
文章目录
什么是数据库设计?
数据库就是根据业务系统的具体需要,结合我们所选用的数据库管理系统(DBMS),为这个,业务构造出最优的数据存储模型。并建立好数据库中的表结构及表与表之间的关联关系的过程。使之能有效的对应用系统中的数据进行存储,并可以高效的对已经存储的数据进行访问。 (有效的存储,高效的访问)
常见的数据库管理系统:
MySQL 、Qracle、SQLServer、PgSql 还有一种流行的NoSQL系统:Mongo、Memcache、Redis
为什么要进行数据库设计?
数据库系统是应用系统存储数据的关键组成部分,是系统稳定运行的基础,决定着系统是否可以高效地运行。
优良的设计:减少数据冗余,避免数据维护异常,节约空间,高效访问。
糟糕的设计:存在大量的数据冗余,存在数据插入、更新、删除异常,浪费大量存储空间,访问数据低效。
数据库设计的步骤:
一、数据库的设计过程---->需求分析-逻辑设计-物理设计-维护优化
二、具体来说:
需求分析: 数据是什么,数据的属性,数据和属性各自的特点
逻辑设计: ER建模
物理设计: ora,mysql等特点
维护优化: 新的需求进行建表,索引优化,大表拆分
1,对一个数据库设计前,我们要了解我们数据库要存入哪些数据,这些数据有哪些特征(重要程度? 时效性? )然后对症下药,时效性不同->可以定时归档,清理。 重要程度或扩展程度不同可以->分库分表……
2,了解数据之间的联系,1对1,1对多还是多对多,从而建立的数据表可以是独立的,可以是关联性质的。
3,如果是日志文件,我们打算存入数据库。就要想到这种数据增长性很大,如果只存不清理会造成数据库使用量的大幅度增长,是不好的。我们要定期进行归档,清除操作。
实例
1,我们接到一个项目:
首先要去分析这个项目有哪些模块—>然后针对具体模块分析有哪些属性—>针对属性分析哪个属性或哪几个属性的集合可以用来标识这个属性[唯一标识]------->分析这个模块数据是否永久存储,是否数据增长很快,是否经常查询---->如果是就要考虑分库分表了。如果不是,那么这些数据是否只会存储一定时间,是否需要永久记录—>如果是我们就定期归档及数据的迁移操作了。
如:注册用户表:
属性:用户名,密码,电话,邮箱,地址,昵称,头像,……
唯一标识: 邮箱? 用户名+邮箱->md5加密来标识?……
存储特点:随系统上线时间逐渐增加,需要永久存储。 —> 必须分库分表操作了。
如拟定2亿用户 可以分4个库,每个库100张表,每张表50w条记录。
2,分析这些模块之间的关联性:
1对1? 1对多? 多对多? ---->画ER图。
比如,电子商务网站系统包括几个模块:用户模块,商品模块,订单模块,购物车模块,供应商模块。
记录注册用户信息
属性:用户名、密码、电话、邮箱、身份证号、地址、姓名、昵称。。。
可选唯一标识属性:用户名、身份证号、电话
存储特点:随系统上线时间逐渐增加,需要永久存储。
E-R图
1)逻辑设计是做什么的?
