
一、selenium简介
Selenium是一个用于自动化测试的工具,它可以模拟用户在浏览器中的各种操作。除了用于爬虫,Selenium还可以用于测试,尤其是在处理动态加载页面时非常有用。本文将提供一个超级详细的Selenium教程,以帮助您快速入门并了解其各种功能和用法。
二、环境安装
2.1、安装Selenium
** 在终端通过pip安装:**
1|pip install selenium
2.2、浏览器驱动安装
针对不同的浏览器,安装不同的驱动:(本文以Edge浏览器为例)
2.2.1、查看浏览器的版本


2.2.2、下载对应版本的驱动程序
下载网址链接:Microsoft Edge WebDriver |Microsoft Edge 开发人员

2.2.3、解压获取exe文件地址

三、基本操作
3.1、对页面进行操作
3.1.1、初始化webdriver
在使用Selenium之前,我们需要初始化WebDriver。WebDriver是一个控制浏览器的工具,它可以模拟用户在浏览器中的各种操作。Selenium支持多种浏览器,如Chrome、Firefox、Safari等。下面是一些示例代码,展示如何初始化Edge、Chrome和Firefox浏览器的WebDriver:
from selenium import webdriver
# 初始化Edge浏览器
driver = webdriver.Edge()
# 初始化Chrome浏览器
driver = webdriver.Chrome()
# 初始化Firefox浏览器
driver = webdriver.Firefox()
3.1.2、打开网页
一旦我们初始化好了WebDriver,接下来我们就可以使用它来打开网页。下面是一些示例代码,展示如何使用WebDriver打开网页:
from selenium import webdriver
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
driver.get("https://www.jd.com/")
3.1.3、页面操作
一旦我们打开了网页,我们就可以使用WebDriver来模拟各种用户操作,如设置窗口最大化、设置窗口位置、设置窗口大小等。下面是一些示例代码,展示如何在网页中进行一些常见的操作:
import time
from selenium import webdriver
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置浏览器的窗口位置
driver.set_window_position(1100, 20)
# 设置浏览器的窗口大小
driver.set_window_size(900, 900)
time.sleep(5)
3.1.4、页面数据提取
除了操作页面,Selenium还可以用于提取页面的源代码。我们可以使用WebDriver的page_source来获取页面源代码,下面是示例代码,展示如何提取页面中的数据:
import time
from selenium import webdriver
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置浏览器的窗口位置
driver.set_window_position(1100, 20)
# 设置浏览器的窗口大小
driver.set_window_size(900, 900)
time.sleep(5)
# 获取页面源代码
page_content = driver.page_source
# 打印获取内容
print(page_content)
3.1.5、关闭页面
当我们完成了对网页的操作和数据提取后,最后不要忘记关闭WebDriver。关闭WebDriver将会关闭浏览器窗口,并释放相关的资源。下面是示例代码,展示如何关闭WebDriver:
import time
from selenium import webdriver
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
time.sleep(2)
# 获取页面数据
page_content = driver.page_source
# 打印页面数据内容
print(page_content)
# 关闭一个页面
driver.close()
# 关闭全部页面
driver.quit()
3.1.6、综合小案例
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :Selenium爬虫
@Time :2024/12/5 11:19
