
一、Kafka的消息传输保障
一般而言,消息中间件的消息传输保障分为3个层级:
- at most once:至多一次。消息可能丢失,但绝不会重复消费
- at least once:最少一次。消息绝不丢失,但可能重复传输
- exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次。
1. Kafka生产者消息保障
- 一旦消息被成功提交到日志文件,多副本机制会保障消息不丢失
- 对于网络问题,生产者也会通过重试机制来确保消息写入Kafka,但是重试过程中可能会导致消息的重复写入
因此,Kafka生产者提供的消息保障为 at least once
2. Kafka消费者消息保障
Kafka消费者消息保障主要取决于消费者处理消息和提交消费位移的顺序
如果消费者先处理消息后提交位移,那么如果在消息处理之后在位移提交之前消费者宕机了,那么重新上线后,会从上一次位移提交的位置拉取,这就导致了重复消息,对应 at least once
反过来,如果先提交位移后处理消息,就有可能会造成消息的丢失,对应 at most once
Kafka从0.11.0.0版本开始引入了幂等和事务这两个特性,以此来实现EOS(exactly once semantics)
二、Kafka幂等性
Kafka提供了幂等机制,只需显式地将生产者客户端参数 enable.idempotence 设置为 true即可(默认为false),开启后生产者就会幂等的发送消息
实现原理:
- 每个新的生产者实例在初始化时会被分配一个PID(producer id)
- 对于每个PID,消息发送到的每一个分区都有对应的序列号,序列号从0开始单调递增,生产者每发送一条消息就会将<PID,分区>对应的序列号值加1
- broker端会在内存中为每一对<PID,分区>维护一个序列号,对于收到的每一条消息,只有当它的序列号的值(SN_new)正好比broker端中维护的对应序列号的值(SN_old)大1,broker才会接收该消息。如果 SN_new < SN_old + 1,说明消息被重复写入,broker会将该消息丢弃。否则,说明中间有数据尚未写入,暗示可能有消息丢失,对应生产者会抛出 OutOfOrderSequenceException 异常
注意:序列号实现幂等只是针对每一对<PID,分区>,即Kafka的幂等性只能保证单个生产者会话(session)中单分区的幂等!!!!
三、Kafka事务
通过事务可以弥补幂等性不能跨多个分区的缺陷,且可以保证对多个分区写入操作的原子性
在使用Kafka事务前,需要开启幂等特性,将 enable.idempotence 设置为 true
事务消息发送的示例如下:
Properties properties =newProperties();
properties.put(org.apache.kafka.clients.producer.ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);KafkaProducer<String,String> producer =newKafkaProducer<String,String>(properties);// 初始化事务
producer.initTransactions();// 开启事务
producer.beginTransaction();try{// 处理业务逻辑ProducerRecord<String,String> record1 =newProducerRecord<String,String>(topic,"msg1");
producer.send(record1);ProducerRecord<String,String> record2 =newProducerRecord<String,String>(topic,"msg2");
producer.send(record2);ProducerRecord<String,String> record3 =newProducerRecord<String,String>(topic,"msg3");
producer.send(record3);// 处理其他业务逻辑// 提交事务
producer.commitTransaction();}catch(ProducerFencedException e){// 中止事务,类似于事务回滚
producer.abortTransaction();}
producer.close();
通过事务,在生产者角度,Kafka可以保证:
- 跨生产者会话的消息幂等发送 transactionId与PID一一对应,如果新的生产者启动,具有相同transactionId的旧生产者会立即失效。(每个生产者通过 transactionId获取PID的同时,还会获取一个单调递增的 producer epoch)
- 跨生产者会话的事务恢复 当某个生产者实例宕机后,新的生产者实例可以保证任何未完成的旧事物要么被提交(Commit),要么被中止(Abort),如此可以使新的生产者实例从一个正常的状态开始工作(通过 producer epoch判断)
在消费者角度,事务能保证的语义相对偏弱,对于一些特殊的情况,Kafka并不能保证已提交的事务中的所有消息都能被消费:
- 对采用日志压缩策略的主题,事务中的某些消息可能被清理(相同key的消息,后写入的消息会覆盖前面写入的消息)
