
文章目录
前言
在前面的内容中我们已经把查询的基本操作介绍的差不多了,接下来我们就要介绍一些更加复杂的查询操作
1、新增
这里的新增是插入和查询的结合,可以把一个表查询的结果,插入到另一个表中
创建一个学生表:
mysql>insertinto student values(1,'张三','男'),(2,'李四','男'),(3,'王五','女');
Query OK,3rows affected (0.02 sec)
Records: 3 Duplicates: 0Warnings: 0
mysql>select*from student;+------+--------+--------+| id | name | gender |+------+--------+--------+|1| 张三 | 男 ||2| 李四 | 男 ||3| 王五 | 女 |+------+--------+--------+3rowsinset(0.00 sec)
创建一个学生表2:
mysql>createtable student2(id int, name varchar(20));
Query OK,0rows affected (0.02 sec)
把学生表的id和name插入到学生表2中:
mysql>insertinto student2 select id, name from student;
Query OK,3rows affected (0.00 sec)
Records: 3 Duplicates: 0Warnings: 0
mysql>select*from student2;+------+--------+| id | name |+------+--------+|1| 张三 ||2| 李四 ||3| 王五 |+------+--------+3rowsinset(0.00 sec)
把数据从student中查询出来,然后插入到student2中
这里需要确保,查询到的结果集合的列/类型,要和待插入表的列数类型匹配
2、聚合查询
2.1聚合函数
函数说明COUNT([DISTINCT] expr)返回查询到的数据的数量SUM([DISTINCT] expr)返回查询到的数据的总和,不是数字没有意义AVG([DISTINCT] expr)返回查询到的数据的平均值,不是数字没有意义MAX([DISTINCT] expr)返回查询到的数据的最小值,不是数字没有意义MIN([DISTINCT] expr)返回查询到的数据的最小值,不是数字没有意义
上述的聚合函数只能针对数字,接下来我们针对下面这张表演示上述的聚合函数
mysql>select*from exam_result;+------+-----------+---------+------+---------+| id | name | chinese | math | english |+------+-----------+---------+------+---------+|1| 唐三藏 |87.0|98.0|56.0||2| 孙悟空 |87.0|80.0|77.0||3| 猪悟能 |88.0|98.0|90.0||4| 曹孟德 |82.0|84.0|67.0||5| 刘玄德 |55.0|85.0|45.0||6| 孙权 |60.0|70.0|80.0||7| 宋公明 |75.0|65.0|30.0||8| 诸葛亮 |90.0|85.0|66.0|+------+-----------+---------+------+---------+8rowsinset(0.01 sec)
2.1.1count
mysql>selectcount(*)from exam_result;+----------+|count(*)|+----------+|8|+----------+1rowinset(0.02 sec)
此处查询的结果表示在这张表中有多少行
当前这个写法,就想当于先执行select * from exam_result,再对结果进行count聚合
这里的 * 也可以写具体的列,如果写具体的列/表达式,就是针对这一列查询,在进行聚合
