
「Kafka」生产者篇
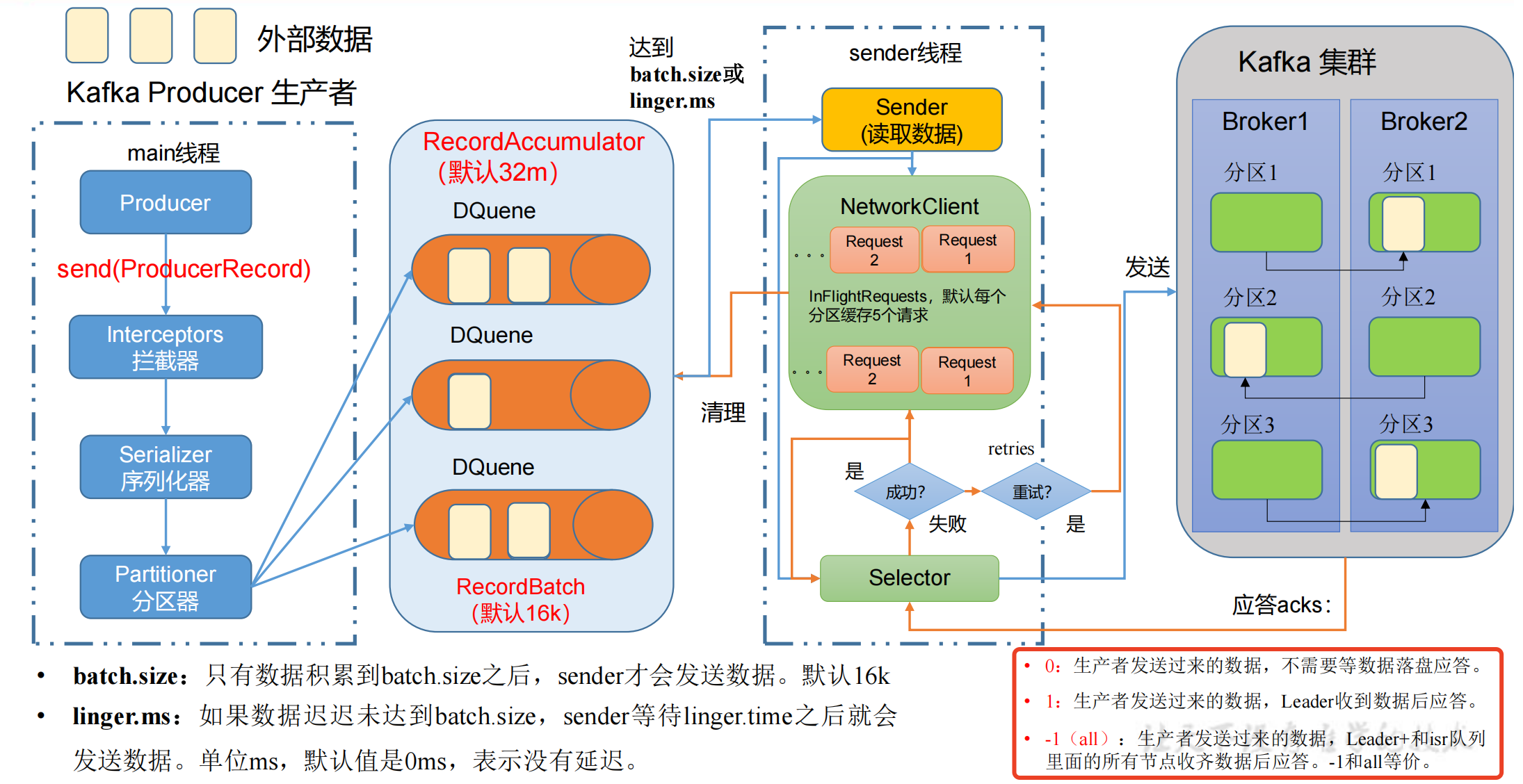
生产者发送消息流程
在消息发送的过程中,涉及到了
两个线程
——
main 线程
和
Sender 线程
。
在 main 线程中创建了 一个
双端队列 RecordAccumulator
。
main线程将消息发送给RecordAccumulator,Sender线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
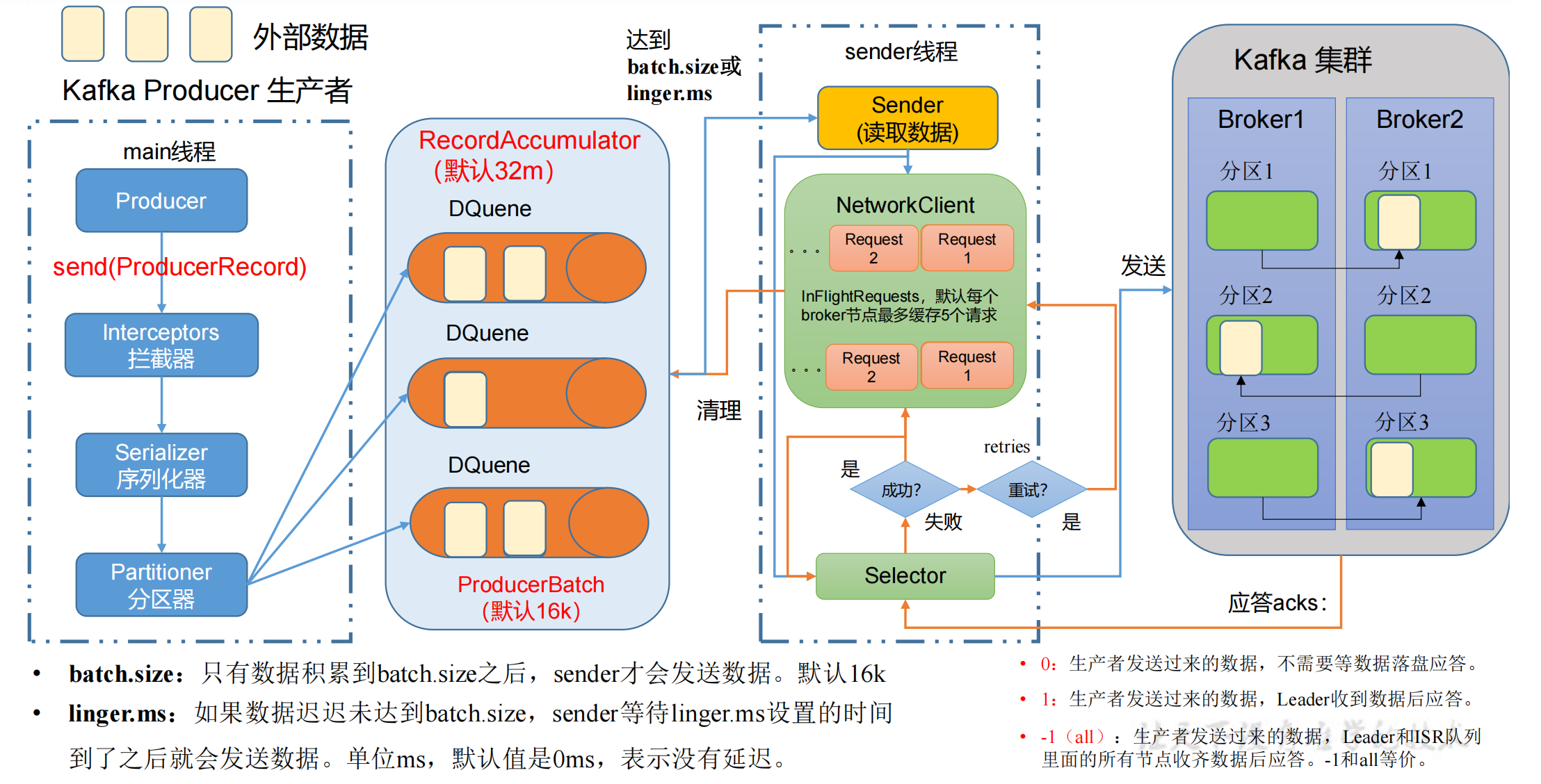
- main线程创建 Producer 对象,调用 send 函数发送消息,经过: - 拦截器 Interceptors(可选项,扩展一些额外功能)- 序列化器 Serializer(为什么不用Java的序列化?因为大数据传输需要更轻量的序列化方式)- 分区器 Partitioner,需要判断发送到哪个分区
- 一个分区就会创建一个双端队列 RecordAccumulator,创建队列都是在
内存里完成的,总大小默认为32m。 - 双端队列 RecordAccumulator 还有一个内存池的概念,每次 send 数据到队列后,在存放数据的时候会从内存池中取出内存,数据发送到kafka后释放内存归还到内存池;一端创建内存,另一端释放内存,这也是它为什么设计为双端队列。 - Sender线程从队列中拉取数据 - 每次批处理
batch.size的大小默认为16k,延迟时间linger.ms默认为0ms,没有延迟。 - 这两个条件是 或 的关系,两个条件达到任意一个就可以发送数据。- 以节点的方式,key:value => Broker1:(队列数据...)的格式发送给对应的 kafka 服务器,如果kafka没有应答,默认每个broker节点队列最多缓存 5 个请求,后续 生产经验—数据乱序 的章节会讲这个作用。 - Selector负责打通底层的链路,IO输入流 => IO输出流,经过Selector发送到kafka集群,kafka集群进行副本的同步。
