
可视化时间序列数据是具有挑战性,尤其是涉及多个数据集时。精心设计的可视化不仅能清晰地传达信息,还能减少观察者的认知负荷,使其更容易提取有意义的洞察。
在本文中,我们将探讨使真实世界的疫苗接种数据来可视化单个时间序列和多个时间序列。
数据可视化中认知负荷的重要性
认知负荷指的是处理信息所需的心理努力量。在数据可视化的背景下,减少认知负荷意味着让观察者更容易理解数据。这对于时间序列数据尤为重要,因为需要快速准确地解释随时间变化的趋势、模式和关系。
可视化单个时间序列
我们首先探讨使用印度的数据来表示单个时间序列的各种方法。
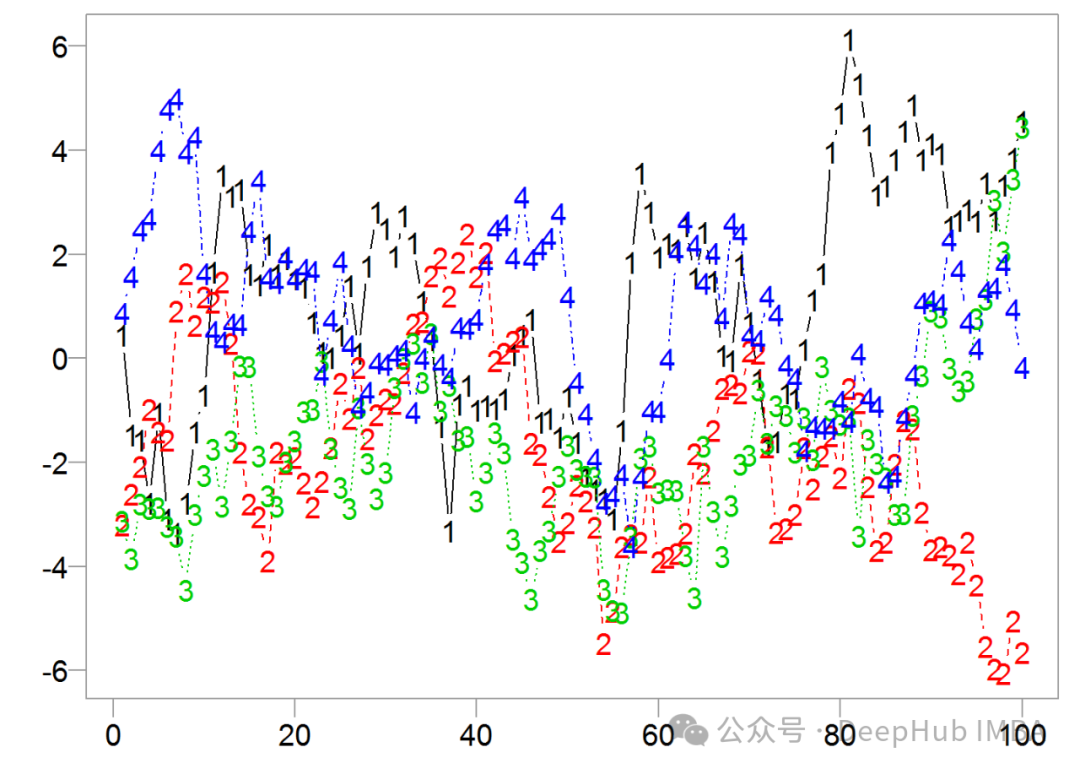
1、无连接线的散点图
无连接线的散点图是可视化时间序列数据的基本方法。但是它往往无法清晰地传达随时间变化的趋势。
import pandas as pd
# Load the COVID-19 vaccination dataset
url = 'https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/vaccinations/vaccinations.csv'
data = pd.read_csv(url)
# Convert the date column to datetime
data['date'] = pd.to_datetime(data['date'])
# Filter data for the years 2020, 2021, and 2022
data = data[(data['date'] >= '2020-01-01') & (data['date'] <='2021-12-31')]
# Filter data for India, USA, and Brazil
countries = ['India', 'United States', 'Brazil']
filtered_data = data[data['location'].isin(countries)]
# Select relevant columns
filtered_data = filtered_data[['location', 'date', 'daily_vaccinations']]
import matplotlib.pyplot as plt
# Filter data for India
india_data = filtered_data[filtered_data['location'] == 'India']
# Scatter plot without connecting lines
plt.figure(figsize=(15, 6))
plt.scatter(india_data['date'], india_data['daily_vaccinations'], color='blue', marker='.',s=2)
plt.title('India - Scatter Plot Without Connecting Lines')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.show()
重叠的数据点可能使辨别趋势变得困难。这种方法要求观察者在脑海中连接各个点,增加了认知负荷。
2、带连接线的散点图
用线条连接各个点可以提高趋势的清晰度,使跟随数据随时间的进展更加容易。
# Scatter plot with connecting lines
plt.figure(figsize=(15, 6))
plt.plot(india_data['date'], india_data['daily_vaccinations'], marker='+', color='blue', markersize=2)
plt.title('India - Scatter Plot with Connecting Lines')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.show()
线条有助于引导视线沿着时间线移动,减少了理解趋势所需的努力。重要的是要注意这些线条并不代表实际的数据点;它们只是作为视觉引导。
3、无点的线图