mysql>selectcount(chinese)from exam_result;+----------------+|count(chinese)|+----------------+|8|+----------------+1rowinset(0.00 sec)
针对某一列进行查询的时候,就要看这一列有多少个非NULL的结果,而select * 则不关注NULL
注意:使用聚合函数的函数名和括号之间,不能有空格
2.1.2sum
mysql>selectsum(chinese+math+english)from exam_result;+---------------------------+|sum(chinese+math+english)|+---------------------------+|1800.0|+---------------------------+1rowinset(0.00 sec)
先把每一行的语文数学英语累加再把所有的行进行累加
如果针对非数值的列进行相加,虽然没有报错但是结果是不正确的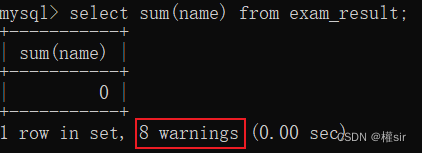
2.1.3avg
mysql>selectavg(chinese)from exam_result;+--------------+|avg(chinese)|+--------------+|78.00000|+--------------+1rowinset(0.00 sec)
2.1.4max和min
mysql>selectmax(chinese)from exam_result;+--------------+|max(chinese)|+--------------+|90.0|+--------------+1rowinset(0.01 sec)
mysql>selectmin(chinese)from exam_result;+--------------+|min(chinese)|+--------------+|55.0|+--------------+1rowinset(0.00 sec)
上述的聚合函数也可以搭配一些条件来进行查询
2.2、GROUP BY子句
指定某个列,针对这个列把值相同的行,分到同一组中,可以针对每个组,分别进行聚合查询
这里我们创建一张工资表emp:
createtable emp(id int,
name varchar(20),
role varchar(20),
salary int);insertinto emp values(1,'张三','开发',13000),(2,'李四','开发',12000),(3,'王五','开发',11000),(4,'赵六','测试',12000),(5,'田七','测试',13000),(6,'周八','产品',10000),(7,'雷军','老板',10000000);
查询每个岗位有多少人:
mysql>select role,count(id)from emp groupby role;+--------+-----------+| role |count(id)|+--------+-----------+| 产品 |1|| 开发 |3|| 测试 |2|| 老板 |1|+--------+-----------+4rowsinset(0.00 sec)
执行过程:
1.先执行select role, id from emp
2.再根据group by role 设定,按照role这一列的值,针对上述查询结果,进行分组
3.针对上述的每个组,分别执行count聚合操作,再把结果整理成临时表,返回给客户端
2.3HAVING
我们还可以给聚合查询指定条件
1.聚合之前的条件
查询每个岗位的平均工资,但是要刨出张三:
mysql>select role,avg(salary)from emp where name !='张三'groupby role;+--------+---------------+| role |avg(salary)|+--------+---------------+| 产品 |10000.0000|| 开发 |11500.0000|| 测试 |12500.0000|| 老板 |10000000.0000|+--------+---------------+4rowsinset(0.00 sec)
