
文章目录
其它文章请参考
数据仓库系列:StarRocks 下一代高性能分析数据仓库的架构、数据存储及表设计
数据仓库系列:StarRocks的简单试用及与clickhouse的对比
数据仓库系列:如何将StarRocks集群与Jupyter集成?
1. 什么是StarRocks?
StarRocks 是一款MPP DB, 对标ClickHouse、Vertica、Teradata、Greenplum,在查询性能上远超当代最快的开源数据库 clickhouse,目前已经被一众互联网企业在生产环境中采用。
提供千亿级大数据的在线多维分析和分布式存储。
新一代极速全场景 MPP (Massively Parallel Processing) 数据库
是fork doris后独立运营的商业化版本StarRocks
可以认为是 MySQL 8.x的分布式版本,会用MySQL, 就会用StarRocks
1.1. 适用场景
StarRocks 可以满足企业级用户的多种分析需求,主要使用场景如下:
OLAP (Online Analytical Processing) 多维分析如自助式报表平台,用户行为分析实时数据仓库如电商大促数据分析、广告投放分析,支持针对数据更新高并发查询如如广告主报表分析统一分析- 通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。- 使用 StarRocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 StarRocks 中分析,也可以使用 External Catalog 和外部表进行数据湖上的分析。
详见适用场景
1.2. 产品特性
- MPP 分布式执行框架 在 MPP 框架中,数据会被 Shuffle 到多个节点,并且由多个节点来完成最后的汇总计算。在复杂计算时(比如高基数 Group By,大表 Join 等操作),StarRocks 的 MPP 框架相对于 Scatter-Gather 模式的产品有明显的性能优势
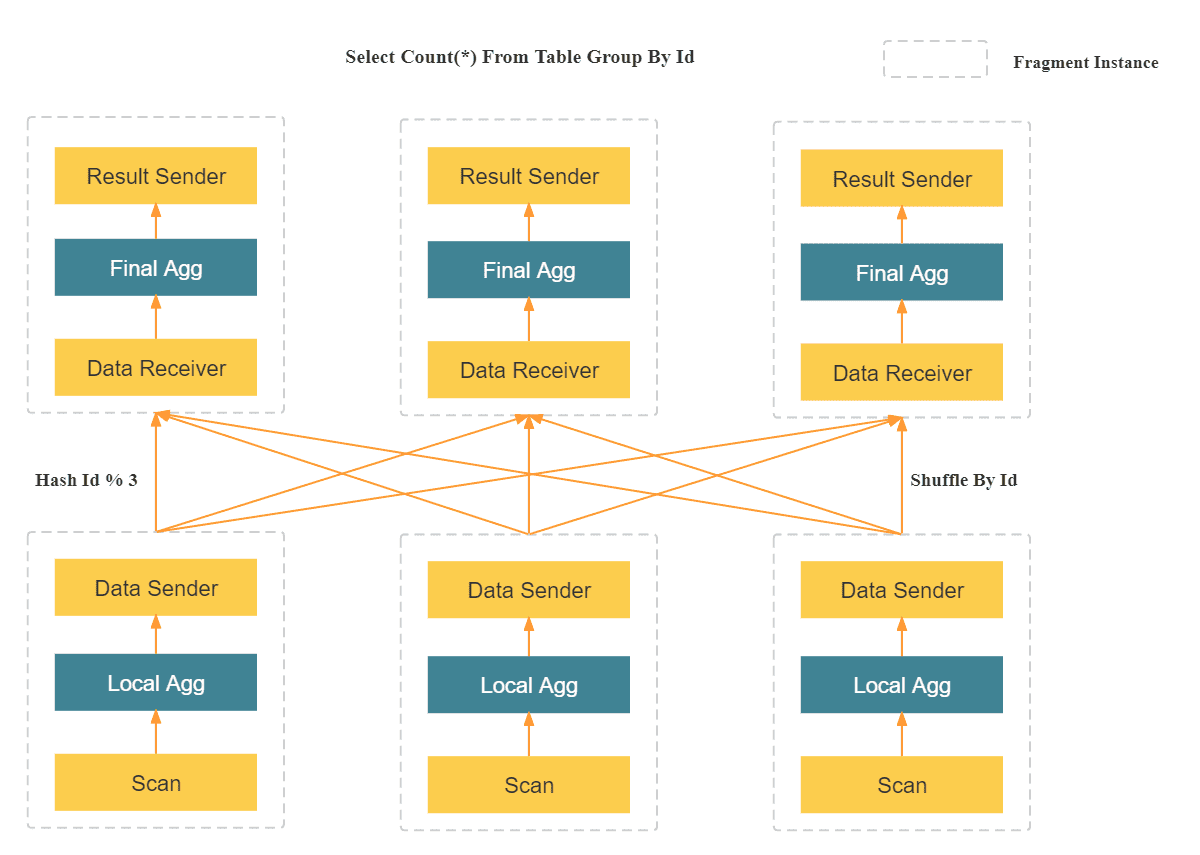
- 全面向量化 MPP 查询引擎: 充分发挥了 CPU 的处理能力,同时支持极速的单表和多表查询性能
- CBO 优化器: 支持极速的秒级 AdHoc 查询
- 可实时更新的列式存储引擎: 具备极致的实时更新和查询性能
- 全新设计的数据分布模式,具备高并发查询能力, 可以支持每秒上万次的并发查询能力。
- 智能的物化视图: 使用物化视图(materialized view)进行查询加速和数仓分层, 具备灵活透明的预计算加速能力
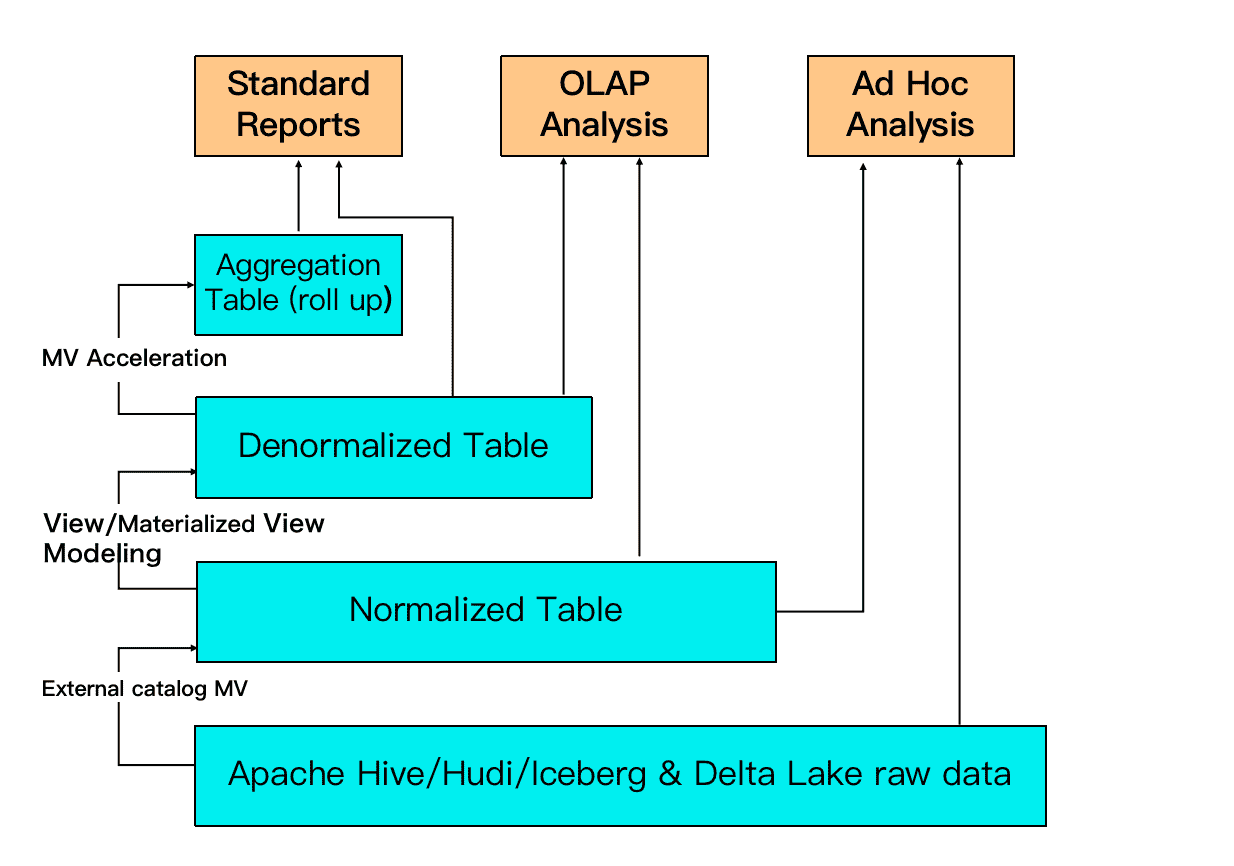
- 数据湖分析: StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护【类似于spark作为查询分析引擎】
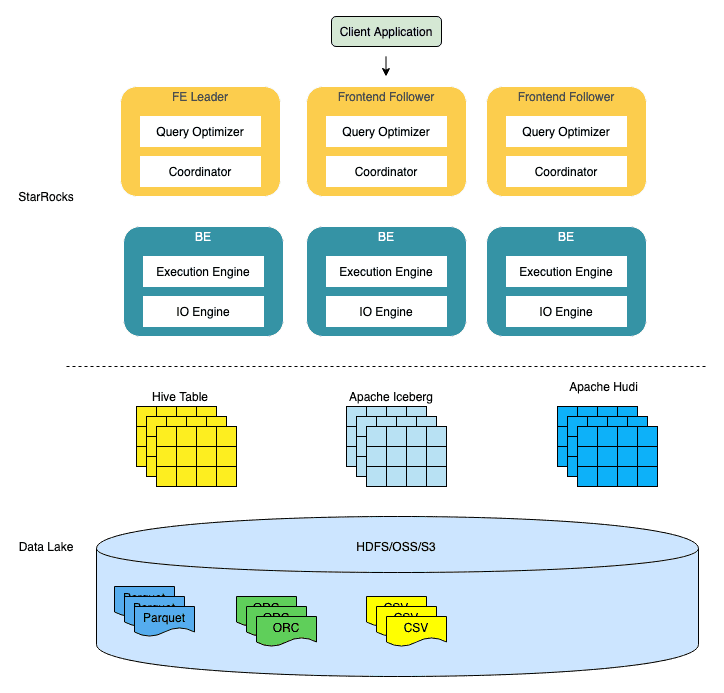
2. 系统架构
2.1. 系统架构
2.1.1. 整体架构
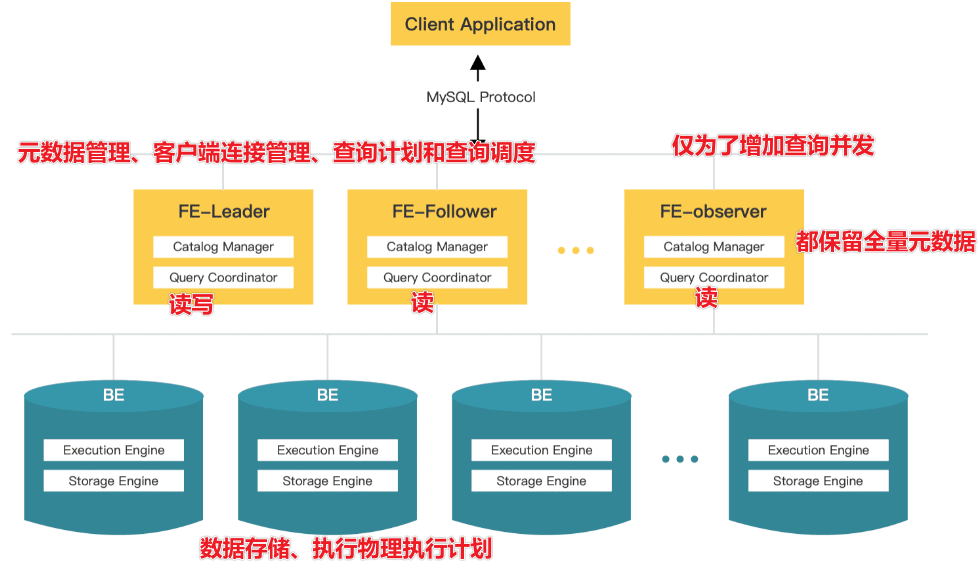