a将需求转化为数据库的逻辑模型 b通过ER图的形式对逻辑模型进行展示 c同所选用的具体的数据库管理系统无关
(2)名词解释
关系:一个关系对应通常所说的一张表;
元组:表中的一航即为一个元组。
属性:表中的一列及为一个属性;每一个属性都有一个名称,成为属性名。
候选码:表中的某个属性组,它可以唯一确定一个元组。
主码:一个关系有多个候选吗,选定其中一个为主码。
域:属性的取值范围。
分量:元组中的一个属性值。
(3)ER图例说明
矩形:表示实体集,矩形内些实体集的名字
菱形:表示联系集,将原来多对对的关系转换为一对多的关系
椭圆:表示实体的属性
线段:将属性连接到实体集,或将实体集连接到联系集
设计范式
设计范式
第一、二、三范式(重点)
BC范式
第四、五范式
操作异常:
插(依赖于其他的存在)、更(需要一次更新多处)删除(删除一个其他的坏了)
数据冗余:多处存储、可以通过其他列计算得到
第一范式
第一范式
数据库表中的所有字段都是单一属性,不可再分
单一属性是由基本的数据类型所构成的,如整数、浮点数、字符串
要求数据库中的表都是二维表
第二范式
第二范式(2NF):数据库的表中不存在非关键字段对任一候选关键字段的部分函数依赖。
部分函数依赖是指存在着组合关键字中的某一关键字决定非关键字的情况。(多关键字字段的某一字段和其他某一非关键字字段有必然的关系,例如:关键字1=“aa” 则 非关键字3 必定是 “bbcc” , 关键字1=“bb” 则 非关键字3 必定是 “addccasd” )
所有的单关键字段的表都符合第二范式。
第三范式
第三范式(3NF):第三范式是在第二范式的基础上定义的,
如果数据表中不存在非关键字段对任意候选关键字段的传递函数依赖
则符合第三范式。
1NF:列不可分就满足1NF了。
2NF:不存在部分依赖,比如 (A,B)→C。(消除非主属性对主属性的传递依赖,即完全依赖于主键)
3NF:不存在传递依赖,比如A→B→C。(在2NF基础上消除了传递依赖)
BC范式
BCNF指主属性之间也不能有部分函数依赖或传递函数依赖
物理设计
物理设计:1234步骤不能颠倒
1 常用DBMS有 mysql oracle sqlserver 等
2 定义数据库、表及字段的命名规范
3 选择合适的字段类型 varchar char
4 反范式化设计:增加冗余,提高效率 -空间换时间
选择哪种数据库
物理设计 1.选择合适的数据库管理系统(考虑成本特点之类) 2.定义数据库、表及字段的命名规范 3.根据选择的DBMS系统选择合适的字段类型(各种数据类型适合的东西) 4.反范式化设计(有时候用空间换时间) 物理设计要做什么 常见DBMS系统(商业、企业级:oracle大,口碑好、SqlServer小) (开源、互联网项目:MySQL、PgSQL小)
MySQL常见搜索引擎