- 如果kafka集群收到数据后,会返回 ack,有3种模式,如上图。 - 如果ack返回成功,则先清理掉缓存的Request请求,然后清理到对应队列中的数据。- 如果ack返回失败,则进行 retries 重试,默认重试次数是int的最大值(死磕),一直发Request请求,直到重试成功。- 详细讲解请参考下文的 生产经验—数据可靠性。
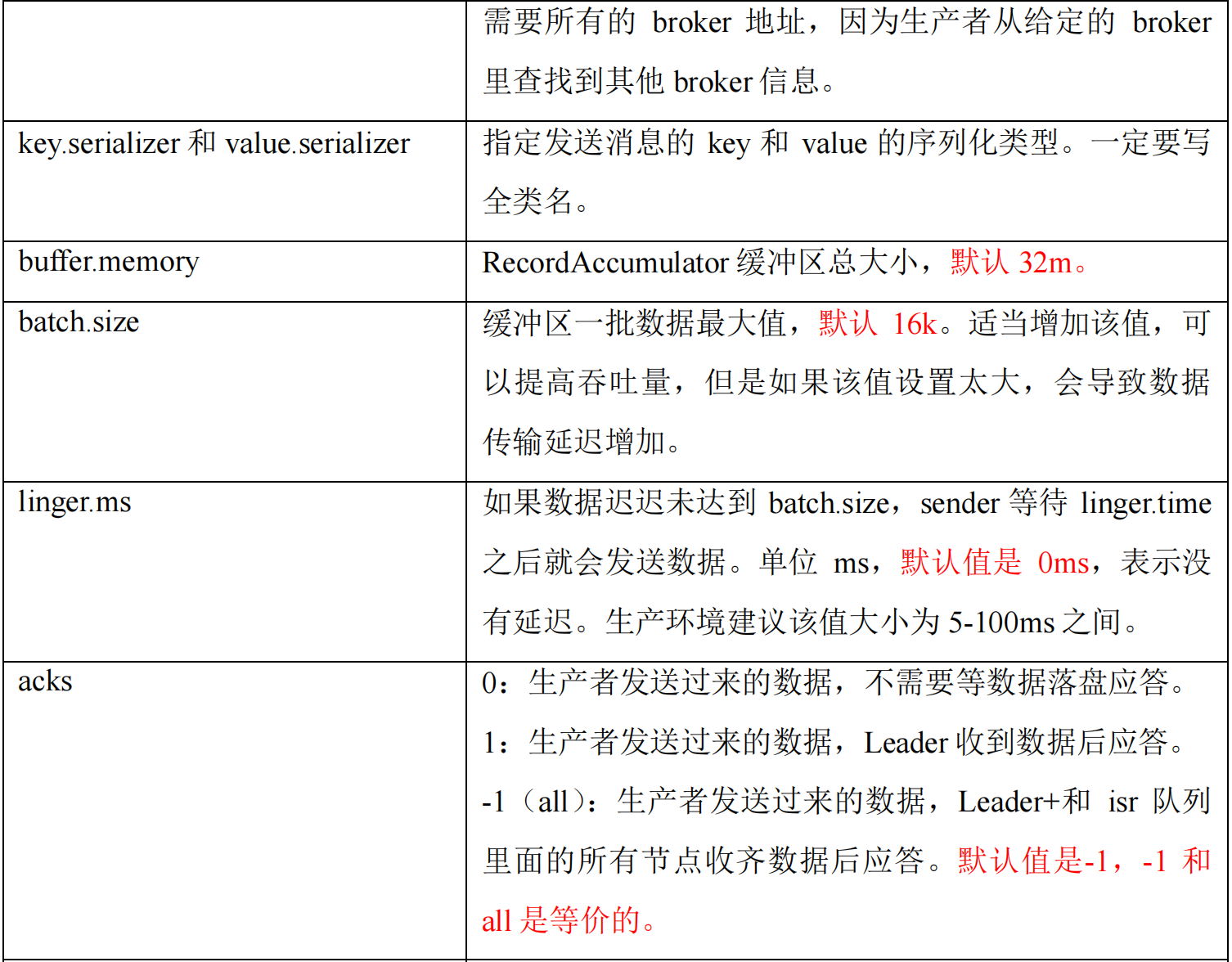
生产者重要参数列表

异步发送
- 同步发送:外部数据发送到 RecordAccumulator 队列中,等待这批数据都发送到 kafka 集群,再返回。
- 异步发送:外部数据发送到 RecordAccumulator 队列中,不管这些数据有没有发送到 kafka 集群,直接返回。 - 默认为异步发送
普通异步发送
编写不带回调函数的代码
importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importjava.util.Properties;publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsInterruptedException{// 1. 创建 kafka 生产者的配置对象Properties properties =newProperties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 3. 创建 kafka 生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 4. 调用 send 方法,发送消息for(int i =0; i <5; i++){// 这里只指定了topic和value
kafkaProducer.send(newProducerRecord<>("first","atguigu "+ i));}// 5. 关闭资源
kafkaProducer.close();}}
回调异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception)。