StarRocks 架构简洁,整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护
StarRocks 的整体架构如下图:
- FE(Frontend)前端节点: 多个FE组成第一层,提供FE的
横向扩展和高可用。 - 负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。- 每个 FE 节点都会在内存保留一份完整的元数据,这样每个 FE 节点都能够提供无差别的服务 - BE(Backend)后端节点: 多个BE组成第二层 - 负责数据存储与管理、查询计划执行等工作
- FE 和 BE 模块都可以在线水平扩展,元数据和业务数据都有副本机制,确保整个系统无单点
- StarRocks 提供 MySQL 协议接口,支持标准 SQL 语法
2.1.2. 高可用实现方式
FE 有三种角色:Leader FE,Follower FE 和 Observer FE。Follower 会通过类 Paxos 的 Berkeley DB Java Edition(BDBJE)协议自动选举出一个 Leader
- Leader - Leader 从 Follower 中自动选出,进行选主需要集群中有半数以上的 Follower 节点存活。如果 Leader 节点失败,Follower 会发起新一轮选举。- Leader FE 提供元数据读写服务。只有 Leader 节点会对元数据进行写操作,Follower 和 Observer 只有读取权限。Follower 和 Observer 将元数据写入请求路由到 Leader 节点,Leader 更新完数据后,会通过 BDB JE 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。
- Follower - 只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。- 参与 Leader 选举,必须有半数以上的 Follower 节点存活才能进行选主。
- Observer - 主要用于扩展集群的查询并发能力,可选部署。- 不参与选主,不会增加集群的选主压力。- 通过回放 Leader 的元数据日志来异步同步数据。
2.2. 数据如何管理?
StarRocks 使用列式存储,采用分区分桶机制进行数据管理。
表按照日期划分为 4 个分区,第一个分区进一步切分成 4 个 Tablet。每个 Tablet 使用 3 副本进行备份,分布在 3 个不同的 BE 节点上。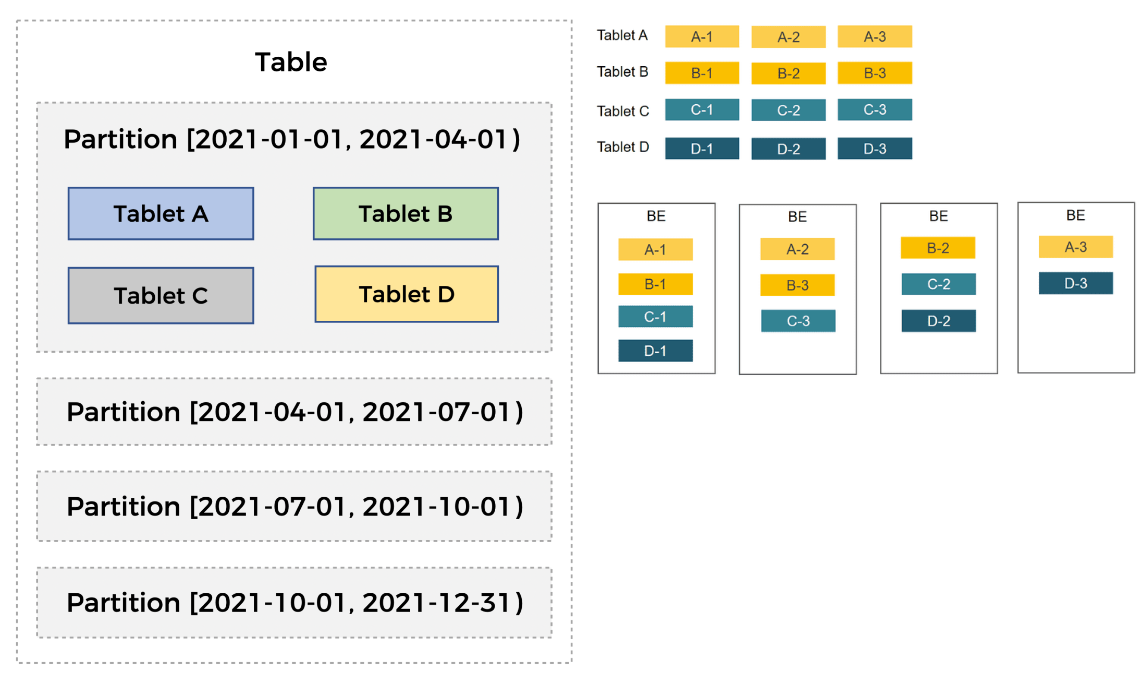
- 一张表被切分成了多个 Tablet,StarRocks 在执行 SQL 语句时,可以对所有 Tablet 实现并发处理,从而充分的利用多机、多核提供的计算能力
- Tablet 的分布方式与具体的物理节点没有相关性。在 BE 节点规模发生变化时,比如在扩容、缩容时,StarRocks 可以做到无需停止服务,直接完成节点的增减。节点的变化会触发 Tablet 的自动迁移
- 支持 Tablet 多副本存储,默认副本数为三个。多副本能够保证数据存储的高可靠以及服务的高可用。
