
1.系统环境
VMware-workstation:VMware-workstation-full-16.2.3
ubuntu:ubuntu-21.10
hadoop:hadoop2.7.2
mysql:mysql-connector-java-8.0.19
jdk:jdk-8u91-linux-x64.tar(注意要是linux版本的,因为是在linux系统中创建虚拟机)
hive:hive1.2.1
小技巧:
右键单击可以paste
2.创建虚拟机
1.选择典型即可

2.将ubuntu镜像文件导入:

3.用户名要记住,涉及到之后的文件路径:(推荐使用hadoop)

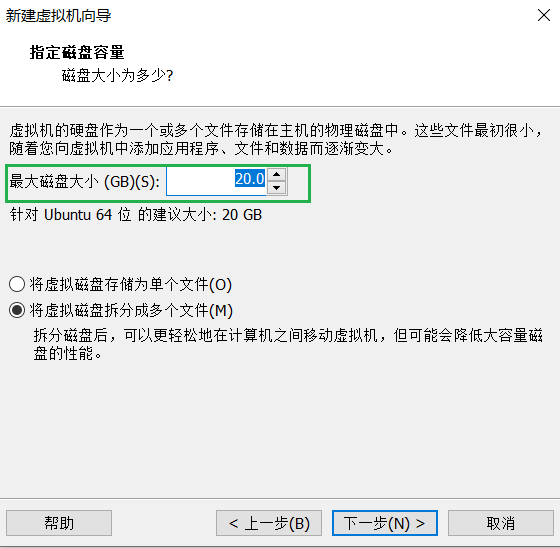
4.磁盘大小,选择默认的20GB就行,不要低于15GB,否则在远程连接的时候可能会出问题
5.进行克隆,生成子节点slave1,slave2......
要选择
完整克隆
克隆后的虚拟机密码和原虚拟机相同
3.修改虚拟机
修改hostname和主机名解析文件
步骤
sudo vi /etc/hostname
修改为自己虚拟机的名称即可:master,slave1等等
(需要重启才能生效)
第一次使用sudo需要输入密码,即创建虚拟机时的密码
sudo vi /etc/hosts
编辑主机名解析文件,填入对应的各节点地址和对应的主机名
把类似于下面格式的文本粘贴到原文件中(各个节点都要)
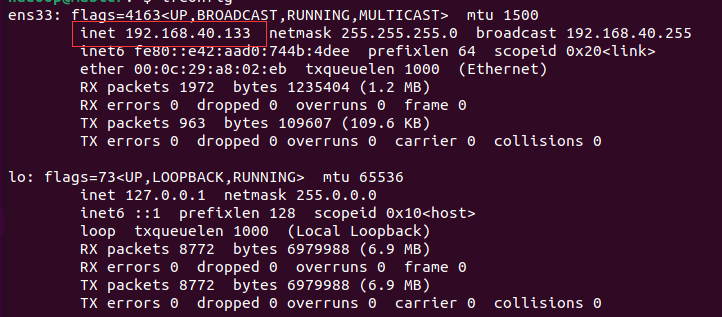
192.168.40.133 master
192.168.40.132 slave1
首先需要
ifconfig
查看当前的ip地址
如果显示
ifconfig
命令找不到,按照报错提示安装即可
问题
1.vim无法输入
原因:ubuntu默认安装的是vim-tiny版本,并没有老版本的vi编辑器,它是vim的最小化版本,只包含一小部分功能
可以到文件夹中看看文件,是不是下面这样:

如果是的话,重装一下vim即可
重装命令:
sudo apt-get remove vim-common
(卸载老版本)
sudo apt-get install vim
(安装新版本)
4.设置SSH
:查看是否安装ssh服务(一开始都是没安装的)ps -e|grep ssh
如果安装:

有sshd表示ssh-server已启动
:安装sshsudo apt-get install ssh
3.节点生成公钥、私钥对对:
ssh-keygen -t rsa
:生成
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
:导入公钥
cd .ssh
cat id_rsa.pub
:查看公钥
最终看到的应该是这样的:

这一步骤每个节点都需要执行
4.子节点向主节点传送密钥
scp .ssh/id_rsa.pub **hadoop**@master:/home/**hadoop**/id_rsa1.pub
(这里的hadoop就是创建虚拟机时填写用户名)
5.主节点设置免密码登录
cat **id_rsa1.pub** >> .ssh/authorized_keys
(这个就是子节点传过来的密钥)
6.主节点返回子节点:
scp .ssh/authorized_keys hadoop@**slave1**:/home/hadoop/.ssh/authorized_keys
(子节点的名称)
7.验证ssh免密码登录:
执行
ssh+hostname
(如
ssh master
)
验证是否能直接登录,而不需要输入密码
5.配置集群
1.创建以下文件夹
/home/hadoop/data/namenode
/home/hadoop/data/datanode
/home/hadoop/temp
(可以直接在文件夹中创建:

