
数据仓库的建立不仅仅是数据的简单存储,更是对数据的深度利用。而数据清洗和转换是确保数据质量和一致性的重要环节。在这篇文章中,我们将深入探讨数据清洗和转换的常见方法,帮助你在数据仓库中更高效地处理数据。

目录
为什么数据清洗和转换如此重要?
在大数据时代,数据质量直接影响分析结果的准确性。数据清洗和转换是确保数据可靠性的关键步骤。它不仅可以帮助纠正错误数据,还可以统一数据格式,便于后续的分析和处理。
数据清洗和转换,如何决定数据分析的成败?
很多人在数据仓库的搭建中会遇到这样的情况:原始数据包含大量缺失值、重复数据、不一致的格式等问题,这些问题不解决,将直接导致后续的数据分析结果偏差甚大。那么,我们该如何进行数据清洗和转换?有哪些具体的方法和技巧可以使用?让我们一探究竟。
数据清洗的常见方法
数据清洗的目的是去除或修复数据中的错误和噪音。常见的清洗方法包括去除重复数据、处理缺失值、修正错误数据、标准化数据等。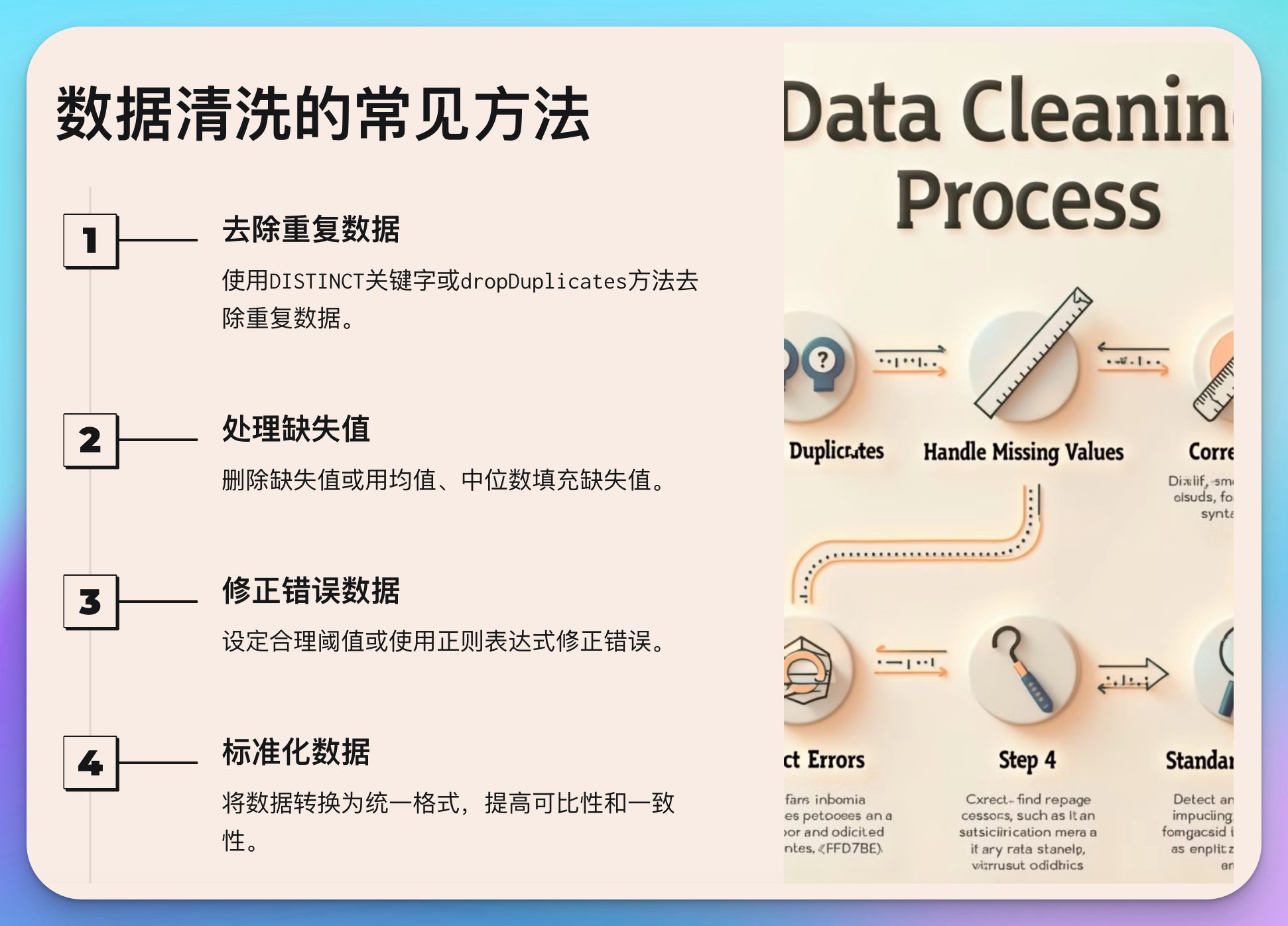
1. 去除重复数据
重复数据会导致统计结果失真。在进行数据分析之前,必须确保数据的唯一性。去除重复数据通常可以使用数据库的
DISTINCT
关键字或大数据处理工具(如Spark、Hadoop)中的
dropDuplicates
方法。
-- SQL 例子:去除重复的用户IDSELECTDISTINCT user_id, user_name
FROM users;
# PySpark 例子:去除重复的数据行from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataCleaning").getOrCreate()
df = spark.read.csv("path_to_file.csv", header=True)# 去除重复行
df_cleaned = df.dropDuplicates()
df_cleaned.show()
2. 处理缺失值
缺失值是数据清洗中最常见的问题之一。处理缺失值的方法包括删除缺失值、用均值或中位数填充缺失值、插值法等。
# Pandas 例子:处理缺失值import pandas as pd
df = pd.read_csv("data.csv")# 方法1:删除包含缺失值的行
df_dropped = df.dropna()# 方法2:用均值填充缺失值
df_filled = df.fillna(df.mean())print(df_filled)
3. 修正错误数据
数据中可能存在各种错误,如日期格式错误、数值超出合理范围等。通过设定合理的阈值或使用正则表达式,可以有效修正这些错误。