相关的SQL语句
-- 建表SQLCREATETABLEIFNOTEXISTS sr_member (
sr_id INT,
name STRING,
city_code INT,
reg_date DATE,
verified BOOLEAN)PARTITIONBY RANGE(reg_date)(START("2021-01-01")END("2021-12-31") EVERY (INTERVAL3MONTH))DISTRIBUTEDBYHASH(city_code) BUCKETS 4
PROPERTIES("replication_num"="1");-- 查看表分区showpartitionfrom test.sr_member;-- 查看tabletshow tablet from test.sr_member;
3. 表模型
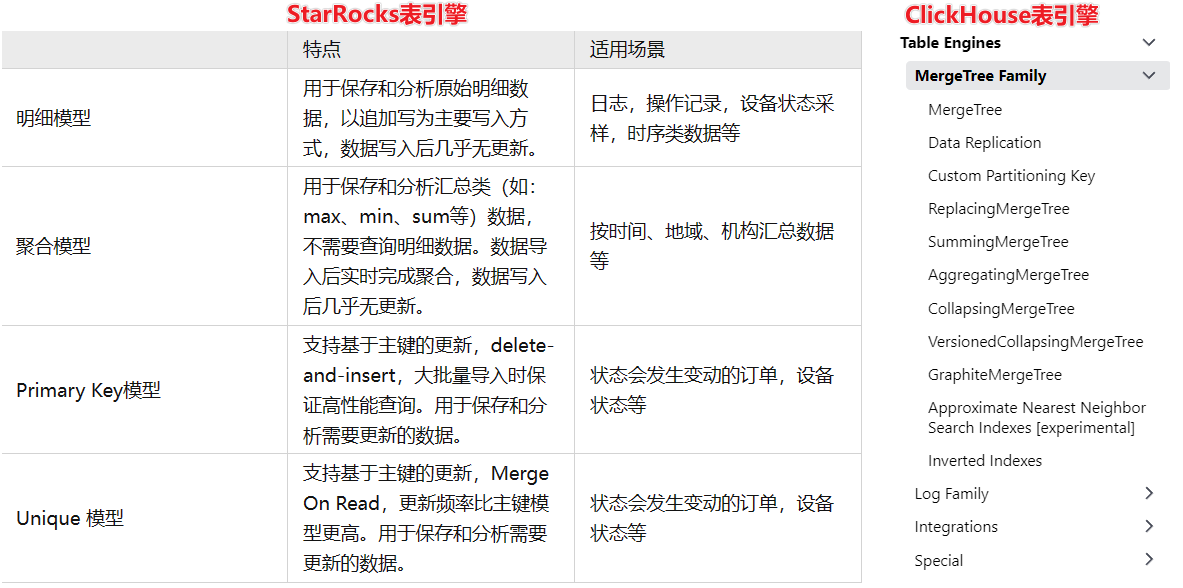
3.1. 明细模型
适用场景
- 分析原始数据,例如原始日志、原始操作记录等。
- 查询方式灵活,不需要局限于预聚合的分析方式。
- 导入日志数据或者时序数据,主要特点是旧数据不会更新,只会追加新的数据。
建表示例
CREATETABLEIFNOTEXISTS detail (
event_time DATETIMENOTNULLCOMMENT"datetime of event",
event_type INTNOTNULLCOMMENT"type of event",
user_id INTCOMMENT"id of user",
device_code INTCOMMENT"device code",
channel INTCOMMENT"")DUPLICATEKEY(event_time, event_type)DISTRIBUTEDBYHASH(user_id) BUCKETS 8
PROPERTIES("replication_num"="1");
注意事项:
- 排序键的相关说明: - 在建表语句中,排序键必须定义在其他列之前。- 排序键可以通过
DUPLICATE KEY显式定义。本示例中排序键为event_time和event_type。 如果未指定,则默认选择表的前三列作为排序键。- 明细模型中的排序键可以为部分或全部维度列。 - 建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
- 建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键, 也可以不指定(自 2.5.7 版本起,会自动设置分桶数量 (BUCKETS))
3.2. 聚合模型
适用场景:数据统计和分析场景
- 大多数查询是聚合查询,例如SUM、COUNT和MAX。
- 不需要检索原始的详细数据。
- 历史数据不经常更新。只追加新数据。
建表示例
CREATETABLEIFNOTEXISTS example_db.aggregate_tbl (
site_id LARGEINT NOTNULLCOMMENT"id of site",dateDATENOTNULLCOMMENT"time of event",
