
- Hadoop 的安装模式
- 基础环境准备
- 软件环境准备
- 安装单机模式的 Hadoop
- 安装单机伪分布式模式的 Hadood
一,Hadoop 的安装模式
- 单机模式
- 安装在一台服务器上
- 没有启动完整的功能
- 用于开发和调试 MapReduce 程序
- 分布式集群模式(企业生产环境)
- 安装在成千上万台服务器上
- 启动全部的功能
- 不同功能,分布在不同的服务器
- 单机伪分布式模式(学习环境)
- 安装在一台服务器上
- 启动全部功能
- 所有功能集中在一台服务器上
二,基础环境准备-选择操作系统
- Hadoop 使用 Linux 作为其开发和生产平台
- Linux 发行版选择
- CentOS 7:企业中使用最多的操作平台
- Ubuntu 18:官方推荐的操作平台
- CentOS 7 和 Ubuntu 18 的异同
- 不同地方:部分 Linux 系统命令不相同
- 相同地方:Hadoop 的操纵命令一模一样
- 此文章中以 Ubuntu 18 作为 Hadoop 的操作 基础环境准备-安装 VMware
- 下载 VMware的平台
- https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html 平台

- 建议取消启动时检查产品更新,创建在桌面和开始菜单创建快捷方式
- 安装完成后基础环境准备-部署 Ubuntu
- 下载 Ubuntu 18 镜像http://mirrors.aliyun.com/ubuntu-releases/18.04/ 基础环境准备-部署 Ubuntu
- 打开 VMware 点击【创建新的虚拟机】

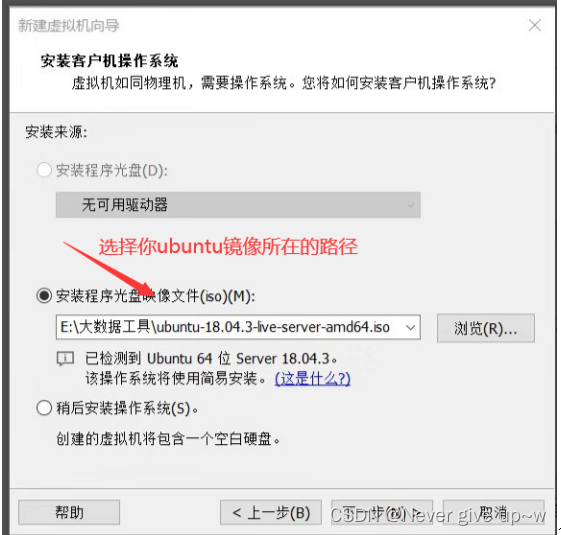
选择前边下载好的 Ubuntu 镜像
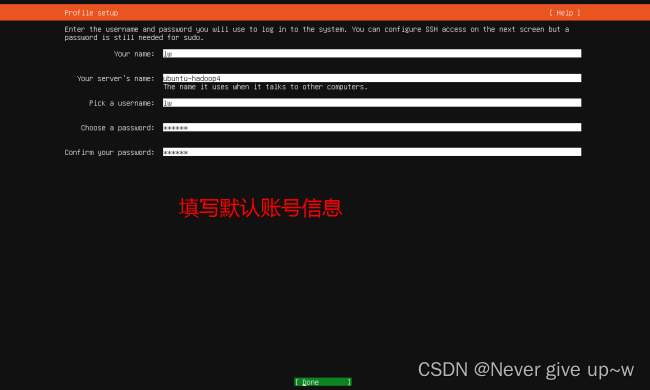
设置服务器名称和用户名
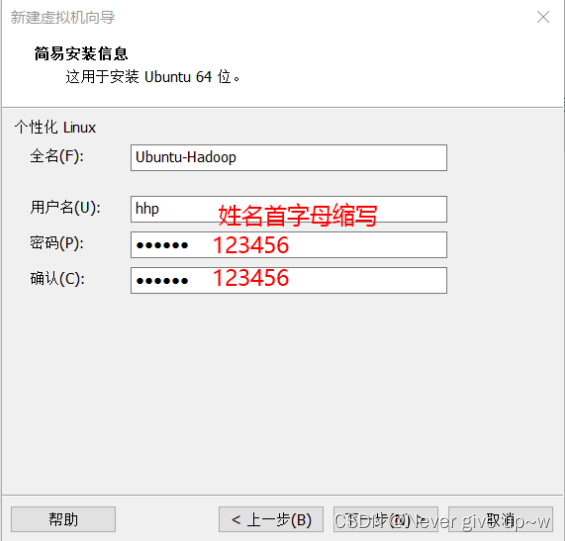
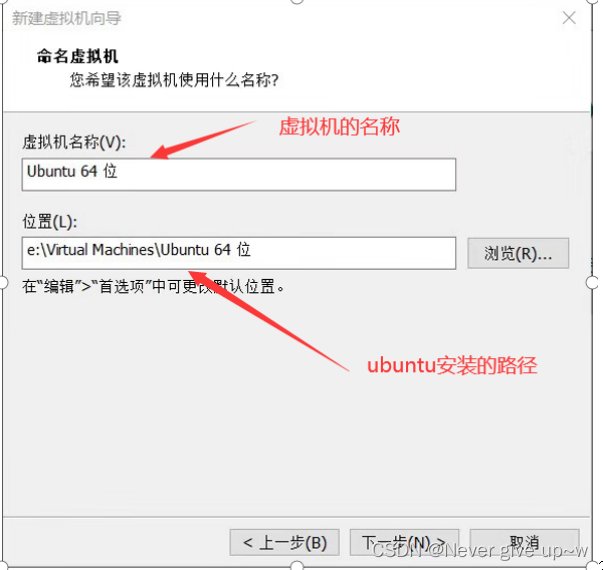
设置虚拟机名称和存储位置
