件到某处

mv 命令移动文件或者更改文件名
更改文件名

移动文件
cat 命令查看文件内容

tar 命令

useradd 命令创建新用户

passwd 命令

chown 命令
 chmod命令更改文件夹权限
chmod命令更改文件夹权限

su命令更换用名

本文转载自: https://blog.csdn.net/qq_62908982/article/details/136537003
版权归原作者 熊某某21 所有, 如有侵权,请联系我们删除。
版权归原作者 熊某某21 所有, 如有侵权,请联系我们删除。