city_code VARCHAR(20)COMMENT"city_code of user",
pv BIGINT SUM DEFAULT"0"COMMENT"total page views")
AGGREGATE KEY(site_id,date, city_code)DISTRIBUTEDBYHASH(site_id) BUCKETS 8
PROPERTIES ("replication_num"="1");
注意事项:
- 排序键的相关说明 - 在建表语句中,排序键必须定义在其他列之前。- 如果 AGGREGATE KEY 未包含全部维度列(除指标列之外的列),则建表会失败。- 如果不通过 AGGREGATE KEY 显示定义排序键,则默认除指标列之外的列均为排序键。- 排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。
- 在运行查询时,排序键在多版聚合之前就能进行过滤,而指标列的过滤在多版本聚合之后
- 建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引
- 将数据加载到使用聚合键模型的表中时,只能更新表的所有列
3.3. 更新模型
适用场景
- 需要实时和频繁更新数据的业务场景,如在电子商务场景中,每天可以下数亿个订单,订单状态经常变化
建表示例
CREATETABLEIFNOTEXISTS orders (
create_time DATENOTNULLCOMMENT"create time of an order",
order_id BIGINTNOTNULLCOMMENT"id of an order",
order_state INTCOMMENT"state of an order",
total_price BIGINTCOMMENT"price of an order")UNIQUEKEY(create_time, order_id)DISTRIBUTEDBYHASH(order_id) BUCKETS 8
PROPERTIES ("replication_num"="1");
注意事项:
- 主键的相关说明: - 在建表语句中,主键必须定义在其他列之前。- 主键通过
UNIQUE KEY定义。- 主键必须满足唯一性约束,且列的值不会修改。- 设置合理的主键。 - 查询时,主键在聚合之前就能进行过滤,而指标列的过滤通常在多版本聚合之后,因此建议将频繁使用的过滤字段作为主键,在聚合前就能过滤数据,从而提升查询性能。- 聚合过程中会比较所有主键,因此需要避免设置过多的主键,以免降低查询性能。如果某个列只是偶尔会作为查询中的过滤条件,则不建议放在主键中。 - 建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
3.4. 主键模型
适用场景: 适用于实时和频繁更新的场景
- 实时对接事务型数据至 StarRocks
- 利用部分列更新轻松实现多流 JOIN
建表示例
createtable orders (
dt dateNOTNULL,
order_id bigintNOTNULL,
user_id intNOTNULL,
