
前言
这段时间做了好几个关于年报的需求,其中无一例外需要从年报PDF中提取文本再进行下一步的操作。为了提高效率,对比分析了python中各种可以实现此功能的方法效率。
一、pdfplumber
简介:
- 可以为pdf文件插入文本字符、矩形和行的详细信息
- 对于非扫描格式pdf解析效果最佳
- 基于pdfminer.six构建
- 代码简洁,易于理解
安装:
pip install pdfplumber
示例:
import pdfplumber
def pdf2txt(pdf_path):
txt = ''
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
txt = txt + page.extract_text()
return txt
二、pdfminer
简介:
- 可以获取文本的提取位置以及其他布局信息
- 可将pdf转换为其他格式(HTML/XML)
- 支持基本的加密方式(RC4 and AES)
安装:
pip install pdfminer
示例:
from pdfminer.converter import TextConverter
from pdfminer.pdfdocument import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
def parsePDF(PDF_path):
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager,fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager,converter)
with open(PDF_path,'rb') as fh:
for page in PDFPage.get_pages(fh,caching=True,check_extractable=True):
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
converter.close()
fake_file_handle.close()
if text:
return text
三、fitz / pymupdf
简介:
- 支持多种格式
- 可以提取文字和图像
- 搜索文本
安装:
直接安装fitz会出现较多问题,建议安装pymupdf
pip install pymupdf
示例:
import fitz
def parsePDF(filePath):
with fitz.open(filePath) as doc:
text = ""
for page in doc.pages():
text += page.get_text()
if text:
return text
官方示例:
https://github.com/pymupdf/PyMuPDF/tree/master/tests
四、性能对比
使用以上三种方法对同一个PDF进行文本提取,分别记录提取文本结果的长度和运行时间,结果如下:
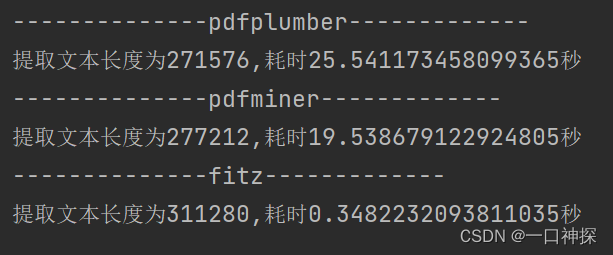
fitz提取出的文本长度不仅更长,耗时更是快了不止10倍!
可以说fitz在提取文本的性能方面完爆其他库,但是却很少有文章介绍这个库,有点奇怪。
下一篇文章将对比三种方法提取的文本精度,欢迎关注~
本文转载自: https://blog.csdn.net/Achernar0208/article/details/129199937
版权归原作者 一口神探 所有, 如有侵权,请联系我们删除。
版权归原作者 一口神探 所有, 如有侵权,请联系我们删除。