
文章目录
Kafka
Kafka是一个分布式流处理平台,它可以快速地处理大量的数据流。Kafka的核心原理是基于
发布/订阅
模式的消息队列。Kafka允许多个生产者将数据写入主题(topic)中,同时也允许多个消费者从主题中读取数据。
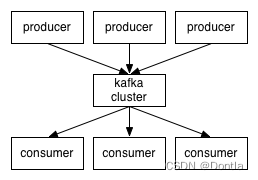
Kafka重要原理
Kafka的设计原则之一是高可用性和可扩展性,因此它可以处理大规模的数据流,并且可以在出现故障时快速恢复。这使得Kafka成为一种流行的数据处理工具,广泛应用于实时数据处理、日志收集、消息传递和其他数据管道场景中。
Topic 主题
Kafka的基本单位是主题(topic),它是一个逻辑概念,可以简单理解为一组相关的消息。生产者可以向一个或多个主题发布消息,消费者可以订阅一个或多个主题以获取数据。
Partition 分区
一个主题可以分成多个分区(partition),每个分区是一个有序的消息日志。每个分区都有一个唯一的标识符(partition ID),并且可以在多个节点上进行复制以提高可靠性。
Producer 生产者
生产者向主题发布消息。生产者可以选择将消息发布到指定的分区,也可以使用Kafka的分区器(partitioner)来决定将消息发布到哪个分区。
Consumer 消费者
消费者从主题订阅消息。消费者可以以消费者组(consumer group)的形式订阅主题,每个消费者组中的消费者共同消费主题中的所有分区。Kafka的消费者是分布式的,可以在多个节点上运行以提高可伸缩性和容错性。
Broker 中间件
Kafka集群中的每个节点都是一个Kafka Broker。每个Broker可以处理多个主题和分区,同时也可以作为生产者和消费者与其他Broker通信。
Offset 偏移量
每个消息在分区中都有一个唯一的偏移量(offset),用于标识消息在分区中的位置。消费者可以控制从哪个偏移量开始消费消息,这使得消费者可以在需要时重放消息或跳过一些消息。
Kafka与mqtt区别
Kafka和MQTT都是用于实时数据传输的消息中间件,但它们在设计和使用上有一些区别。
- 数据模型不同:Kafka以分布式的方式存储数据,数据按照主题分区存储,每个分区都有多个副本,可以通过分区键选择分区,消费者可以根据分区键并行消费数据。而MQTT是一种
发布/订阅模型,发布者将消息发布到主题,订阅者可以订阅感兴趣的主题并接收相关消息。 - 传输协议不同:Kafka使用TCP协议进行数据传输,而MQTT使用自定义的二进制协议进行数据传输。
- 数据保证机制不同:Kafka使用多副本机制保证数据的可靠性,每个分区都有多个副本,可以配置副本数和同步方式,保证数据不丢失和可靠性;而MQTT没有数据保证机制,如果消息发送失败或消费者没有收到消息,需要通过应用程序来实现重试等机制。
- 应用场景不同:Kafka适用于需要处理大量数据的实时应用场景,如流处理、日志处理、消息传递等;而MQTT适用于物联网、传感器网络、即时通讯等场景,需要支持大规模连接和消息传递。
总的来说,Kafka更加适合处理大规模的实时数据,具有高吞吐量、低延迟和高可靠性的特点,而MQTT适用于轻量级的实时数据传输,具有简单易用和广泛支持的特点。
版权归原作者 Dontla 所有, 如有侵权,请联系我们删除。