merchant_id intNOTNULL,
good_id intNOTNULL,
good_name string NOTNULL,
price intNOTNULL,
cnt intNOTNULL,
revenue intNOTNULL,
state tinyintNOTNULL)PRIMARYKEY(dt, order_id)PARTITIONBY RANGE(`dt`)(PARTITION p20210820 VALUES[('2021-08-20'),('2021-08-21')),PARTITION p20210821 VALUES[('2021-08-21'),('2021-08-22')),PARTITION p20210929 VALUES[('2021-09-29'),('2021-09-30')),PARTITION p20210930 VALUES[('2021-09-30'),('2021-10-01')))DISTRIBUTEDBYHASH(order_id) BUCKETS 4
PROPERTIES("replication_num"="1","enable_persistent_index"="true");createtable users (
user_id bigintNOTNULL,
name string NOTNULL,
email string NULL,
address string NULL,
age tinyintNULL,
sex tinyintNULL,
last_active datetime,
property0 tinyintNOTNULL)PRIMARYKEY(user_id)DISTRIBUTEDBYHASH(user_id) BUCKETS 4
PROPERTIES("replication_num"="1","enable_persistent_index"="true");
注意事项:
- 主键相关的说明: - 在建表语句中,主键必须定义在其他列之前。- 主键通过
PRIMARY KEY定义。- 主键必须满足唯一性约束,且列的值不会修改。本示例中主键为dt、order_id。- 主键支持以下数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。- 分区列和分桶列必须在主键中。- 合理设置主键的列数和长度。建议主键为占用内存空间较少的数据类型,例如 INT、BIGINT 等,暂时不建议为 VARCHAR。 - the memory occupied by the primary key index 的计算公式: (主键长度+9) x 记录数量 x 副本数 x 1.5 = 占用内存大小 - 9是每行不可变的开销,- 1.5是每个哈希表的平均额外开销
- enable_persistent_index:主键索引可以持久化到磁盘并存储在内存中,以避免占用太多内存。
4. 数据导入导出
4.1. 数据导入
- 所有导入方式都提供原子性保证,即同一个导入作业内的所有有效数据要么全部生效,要么全部不生效,不会出现仅导入部分数据的情况。
- 通过导入作业实现数据导入。每个导入作业都有一个标签 (Label),由用户指定或系统自动生成,用于标识该导入作业