如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
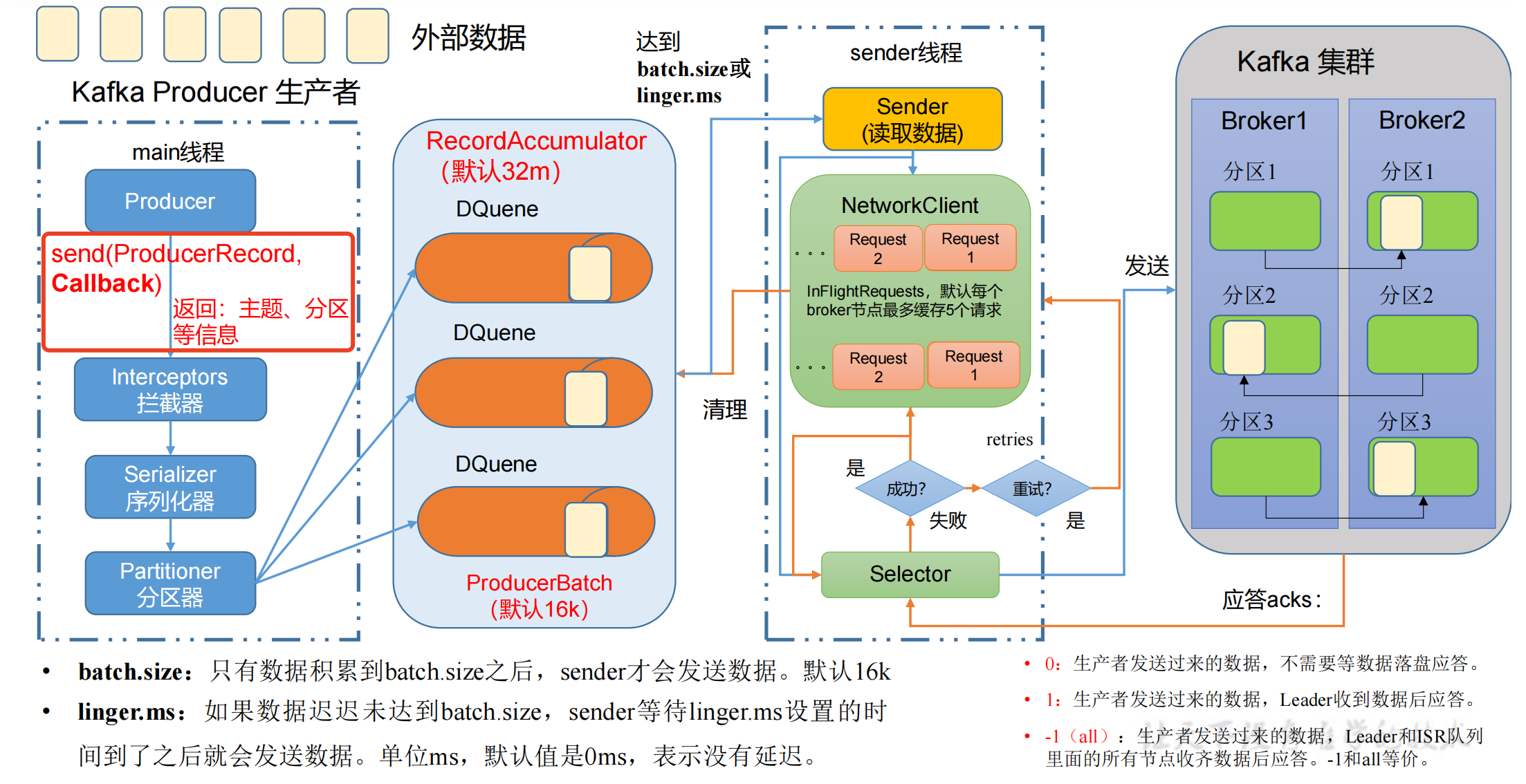
// 4. 调用 send 方法,发送消息for(int i =0; i <5; i++){// 添加回调 Callback
kafkaProducer.send(newProducerRecord<>("first","atguigu "+ i),newCallback(){// 该方法在 Producer 收到 ack 时调用,为异步调用@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception ==null){// 没有异常,输出信息到控制台System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{// 出现异常打印
exception.printStackTrace();}}});// 延迟一会会看到数据发往不同分区Thread.sleep(2);}
同步发送
只需在异步发送的基础上,再调用一下
get()
方法即可。

生产者分区
分区好处
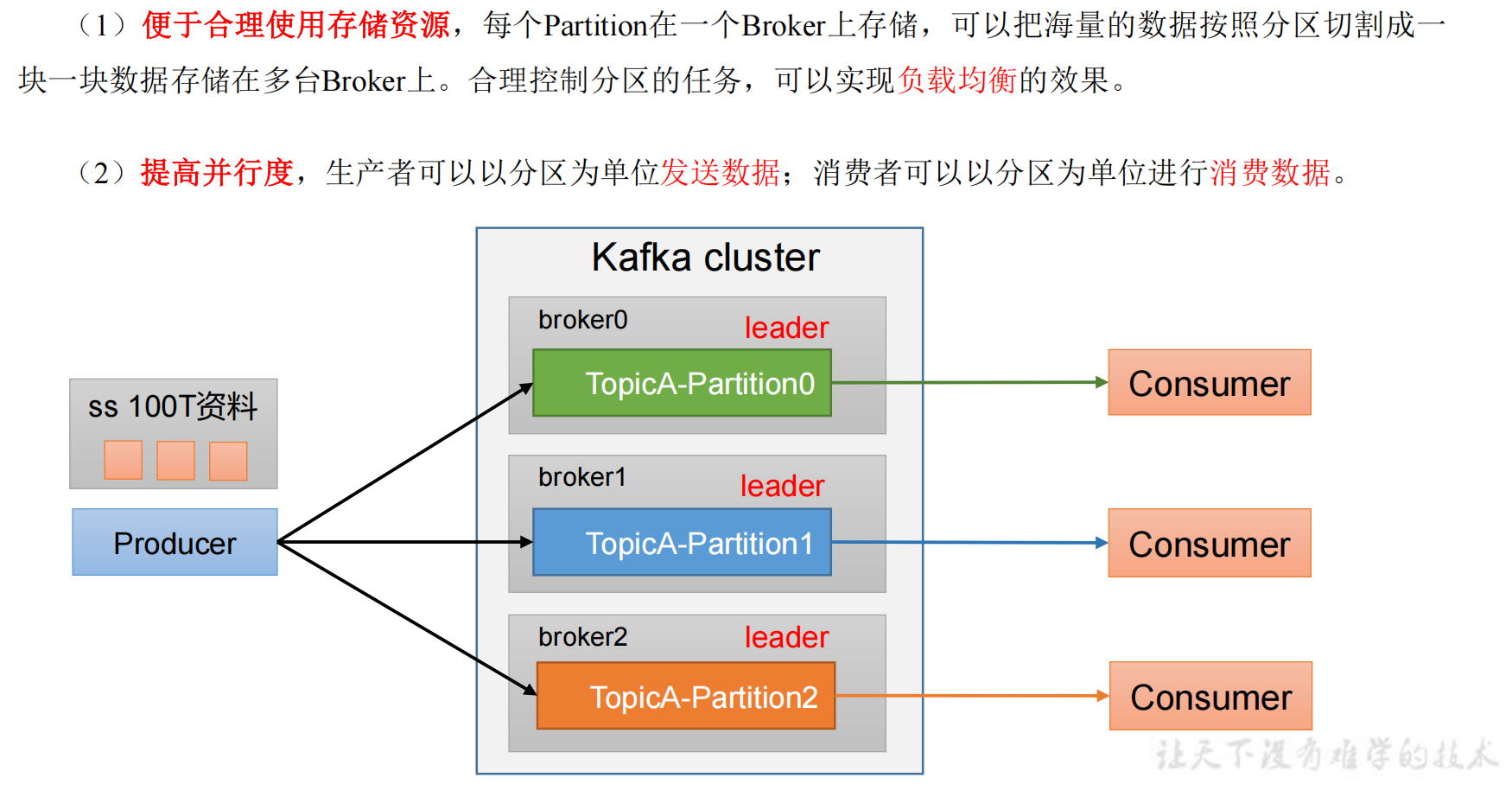
可以通过机器的存储能力自定义分区数据,比如 broker0 存储 20T 数据,broker1和2分别存储 40T 数据。
生产者发送消息的分区策略
可阅读:详解Kafka分区机制原理|Kafka 系列 二
默认的分区器 DefaultPartitioner
/**
* The default partitioning strategy: 默认分区策略
* 如果你指定了分区,则直接用这个分区
* 如果没指定分区,但有key,则按照key的hash值 % 分区数
* 如果既没指定分区也没指定key,则按照粘性分区处理。
* See KIP-480 for details about sticky partitioning.