@Motto:一直努力,一直奋进,保持平常心
"""
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
url = "https://www.baidu.com/"
url1 = "https://www.jd.com/"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service,options=opt)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
# 设置浏览器的窗口位置
# browser.set_window_position(1100, 20)
# 设置浏览器的窗口大小
# browser.set_window_size(900, 900)
# 使用get方法通过url打开指定的网页
browser.get(url)
# time模块的sleep函数用于暂停程序执行,这里暂停5秒,以便有足够的时间观察网页加载情况
time.sleep(2)
# 通过url访问另一个网页
browser.get(url1)
time.sleep(2)
# 调用back返回上一个网页
browser.back()
time.sleep(2)
# 调用forward()函数前往下一个网页
browser.forward()
time.sleep(1)
# 刷新页面
browser.refresh()
time.sleep(1)
# 调用page_source获取网页内容
page_content = browser.page_source
print(page_content)
# 最后,调用close方法关闭浏览器窗口
browser.close()
3.2、对页面元素进行操作
3.2.1、获取页面链接元素
鼠标右键然后选择检查(或者按F12),获取页面的全部元素,然后选中元素,进行复制。
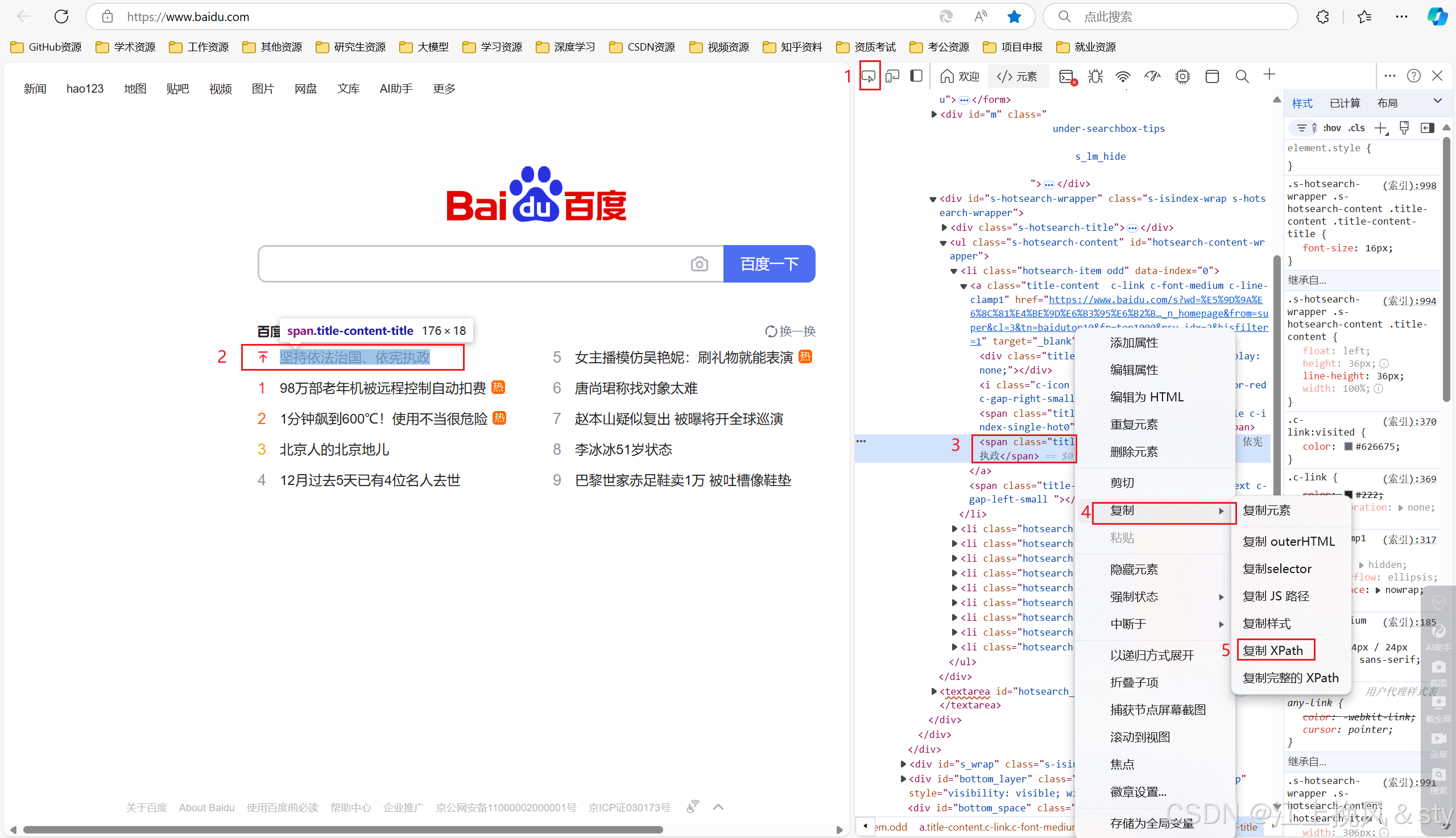
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 模拟点击百度页面链接进行跳转
# 获取页面元素
link = driver.find_element(by=By.XPATH,value="//*[@id='hotsearch-content-wrapper']/li[1]/a/span[2]")
# 链接跳转
link.click()
我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此,Selenium提供了一系列的方法来方便我们实现以上操作。通过webdriver对象的 find_element(by=“属性名”, value=“属性值”),主要包括以下这八种:
属性****函数CLASSfind_element(by=By.CLASS_NAME, value=‘’)XPATHfind_element(by=By.XPATH, value=‘’)LINK_TEXTfind_element(by=By.LINK_TEXT, value=‘’)CSSfind_element(by=By.CSS_SELECTOR, value=‘’)IDfind_element(by=By.ID, value=‘’)TAGfind_element(by=By.TAG_NAME, value=‘’)PARTIAL_LINK_TEXTfind_element(by=By.PARTIAL_LINK_TEXT, value=‘’)
3.2.2、模拟鼠标的基本操作
首先,我们需要引入Keys类。
from selenium.webdriver.common.keys import Keys
其次,模型通过百度搜索python爬虫。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 模拟点击百度页面链接进行跳转
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
基本操作:
具体操作****函数删除键send_keys(Keys.BACK_SPACE)空格键send_keys(Keys.SPACE)制表键send_keys(Keys.TAB)回退键send_keys(Keys.ESCAPE)回车send_keys(Keys.ENTER)全选send_keys(Keys.CONTRL,‘a’)复制send_keys(Keys.CONTRL,‘c’)剪切send_keys(Keys.CONTRL,‘x’)粘贴send_keys(Keys.CONTRL,‘x’)键盘F1send_keys(Keys.F1)
