
启动和关闭hadoop服务
一键启动/停止
start-hdf.sh
stop-hdf.sh
单进程关闭启动
hdfs --daemon stop/start/status namenode
或者
hadoop--daemon stop/start/status namenode
hadoop 中创建文件夹
# 创建文件夹
hadoop fs -mkdir -p /it/text
# 列出文件结构
hadoop fs -ls [-h][-R][<path>...]-h 显示文件size
-R 列出根目录下面的子目录
# 上传文件到hadoop下面
hadoop fs -put [-f][-p] <localsrc>....<dst>
hadoop fs -D dfs.replication=2 -put [-f][-p] <localsrc>....<dst># 以两个备份副本上传,默认三个
hadoop fs -setrep 1 <dst># 把这个路径的副本设置成1个-f 覆盖目标文件
-p 保留访问修改时间,所有权和权限
localsrc linux下的目录
dst hadoop下的目录
# hadoop fs -put file:///home/text hdfs:///node1:9001 # 不带协议头hadoop也可以自动识别# 查看文件
hadoop fs -cat <src>.... |more #以分页的方式查看文件# 下载hadoop的文件
hadoop fs -get [-f][-p] <dst>....<localsrc>-f 覆盖目标文件
-p 保留访问修改时间,所有权和权限
localsrc linux下的目录
dst hadoop下的目录
# 复制文件,在hadoop内部
hadoop fs -cp [-f] <dst> <dst>
hadoop fs -mv <dst> <dst>#追加文件,hadoop只能追加或者删除文件
hadoop fs -appendToFile <localsrc>....<dst># 删除文件
hadoop fs -rm -r [-skipTrash] URI
-skipTrash 跳过回收站,直接删除(回收站默认开启)
可通过配置core-site.yml开启 # 保留时间和 检查间隔
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]-file 列出文件状态
