
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

本文已经加入「大数据成神之路PDF版」中提供下载。
你可以关注公众号,后台回复:「PDF****」 即可获取。
更多PDF下载可以参考:《重磅,大数据成神之路PDF可以分类下载啦!》
Spark重点难点系列:
- 《【Spark重点难点01】你从未深入理解的RDD和关键角色》
- 《【Spark重点难点02】你以为的Shuffle和真正的Shuffle》
- 《【Spark重点难点03】你的数据存在哪了?》
- 《【Spark重点难点04】你的代码跑起来谁说了算?(内存管理)》
- 《【Spark重点难点05】SparkSQL YYDS(上)!》
- 《【Spark重点难点06】SparkSQL YYDS(中)!》
- 《【Spark重点难点07】SparkSQL YYDS(加餐)!》
- 《【Spark重点难点08】Spark3.0中的AQE和DPP小总结》
基础配置
spark.executor.memory
指定Executor memory,也就是Executor可用内存上限
spark.memory.offHeap.enabled
堆外内存启用开关
spark.memory.offHeap.size
指定堆外内存大小
spark.memory.fraction
堆内内存中,Spark缓存RDD和计算的比例
spark.memory.storageFraction
Spark缓存RDD的内存占比,相应的执行内存比例为
1 - spark.memory.storageFraction
spark.local.dir
Spark指定的临时文件目录
spark.cores.max
一个Spark程序能够给申请到的CPU核数
spark.executor.cores
单个Executor的核心数
spark.task.cpus
单个task能够申请的cpu数量
spark.default.parallelism
默认并行度
spark.sql.shuffle.partitions
Shuffle过程中的Reducer数量
Shuffle配置
spark.shuffle.file.buffer
设置shuffle write任务的bufferedOutputStream的缓冲区大小。将数据写入磁盘文件之前,将其写入缓冲区,然后在将缓冲区写入磁盘后将其填充。
spark.reducer.maxSizeInFlight
该参数用于设置Shuffle read任务的buff缓冲区大小,该缓冲区决定一次可以拉取多少数据。
spark.shuffle.sort.bypassMergeThreshold
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
Spark SQL配置
spark.sql.adaptive.enabled
Spark AQE开启开关
spark.sql.adaptive.coalescePartitions.enabled
是否开启合并小数据分区,默认开启
spark.sql.adaptive.advisoryPartitionSizeInBytes
倾斜数据分区拆分,小数据分区合并优化时,建议的分区大小
spark.sql.adaptive.coalescePartitions.minPartitionNum
合并后最小的分区数
spark.sql.adaptive.fetchShuffleBlocksInBatch
是否批量拉取blocks,而不是一个个的去取。给同一个map任务一次性批量拉取blocks可以减少IO提高性能
spark.sql.adaptive.skewJoin.enabled
自动倾斜处理,处理sort-merge join中的倾斜数据
spark.sql.adaptive.skewJoin.skewedPartitionFactor
判断分区是否是倾斜分区的比例。
当一个 partition 的 size 大小大于该值(所有 parititon 大小的中位数)且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者 parition 的条数大于该值(所有 parititon 条数的中位数)且大于 spark.sql.adaptive.skewedPartitionRowCountThreshold,才会被当做倾斜的 partition 进行相应的处理。默认值为 10