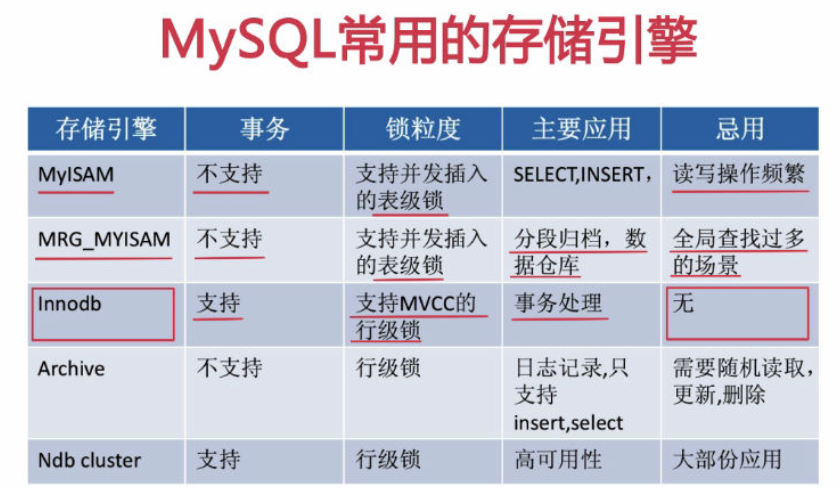
数据库表及字段的命名规则
确定库、表、字段命名规范
1、可读性:大小写 (有些系统对大小写是敏感的)
2、表意性:见名知意
3、长名:尽量不要缩写
数据库字段类型选择原则
当一个列可以选择多种数据结构时,应优先考虑数字类型,其次是日期或二进制类型,最后是字符类型,对于同级别的数据类型,应该优先选择占用空间小的数据类型。
1.在堆数据进行比较(查询,JOIN条件及排序)操作时,同样的数据,字符处理往往比数字处理慢
2.在数据库中,数据处理以页为单位,列的长度越小,利于性能提升
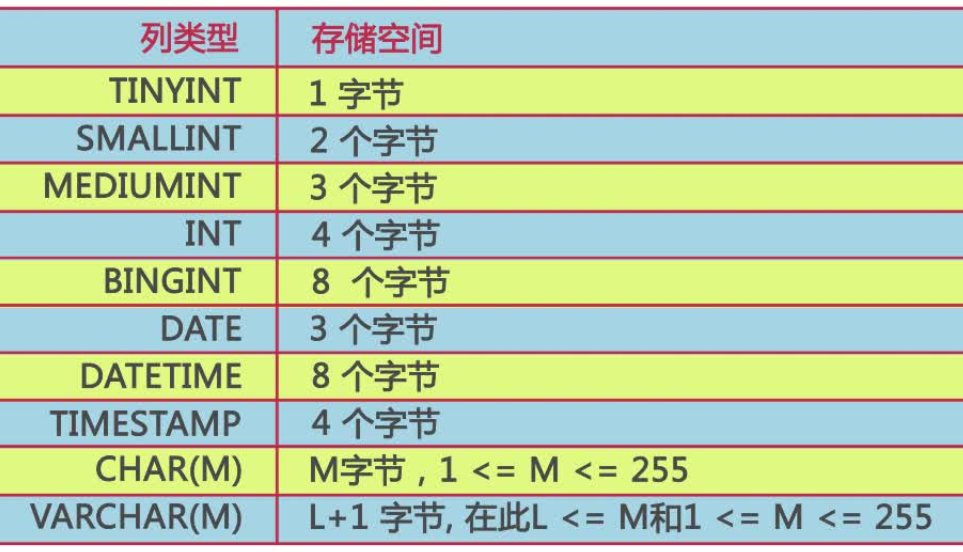
数据库如何选择字段类型
char和varchar如何选择?
原则:
1.如果列中药存储的数据程度产不多一致,则考虑char,否则考虑varchar
2.如果劣种的最大长度小于50byte,则一般也要考虑char
3.一般不易定义大于50byte的char类型列
decimal和float如何选择?
1.decimal用于存储精确数据,而float只能用于存储非精确度数据
2.由于float的存储空间开销一般比decimal小,所以非精度数据优先选择float
时间类型如何存储?
1.使用int存储时间字段的优缺点
优点:字段长度比datetime小
缺点:使用不方便,需要进行函数转换
2.需要存储的时间粒度
年月日小时分秒周
字符:计算机中使用的文字和符号
字节:计量单位
①ASCII码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中,一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
③Unicode编码中,一个英文等于两个字节,一个中文(含繁体)等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
④UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中,世界上任何字符的存储都需要4个字节。
数据库设计其他注意事项
如何选择主键
1.区分业务主键和数据库主键
业务主键用于标识业务数据,进行表与表之间的关联。
数据库主键为了优化数据存储
2.根据数据库的类型,考虑主键是否要顺序增长
有些数据库是按主键的顺序逻辑存储的
3.主键的字段类型所占用空间要尽可能的小
对于使用聚集索引方式的存储的表,每个索引后都会附加主键的信息
避免使用外键约束
1.降低数据导入的效率
2.增加维护成本
3.虽然不建议使用外键约束,但是相关联的列上一定要建立索引。
避免使用触发器
1.降低数据导入的效率
2.可能会出现意想不到的数据异常
3.使业务逻辑变的复杂。
关于预留字段