3.2.3、页面加载策略和延时等待
页面加载策略是指在浏览器中加载网页时,Selenium WebDriver等待页面加载完成的行为。这些策略可以帮助我们控制WebDriver在页面加载时的行为,以适应不同的测试需求和性能优化。选择合适的页面加载策略可以显著影响测试的执行时间和稳定性。例如,在单页应用中,由于页面内容是动态加载的,使用
eager
或
none
策略可能更合适,因为它们可以更快地响应页面的变化。而在需要完全加载所有资源以确保页面功能正常的测试中,使用
normal
策略可能更合适以下是Selenium支持的页面加载策略:
页面加载策略特点normal这是默认的页面加载策略。在这种策略下,WebDriver会等待整个页面包括所有子资源(如图像、CSS、JavaScript等)都加载完成,直到触发
load
事件后才会继续执行后续的操作。这意味着WebDriver会等待页面完全加载,包括所有的外部资源加载完成eager在
eager
策略下,WebDriver会等待文档被完全加载和解析完成,但不会等待样式表、图像和iframe等子资源加载完成。这通常意味着WebDriver会等待
DOMContentLoaded
事件触发后继续执行,这比
load
事件更早none使用
none
策略时,WebDriver不会等待页面加载完成,它仅等待初始的HTML被部分下载后就会停止等待,允许脚本继续执行。这意味着WebDriver不会等待任何额外的资源加载,如CSS、JavaScript或图像
在Selenium中,设置WebDriver等待是一种重要的技术,用于确保在执行某些操作之前,页面上的元素已经加载完成或者某个条件已经满足。Selenium提供了两种主要的等待机制:显式等待(Explicit Wait)和隐式等待(Implicit Wait)。
** 显式等待:**显式等待允许你等待某个条件成立,而不是盲目地等待一个固定的时间。它提供了更灵活的控制,可以等待特定的元素出现、元素变得可点击、元素的可见性等。下面包含常用的显式等待方法:
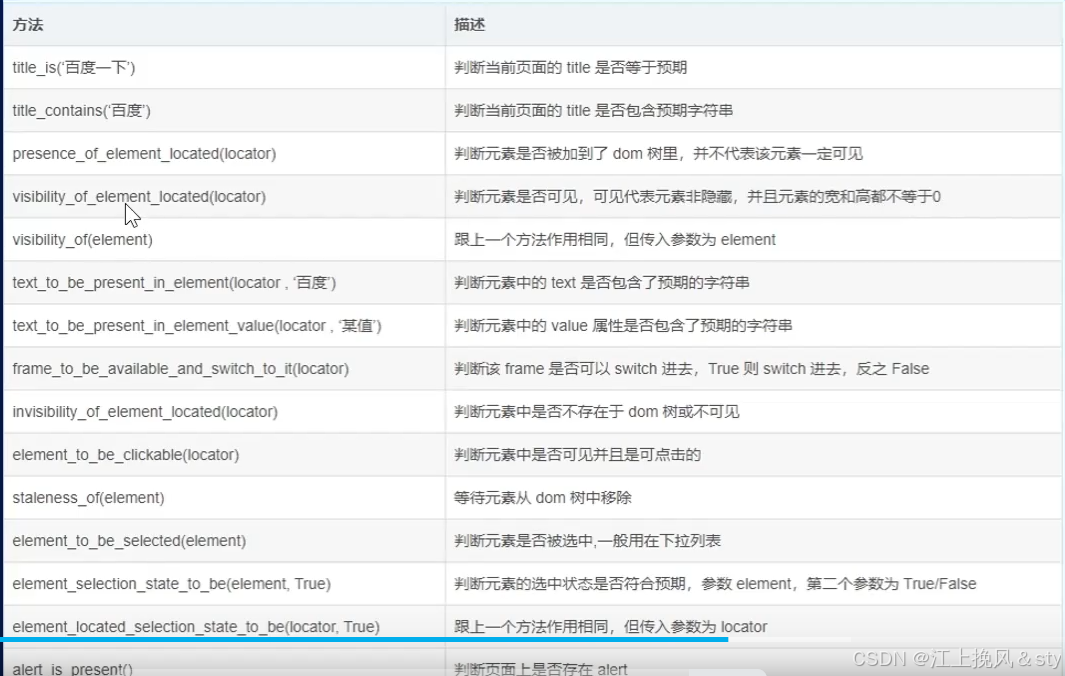
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :练习
@Time :2024/12/5 13:57
@Motto:一直努力,一直奋进,保持平常心
"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 导入显式等待库
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置显式等待,最多等待10秒
wait = WebDriverWait(driver, 10)
try:
# 等待直到某个元素出现
element = wait.until(EC.presence_of_element_located((By.XPATH, "//*[@id='kw']")))
except:
print("未找到元素")
driver.close()
exit()
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
driver.close()
** 隐式等待:**隐式等待设置了一个全局等待时间,在这个时间内,WebDriver会等待某个元素出现。如果在设置的时间内找到了元素,WebDriver会继续执行;如果超时,则抛出
NoSuchElementException
异常。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 初始化Edge浏览器
driver = webdriver.Edge()
# 设置隐式等待5秒钟
driver.implicitly_wait(5)
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 模拟点击百度页面链接进行跳转
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
driver.close()
3.2.4、切换窗口
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
- 打开一个新的页面并切换到新页面:switch_to.new_window('tab')
- 打开一个新的窗口并切换到新窗口:switch_to.new_window('window')
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :练习