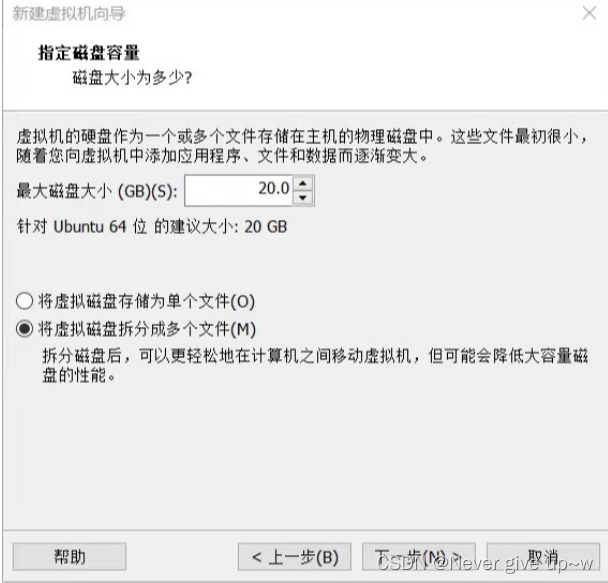
设置磁盘容量
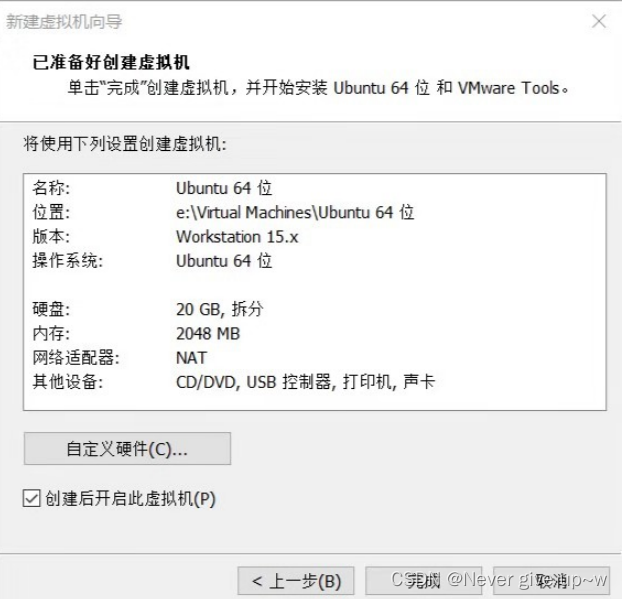
完成虚拟机创建,并自动启动虚拟机
选择 English 作为系统语言
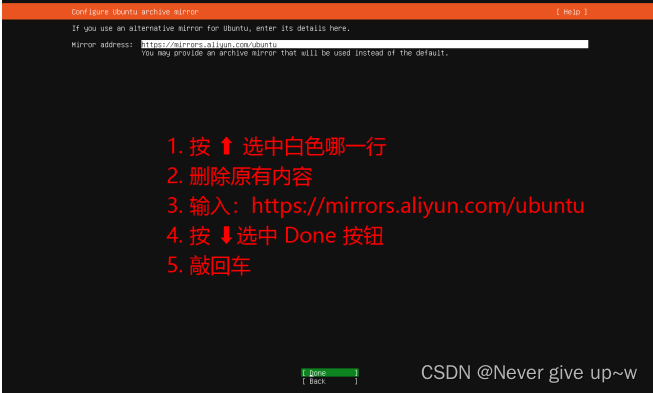
配置 Ubuntu 的镜像地址
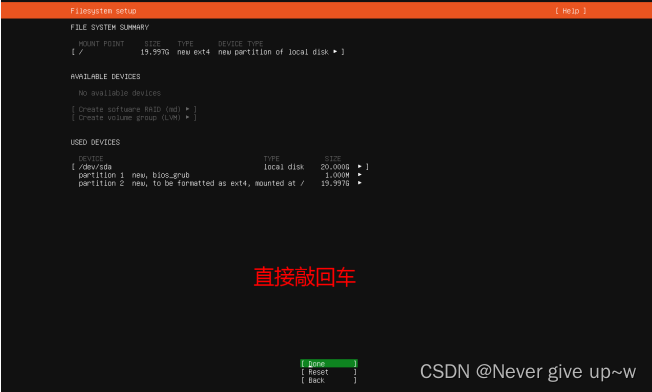
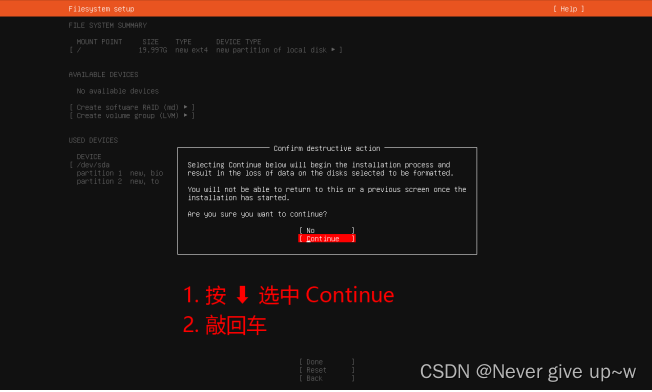
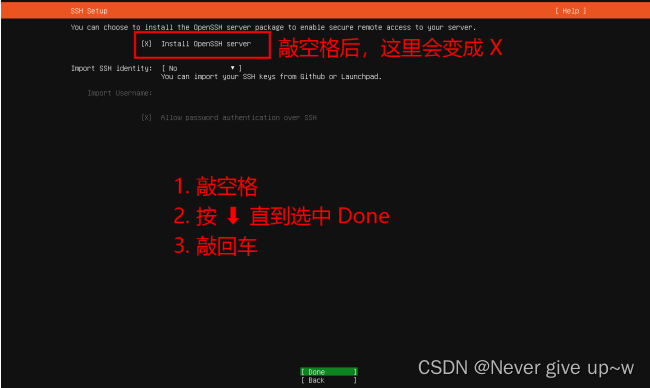

使用 ip a 命令查找 ip 地址,并记录下来
使用 xshell 登录 Ubuntu
使用 sudo vim /etc/netplan/50-cloud-init.yaml 命令
编辑 /etc/netplan/50-cloud-init.yaml 文件
配置静态 ip
按下 i 键进入编辑模式
修改文件内容如图片所示,addresses 为上一步记录的 ip
所有冒号后边需要添加一个空格
gateway 的前三位和 ip 保持一致,最后一位是 2
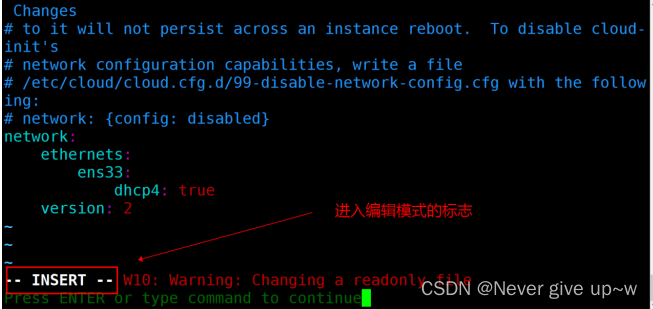
按下 ESC 键,退出编辑模式
按下 : 键,进入命令行模式
输入 wq 后敲回车,保存并退出文件
使用 sudo netplan apply 重启网络
使用 ping 检测是否配置成功

使用 sudo passwd root 为 root 用户设置密码
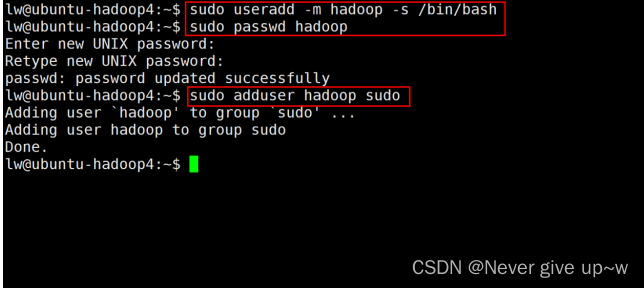
使用 sudo useradd -m hadoop -s /bin/bash 命令
创建 hadoop 用户
使用 sudo passwd hadoop 命令
为 hadoop 用户设置密码
使用 sudo adduser hadoop sudo 为 hadoop 命令
为 hadoop 用户添加管理员权限
使用 su hadoop 命令
切换到 hadoop 用户
使用 cd ~ 命令