# Pandas 例子:修正日期格式错误import pandas as pd
df = pd.read_csv("data.csv")# 转换日期格式
df['date']= pd.to_datetime(df['date'], errors='coerce')# 去除无效日期
df = df.dropna(subset=['date'])print(df)
4. 标准化数据
数据标准化是指将数据转换为统一的格式,如日期格式统一、数值单位统一等。标准化可以提高数据的可比性和一致性。
# PySpark 例子:标准化数值列from pyspark.sql.functions import col
df = spark.read.csv("data.csv", header=True)# 将数值标准化到0到1之间from pyspark.ml.feature import MinMaxScaler
scaler = MinMaxScaler(inputCol="features", outputCol="scaledFeatures")
scalerModel = scaler.fit(df)
scaledData = scalerModel.transform(df)
scaledData.show()
数据转换的常见方法
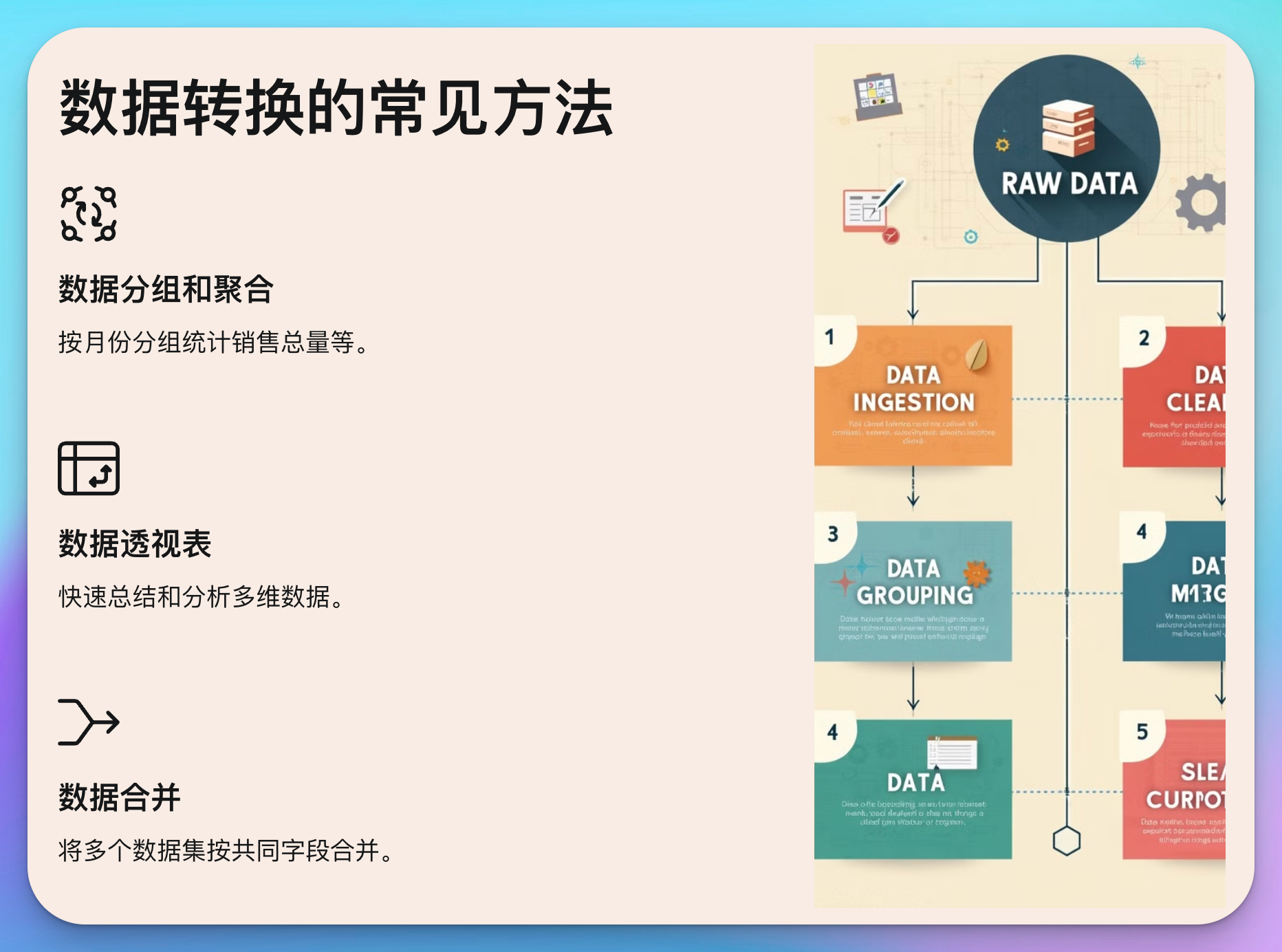
数据转换的目标是将数据从一种格式转换为另一种格式,以便于分析和使用。常见的数据转换方法包括数据分组、聚合、数据透视等。
1. 数据分组和聚合
数据分组和聚合可以帮助我们从数据中提取有意义的统计信息。例如,按月份分组统计销售数据的总量。
-- SQL 例子:按月份分组统计销售总量SELECTMONTH(sale_date)asmonth,SUM(sale_amount)as total_sales
FROM sales
GROUPBYMONTH(sale_date);
# Pandas 例子:按月份分组统计销售总量import pandas as pd
df = pd.read_csv("sales.csv")# 按月份分组并聚合
df['month']= pd.to_datetime(df['sale_date']).dt.month
monthly_sales = df.groupby('month')['sale_amount'].sum()print(monthly_sales)
2. 数据透视表
数据透视表是一种多维数据分析工具,可以快速总结和分析数据。例如,按产品和地区统计销售数据。
# Pandas 例子:创建数据透视表import pandas as pd
df = pd.read_csv("sales.csv")# 创建数据透视表
