
面对的问题
通过selenium启动文件但是被反爬或无法启动某些页面
解决方式:
利用python自带的 subprocess启动浏览器再,通过selenium连接启动的这个浏览器
实现代码
注意:sebprocess与selenium是分为两份.py文件运行的
1.利用 subprocess 启动浏览器程序
1.达到Chrome的地址
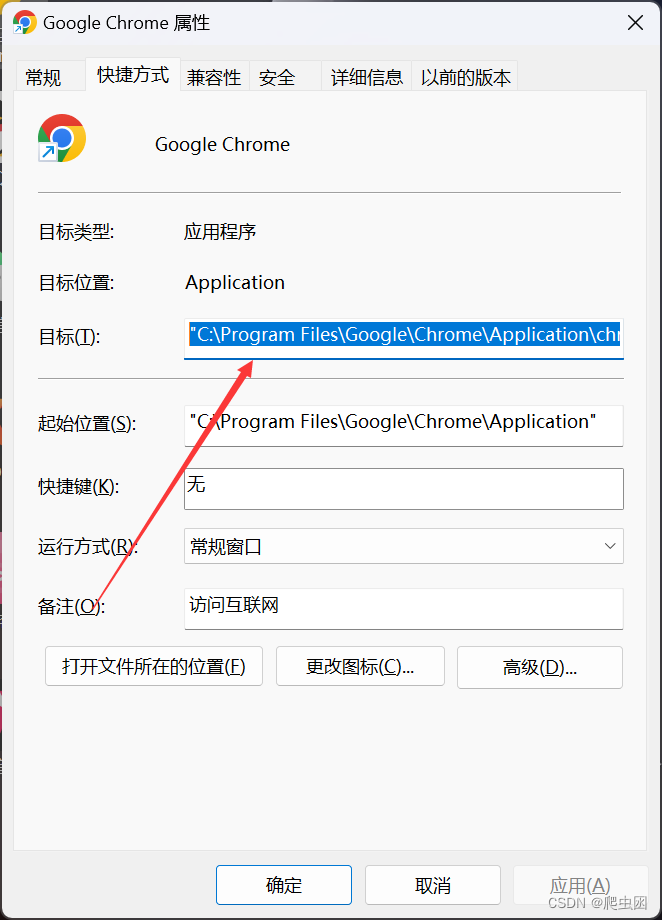
2.输入代码(自行更改chrome的位置)
import subprocess
cmd =r'"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222 --user-data-dir=C:\selenium\ChromeProfile'# --remote-debugging-port=9222 --user-data-dir=C:\selenium\ChromeProfile
subprocess.run(cmd)
2.selenium连接
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress","127.0.0.1:9222")
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.baidu.com")
该文借鉴了:这位博主的文章,本人也是先看他解决再记录下这个问题的
本文转载自: https://blog.csdn.net/2301_80809706/article/details/139127840
版权归原作者 爬虫囦 所有, 如有侵权,请联系我们删除。
版权归原作者 爬虫囦 所有, 如有侵权,请联系我们删除。