*/publicclassDefaultPartitionerimplementsPartitioner{...}
ProducerRecord 类的构造方法就表示了这 3 种分区策略:

自定义分区器
- 定义类实现
Partitioner接口 - 重写
partition()方法importorg.apache.kafka.clients.producer.Partitioner;importorg.apache.kafka.common.Cluster;importjava.util.Map;/** * 1. 实现接口 Partitioner * 2. 实现3个方法: partition、close、configure * 3. 编写 partition 方法,返回分区号 */publicclassMyPartitionerimplementsPartitioner{/** * 返回信息对应的分区 * @param topic 主题 * @param key 消息的 key * @param keyBytes 消息的 key 序列化后的字节数组 * @param value 消息的 value * @param valueBytes 消息的 value 序列化后的字节数组 * @param cluster 集群元数据可以查看分区信息 * @return */@Overridepublicintpartition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,Cluster cluster){// 获取消息String msgValue = value.toString();// 创建 partitionint partition;// 判断消息是否包含 atguiguif(msgValue.contains("atguigu")){ partition =0;}else{ partition =1;}// 返回分区号return partition;}// 关闭资源@Overridepublicvoidclose(){}// 配置方法@Overridepublicvoidconfigure(Map<String,?> configs){}} - 使用分区器的方法,在生产者的配置中添加分区器参数
importorg.apache.kafka.clients.producer.*;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;publicclassCustomProducerCallbackPartitions{publicstaticvoidmain(String[] args){Properties properties =newProperties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 添加自定义分区器 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.producer.MyPartitioner");KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);for(int