
MapReduce是一个用于处理大数据集的编程模型和算法框架。其优势在于能够处理大量的数据,通过并行化来加速计算过程。它适用于那些可以分解为多个独立子任务的计算密集型作业,如文本处理、数据分析和大规模数据集的聚合等。然而,MapReduce也有其局限性,比如对于需要快速迭代的任务或者实时数据处理,MapReduce可能不是最佳选择。
总的来说,MapReduce是大数据技术中的一个重要概念,它在Hadoop生态系统中发挥着关键作用,特别是在处理大规模数据集时,它提供了一种可靠且高效的方法来并行处理数据。本篇我们来讲解一下MapReduce的相关内容。

一 MapReduce模型介绍
随着需要处理的数据量激增,我们开始借助分布式并行编程来提高程序的性能,分布式并行程序运行在大规模计算机集群上,可以并行执行大规模数据处理任务,从而获得海量计算的能力。
谷歌公司最先提了分布式并行模型MapReduce,hadoop MapReduce则是其的开源实现。但是在MapReduce出现之前,就已经有MPI一类的并行计算框架了,两者的区别主要在于:
传统并行计算框架MapReduce集群架构共享式(共享内存/共享存储)非共享式
容错性
容错性差容错性好价格贵相对较低硬件&扩展性刀片服务器+高速网+SAN,扩展性差普通PC机,扩展性好学习难度高低使用场景实时、细粒度、计算密集型批处理、非实时、数据密集型
可以看出,两者最大的区别在与其适用的场景不同,之前我们对于并行计算的要求更多注重计算密集型,而云计算则更注重对“大数据”的处理,因此传统的并行计算框架已经远远不能满足我们的需求了。
MapReduce的优点在于其易于编程、具有良好的扩展性以及高容错性,可以实现上千台服务器集群并发工作,提供数据处理能力。但同样的,MapReduce也不适合进行实时计算或流式计算。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数——map和reduce。通过MapReduce框架,我们不需要掌握分布式编程的细节,也能够容易的将自己的程序运行在分布式系统上。
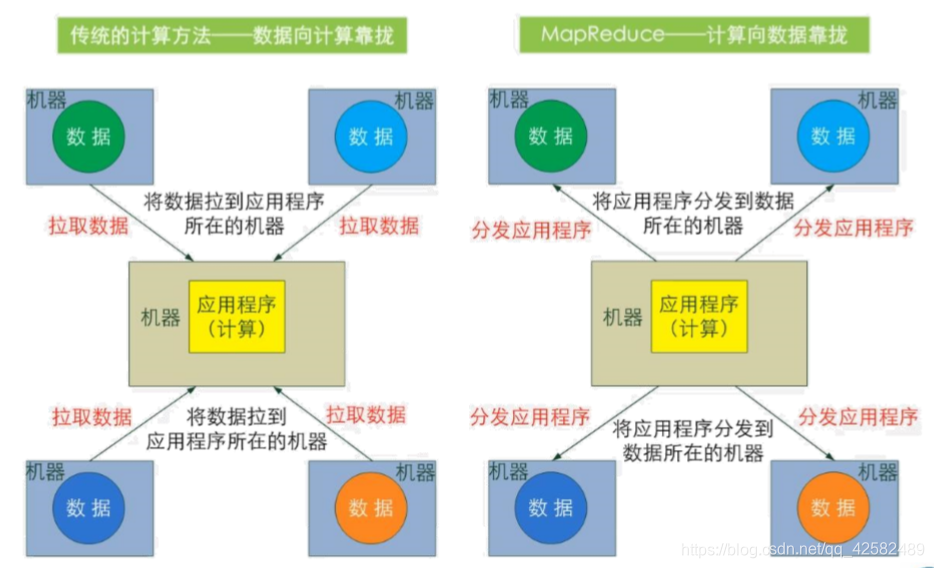
MapReduce的一个重要理念就是“计算向数据靠拢”,而不是传统的“数据向计算靠拢”。
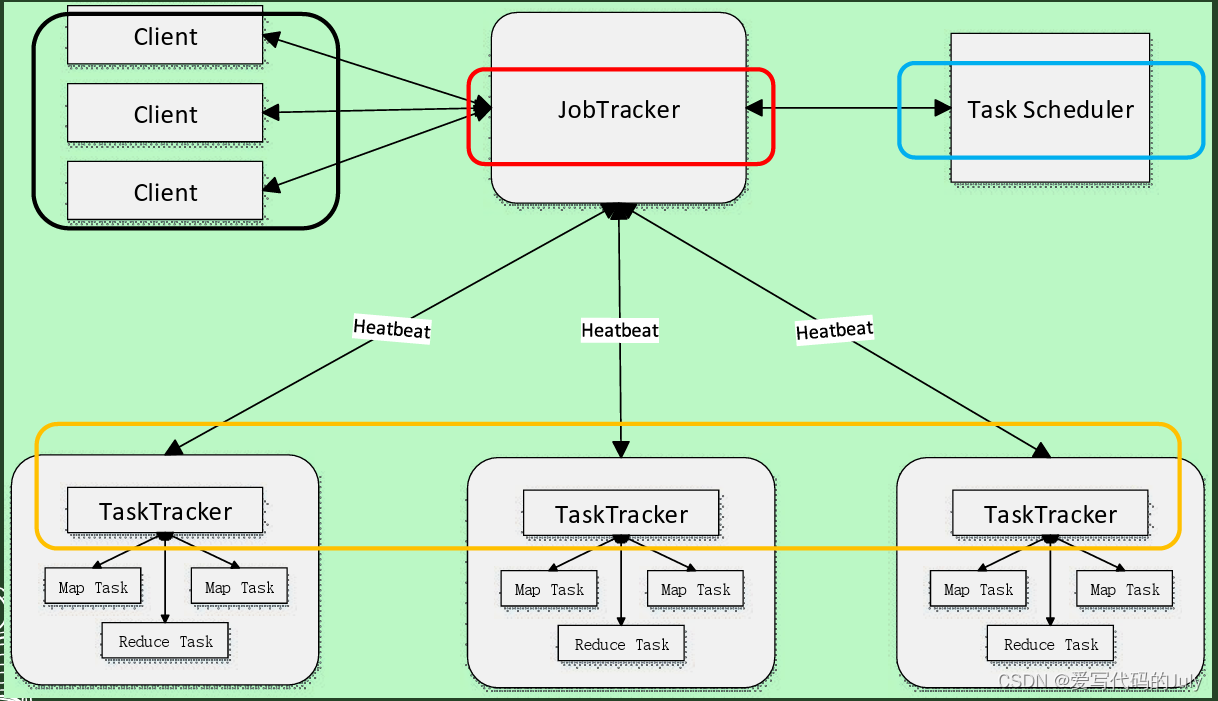
MapReduce框架采用了master/slave架构,包括一个master和若干个slave,master上运行作业跟踪器JobTracker,负责整个作业的调度和处理以及失败和恢复,slave上运行负责具体任务执行的组件TaskTracker,负责接受JobTracke发给它的作业处理指令,完成具体的任务处理。
map函数的输入为<k,v>键值对,每一个输入的<k,v>键值对会输出一批<k2,v2>中间结果。
reduce函数的输入为<k,list(v)>,输出为**<k,v>键值对**。list(v)表示一批属于同一个k的value。
二 MapReduce体系结构
MapReduce的体系结构包括:
- Client 客户端。
用户编写的MapReduce程序通过Client提交到JobTracker端 ,用户可通过Client提供的一些接口查看当前提交作业的运行状态。
- JobTracker 作业跟踪器。
JobTracker负责资源监控和作业调度。
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