进入 /home/hadoop 目录
后续软件安装都需要使用 hadoop 用户
在 /home/hadoop 目录进行操作
使用 sudo apt-get install lrzsz 命令安装 lrzsz 软件
安装 lrzsz 软件后可以实现拖拽上传文件
拖拽文件到到 xshell 窗口即可自动上传到 Linux
从网络获取他人共享的 Oracle 账号密码
下载 jdk https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
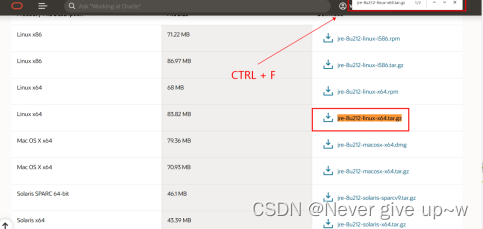
三,软件环境准备-安装 jdk
拖拽下载的 jdk 到 xshell 进行上传
使用 sudo tar -xvf jdk-8u212-linux-x64.tar.gz -C /usr/local/lib/ 命令
解压 jdk 到 /usr/local/lib 目录
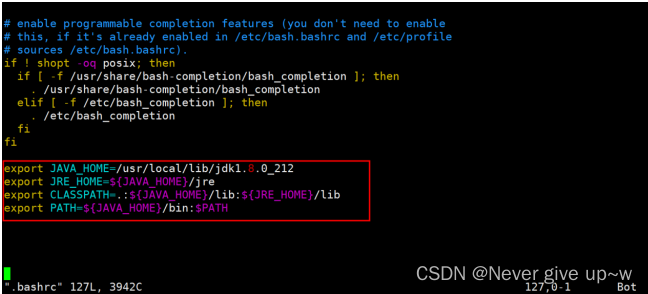
使用 vim .bashrc 命令
编辑环境变量
在文件最后追加以下内容:
export JAVA_HOME=/usr/local/lib/jdk1.8.0_212
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
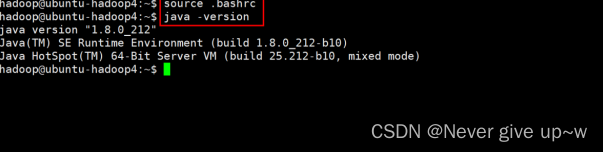
使用 source .bashrc 命令
刷新环境变量使用 java -version 命令
验证 jdk 是否配置成功
看到版本号说明配置成功,否则说明配置有误
软件环境准备-配置 ssh 免密登录
- Hadoop 各个节点之间需要频繁进行远程登录操作
- 需要配置 ssh 消除远程登录时输入密码的操作
- 使用 ssh-keygen 命令
- 在 /home/hadoop/.ssh 目录下生成公钥和私钥
- 所有选项全部敲回车
- 使用 ssh-copy-id localhost 命令
- 发送本机的公钥给 localhost
- 本机就可以免密登录 localhost