i =0; i <5; i++){ kafkaProducer.send(newProducerRecord<>("first","atguigu "+ i),newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception e){if(e ==null){System.out.println("主题:"+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{ e.printStackTrace();}}});} kafkaProducer.close();}}
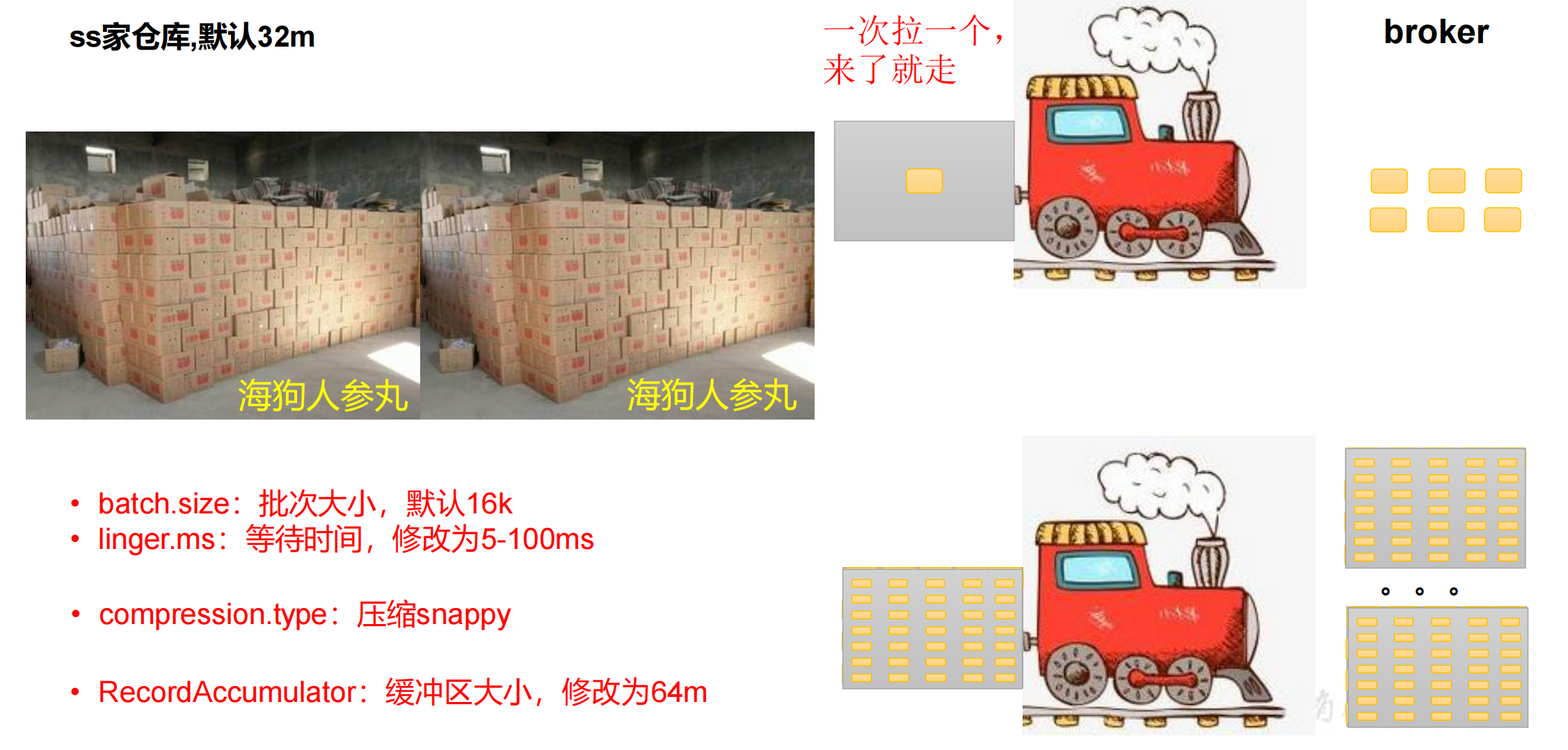
生产者如何提高吞吐量
- 合理调整
batch.size和linger.ms的参数值 - 采用数据压缩
- 调整缓冲区大小
importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importjava.util.Properties;publicclassCustomProducerParameters{publicstaticvoidmain(String[] args){// 1. 创建 kafka 生产者的配置对象Properties properties =newProperties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// batch.size:批次大小,默认 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);// linger.ms:等待时间,默认 0ms
properties.put(ProducerConfig.LINGER_MS_CONFIG,1);// RecordAccumulator:缓冲区大小,默认 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// compression.type:压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");// 3. 创建 kafka 生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 4. 调用 send 方法,发送消息for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","atguigu "+ i));}// 5. 关闭资源
kafkaProducer.close();}}
生产经验—数据可靠性
回顾发送流程
**数据可靠性主要根据 kafka 集群返回给我们的
ack
。**
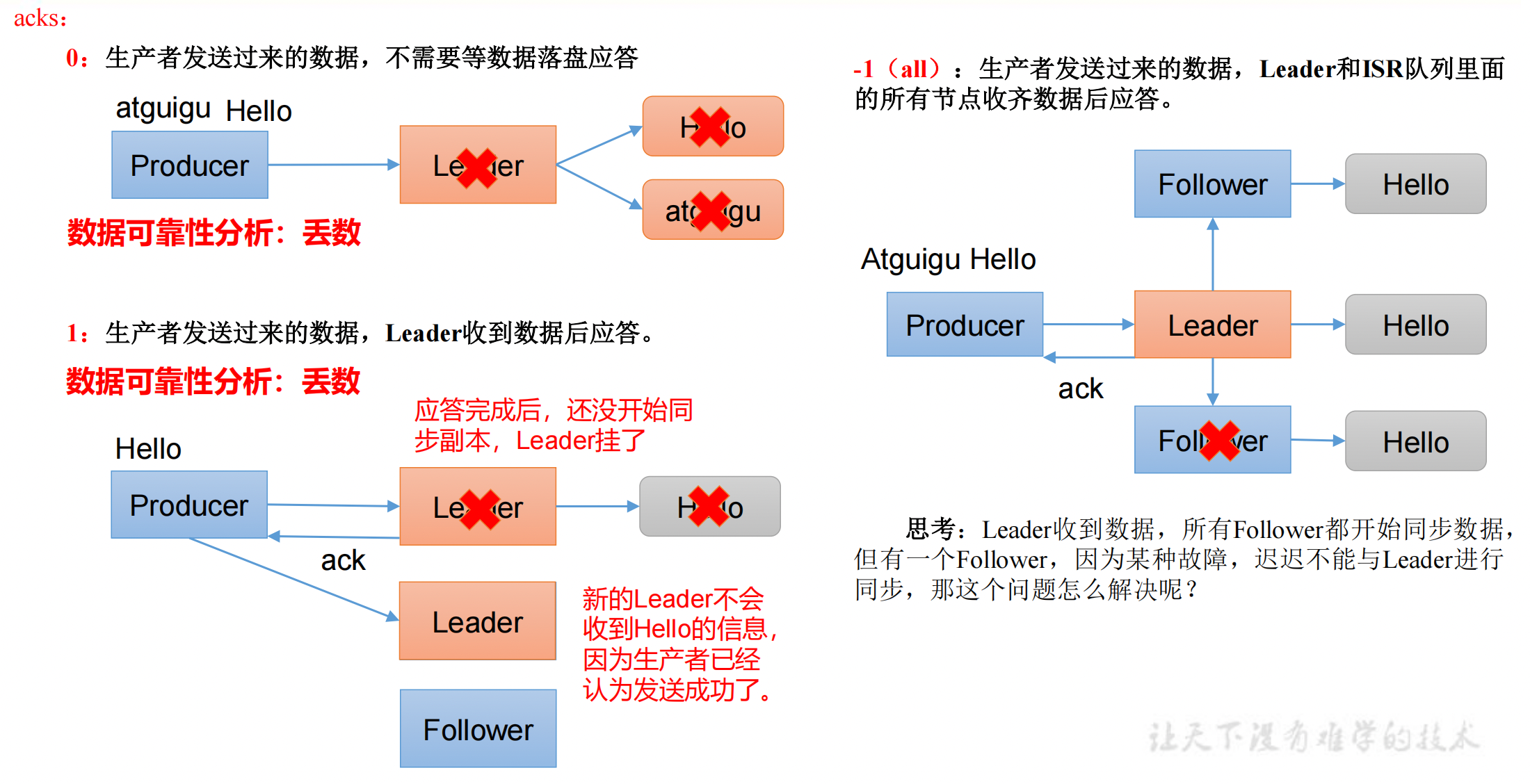
ack 应答原理