- 提供两种访问协议用于提交导入作业:MySQL 协议和 HTTP 协议
详见用法参见: 导入总览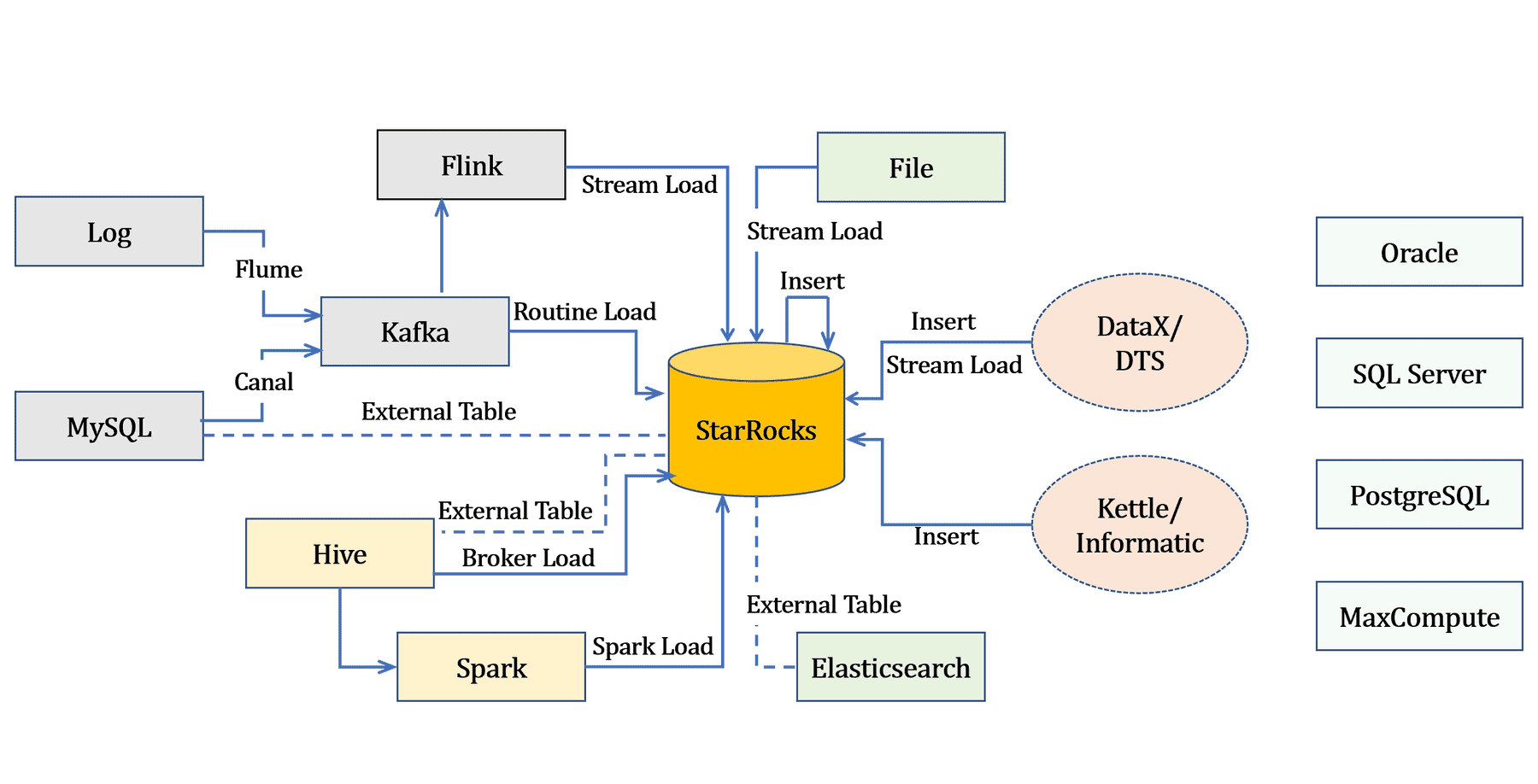
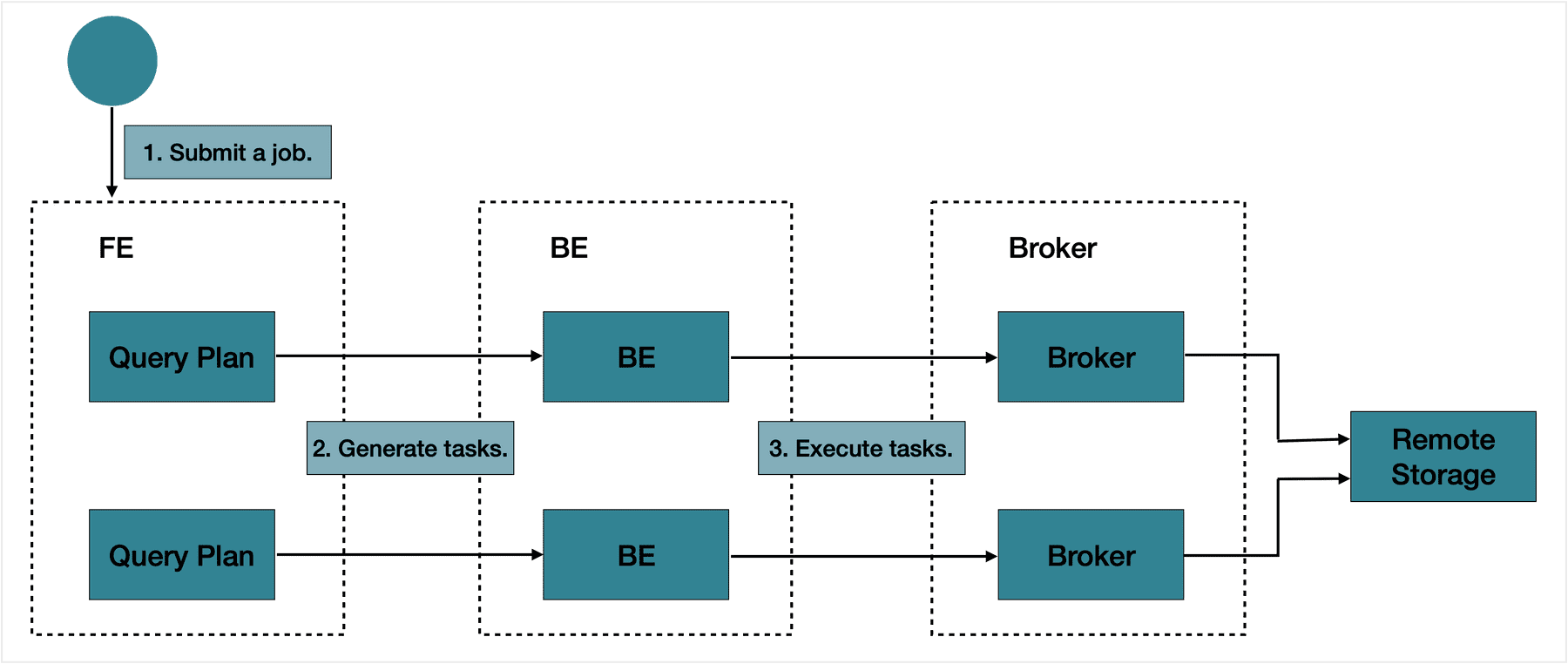
4.2. 导出数据
导出使用详见EXPORT,
注意:
- 导出路径需要各个BE节点都可以访问,不能是本地路径
- 目前支持HDFS及对象存储,如 - Alibaba Cloud OSS- Tencent Cloud COS- AWS S3- Huawei Cloud OBS
 导出示例SQL
导出示例SQL
EXPORT TABLE db1.tbl1
PARTITION(p1,p2)(col1, col3)TO"hdfs://HDFS_IP:HDFS_Port/export/lineorder_"
PROPERTIES
("column_separator"=",","load_mem_limit"="2147483648","timeout"="3600")WITH BROKER
("username"="user","password"="passwd");
5. 使用 Catalog 管理和查询内外部数据
5.1. Catalog
外部数据:指保存在外部数据源(如 Apache Hive™、Apache Iceberg、Apache Hudi、Delta Lake、JDBC)中的数据。
通过Catalog不需要执行数据导入就可以直接查询
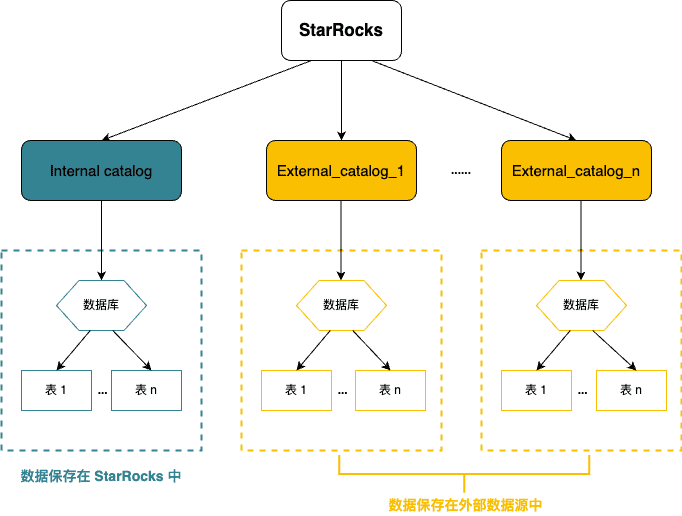
External catalog: 外部数据目录,用于连接外部 metastore。在 StarRocks 中,您可以通过 external catalog 直接查询外部数据,无需进行数据导入或迁移。当前支持创建以下类型的 external catalog:
- Hive catalog:用于查询 Hive 数据。
- 数据湖 - Iceberg catalog:用于查询 Iceberg 数据。- Hudi catalog:用于查询 Hudi 数据。- Delta Lake catalog:用于查询 Delta Lake 数据。
- JDBC catalog:用于查询 JDBC 数据源的数据。
CREATE EXTERNAL CATALOG jdbc0
PROPERTIES
("type"="jdbc","user"="postgres","password"="changeme","jdbc_uri"="jdbc:postgresql://127.0.0.1:5432/jdbc_test","driver_url"="https://repo1.maven.org/maven2/org/postgresql/postgresql/42.3.3/postgresql-42.3.3.jar","driver_class"="org.postgresql.Driver");CREATE EXTERNAL CATALOG jdbc1
PROPERTIES
