

C# 是一种广泛应用于企业级项目和应用程序的多功能编程语言。它源自 C 系列语言,具有高效和强大的特点,使其成为任何开发人员工具包中不可或缺的一部分。
由于其广泛的应用,C# 提供了大量的工具,使开发人员能够解决复杂的解决方案,网络爬虫也不例外。
在本教程中,我们将带您一步步创建一个简单的网络爬虫,使用 C# 及其用户友好的爬虫库。此外,我们还将揭示一个巧妙的技巧,只需一行代码即可帮助您避免被封锁。准备好了吗?我们开始吧!
以下是文章的目录:
目录
- 网络爬虫简介 - 为什么选择 C# 而不是 C 进行网络爬虫?
- 设置您的环境 - 前提条件- 安装库- 在 Visual Studio 中创建一个 C# 网络爬虫项目
- 使用 C# 进行基本的网络爬虫 - 发出 HTTP 请求- 解析 HTML 内容- 高级 HTML 解析
- 如何处理爬取的数据
- 在网络爬虫中处理 CAPTCHA - 集成 CAPTCHA 解决方案- CapSolver 示例代码
- 结论
1. 网络爬虫简介
网络爬虫是自动从网站提取信息的过程。这可以用于各种目的,包括数据分析、市场研究和竞争情报。然而,许多网站实现了检测和阻止自动爬虫尝试的机制,因此使用复杂的技术来避免被封锁是至关重要的。
为什么选择 C# 而不是 C 进行网络爬虫?
网络爬虫通常涉及与网页元素交互、管理 HTTP 请求以及处理数据提取和解析。虽然 C 是一种强大且高效的语言,但它缺乏使网络爬虫更容易和高效的内置库和现代功能。以下是 C# 更适合网络爬虫的一些原因:
- 丰富的库:C# 拥有丰富的库,如 HtmlAgilityPack 用于 HTML 解析,Selenium 用于浏览器自动化,这些都简化了爬虫过程。
- 异步编程:C# 的 async 和 await 关键字允许进行高效的异步操作,这对于同时处理多个网络请求至关重要。
- 易用性:C# 的语法比 C 更现代和用户友好,使开发过程更快且错误更少。
- 集成:C# 无缝集成到 .NET 框架中,提供了强大的工具和服务,用于构建强大的应用程序。
是否因为反复无法完全解决恼人的验证码而感到困扰?
通过 Capsolver AI 驱动的自动网络解封技术,体验无缝自动验证码解决方案!
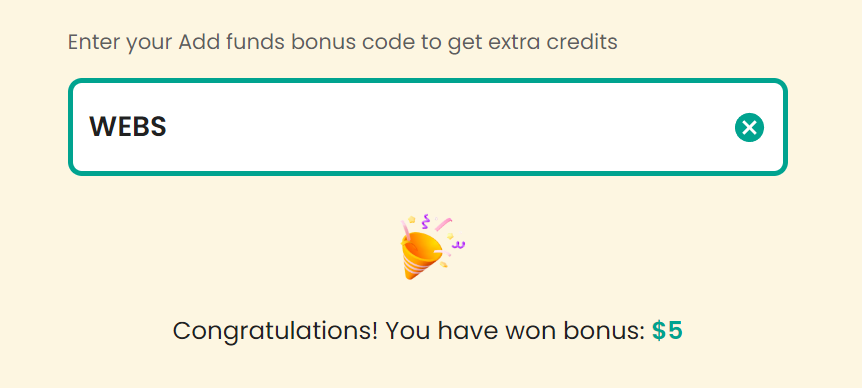
领取您的 优惠码,获取最佳验证码解决方案;CapSolver:WEBS。兑换后,您每次充值将获得额外 5% 的奖励,无限制。
2. 设置您的环境
在我们开始爬取之前,我们需要设置开发环境。以下是设置方法:
前提条件
- Visual Studio:免费的 Visual Studio 2022 Community 版即可。
- .NET 6+:任何大于或等于 6 的 LTS 版本都可以。
HtmlAgilityPack库用于 HTML 解析RestSharp库用于发出 HTTP 请求
在 Visual Studio 中创建一个 C# 网络爬虫项目
在 Visual Studio 中设置项目
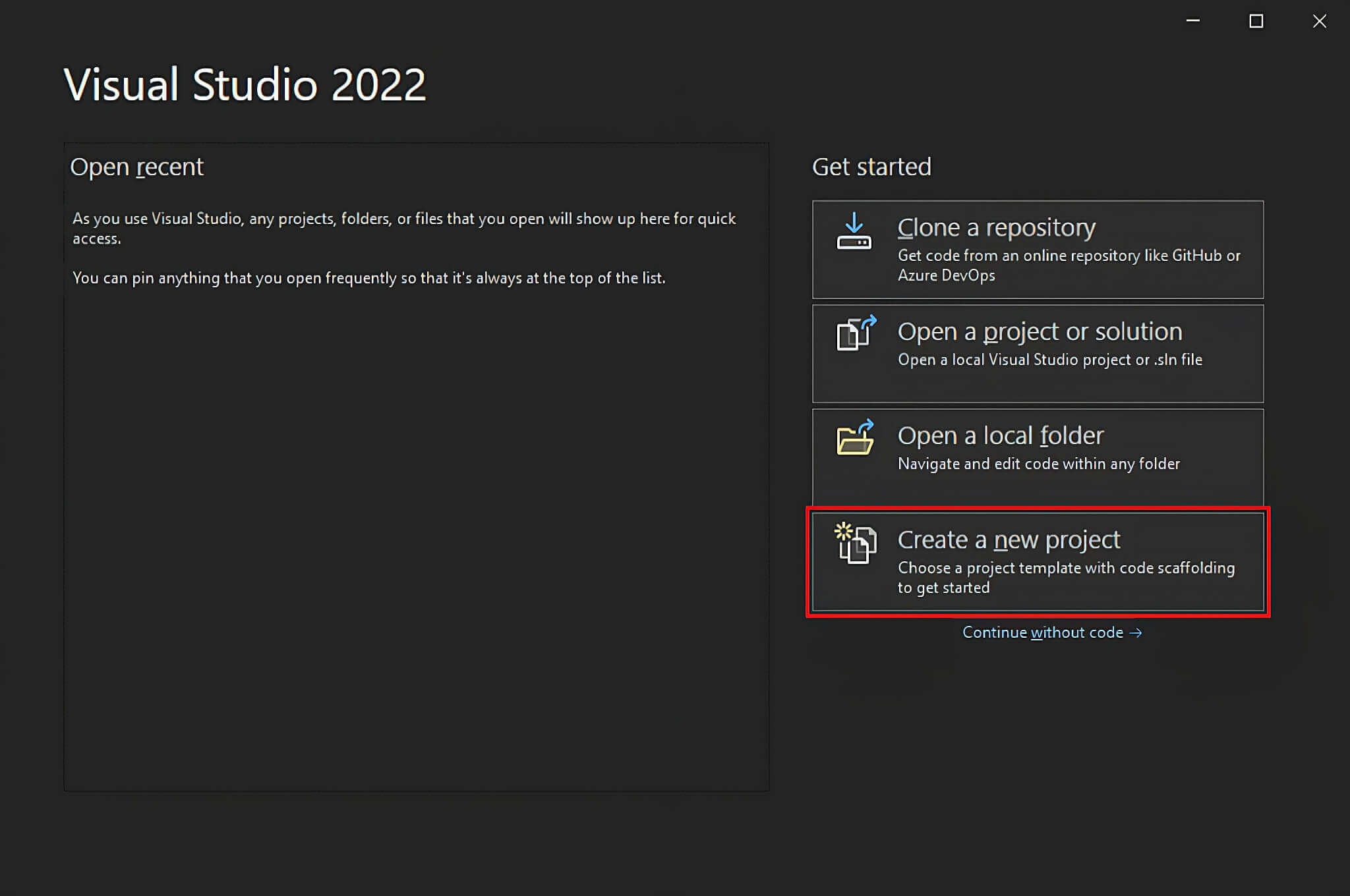
- 打开 Visual Studio,点击“创建新项目”选项。
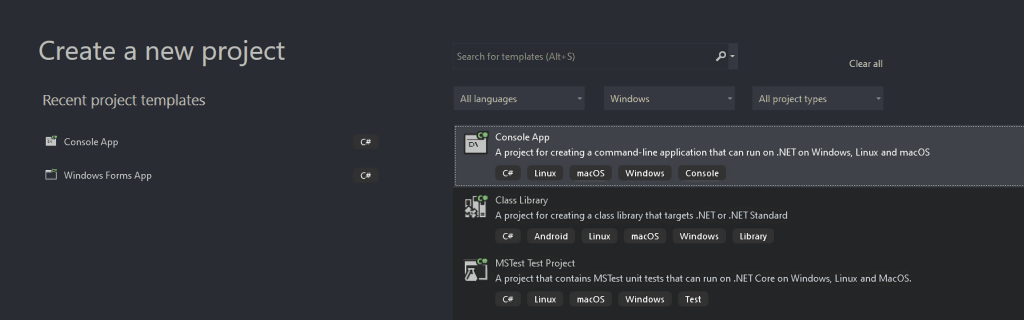
- 在“创建新项目”窗口中,从下拉列表中选择“C#”选项。指定编程语言后,选择“控制台应用程序”模板,然后点击“下一步”。