@Time :2024/12/5 13:57
@Motto:一直努力,一直奋进,保持平常心
"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
opt.page_load_strategy = 'eager'
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.readnovel.com/book/22312481000716402#Catalog")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
time.sleep(3)
locator = (By.XPATH, '//*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li/a')
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located(locator))
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[1]/a
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[14]/a
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[15]/a
next_page = driver.find_elements(by=By.XPATH, value="//*[@id='j-catalogWrap']/div[2]/div[2]/ul/li/a")
for next in next_page:
next.click()
a = str(next.get_attribute('href').split("/")[-1])
print(a)
time.sleep(2)
driver.execute_script('$(".lbf-panel-head").css("display","none")')
driver.execute_script('$(".lbf-panel-body").css("display","none")')
# link = driver.find_element(by=By.ID, value='//*[@id="j_closeGuide"]')
# link.click()
# locator1 = (By.XPATH, '//*[@id="chapter-95831384777767481"]/div/div[1]/h1')
# locator1 = (By.XPATH, '//*[@id="chapter-95831384777833017"]/div/div[1]/h1')95831384777833017
driver.switch_to.window(driver.window_handles[-1])
# WebDriverWait(driver,20).until(EC.presence_of_element_located(locator1))
time.sleep(5)
# filename = driver.find_element(by=By.XPATH,value='//*[@id="chapter-id}]/div/div[1]/h1').text
filename = driver.find_element(by=By.XPATH, value=f'//*[@id="chapter-{a}"]/div/div[1]/h1').text
content = driver.find_element(by=By.XPATH,value=f'//*[@id="chapter-{a}"]/div/div[2]/div').text
with open(f'D:\ProjectCode\Spider\StudySpider07\\{filename}.txt', 'w', encoding='utf-8') as f:
f.write(content)
print(f'已下载{filename}')
driver.switch_to.window(driver.window_handles[0])
3.2.5、切换表单
在Selenium中,处理表单切换是一个常见的任务,尤其是在涉及到
frame
或
iframe
元素时。以下是Selenium中切换表单的一些关键点:
- Selenium提供了