- ack=0,不需要等待数据落盘应答,一直发送给 kafka,很容易丢数据。 - 数据发送到 Leader 后,Leader 挂掉了,此时数据还在内存中,未落盘,数据丢失。
- ack=1,不需要等待 kafka 主从同步完成,Leader 收到数据落盘后应答。 - Leader 成功落盘,但还未同步给 Follower,Leader 挂了,数据丢失。
- ack=-1,需要等待 Leader 和 ISR 队列里面的所有节点收齐数据后应答。
数据完全可靠条件
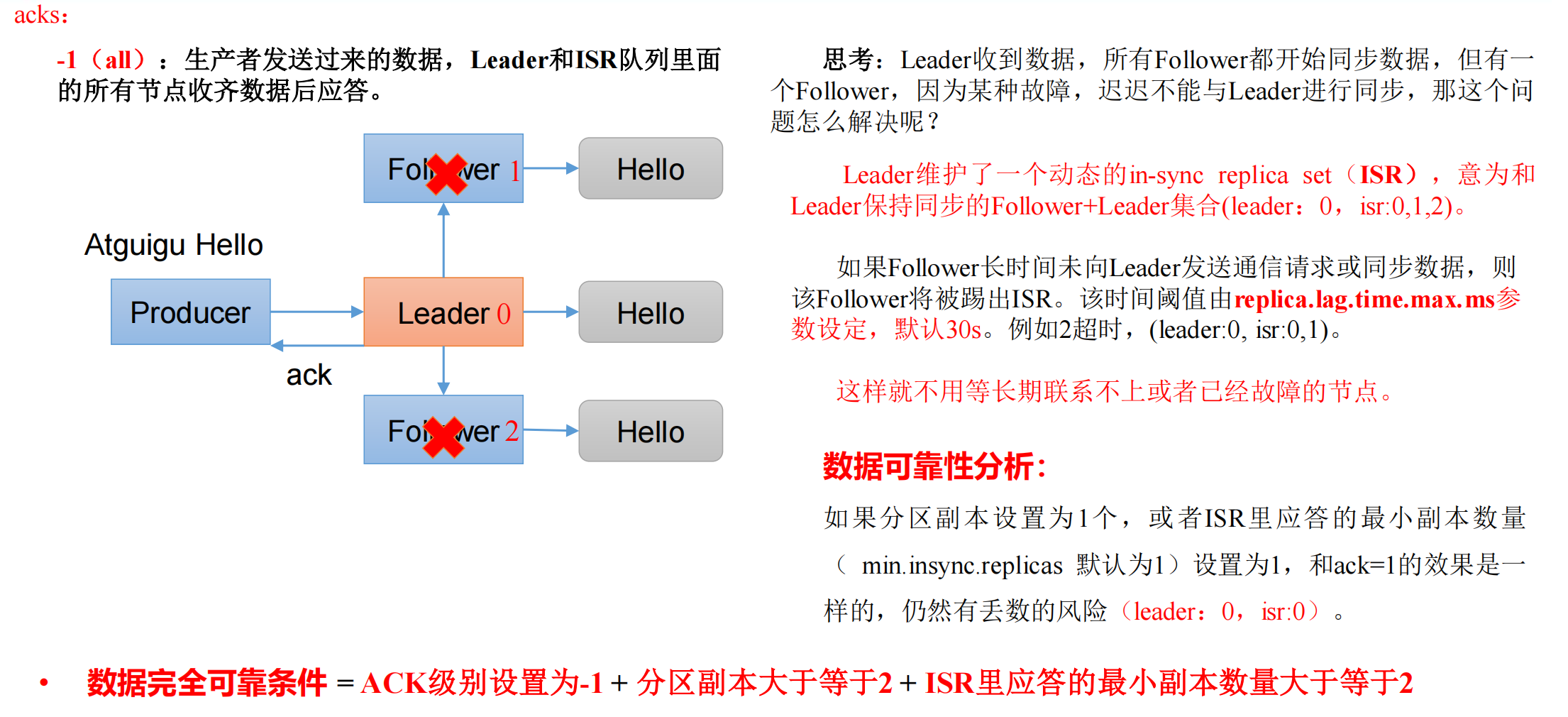
数据完全可靠条件 = ACK 级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
注意,这里的“副本”并不是指的 Follower;在 Kafka 中,副本分为 Leader 副本和 Follower 副本。Leader 副本负责处理消息,而 Follower 副本则简单地复制 Leader 副本的数据。
也就是一个分区至少要有 1 个 Leader 和 1 个 Follower,ISR 队列最少也要有 1 个 Leader 和 1 个 Follower。
一个分区至少有 1 个 Leader,所以每个 Partition 都会有一个 ISR,而且是由 Leader 动态维护。
可靠性总结
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据 Leader 应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据 Leader 和 ISR 队列里面所有 Follwer 应答,可靠性高,效率低;
- 在生产环境中, - acks=0,很少使用;- acks=1,一般用于传输普通日志,允许丢个别数据;- acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
代码实现
// 设置 acks=-1
properties.put(ProducerConfig.ACKS_CONFIG,"all");// 重试次数 retries,默认是 int 最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG,3);
拓展:
生产者将数据发送给 Leader,并且完成同步给 Follower,此时回复 ack 时,Leader 挂了,kafka 会挑一个 Follower 成为新的 Leader,因为生产者没有收到 ack,此时就会认为他的数据没有发送到 kafka,就会进行重试,导致新 Leader 重复接收了两份数据。
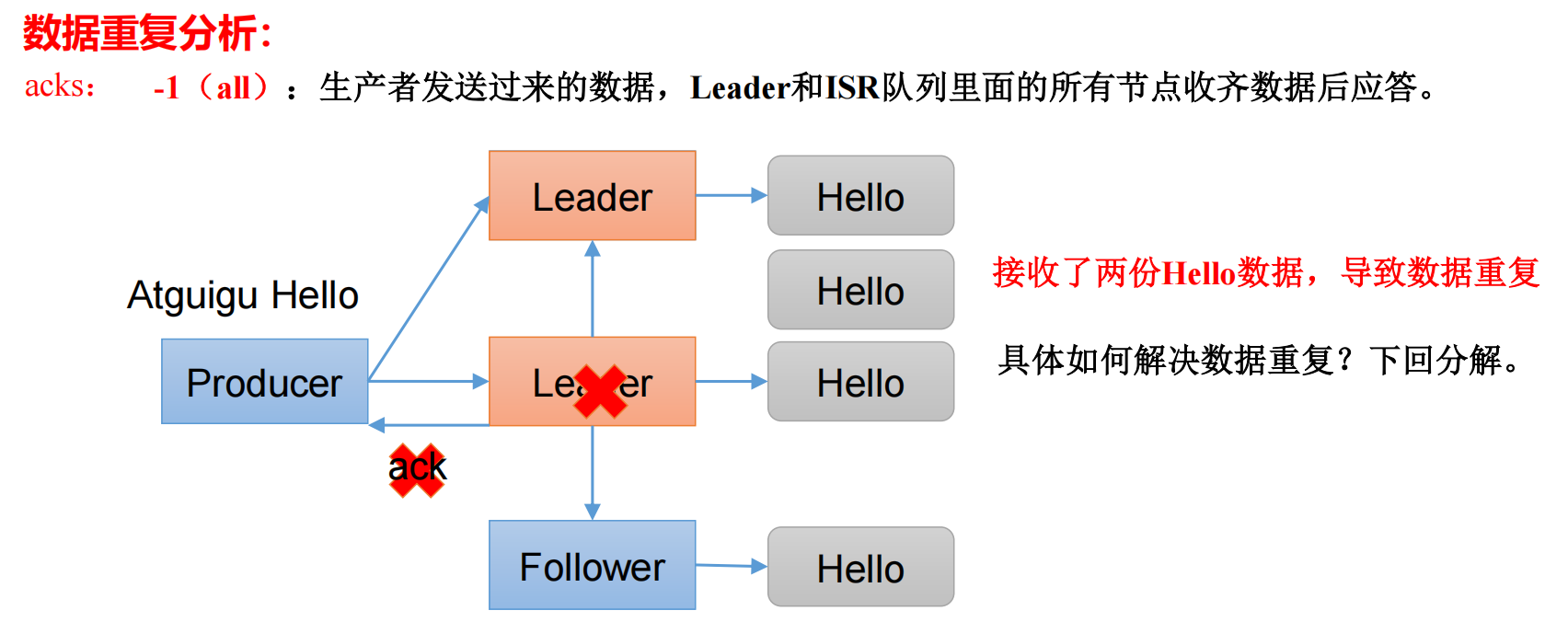
生产经验—数据去重
数据传递语义

幂等性
幂等性原理
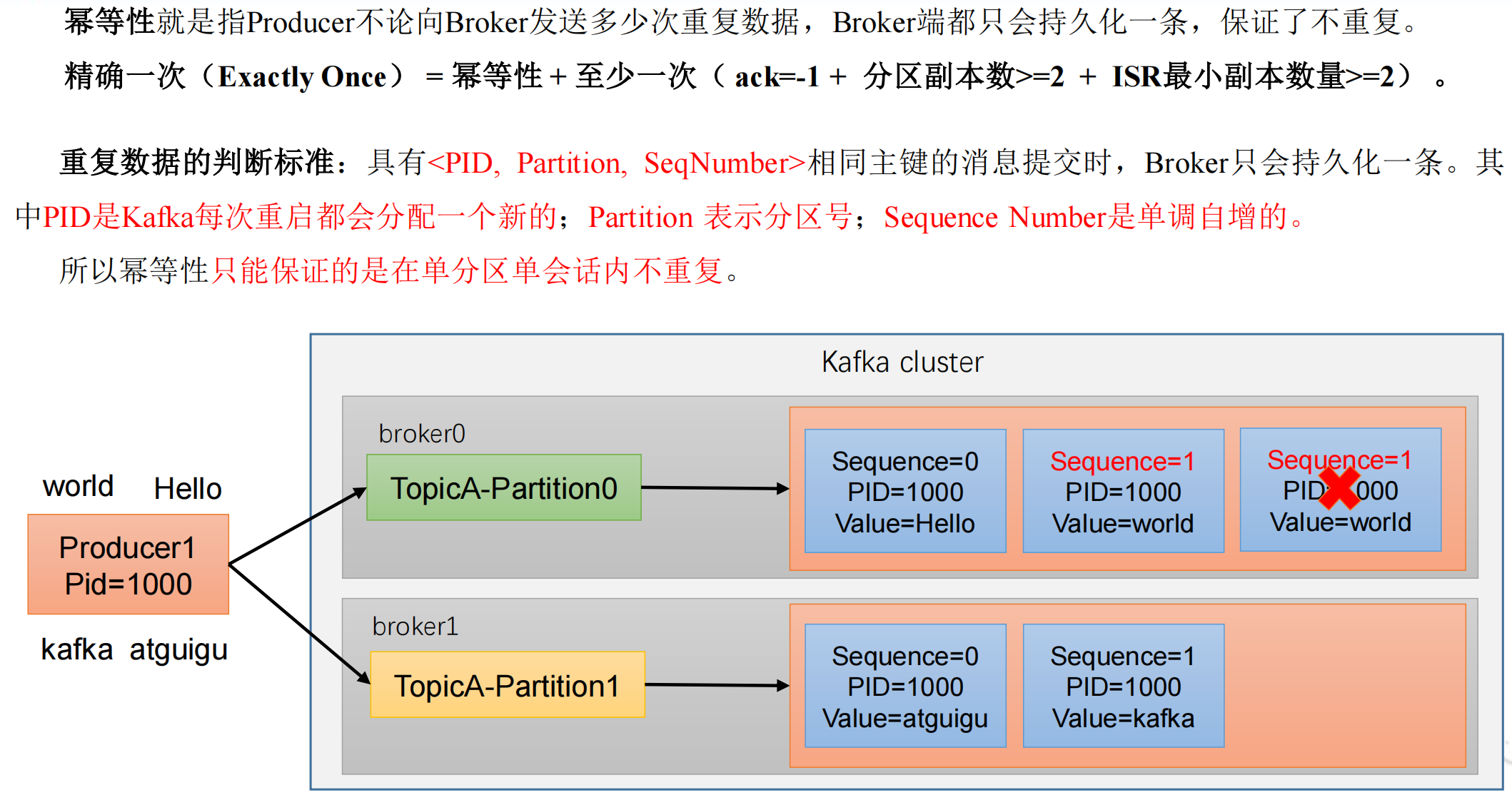
如何使用幂等性
开启参数
enable.idempotence
,默认为
true
(默认开启)。
生产者事务
幂等性只能保证单分区单会话的不重复,一旦 kafka 挂掉重启,还是有可能产生重复数据。如果想完全去重,就必须使用事务。