("type"="jdbc","user"="root","password"="changeme","jdbc_uri"="jdbc:mysql://127.0.0.1:3306","driver_url"="https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.28/mysql-connector-java-8.0.28.jar","driver_class"="com.mysql.cj.jdbc.Driver");
5.2. 外部表
StarRocks 支持以
外部表 (External Table)
的形式,接入其他数据源。外部表指的是保存在其他数据源中的数据表,而 StartRocks 只保存表对应的元数据,并直接向外部表所在数据源发起查询。
目前 StarRocks 已支持的第三方数据源包括
- MySQL、
- StarRocks、
- Elasticsearch、
- Apache Hive™、
- Apache Iceberg
- Apache Hudi。
对于 StarRocks 数据源,现阶段只支持 Insert 写入,不支持读取,对于其他数据源,现阶段只支持读取,还不支持写入。
CREATE EXTERNAL TABLE mysql_external_table
(
k1 DATE,
k2 INT,
k3 SMALLINT,
k4 VARCHAR(2048),
k5 DATETIME)ENGINE=mysql
PROPERTIES
("host"="127.0.0.1","port"="3306","user"="mysql_user","password"="mysql_passwd","database"="mysql_db_test","table"="mysql_table_test");
5.3. 文件外部表
文件外部表 (File External Table) 是一种特殊的外部表。您可以通过文件外部表直接查询外部存储系统上的 Parquet 和 ORC 格式的数据文件,无需导入数据。同时,文件外部表也不依赖任何 Metastore。StarRocks 当前支持的外部存储系统包括 HDFS、Amazon S3 及其他兼容 S3 协议的对象存储、阿里云对象存储 OSS 和腾讯云对象存储 COS。
USE db_example;CREATE EXTERNAL TABLE table_1
(
name string,
id int)ENGINE=file
PROPERTIES
("path"="s3://bucket-test/folder1/","format"="orc","aws.s3.use_instance_profile"="true","aws.s3.iam_role_arn"="arn:aws:iam::51234343412:role/role_name_in_aws_iam","aws.s3.region"="us-west-2");
6. 物化视图
6.1. 同步物化视图
同步物化视图下,所有对于基表的数据变更都会自动同步更新到物化视图中。您无需手动调用刷新命令,即可实现自动同步刷新物化视图。同步物化视图的管理成本和更新成本都比较低,适合实时场景下单表聚合查询的透明加速。
6.2. 异步物化视图