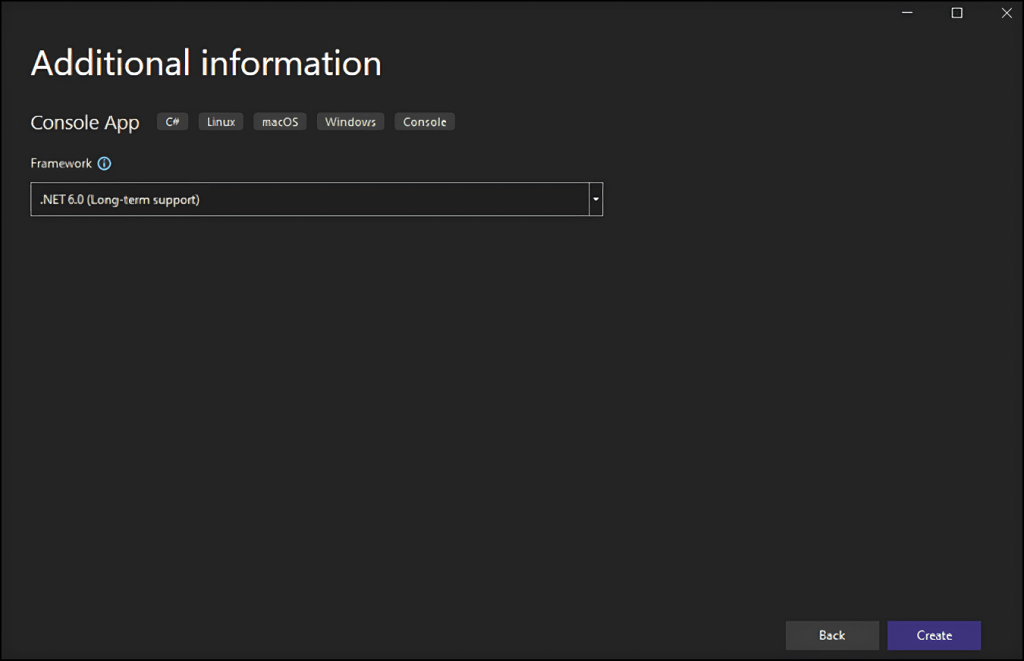
- 将您的项目命名为
StaticWebScraping,点击“选择”,并选择 .NET 版本。如果您已安装 .NET 6.0,Visual Studio 应该已经为您选择好了。
- 点击“创建”按钮初始化您的 C# 网络爬虫项目。Visual Studio 将初始化一个包含
App.cs文件的StaticWebScraping文件夹。这个文件将存储您的 C# 网络爬虫逻辑:
namespaceWebScraping{publicclassProgram{publicstaticvoidMain(){// 爬虫逻辑...}}}
现在是时候了解如何在 C# 中构建一个网络爬虫了!
3. 使用 C# 进行基本的网络爬虫
在本节中,我们将创建一个 C# 应用程序,该应用程序向网站发出 HTTP 请求,获取 HTML 内容,并解析它以提取信息。
发出 HTTP 请求
首先,让我们创建一个基本的 C# 应用程序,该应用程序向网站发出 HTTP 请求并获取 HTML 内容。
usingSystem;usingRestSharp;classProgram{staticvoidMain(){// 创建一个新的 RestClient 实例,目标 URLvar client =newRestClient("https://www.example.com");// 创建一个新的 RestRequest 实例,使用 GET 方法var request =newRestRequest(Method.GET);// 执行请求并获取响应IRestResponse response = client.Execute(request);// 检查请求是否成功if(response.IsSuccessful){// 打印响应的 HTML 内容
Console.WriteLine(response.Content);}else{
Console.WriteLine("获取内容失败");}}}
解析 HTML 内容
接下来,我们将使用
HtmlAgilityPack
解析 HTML 内容并提取我们需要的信息。
usingHtmlAgilityPack;usingSystem;usingRestSharp;classProgram{staticvoidMain(){// 创建一个新的 RestClient 实例,目标 URLvar client =newRestClient("https://www.example.com");// 创建一个新的 RestRequest 实例,使用 GET 方法var request =newRestRequest(Method.GET);// 执行请求并获取响应IRestResponse response = client.Execute(request);// 检查请求是否成功if(response.IsSuccessful){// 将 HTML 内容加载到 HtmlDocument 中var htmlDoc =newHtmlDocument();
htmlDoc.LoadHtml(response.Content);// 选择匹配指定 XPath 查询的节点var nodes = htmlDoc.DocumentNode.SelectNodes("//h1");// 遍历选定的节点并打印它们的内文本foreach(var node in nodes){