移除单个点并专注于线条,可以更加强调整体趋势并减少视觉杂乱。
# Line plot without dots
plt.figure(figsize=(15, 6))
plt.plot(india_data['date'], india_data['daily_vaccinations'], color='blue')
plt.title('India - Line Plot Without Dots')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.show()
这种风格通过纯粹关注趋势来简化视觉效果,使观察者更容易把握总体模式,而不会被单个数据点分散注意力。
4、填充区域的线图
填充曲线下的区域进一步强调了趋势的大小和方向。这种方法为数据增加了视觉权重,使增长或下降更加明显。
# Line plot with filled area
plt.figure(figsize=(10, 6))
plt.fill_between(india_data['date'], india_data['daily_vaccinations'], color='blue', alpha=0.3)
plt.plot(india_data['date'], india_data['daily_vaccinations'], color='blue')
plt.title('India - Line Plot with Filled Area')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.show()
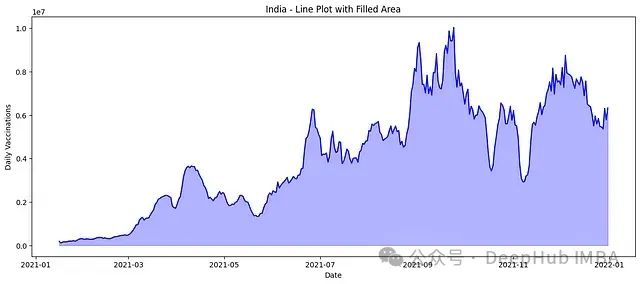
填充区域突出了随时间变化的数据量,强化了整体趋势。当你想要同时强调变化的方向和幅度时,这种风格特别有效。
可视化多个时间序列
在可视化多个时间序列时,目标是在保持清晰度的同时允许数据集之间的简单比较。以下是使用印度、美国和巴西数据的三种方法。
不好的设计:无连接线的散点图
我们为多个时间序列创建了一个无连接线的散点图。这是一个常见的错误,可能导致混乱和杂乱的可视化。
# Filter data for India, USA, and Brazil
countries = ['India', 'United States', 'Brazil']
filtered_data = data[data['location'].isin(countries)]
# Bad design: Scatter plot without connecting lines
plt.figure(figsize=(15, 6))
plt.scatter(filtered_data[filtered_data['location'] == 'India']['date'],
filtered_data[filtered_data['location'] == 'India']['daily_vaccinations'],
label='India', color='orange', s=2)
plt.scatter(filtered_data[filtered_data['location'] == 'United States']['date'],
filtered_data[filtered_data['location'] == 'United States']['daily_vaccinations'],
label='United States', color='blue', s=2)
plt.scatter(filtered_data[filtered_data['location'] == 'Brazil']['date'],
filtered_data[filtered_data['location'] == 'Brazil']['daily_vaccinations'],
label='Brazil', color='green', s=2)
plt.title('Bad Design - Scatter Plot Without Connecting Lines (2020-2022)')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.legend()