右键new即可)
2.Master上 hadoop路径下解压缩hadoop2.7.2和jdk1.8
压缩包如果不能直接拖到文件夹中,可以通过以下命令从windows系统中上传到虚拟机:
首先windows+R打开命令行
然后:
scp **E:\python+hive\hadoop-2.7.2.tar.gz****hadoop**@**192.168.40.133**:/home/hadoop
windows中文件的路径 用户名 主机ip
以hadoop为例,其他的压缩包类似
jdk传过来之后需要重命名为jdk1.8
3.解压gz文件:
tar zxvf hadoop-2.7.2.tar.gz
(以hadoop为例)
4.修改master的一些配置文件:
- 修改hadoop-env.sh 文件:
export HADOOP_PREFIX=/home/hadoop/hadoop-2.7.2(这个是新建的,原文件中没有)
export JAVA_HOME=/home/hadoop/jdk1.8
- 修改yarn-env.sh文件:
export JAVA_HOME=/home/hadoop/jdk1.8
- 下面是一些xml文件的配置
修改core-site.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/temp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
修改hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
修改yarn-site.xml文件:
<configuration>
<property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value></property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property><property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value></property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value></property>
<property> <name>yarn.resourcemanager.address</name>
<value>master:8032</value> </property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value></property>
<property><name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
以上直接复制粘贴即可
注意,configuration包裹的替换源文件中的configuration部分,不要替换多了,如果有的文件是.template格式的,直接重命名,把.template删除即可
6.修改环境变量:
sudo vi /etc/profile
:修改环境变量
export HADOOP_HOME=/home/hadoop/hadoop-2.7.2
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.2.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.2.jar:$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME=/home/hadoop/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
所有节点都要配置
直接CV即可
7.拷贝hadoop:
scp -r hadoop-2.7.2/ hadoop@slave1:/home/hadoop
:从主节点拷贝到其他节点
8.查看版本:
source /etc/profile
:可以使环境变量的配置即刻生效(否则需要重启虚拟机)
然后:
java –version
hadoop version
查看jdk和hadoop的版本
能找到对应的版本说明环境变量配置成功
9.启动集群
hdfs namenode -format
:格式化(只需配置一次即可)
start-all.sh
:启动hadoop集群

信息如上说明成功
集群启动到此结束
jps
:查看进程

能看到除去RunJar的其他进程,说明集群启动成功
6.安装hive
Mysql
1.安装MySQL(在master中)
sudo apt-get install mysql-server
:服务器
sudo apt-get install mysql-client
sudo apt-get install libmysqlclient-dev
:客户端
默认安装的是MySQL8,会自动生成一个密码
sudo cat /etc/mysql/debian.cnf
:查看初始密码:
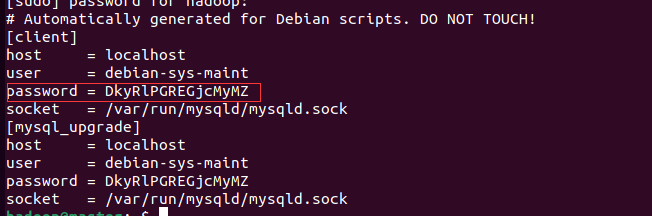
建议复制下来保存
2.修改配置文件:
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
将 bind-address = 127.0.0.1给注释掉

3.登录数据库:
mysql -u debian-sys-maint -p
:登录数据库,密码输入以上的默认密码
4.创建用户
create user 'hive'@'%' IDENTIFIED BY '123456';
grant all privileges on *.* to 'hive'@'%';
flush privileges;
依次执行,创建的数据库用户名是hive,密码是123456
Hive
5.上传apache-hive-1.2.1-bin.tar.gz,解压后重命名为hive-1.2.1
也是可以从windows传送
MySQL的驱动包mysql-connector-java-8.0.19.jar,将解压出来的jar放入hive 的lib目录下
版本可能不同
6.hive环境变量配置
sudo vi /etc/profile
export HIVE_HOME=/home/hadoop/hive-1.2.1
export PATH=$PATH:$HIVE_HOME/bin:$PATH
export CLASSPATH=$CLASSPATH:$HIVE_HOME/lib
所有节点都要配置
7.修改/conf/hive-env.sh文件
添加以下语句:
HADOOP_HOME=/home/hadoop/hadoop-2.7.2
export HIVE_CONF_DIR=/home/hadoop/hive-1.2.1/conf
如果是.template直接删除掉或者复制一份为.xml都行
template就只是一个模板而已
8.修改hive配置文件:
①执行以下命令,创建路径,用于HDFS存储:
hdfs dfs -mkdir -p /hive/warehouse
hdfs dfs -mkdir -p /hive/logs
hdfs dfs -mkdir -p /hive/tmp
hdfs dfs -chmod 733 /hive/warehouse
hdfs dfs -chmod 733 /hive/logs
hdfs dfs -chmod 733 /hive/tmp
查看是否成功:

②创建本地目录:
mkdir -p /home/hadoop/hive-1.2.1/hivedata/logs
③配置.xml文件:
cd /home/hadoop/hive-1.2.1/conf
:跳转到conf文件夹下
配置hive-site.xml:
cp hive-default.xml.template hive-site.xml:首先复制一份hive-site.xml
然后修改hive-site.xml
<property><name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/stock?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true</value></property>
<property><name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value></property>
<property><name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value></property>
<property><name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value></property>
<property><name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value></property>
<property><name>hive.exec.scratchdir</name><value>/hive/tmp</value>
</property>
<!--第六行的stock是数据库名,自己起;然后url后面的比较长,要复制全-->
配置log4j:
先复制出两个文件:
cp hive-exec-log4j.properties.template hive-exec-log4j.properties
cp hive-log4j.properties.template hive-log4j.properties
然后修改配置:
hive.log.dir=/home/hadoop/hive-1.2.1/logs
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
<!--两个文件(hive-exec-log4j.properties和hive-log4j.properties)中的都要修改-->
9.主节点hive启动:
schematool --dbType mysql -initSchema
:启动数据库
如果启动失败:
则可以通过
df -hl
查看当前内存的使用情况,如果内存太满:
尝试一下虚拟机-》右键打开设置-》找到硬盘-》扩展,增加容量-》重启虚拟机

再不好用就去网上搜报错信息吧
注意:只能启动一次

这样的报错信息意思是不能重复启动,对正常使用无影响
hive
:hive启动

这样就是启动成功
hive中的语句和mysql一样
通过
exit;
可以退出hive
10.远程连接配置(子节点slave1):
子节点配置:
①将master上的hive-1.2.1目录复制到其他节点上
scp -r hive-1.2.1/ hadoop@slave1:/home/hadoop
②修改hive-site.xml文件,删除如下的配置:
• javax.jdo.option.ConnectionURL
• javax.jdo.option.ConnectionDriverName
• javax.jdo.option.ConnectionUserName
• javax.jdo.option.ConnectionPassword
然后添加如下配置:
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.149.128:9083</value>、
</property>
<!--192.168.149.128是主机名,自己修改;9083是端口,不要动-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>**.**.**.**</value> <!--主机地址-->
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value> <!--端口使用默认的即可-->
</property>
远程连接配置到此结束
11.进行远程连接:
①
master启动metastore:
hive --service metastore &
&表示后台启动
执行
jps
可以看到其RunJar
子节点连接:执行
hive
即可
②
master启动hiveserver2 :
hive --service hiveserver2 &
子节点连接:执行
beeline -u jdbc:hive2://192.168.40.133:10000/stock1 -n root
即可
自己改主机地址和数据库名,端口10000不要动
上面两个服务器,可以同时开启,一般用第二个比较多
然后就可以在子节点进行hive的操作了
7.hive操作示例:
123
流程:建表-》整理数据-》数据加载到hive中-》JDBC连接hive取出数据
①建表语句:
create table fortest(time_ String,begin_ FLOAT,end_ FLOAT,low_ FLOAT,high_ FLOAT) row format delimited fields terminated by ',';
②数据格式:

不同的列以“,”分隔,多条数据之间以换行分隔
③加载数据:
LOAD DATA LOCAL INPATH "/home/hadoop/test.txt" INTO TABLE fortest;
需要先把.txt文件复制到虚拟机文件夹中,直接CV即可
④JDBC配置
需要导入的坐标:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
配置文件:
jdbc_driver=org.apache.hive.jdbc.HiveDriver
jdbc_url=jdbc:hive2://192.168.40.133:10000/stock1
jdbc_username=hive
jdbc_password=123456
版权归原作者 THE WHY 所有, 如有侵权,请联系我们删除。