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
判断是否倾斜分区的最低阈值。
《大数据成神之路》正在全面PDF化。
你只需要关注并在后台回复**
「PDF」
**就可以看到阿里云盘下载链接了!
另外我把发表过的文章按照体系全部整理好了。现在你可以在后台方便的进行查找:
电子版把他们分类做成了下面这个样子,并且放在了阿里云盘提供下载。
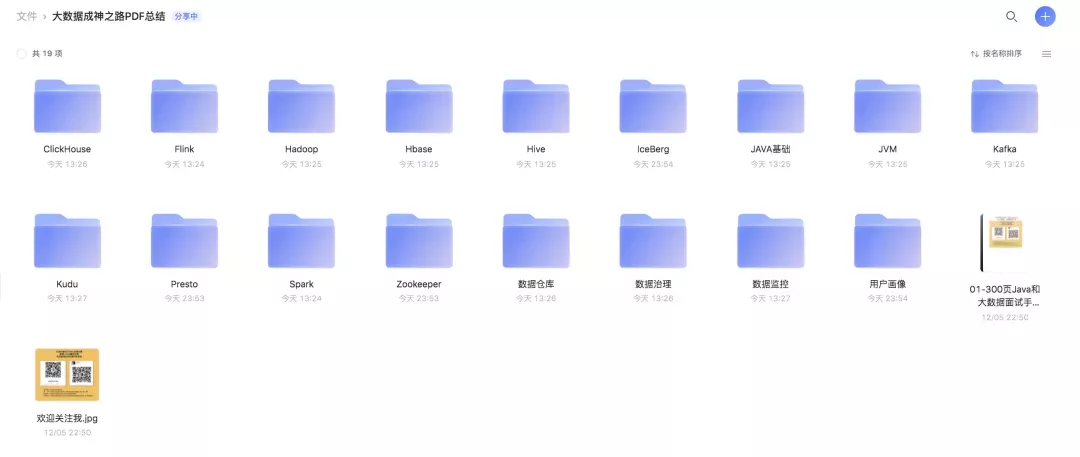
我们点开一个文件夹后:
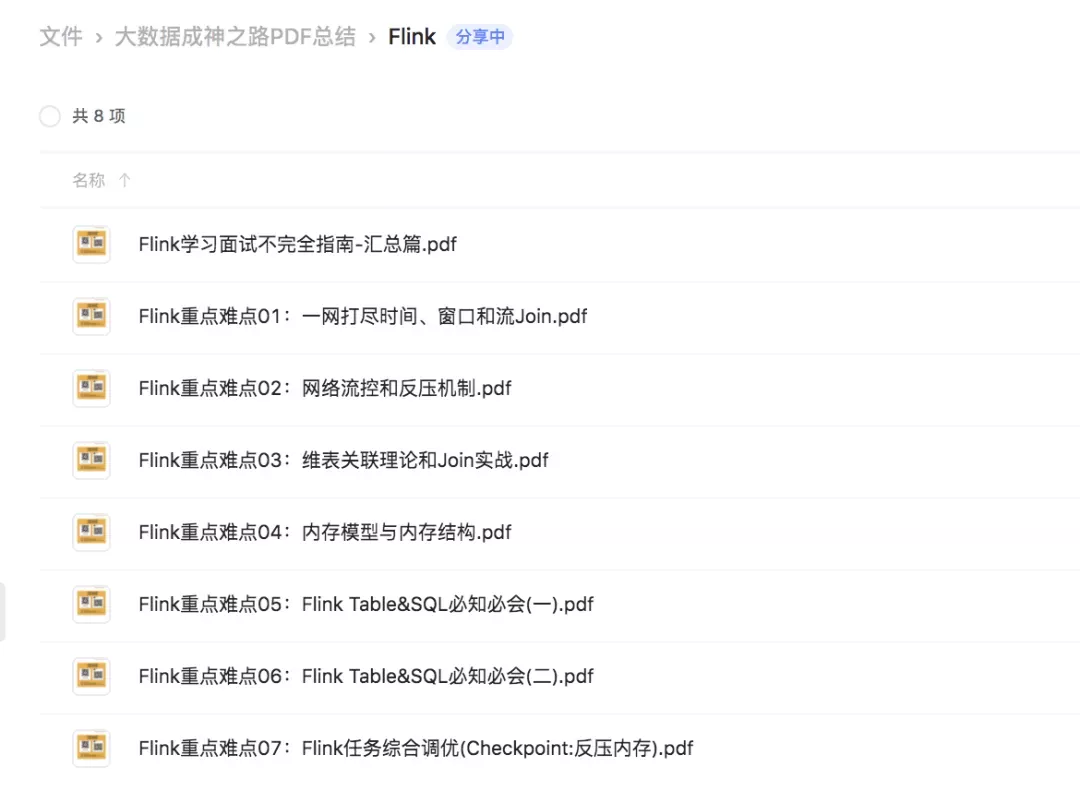
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!
Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。


八千里路云和月 | 从零到大数据专家学习路径指南
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
版权归原作者 王知无(import_bigdata) 所有, 如有侵权,请联系我们删除。