plt.show()
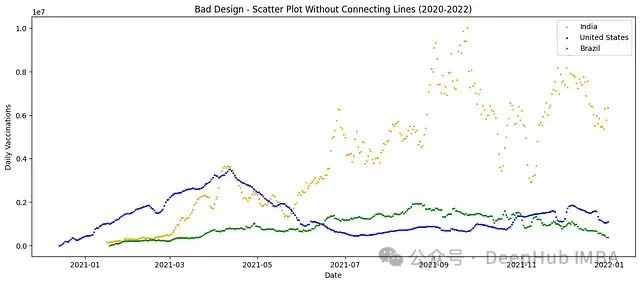
这种设计的问题:
- 数据点重叠: 散点图显示了各个序列的数据点,但由于没有连接线,很难跟踪每个序列的趋势。并且重叠的点创造了一个杂乱和混乱的视觉效果。
- 高认知负荷: 观察者必须在脑海中连接这些点以理解趋势,这需要额外的认知努力。这种设计增加了误解的可能性,使观察者难以快速掌握关键洞察。
更好的设计:连接线
我们通过用线条连接数据点来改进设计。这个简单的改变显著提高了图表的可读性。
# Better design: Line plot with connecting lines and reduced marker size for 2020, 2021, and 2022 data
plt.figure(figsize=(15, 6))
plt.plot(filtered_data[filtered_data['location'] == 'India']['date'],
filtered_data[filtered_data['location'] == 'India']['daily_vaccinations'],
label='India', color='orange', marker='.', markersize=2)
plt.plot(filtered_data[filtered_data['location'] == 'United States']['date'],
filtered_data[filtered_data['location'] == 'United States']['daily_vaccinations'],
label='United States', color='blue', marker='.', markersize=2)
plt.plot(filtered_data[filtered_data['location'] == 'Brazil']['date'],
filtered_data[filtered_data['location'] == 'Brazil']['daily_vaccinations'],
label='Brazil', color='green', marker='.', markersize=2)
plt.title('Better Design - Connected Lines (2020-2022)')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
plt.legend()
plt.show()
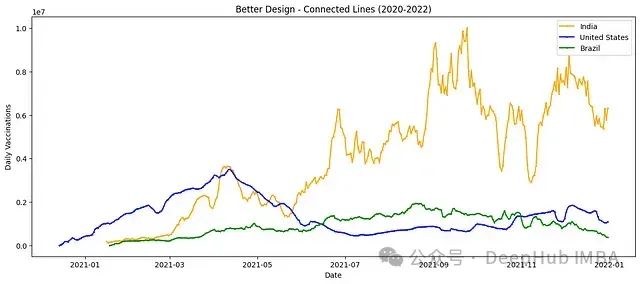
这种设计的改进:
- 连接线: 连接数据点的线条清晰地显示了随时间变化的趋势,减少了跟踪每个序列所需的心理努力。
- 更清晰的趋势: 观察者可以快速识别每个数据集的整体趋势,如峰值和低谷等。
- 减少认知负荷: 通过用线条连接数据点,图表减少了解释数据所需的认知负荷。观察者不再需要在脑海中连接这些点,因为线条已经完成了这项工作。
最佳设计:直接标注
最后我们通过在图表内直接标注趋势线来创建最佳设计。这种方法消除了对图例的需求,使图表更加直观易读。
# Best design: Direct labeling on lines with reduced marker size for 2020, 2021, and 2022 data
plt.figure(figsize=(15, 6))
plt.plot(filtered_data[filtered_data['location'] == 'India']['date'],
filtered_data[filtered_data['location'] == 'India']['daily_vaccinations'],
label='India', color='orange', marker='.', markersize=2)
plt.plot(filtered_data[filtered_data['location'] == 'United States']['date'],
filtered_data[filtered_data['location'] == 'United States']['daily_vaccinations'],