先筛选,再分组计算出每个组的平均工资
2.聚合之后的条件:
查询每个岗位的平均工资,但是刨出平均工资超过 2w的数据:
mysql>select role,avg(salary)from emp groupby role havingavg(salary)<20000;+--------+-------------+| role |avg(salary)|+--------+-------------+| 产品 |10000.0000|| 开发 |12000.0000|| 测试 |12500.0000|+--------+-------------+3rowsinset(0.00 sec)
先分组计算出每个组的工资之后,再进行上述条件筛选
3.分组前分组后都指定条件筛选(where和having结合使用)
计算出每个岗位的平均工资,刨出张三,也刨出平均工资超过2w的:
mysql>select role,avg(salary)from emp where name !='张三'groupby role havingavg(salary)<20000;+--------+-------------+| role |avg(salary)|+--------+-------------+| 产品 |10000.0000|| 开发 |11500.0000|| 测试 |12500.0000|+--------+-------------+3rowsinset(0.00 sec)
这种就是前面两种条件都存在
3、联合查询/多表查询
笛卡尔积是多表查询的基础,这是一种排列组合
多表联合查询的一般步骤:
1.确定要查的信息来自于哪几个表
2.把这些表进行笛卡尔积
3.指定连接条件
4.指定其他补充条件/聚合操作
5.针对列进行精简
这里我们用四张表来进行举例说明:
第一张班级表:
第二张学生表: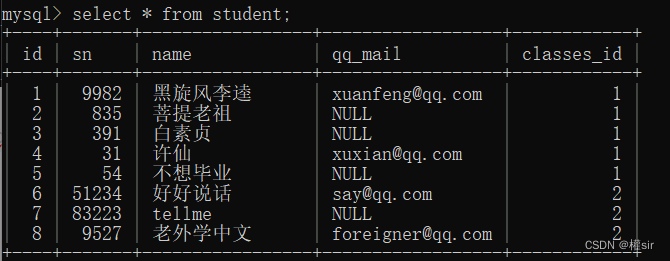
第三张课程表: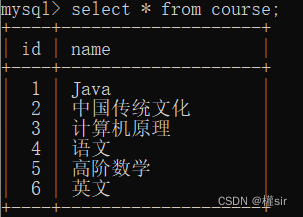
第四张成绩表: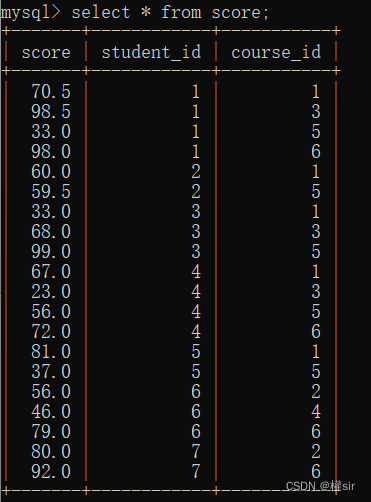
查询许仙同学的成绩:
1.这里要查询的来自学生表和成绩表
2.对这两个表进行笛卡尔积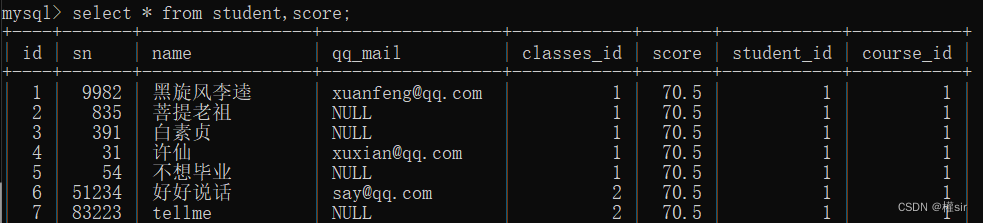
3.指定连接条件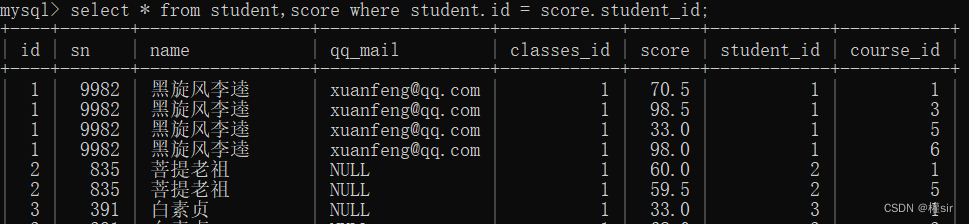
4.指定其他补充条件/聚合操作
5.针对列进行精简
多表查询还可以使用join on的方式来写
3.1内连接和外连接
上述的都是内连接,内连接的语法:
select*from 表一,表二 where 连接条件
select*from 表一 join 表二 on 连接条件
外连接和内连接一样,都是基于笛卡尔积的方式进行计算的,但是对于空值/不存在的值,处理方式是存在区别的
数据一一对应的情况下,使用内连接和外连接是一样的
外连接只能使用join on的方式写,可以在join的前面加上left(“左外连接”/right(“右外连接”)关键字
左外连接,以左侧的表为基准,保证左侧表中的每个数据一定会存在,左侧表数据在右侧表中不存在的部分(列),使用null填充
右外连接,以右侧的表为基准,保证右侧表中的每个数据一定会存在,右侧表数据在左侧表中不存在的部分(列),使用null填充
3.2自连接
同一个表中,自己和自己进行笛卡尔计算
自连接能够把行之间的关系转换成列之间的关系
3.3子查询
把多个sql语句嵌套成一个sql语句
单行子查询:返回一行记录的子查询
多行子查询:返回多行查询记录的子查询通过in
3.4合并查询
把多个查询到的结果集合,合并到一起
union:允许你从不同的多个表分别查询,只要每个表查询的结果集合列的类型和个数匹配都能合并,会去掉重复的行
union all:不会去掉重复的行
版权归原作者 權sir 所有, 如有侵权,请联系我们删除。