JobTracker负责任务的调度,即将不同的Task分派到相应的TaskTracker中。
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息发送给TaskScheduler,而调度器会在资源出现空闲时, 选择合适的任务去使用这些资源
- TaskScheduler 任务调度器
负责任务的调度,即将不同的Task分派到相应的TaskTracker中。
- **TaskTracker **
TaskTracker会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等) 。
TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。 一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和 Reduce slot 两种,分别供MapTask 和Reduce Task 使用,两者不通用。
- **Task **
Task 分为Map Task 和Reduce Task 两种,在一台机器上可以同时运行两种任务,均由TaskTracker启动。
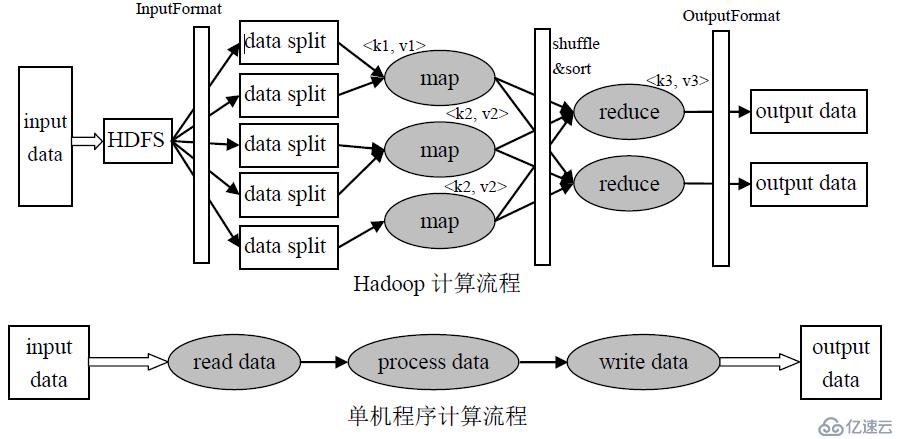
三 MapReduce工作流程
不同的map任务之间不会进行通信。
不同的Reduce任务之间不会发生任何信息交换。
用户不能显式地从一台机器向另一台机器发送消息。
所有的数据交换都是通过MapReduce框架自身去实现。
1) MapReduce 框架使用 InputFormat模块做Ma前的预处理,比如验证输入的格式是否符合输入定义;然后,将输入文件切分为逻辑上的多个 InputSplit。 InputSplit是 MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个 InputSplit并没有对文件进行实际切分,只是记录了要处理的数据的位置和长度
2)因为 InputSplit是逻辑切分而非物理切分,所以还需要通过 RecordReader(RR)根据InputSplit中的信息来处理 InputSplit中的具体记录,加载数据并将其转换为适合Map任务读取的键值对,输入给Map任务
3)Map任务会根据用户自定义的映射规则,输出一系列的<key,value>作为中间结果
4)为了让Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区(Partition)、排序(Sort)、合并(Combine)、归并(Merge)等操作,得到<key,value-list>形式的中间结果,再交给对应的Reduce来处理,这个过程称为Shuffle。
5)Reduce以一系列<key,value-list>中间结果作为输入,执行用户定义的逻辑,输出结果交给OutputFormat模块。
6)OutputFormat 模块会验证输出目录是否已经存在,以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出Reduce的结果到分布式文件系统。
本篇我们简单介绍了MapReduce模型及其工作流程,下面我们会借助章鱼大数据平台完成我们的第一个MapReduce练习,通过代码编写进一步理解MapReduce的原理及流程。
版权归原作者 爱写代码的July 所有, 如有侵权,请联系我们删除。