1.无法准确的知道预留字段的类型
2.无法准确的知道预留字段中所存储的内容
3.严禁使用预留字段
反范式化表设计
反范式化:
允许存在少量的数据冗余,适当对第三范式进行违反,目的是:使用空间来换取时间,提高性能和读写效率。
举例:
抛开红色字体,原表符合第三范式,但是在查询订单信息时需要关联四张表,比较复杂低效。
加入红色字体部分后,尽管出现了数据冗余,但是在读取订单信息的时候,查询变得高效。只要两张表就可以得到详细的订单信息。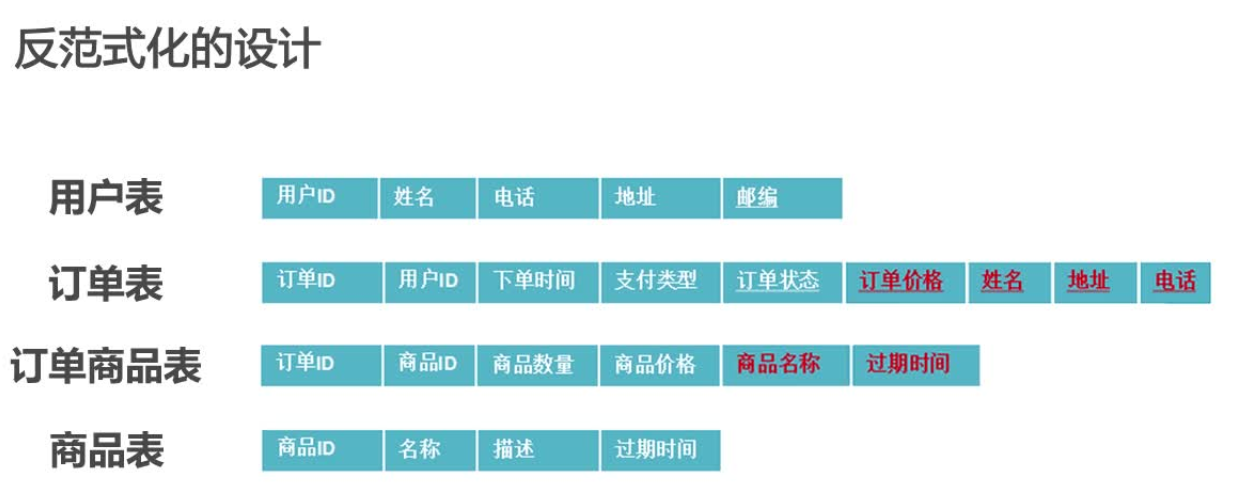
反范式化表设计
什么是反范式化:反范式化是针对范式化而言的,在前面介绍了数据库设计的第三范式,所谓的反范式化就是为了性能和读取效率的考虑而适当的对第三范式的要求进行违反,而允许存在少量的数据冗余,换句话来说反范式化就是使用空间来换取时间。
为什么反范式化
- 减少表的关联数量
- 增加数据的读取效率
- 反范式化一定要适度
数据库维护和优化
1.维护数据字典
2.维护索引
3.维护表结构
4.适当的时候对标进行水平拆分或垂直拆分
1.状态字段的含义都记录在数据字典中,使用时要通过数据字典来查询含义,数据字典很重要
2.使用过程中,发现索引不适用,删除旧的,建立新的索引
3.由于需求变化,列的增加和减少
4.拆分表:水平和垂直
数据库如何维护数据字典
1.第三方工具:针对不同的DBMS
2.利用数据库本身的备注字段:对表和列增加备注字段
3.到处数据字典(通用),但是鼠疫:更改表备注时,只需要更改表备注,其他的一些列的属性(列的长度,宽度,是否为空)必须保持原样
数据库如何维护索引
如何选择合适的列建立索引?
1.出现在WHERE从句,GROUP从句,ORDER BY从句中的列
2.可选择性高的列放到索引的前面
3.索引中不要包含太长的数据库类型
注意事项
- 索引并不是越多越好,过多的索引不但会降低写效率,而且会降低读的效率
- 定期维护索引碎片
- 在SQL 语句中不要使用强制索引关键字
数据库中合适的操作
维护(修改)表结构
注意事项
1、MySQL5.5之前会锁表,可使用第三方工具;5.6之后本身支持在线表结构变更
2、同时维护数据字典
3、控制表的宽度和大小
适合的操作
1、批量操作(数据库中)逐条操作(应用程序中)
2、尽量少用"select * "查询
3、控制使用用户自定义函数(使用函数,索引不起作用)
4、不要使用全文索引(中文支持不好,需要另建索引文件)
数据库表的垂直和水平拆分
表的垂直拆分(由于需求变更,表的列增加)
1.拆分的好处:一页中行数越多I/O效率越高,但是表的宽度过大时(列很多,数据很大),一页中存储的数据会变少,I/O效率低,拆分成窄表时,提高了效率
2.拆分的原则:经常查询的列放在一起,大字段拆分到附加表
版权归原作者 三水J 所有, 如有侵权,请联系我们删除。