switch_to.frame()方法来切换到frame或iframe。这个方法可以接受几种类型的参数,包括id、name、index以及页面元素对象。 - 完成
frame/iframe内的操作后,可以通过switch_to.default_content()切换回主文档,或者使用switch_to.parent_frame()切换到父级frame。 - 如果页面中有多层嵌套的
frame/iframe,你可能需要多次调用switch_to.frame()方法来逐层深入,或者使用switch_to.parent_frame()来逐层返回。
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :切换表单
@Time :2024/12/6 13:41
@Motto:一直努力,一直奋进,保持平常心
"""
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
url = "https://www.qidian.com/all/"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service, options=opt)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
browser.get(url)
# 显式等待五秒,加载页面
browser.implicitly_wait(5)
time.sleep(3)
login_button = browser.find_element(by=By.XPATH, value='//*[@id="login-btn"]')
login_button.click()
time.sleep(3)
# 先获取表单所在的iframe元素
iframe = browser.find_element(by=By.XPATH, value='//*[@id="loginIfr"]')
# 进入这个表单
browser.switch_to.frame(iframe)
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="username"]').send_keys('17369961234')
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="password"]').send_keys('skjhg')
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="j-inputMode"]/div[2]/div/label[2]').click()
time.sleep(2)
browser.find_element(by=By.XPATH, value='//*[@id="j-loginInputMode"]/div[3]/div[1]/p[2]/label').click()
time.sleep(2)
browser.find_element(by=By.XPATH, value='//*[@id="j-inputMode"]/div[2]/a').click()
time.sleep(2)
browser.switch_to.default_content()
time.sleep(2)
3.2.6、动作链
在Selenium中,动作链(ActionChains)是一种用于执行复杂用户交互的方法,比如鼠标移动、点击、拖放和键盘输入等。以下是Selenium中动作链的一些基本介绍和常用方法。动作链允许你将多个操作按顺序存放在一个队列里,当你调用
perform()
方法时,这些操作会依次执行。
**常用方法:**
方法****解释click(on_element=None)单击鼠标左键click_and_hold(on_element=None)点击鼠标左键并保持按下状态context_click(on_element=None)执行鼠标右键点击(上下文菜单)double_click(on_element=None)双击鼠标左键drag_and_drop(source, target)将一个元素拖拽到另一个元素上释放drag_and_drop_by_offset(source, xoffset, yoffset)将源元素拖动到指定的偏移位置上释放key_down(value, element=None)按下键盘上的某个键,不释放key_up(value, element=None)释放键盘上的某个键move_by_offset(xoffset, yoffset)鼠标从当前位置移动到某个坐标move_to_element(to_element)鼠标移动到某个元素move_to_element_with_offset(to_element, xoffset, yoffset)移动到距某个元素多少距离的位置perform()执行链中的所有动作release(on_element=None)在某个元素位置松开鼠标左键send_keys(*keys_to_send)发送某个键到当前焦点的元素send_keys_to_element(element, *keys_to_send)发送某个键到指定元素