相较于同步物化视图,异步物化视图支持多表关联以及更加丰富的聚合算子。异步物化视图可以通过手动调用或定时任务的方式刷新,并且支持刷新部分分区,可以大幅降低刷新成本。除此之外,异步物化视图支持多种查询改写场景,实现自动、透明查询加速。
** 单表聚合多表关联查询改写刷新策略基表*StarRocks 2.5 异步物化视图是是是异步定时刷新手动刷新支持多表构建。基表可以来自:Default CatalogExternal Catalog已有异步物化视图*StarRocks 2.4 异步物化视图是是否异步定时刷新手动刷新支持基于 Default Catalog 的多表构建同步物化视图(Rollup)**仅部分聚合算子否是导入同步刷新仅支持基于 Default Catalog 的单表构建
6.3. Colocate Join(大表关联)
Colocate Join 功能是分布式系统实现 Join 数据分布的策略之一,能够减少数据多节点分布时 Join 操作引起的数据移动和网络传输,从而提高查询性能。
- 使用 Colocate Join 功能,您需要在建表时为其指定一个 Colocation Group(CG),同一 CG 内的表需遵循相同的 Colocation Group Schema(CGS),即表对应的分桶副本具有一致的分桶键、副本数量和副本放置方式
- 如此可以保证同一 CG 内,所有表的数据分布在相同一组 BE 节点上。当 Join 列为分桶键时,计算节点只需做本地 Join,从而减少数据在节点间的传输耗时,提高查询性能
7. 企业架构升级示例
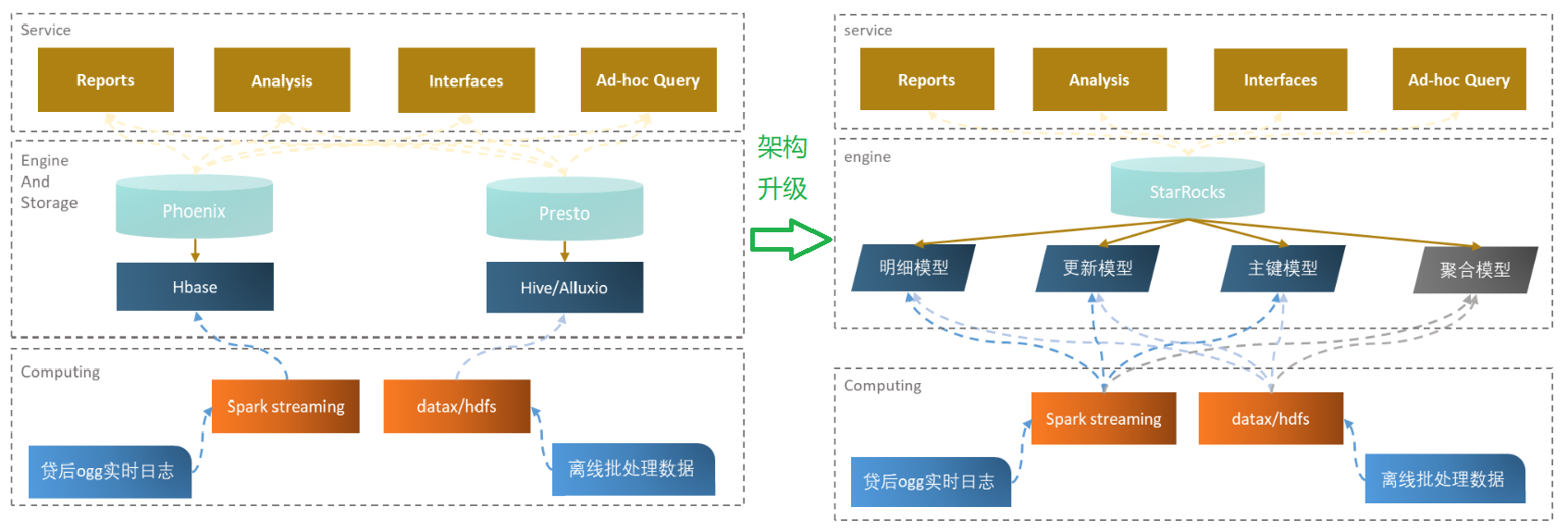
案例1 海尔云链 金融数据查询增速三倍,服务器成本减半
- 在实时处理方面用 StarRocks 替代了以前的 Hbase+Phoenix,
- 离线数据方面也部分用 StarRocks 替代了 Hive+Alluxio+Presto。
迭代新架构后
- 查询效率大幅提升,查询平均耗时得到了大幅缩减
- 服务器成本整体减低到接近原体系架构的一半
- 以前使用多服务多组件,如今统一到 StarRocks,使得运维成本也得到了大大降低。
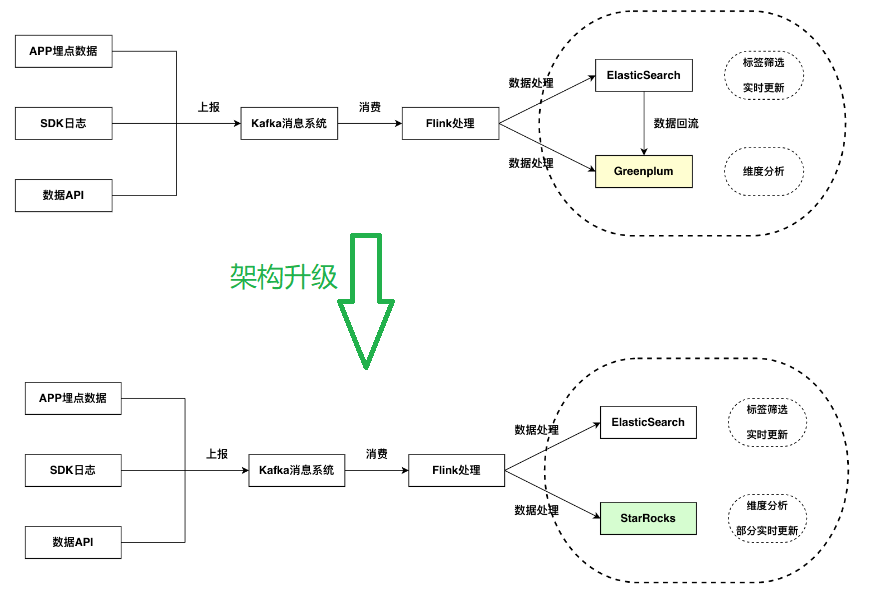
案例2 广告行业中的实时分析场景
- StarRocks 在写入和查询性能上都有比较好的表现;
- StarRocks 的主键能力能够承担部分 ElasticSearch 的点查点更新的场景;
- StarRocks 有 Connector 能力,能够直接将 ElasticSearch 作为外表关联进行一些数据探索的能力,同时也支持了谓词下推等能力,使 - - - StarRocks 与 ElasticSearch 的数据之间产生了很好的联系;
- 因为在非常高的 QPS 的情况下,StarRocks 的能力还未能满足 QPS 和 latency 的要求,所以目前只是部分的更新和点查场景交给了 StarRocks,依然保留了 ElasticSearch 与 StarRocks 共存的场景;
- StarRocks 的扩缩容能力较好,面对不断变化的业务负载有很好的管理。
版权归原作者 enjoy编程 所有, 如有侵权,请联系我们删除。