- 使用 ssh localhost 命令
- 远程登录 localhost
- 第一次执行可能需要输入 yes 和密码
- 后续再执行就不需要输入任何内容
- 使用 exit 命令
- 退出远程登录
- ssh 免密登录的关键在于公钥和私钥
- id_rsa.pub 是公钥
- Id_rsa 是私钥
- 公钥加密,私钥解;私钥加密,公钥解;
- 谁持有你的公钥,你就可以免密登录谁

四,安装单机 Hadoop-下载 Hadoop
- 从 Hadoop 官网下载 Hadoop
- https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
- 程序文件是:hadoop-2.7.7.tar.gz
- 拖拽下载的 hadoop 到 xshell 进行上传
- 使用 sudo tar -xvf hadoop-2.7.7.tar.gz -C /usr/local/ 命令
- 解压 hadoop 到 /usr/local 目录
- 使用 cd /usr/local 命令
- 进入 /usr/local 目录
- 使用 sudo mv hadoop-2.7.7 hadoop 命令
- 重命名 hadoop-2.7.7 目录为 hadoop
- 使用 sudo chown -R hadoop hadoop 命令
- 使用 cd hadoop 命令
- 进入 hadoop 目录
- 使用 mkdir input 命令
- 创建 input 目录
- 使用 cp etc/hadoop/*.xml input 命令
- 复制 etc/hadoop 目录下的 xml 文件到 input 目录
- 使用 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output ‘dfs[a-z]+’命令
- 执行 mapreduce 程序
- 从 input 中找出以 dfs 开头的字符串
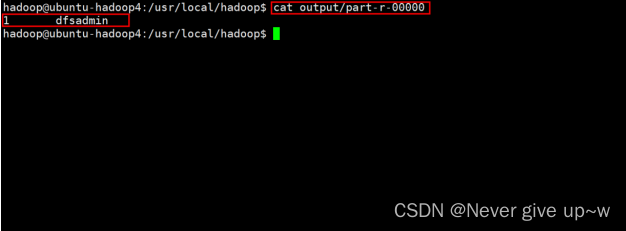
- 使用 cat output/part-r-00000 命令
- 查看 mapreduce 执行结果