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :动作链
@Time :2024/12/6 14:11
@Motto:一直努力,一直奋进,保持平常心
"""
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
url = "https://www.12306.cn/index/index.html"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
# 防止Edge在自动化测试过程中弹出一些对话框
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用add_experimental_option方法可以添加一些实验性的Edge选项
opt.add_experimental_option('excludeSwitches', ['enable-automation'])
# 的作用是让浏览器在WebDriver会话结束后保持开启状态
opt.add_experimental_option("detach", True)
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service, options=opt)
# 显式等待五秒,加载页面
browser.implicitly_wait(5)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
browser.get(url)
time.sleep(1)
# 将鼠标悬停在车票上
ticket_element = browser.find_element(by=By.XPATH, value='//*[@id="J-chepiao"]/a')
ActionChains(browser).move_to_element(ticket_element).perform()
time.sleep(2)
# 点击单程进入下一个页面
one_way_element = browser.find_element(by=By.XPATH, value='//*[@id="megamenu-3"]/div[1]/ul/li[1]/a')
ActionChains(browser).click(one_way_element).perform()
# 输入出发地
time.sleep(2)
from_station = browser.find_element(by=By.XPATH, value='//*[@id="fromStationText"]')
ActionChains(browser).click(from_station).pause(1).send_keys('重庆').pause(1).send_keys(Keys.ARROW_DOWN).pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 输入目的地
to_station = browser.find_element(by=By.XPATH, value='//*[@id="toStationText"]')
ActionChains(browser).click(to_station).pause(1).send_keys('长沙').pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 输入出发日期
date = browser.find_element(by=By.XPATH, value='//*[@id="place_area"]/ul/li[4]/span')
ActionChains(browser).click(date).pause(1).send_keys(Keys.CLEAR).pause(1).send_keys("2024-12-06").pause(1).send_keys(Keys.ARROW_DOWN).pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 选择学生