Console.WriteLine(node.InnerText);}}else{
Console.WriteLine("获取内容失败");}}}
高级 HTML 解析
让我们更进一步,从一个示例网站抓取更复杂的数据。假设我们想从一个博客页面抓取文章列表,包括标题和链接。
usingHtmlAgilityPack;usingSystem;usingRestSharp;classProgram{staticvoidMain(){// 创建一个新的 RestClient 实例,目标 URLvar client =newRestClient("https://www.example.com/blog");// 创建一个新的 RestRequest 实例,使用 GET 方法var request =newRestRequest(Method.GET);// 执行请求并获取响应IRestResponse response = client.Execute(request);// 检查请求是否成功if(response.IsSuccessful){// 将 HTML 内容加载到 HtmlDocument 中var htmlDoc =newHtmlDocument();
htmlDoc.LoadHtml(response.Content);// 选择匹配指定 XPath 查询的节点var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='post']");// 遍历选定的节点并提取标题和链接foreach(var node in nodes)```csharp
{// 遍历选定的节点并提取标题和链接foreach(var node in nodes){var titleNode = node.SelectSingleNode(".//h2/a");var title = titleNode.InnerText;var link = titleNode.Attributes["href"].Value;
Console.WriteLine("标题: "+ title);
Console.WriteLine("链接: "+ link);
Console.WriteLine();}}else{
Console.WriteLine("获取内容失败");}}}
在这个示例中,我们抓取了一个博客页面,选择每篇文章的标题和链接。XPath 查询
//div[@class='post']
用于定位单独的帖子。
4. 如何处理爬取的数据
- 将其存储在数据库中,以便随时查询。
- 将其转换为 JSON 格式,并用它调用各种 API。
- 将其转换为人类可读的格式,如 CSV,可以用 Excel 打开。
这些只是一些示例。关键点是,一旦您在代码中获取了爬取的数据,您可以根据需要使用它。通常,爬取的数据会被转换为更有用的格式,以便您的市场、数据分析或销售团队使用。
然而,请记住,网络爬虫也有其挑战。
5. 在网络爬虫中处理 CAPTCHA
网络爬虫面临的最大挑战之一是处理 CAPTCHA,它们旨在区分人类用户和机器人。如果您遇到 CAPTCHA,您的爬虫脚本需要解决它才能继续。特别是如果您想扩大您的网络爬虫规模,CapSolver 可以通过其高准确率和快速解决的能力帮助您解决任何遇到的 CAPTCHA。