- 如果需要再次执行 mapreduce 程序,请先使用 rm -rf output 命令删除 ouput 目录 ###
五,安装单机伪分布式 Hadoop
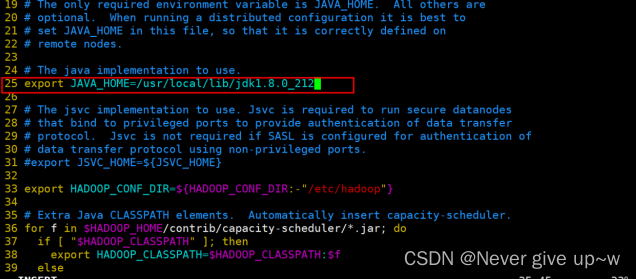
- 使用 sudo vim etc/hadoop/hadoop-env.sh 命令
- 修改文件 hadoop-env.sh 文件
- 修改第 25 行为:
- export JAVA_HOME=/usr/local/lib/jdk1.8.0_212
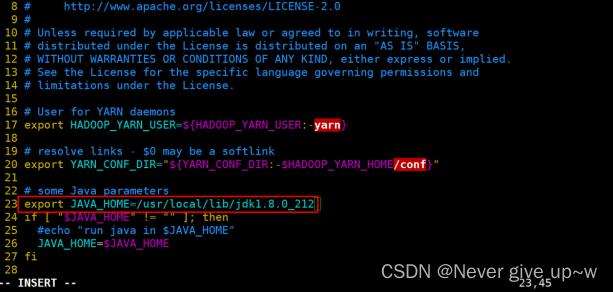
- 使用 sudo vim etc/hadoop/yarn-env.sh 命令
- 修改文件 yarn-env.sh 文件
- 修改第 23 行为:
- export JAVA_HOME=/usr/local/lib/jdk1.8.0_212
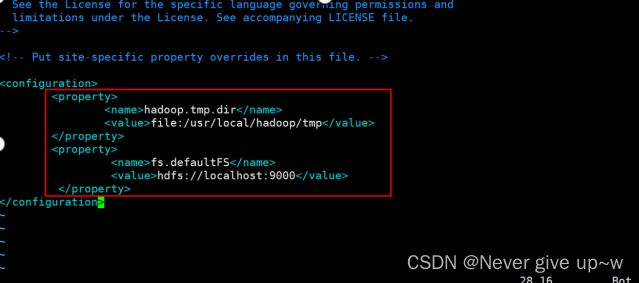
- 使用 sudo vim etc/hadoop/core-site.xml 命令
- 修改文件 core-site.xml 文件
- core-site.xml
- <configuration>
<property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>- </configuration>
使用 sudo vim etc/hadoop/hdfs-site.xml 命令
修改文件 hdfs-site.sh 文件
- hdfs-site.xml
- <configuration>
<property><name>dfs.replication</name><value>1</value>- </property>
- <property>
<name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value>- </property>
<property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>- </configuration>