-file -blocks 输出文件块报告
-file -blocks -locations 输出每一个block的详情
namenode元数据管理维护
namenode是基于edits和FSImage的配合,来完成整个文件系统的管理
1.每次对HDFS操作都会被edits记录,edits达到上限后,开启新的edits进行记录
2.定期对edits进行合并,如果没有fsiamge,则合并所有的edits,如果有fsimage,则把fsimage和所有的edits进行合并形成新的fsimage.
3.一直重复1,2
# 对元数据的合并,是一个定时过程
dfs.namenode.checkpoint.period 默认3600秒
dfs.namenode.checkpoint.txns 默认100w此事务
dfs.namenode.checkpoint.check.period 默认60秒检查一次
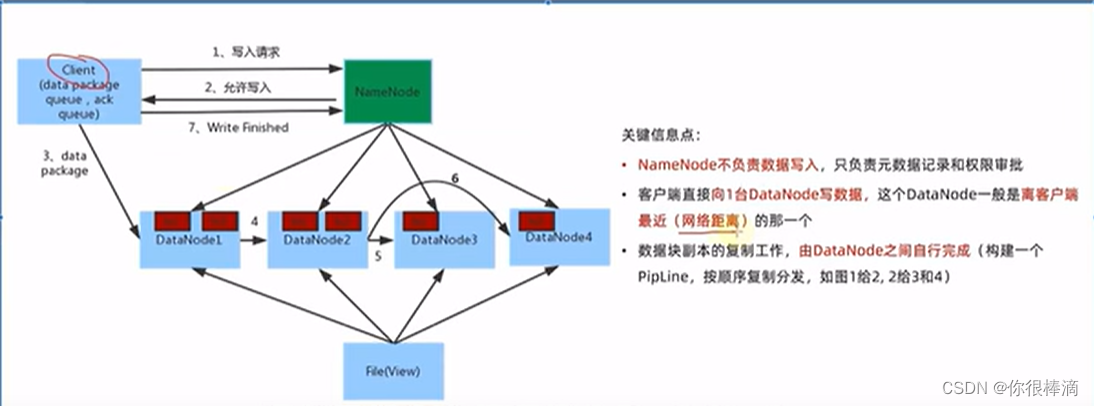
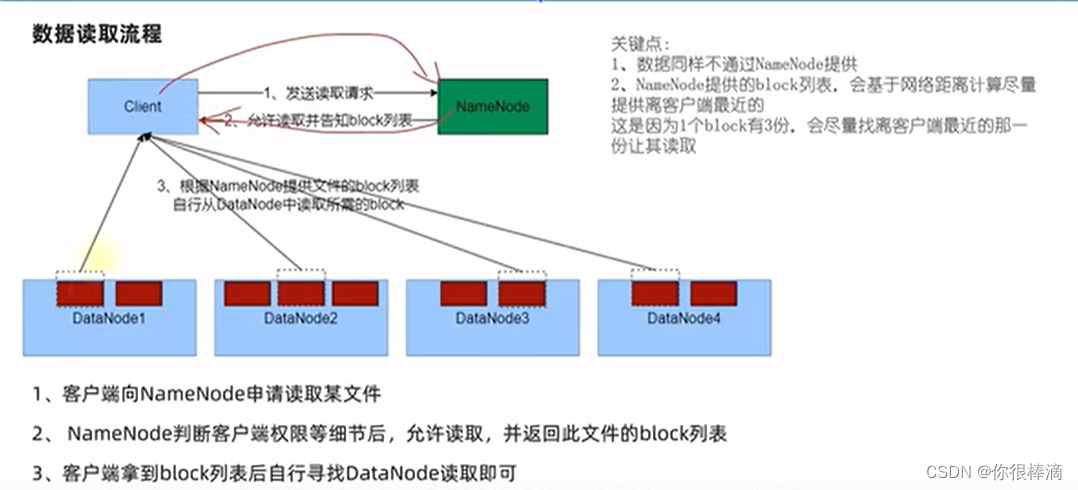
hadoop数据写入/写入流程

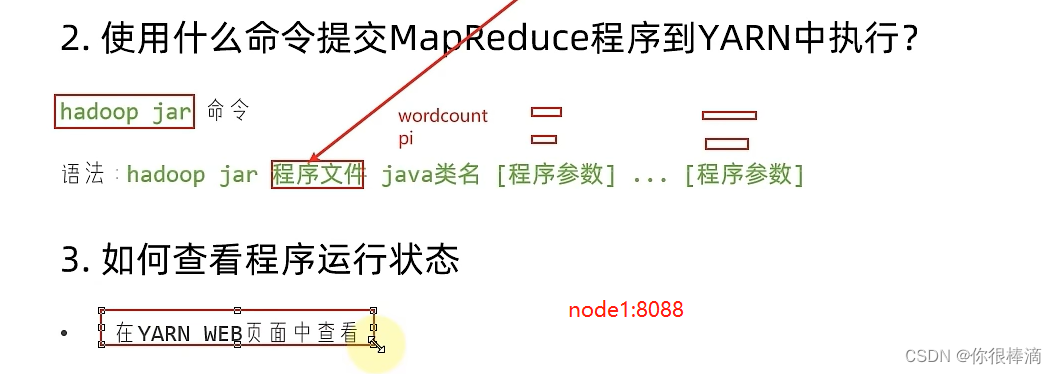
用自带的jar包执行meqreduce
# 如果报错 YARN : root is not a leaf queue 需要在wordcount后面加 -Dmapreduce.job.queuename="root.default"
hadoop jar ./hadoop-mapreduce-examples-3.3.5.jar wordcount -Dmapreduce.job.queuename="root.default" hdfs://node1:9001/input/ hdfs://node1:9001/output/wc
hadoop jar ./hadoop-mapreduce-examples-3.3.5.jar pi -Dmapreduce.job.queuename="root.default" 3 1000
本文转载自: https://blog.csdn.net/RayMand168/article/details/130966975
版权归原作者 你很棒滴 所有, 如有侵权,请联系我们删除。
版权归原作者 你很棒滴 所有, 如有侵权,请联系我们删除。