集成 CAPTCHA 解决方案
有几种 CAPTCHA 解决服务可以集成到您的爬虫脚本中。这里,我们将使用 CapSolver 服务。首先,您需要注册 CapSolver 并获取您的 API 密钥。
步骤 1:注册 CapSolver
在您准备好使用 CapSolver 的服务之前,您需要前往用户面板并注册您的账户。
步骤 2:获取您的 API 密钥
注册后,您可以从主页面板获取您的 API 密钥。

CapSolver 示例代码
在您的网络爬虫或自动化项目中使用 CapSolver 非常简单。以下是一个 Python 示例,演示如何将 CapSolver 集成到您的工作流程中:
# pip install requestsimport requests
import time
# TODO: 设置您的配置
api_key ="YOUR_API_KEY"# 您的 CapSolver API 密钥
site_key ="6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"# 目标网站的站点密钥
site_url =""# 目标网站的页面 URLdefcapsolver():
payload ={"clientKey": api_key,"task":{"type":'ReCaptchaV2TaskProxyLess',"websiteKey": site_key,"websiteURL": site_url
}}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")ifnot task_id:print("创建任务失败:", res.text)returnprint(f"获取任务 ID: {task_id} / 获取结果中...")whileTrue:
time.sleep(3)# 延迟
payload ={"clientKey": api_key,"taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")if status =="ready":return resp.get("solution",{}).get('gRecaptchaResponse')if status =="failed"or resp.get("errorId"):print("解决失败!响应:", res.text)return
token = capsolver()print(token)
在这个示例中,
capsolver
函数向 CapSolver 的 API 发送请求,包含必要的参数,并返回 CAPTCHA 解决方案。这个简单的集成可以在网络爬虫和自动化任务中节省无数的时间和精力。
6. 结论
使用 C# 进行网络爬虫使开发人员能够高效地自动从网站提取数据。通过利用 HtmlAgilityPack 和 RestSharp 等库,以及 CAPTCHA 解决服务如 CapSolver,开发人员可以顺利地浏览网页、解析 HTML 内容,并处理各种挑战。这种能力不仅简化了数据收集过程,还确保了遵守道德爬虫实践,提高了网络爬虫项目在各种应用中的可靠性和可扩展性。
版权归原作者 ForRunner123 所有, 如有侵权,请联系我们删除。