- 使用 sudo vim etc/hadoop/yarn-site.xml 命令
- 修改文件 yarn-site.sh 文件
- yarn-site.xml
- <configuration>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>- </configuration>
- 使用 mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml 命令
- 重命名 mapred-site.xml.template 文件为 mapred-site.xml
- 使用 sudo vim etc/hadoop/mapred-site.xml 命令
- 修改文件 mapred-site.sh 文件
- mapred-site.xml
- <configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value></property>- </configuration>
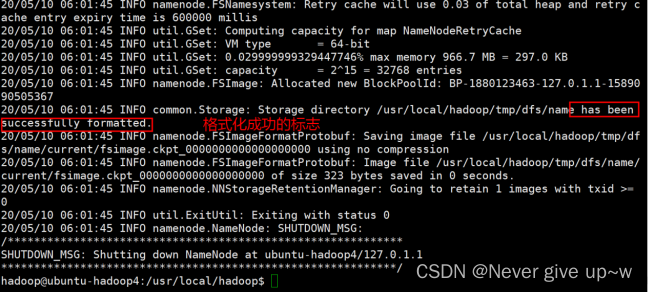
- 使用 bin/hdfs namenode -format 命令
- 格式化 hdfs
- 使用 sbin/start-all.sh 命令
- 启动 hdfs 和 yarn
- 第一次启动可能需要输入 yes
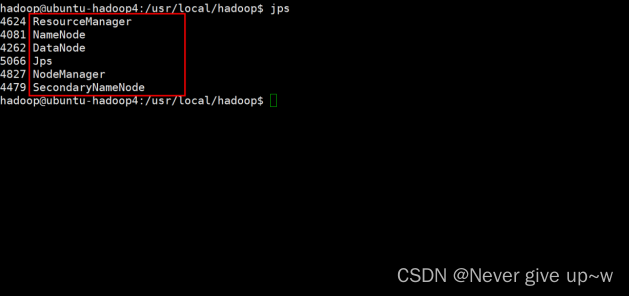
- 使用 jps 命令
- 查看进程
安装单机伪分布式 Hadoop
- 使用 http://[ubuntu的ip]:50070 地址访问 hdfs 的监控页面
- 使用 http://[ubuntu的ip]:8088 地址
- 访问 yarn 的监控页面
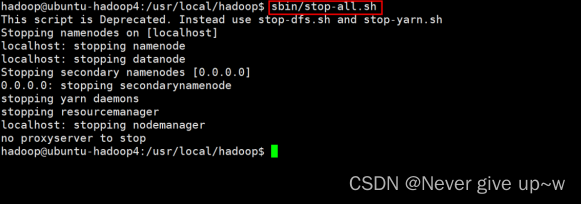
- 使用 sbin/stop-all.sh 命令
- 关闭 hdfs 和 yarn
版权归原作者 Never give up~w 所有, 如有侵权,请联系我们删除。