label='United States', color='blue', marker='.', markersize=2)
plt.plot(filtered_data[filtered_data['location'] == 'Brazil']['date'],
filtered_data[filtered_data['location'] == 'Brazil']['daily_vaccinations'],
label='Brazil', color='green', marker='.', markersize=2)
# Direct labeling at the end of the lines
plt.text(filtered_data[filtered_data['location'] == 'India']['date'].iloc[-1],
filtered_data[filtered_data['location'] == 'India']['daily_vaccinations'].dropna().values[-1],
' India', fontsize=12, color='orange', ha='left', va='center')
plt.text(filtered_data[filtered_data['location'] == 'United States']['date'].iloc[-1],
filtered_data[filtered_data['location'] == 'United States']['daily_vaccinations'].dropna().values[-1],
' United States', fontsize=12, color='blue', ha='left', va='center')
plt.text(filtered_data[filtered_data['location'] == 'Brazil']['date'].iloc[-1],
filtered_data[filtered_data['location'] == 'Brazil']['daily_vaccinations'].dropna().values[-1],
' Brazil', fontsize=12, color='green', ha='left', va='center')
plt.title('Best Design - Direct Labeling for 2020, 2021, and 2022 Data')
plt.xlabel('Date')
plt.ylabel('Daily Vaccinations')
# Remove the legend as we are using direct labeling
plt.legend().set_visible(False)
plt.show()
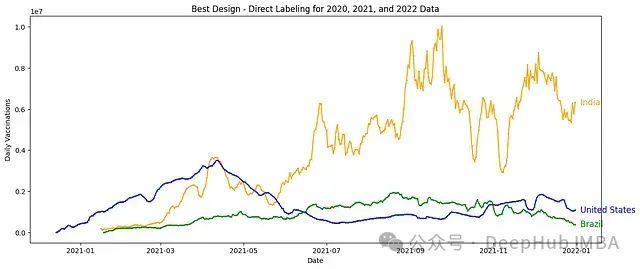
这种设计的主要优点:
- 直接标注: 标签直接放置在趋势线上,消除了对单独图例的需求。这减少了认知负荷并使图表更加直观。
- 简化设计:****移除图例使图表更加整洁,允许观察者完全专注于数据趋势。
- 增强可读性: 通过直接标注,观察者可以快速将每条趋势线与正确的数据集关联起来,使可视化更加高效和有效。
为什么减少认知负荷很重要
减少认知负荷对于创建有效的可视化至关重要,特别是对于时间序列数据。当观察者能够轻松理解数据,只需付出最少的努力时,他们更有可能:
- 快速理解趋势: 精心设计的可视化突出了趋势和模式,允许观察者快速把握关键信息。
- 避免错误: 清晰的视觉提示和最少的干扰有助于防止对数据的误解。
- 保持参与: 简单、直观的设计使观察者专注于数据,导致更好的记忆和更深入的洞察。
我们从**"不良"到"最佳"可视化的过程说明了在时间序列数据可视化中周到设计的重要性。通过用线条连接数据点并使用直接标注,可以显著减少认知负荷,使数据更容易获取,洞察更加明显。在设计可视化时,始终要追求清晰、简单,并关注观察者的体验。这种方法不仅增强了理解,还确保了数据得到有效传达,从而实现更好的决策和分析。**
作者:Ratan Kumar Sajja