- 事务中消息可能分布在同一个分区的多个日志分段(LogSegment)中,当老的日志分段被删除时,对应的消息可能会丢失
- …
事务隔离性
事务的隔离性通过设置消费端的参数 isolation.level 确定,默认值为 read_uncommitted,即消费者可以消费到未提交的事务。该参数可以设置为 read_commited,表示消费者不能消费到还未提交的事务
事务手动提交
在一个事务中如果需要手动提交消息,需要先将 enable.auto.commit 参数设置为 false,然后调用 sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) 方法进行手动提交,该方式特别适用于 消费-转换-生产模式的状况
示例代码如下:
producer.initTransactions();while(true){org.apache.kafka.clients.consumer.ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));if(!records.isEmpty()){Map<TopicPartition,OffsetAndMetadata> offsets =newHashMap<>();
producer.beginTransaction();try{for(TopicPartition partition: records.partitions()){List<ConsumerRecord<String,String>> partitionRecords = records.records(partition);for(ConsumerRecord<String,String>record: partitionRecords){ProducerRecord<String,String> producerRecord =newProducerRecord<>("topic-sink",record.key(),record.value());
producer.send(producerRecord);}long lastConsumedOffset = partitionRecords.get(partitionRecords.size()-1).offset();
offsets.put(partition,newOffsetAndMetadata(lastConsumedOffset +1));}// 手动提交事务
producer.sendOffsetsToTransaction(offsets,"groupId");
producer.commitTransaction();}catch(ProducerFencedException e){// log the exception
producer.abortTransaction();}}}
四、Kafka事务实现原理
为了实现事务,Kafka引入了事务协调器(TransactionCoodinator)负责事务的处理,所有的事务逻辑包括分派PID等都是由TransactionCoodinator 负责实施的。
broker节点有一个专门管理事务的内部主题 __transaction_state,TransactionCoodinator 会将事务状态持久化到该主题中
事务的整体流程如下: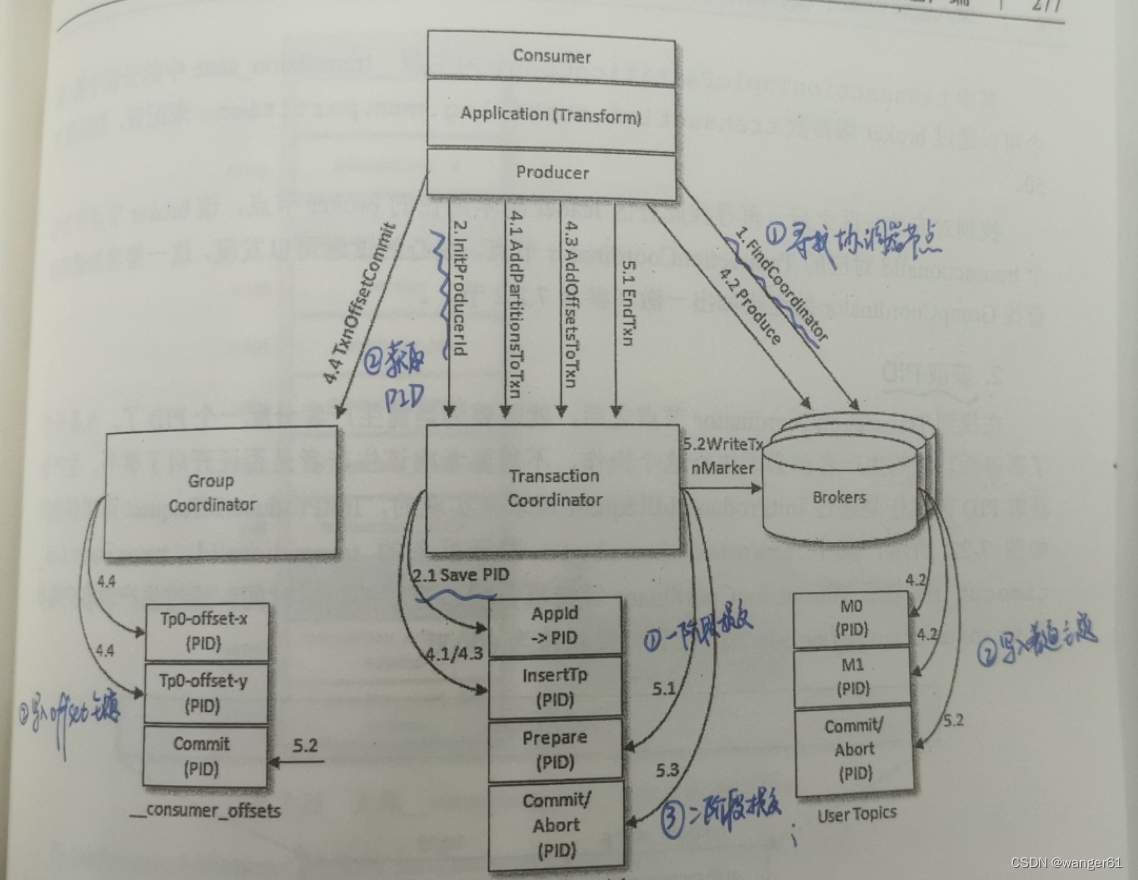
- 查找 TransactionCoordinator:生产者会先向某个broker发送 FindCoordinator 请求,找到 TransactionCoordinator 所在的 broker节点
- 获取PID:生产者会向 TransactionCoordinator 申请获取 PID,TransactionCoordinator 收到请求后,会把 transactionalId 和对应的 PID 以消息的形式保存到主题 __transaction_state 中,保证 <transaction_Id,PID>的对应关系被持久化,即使宕机该对应关系也不会丢失
- 开启事务:调用 beginTransaction()后,生产者本地会标记开启了一个新事务
- 发送消息:生产者向用户主题发送消息,过程跟普通消息相同,但第一次发送请求前会先发送请求给TransactionCoordinator 将 transactionalId 和 TopicPartition 的对应关系存储在 __transaction_state 中
- 提交或中止事务:Kafka除了普通消息,还有专门的控制消息(ControlBatch)来标志一个事务的结束,控制消息有两种类型,分别用来表征事务的提交和中止 该阶段本质就是一个两阶段提交过程: 1. 将 PREPARE_COMMIT 或 PREPARE_ABORT 消息写入主题 __transaction_state2. 将COMMIT 或 ABORT 信息写入用户所使用的普通主题和 __consumer_offsets3. 将 COMPLETE_COMMIT 或 COMPLETE_COMMIT_ABORT 消息写入主题 __transaction_state
如此一来,表面当前事务已经结束,此时就可以删除主题 __transaction_state 中所有关于该事务的消息
版权归原作者 wanger61 所有, 如有侵权,请联系我们删除。