browser.find_element(by=By.XPATH, value='//*[@id="sf2_label"]').click()
time.sleep(2)
# 勾线高铁
browser.find_element(by=By.XPATH, value='//*[@id="_ul_station_train_code"]/li[1]/label').click()
time.sleep(1)
# 选择发车时间
start_time_element = browser.find_element(by=By.XPATH, value='//*[@id="cc_start_time"]')
Select(start_time_element).select_by_visible_text('12:00--18:00')
# 单击查询
browser.find_element(by=By.XPATH, value='//*[@id="query_ticket"]').click()
time.sleep(3)
四、高级操作
4.1、反检测
在使用Selenium进行自动化测试或爬虫时,网站可能会通过各种方式检测到自动化工具的使用。以下是一些常用的Selenium反检测方法。
4.1.1、使用stealth.min.js文件
stealth.min.js
是一个JavaScript文件,它包含了一系列的代码,用于隐藏Selenium WebDriver的自动化特征,使得使用Selenium进行自动化测试时,浏览器的行为更接近于真实用户的浏览器行为,从而降低被网站检测为自动化工具的风险。在使用Selenium WebDriver时,可以在启动浏览器之前,通过执行
stealth.min.js
中的JavaScript代码来实现隐藏特征。这通常是通过Selenium的
execute_cdp_cmd
方法实现的,该方法允许执行Chrome DevTools Protocol命令。
** 下载安装stealth.min.js文件:**

4.1.2、使用debugging模式
在Selenium中使用调试模式来防止检测,主要是指通过开启Chrome的远程调试端口来接管已经打开的浏览器会话,从而避免被网站检测到自动化工具的使用。
**步骤:**
1、找到Edge浏览器的安装路径:
C:\Program Files (x86)\Microsoft\Edge\Application
2、在命令提示符下输入命令创建配置浏览器:
msedge.exe --remote-debugging-port=9222 --user-data-dir="你的用户数据目录路径"
3、复制在Edge的快捷方式,并在其上右击,选择属性,在目标栏后面加上空格加上下面命令
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" --remote-debugging-port=9222 --user-data-dir="你的用户数据目录路径"
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Edge(options=options)
4.1.3、使用undetected_edgedriver
**
undetected_edgedriver
是一个基于
undetected_chromedriver
**进行一些调整以支持Edge浏览器的Selenium库。它旨在帮助自动化脚本更难被网站检测到,从而提高自动化任务的成功率。
** 安装
undetected_edgedriver:
**
pip3 install undetected-edgedriver
** 使用方法:**
import undetected_edgedriver as uc
# 创建Edge浏览器实例
browser = uc.Edge(use_subprocess=True)
# 打开网页
browser.get(url="https://your-target-website.com/")
# 执行其他操作,例如查找元素、点击按钮等
# ...
# 关闭浏览器
browser.quit()
4.2、图片验证码
使用超级鹰打码平台识别验证码图片中的数据,用于模拟登陆操作。
- 查询该用户是否还有剩余的题分

- 创建一个软件:用户中心>软件ID>生成一个软件ID>录入软件名称>提交(软件id和秘钥)

- 下载示例代码:开发文档>点此下载python示例
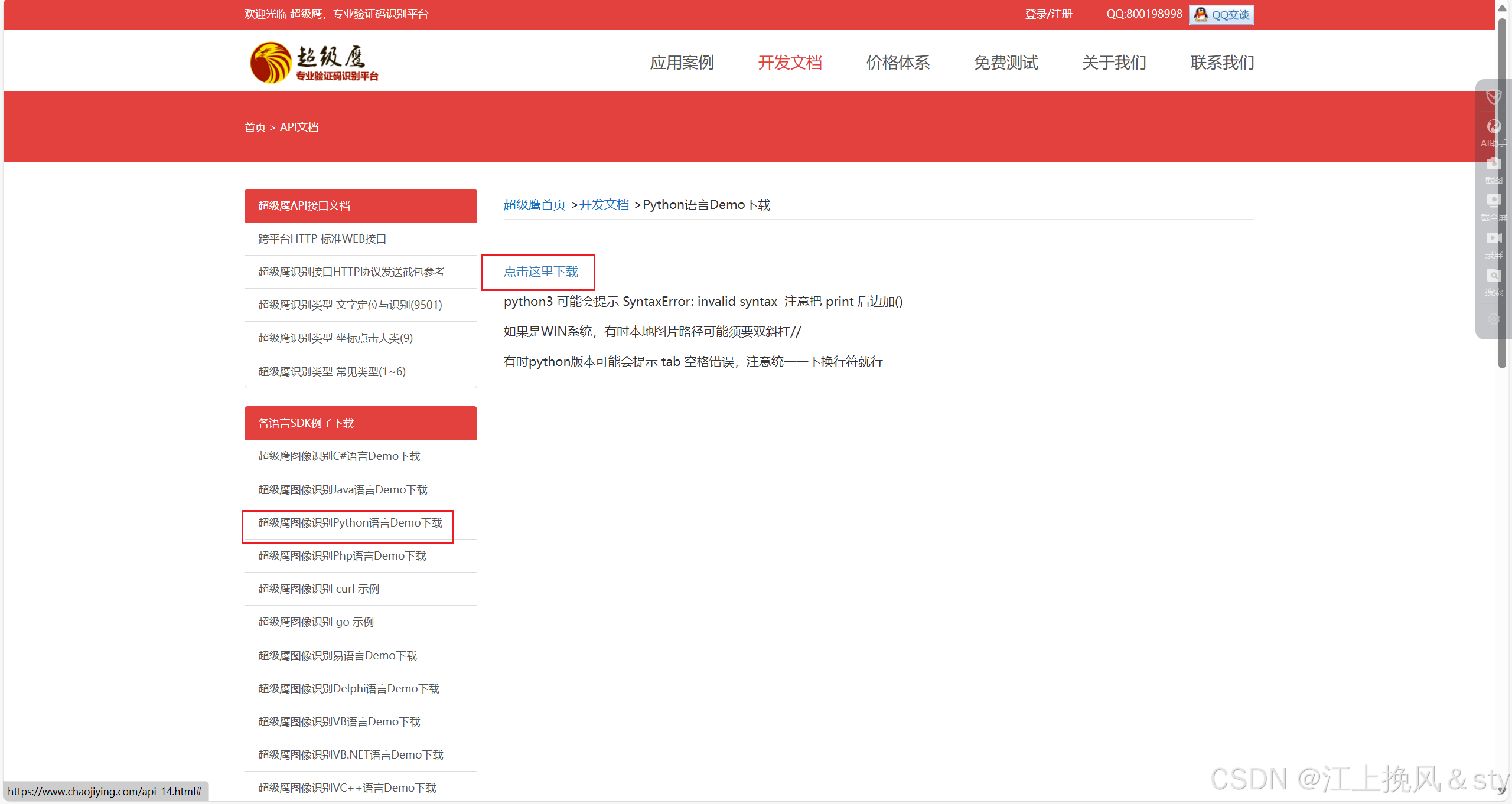