Kafka 事务原理
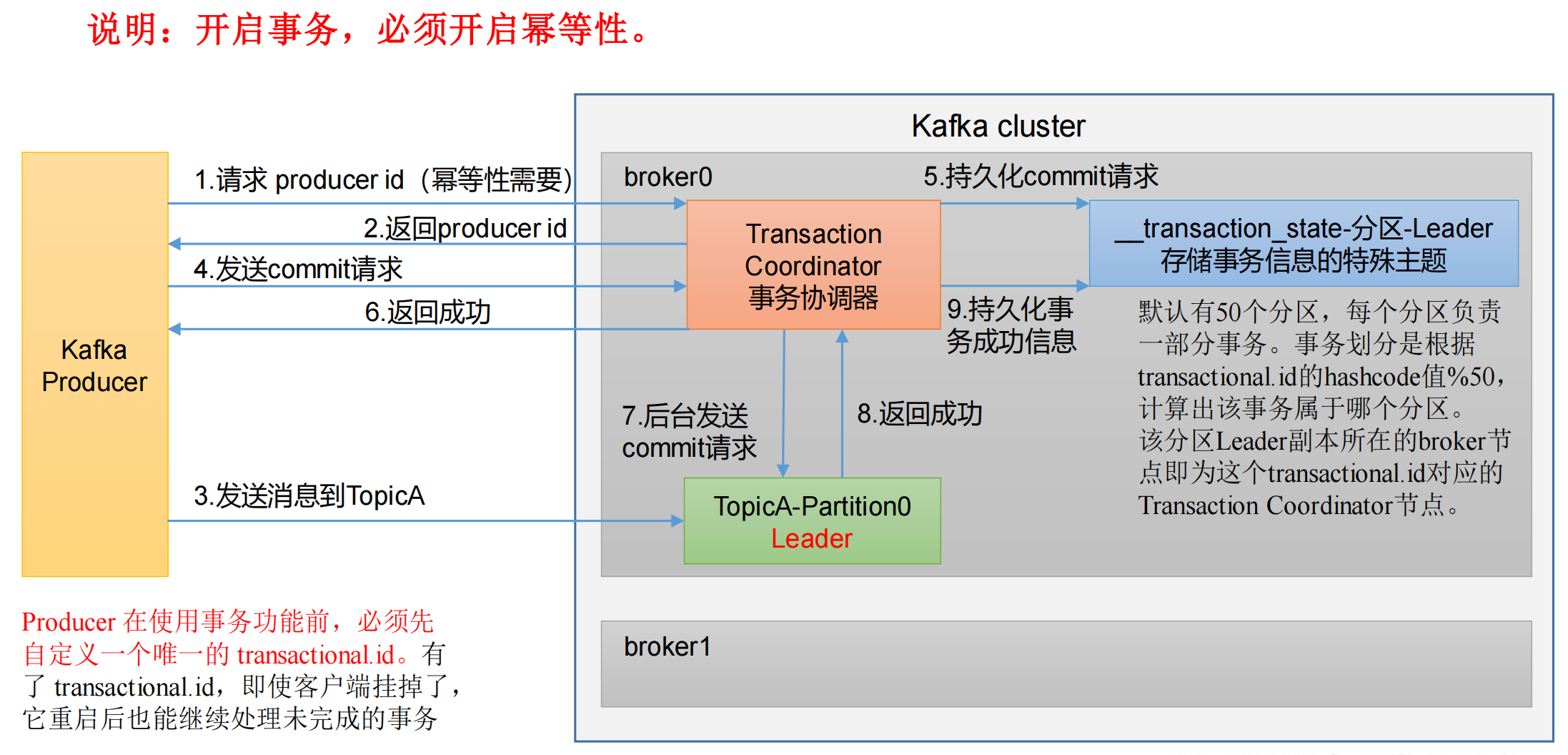
- 幂等性:如果 kafka 挂掉重启,会重新生成一个 PID,所以可能会有重复。
- 事务:kafka 根据全局唯一的
transactional.id会划分到50个分区中的某一个分区,这些分区的信息是存储在一个特殊 Topic 里的,而 Topic 的底层就是硬盘,所以即使客户端挂掉了,重启后也能继续处理未完成的事务,因为有transactional.id存在。
Kafka 的事务一共有如下 5 个 API:
// 1. 初始化事务voidinitTransactions();// 2. 开启事务voidbeginTransaction()throwsProducerFencedException;// 3. 在事务内提交已经消费的偏移量(主要用于消费者)voidsendOffsetsToTransaction(Map<TopicPartition,OffsetAndMetadata> offsets,String consumerGroupId)throwsProducerFencedException;// 4. 提交事务voidcommitTransaction()throwsProducerFencedException;// 5. 放弃事务(类似于回滚事务的操作)voidabortTransaction()throwsProducerFencedException;
单个 Producer,使用事务保证消息的仅一次发送:
importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Properties;publicclassCustomProducerTransactions{publicstaticvoidmain(String[] args){// 1. 创建 kafka 生产者的配置对象Properties properties =newProperties();// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 设置事务 id(必须),事务 id 任意起名,要求全局唯一
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaction_id_0");// 3. 创建 kafka 生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<>(properties);// 初始化事务
kafkaProducer.initTransactions();// 开启事务
kafkaProducer.beginTransaction();try{// 4. 调用 send 方法,发送消息for(int i =0; i <5; i++){// 发送消息
kafkaProducer.send(newProducerRecord<>("first","atguigu "+ i));}// int i = 1 / 0;// 提交事务
kafkaProducer.commitTransaction();}catch(Exception e){// 终止事务
kafkaProducer.abortTransaction();}finally{// 5. 关闭资源
kafkaProducer.close();}}}
生产经验—数据有序
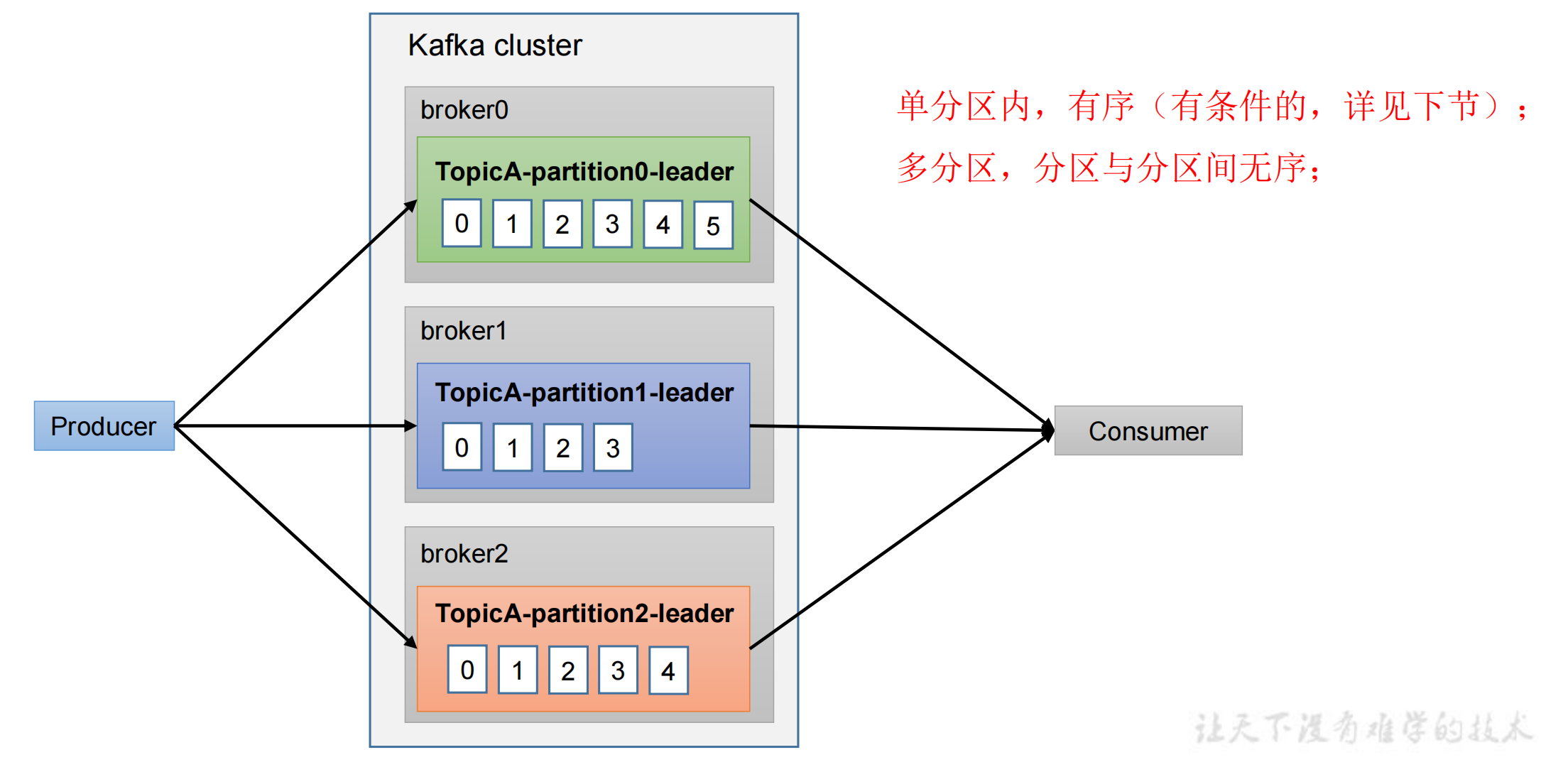
仅能保证单分区内有序,如果想保证全局有序,只能把所有分区的消息都拉到消费者端,进行一个全排序,再进行消费。
但需要等所有数据到齐了再进行排序,效率可能还不如单分区。
生产经验—数据乱序
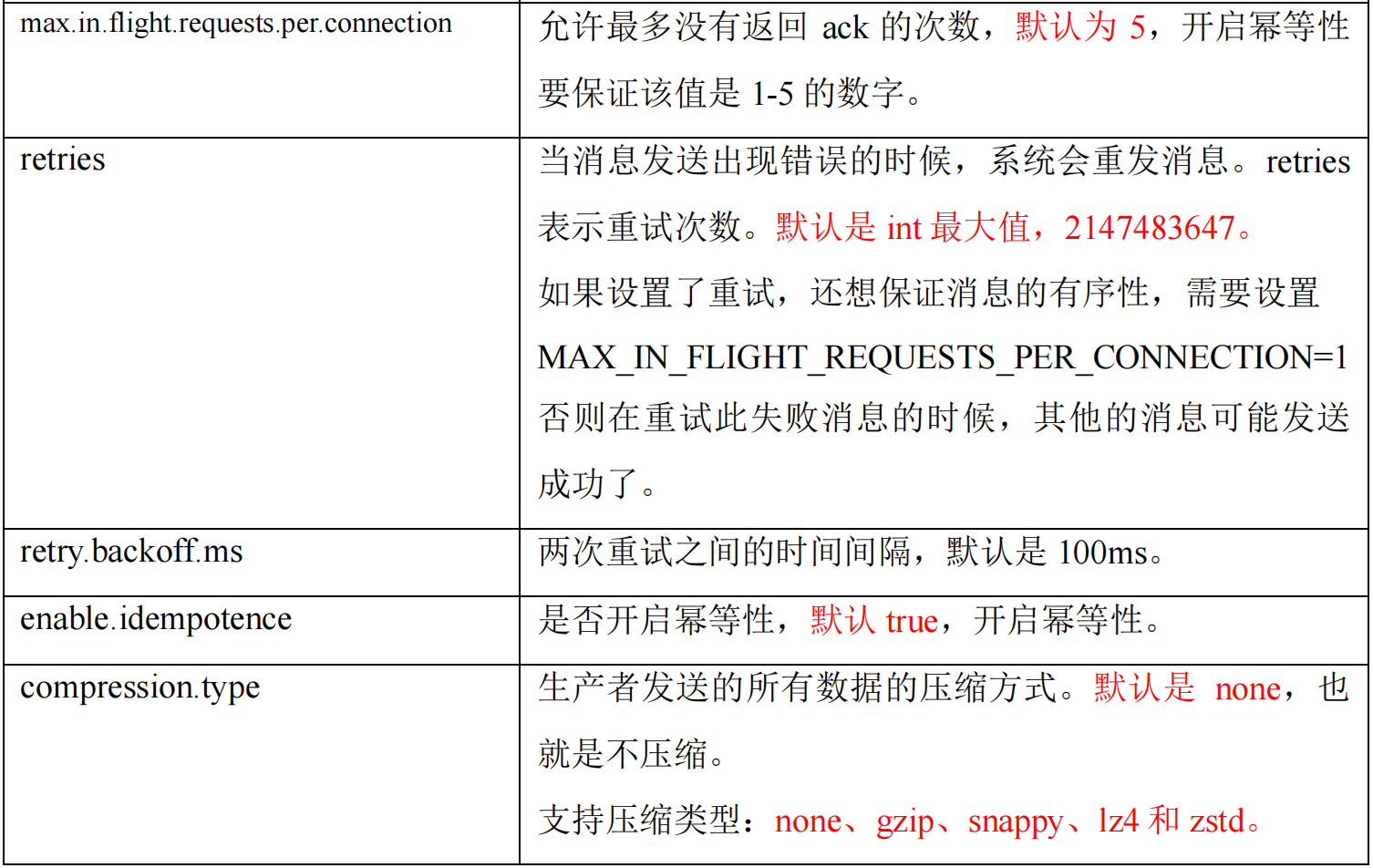
一个 broker 可以有一个 broker 缓存队列,队列中存放的是还未收到 ack 的请求,最多能存放 5 个。
比如发送 Request1 后,对方没有应答,此时还可以发送 Request2、Request3、Request4、Request5,最多能发送 5 次请求。
假设在一个分区中,生产者发送了 Request1、Request2 请求都成功了,但 Request3 请求发送失败了,进行重试,但此时 Request4 请求发送成功了,然后 Request3 请求才发送成功,此时到达 kafka 的顺序就为 1 2 4 3,是乱序的。
- kafka在1.x版本之前保证数据单分区有序,条件如下: -
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。 - 也就是 broker 的缓存队列只允许有 1 个请求,这个请求收到 ack 后才能发送下一个。 - kafka在1.x及以后版本保证数据单分区有序,条件如下: - 开启幂等性 -
max.in.flight.requests.per.connection需要设置小于等于5。- 未开启幂等性 -max.in.flight.requests.per.connection需要设置为1(和kafka在1.x版本之前一样)。
原因说明:因为在 kafka1.x 以后,启用幂等后,kafka 服务端最多会缓存
producer
发来的最近
5
个
request
的元数据。
故无论如何,都可以保证最近
5
个
request
的数据都是有序的。
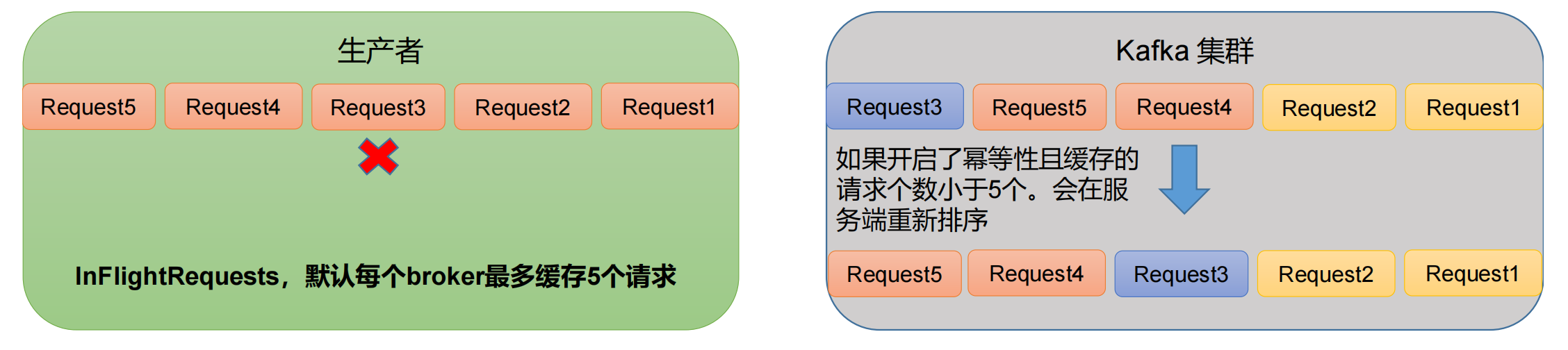
- 比如先来的 Request1、Request2,服务端根据
SeqNumber判断数据是否是单调递增的,如果符合则直接进行落盘; - 但下一个请求是 Request4,正常应该是 Request3,所以 Request4 这个请求只能在内存中放着,不能进行落盘;
- 再下一个是 Request5,同样不能进行落盘;
- 直到 Request3 来了,然后对他们进行排序,然后再依次落盘 Request3、Request4、Request5。
笔记整理自b站尚硅谷视频教程:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
版权归原作者 小成同学_ 所有, 如有侵权,请联系我们删除。