- 示例代码:
#!/usr/bin/env python
# coding:utf-8
import json
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
with open('password.json','r',encoding='utf-8') as f:
info = json.loads(f.read())
password = info['password']
username = info['username']
soft_id = info['soft_id']
print(username)
chaojiying = Chaojiying_Client(username, password, soft_id) #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read()
code = chaojiying.PostPic(im,1902)
print(code)
#本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
# print chaojiying.PostPic(im, 1902)
# #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
只需要password.jsonw文件中替换自己的用户名、密码和ID即可。
** selenium模拟验证码登入超级鹰专业验证码识别平台案例:**
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :验证码
@Time :2024/12/6 16:13
@Motto:一直努力,一直奋进,保持平常心
"""
import json
import time
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from chaojiying_Python import chaojiying
from chaojiying_Python.chaojiying import Chaojiying_Client
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
def login(url,password,username,soft_id):
browser = webdriver.Edge(service=service)
browser.get(url)
# 输入用户名
browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys(username)
# 输入密码
time.sleep(2)
browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys(password)
# 获取验证码
img = browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png
time.sleep(2)
Chaojiying_Client(username,password,soft_id)
code = chaojiying.chaojiying.PostPic(img,1902)['pic_str']
# 输入验证码
browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(code)
time.sleep(2)
# 点击登入
browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
if __name__ == '__main__':
url = "https://www.chaojiying.com/user/login/"
with open('chaojiying_Python/password.json','r',encoding='utf-8') as f:
info = json.loads(f.read())
password = info['password']
username = info['username']
soft_id = info['soft_id']
login(url, password, username, soft_id)
五、结语
本博客为自学python爬虫的过程贴,内容上可能存在些许错误,希望大家批评指正,后续我将努力完善修改,散花!
版权归原作者 江上挽风&sty 所有, 如有侵权,请联系我们删除。