pivot_table = df.pivot_table(values='sale_amount', index='product', columns='region', aggfunc='sum')print(pivot_table)
3. 数据合并
数据合并是将多个数据集按某个共同字段合并为一个数据集。例如,将客户信息表和订单信息表合并。
# Pandas 例子:合并客户和订单数据import pandas as pd
customers = pd.read_csv("customers.csv")
orders = pd.read_csv("orders.csv")# 按客户ID合并数据
merged_data = pd.merge(customers, orders, on='customer_id')print(merged_data)
常见挑战及解决方案
挑战1:处理大规模数据
问题描述: 随着数据量的增长,数据清洗和转换的速度和效率成为一个关键问题。如何在大规模数据环境中高效地进行清洗和转换?
解决方案:
- 分布式计算: 使用大数据处理框架,如Apache Spark或Hadoop,来处理大规模数据。分布式计算可以将任务分解到多个节点上执行,从而提高处理速度。
- 增量处理: 对于持续增长的数据,采用增量处理的方式,只处理新增或更新的数据,避免每次都全量处理。
- 批处理与流处理结合: 根据实际情况选择批处理(Batch Processing)或流处理(Stream Processing)来进行数据清洗和转换。批处理适合定期的数据处理,而流处理适合实时的数据处理。
# PySpark 例子:使用分布式计算处理大规模数据from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("LargeScaleDataProcessing").getOrCreate()
df = spark.read.csv("large_data.csv", header=True)# 分布式去重
df_cleaned = df.dropDuplicates()
df_cleaned.show()
挑战2:数据源多样化和异构性
问题描述: 数据来源于不同的系统和格式,如关系数据库、NoSQL数据库、文件系统等。数据的异构性增加了清洗和转换的复杂性。
解决方案:
- 数据集成工具: 使用ETL工具(如Talend、Informatica)或数据集成平台(如Apache Nifi)来整合不同来源的数据。这些工具通常提供连接器,可以连接到多种数据源,并支持多种格式的转换。
- 标准化接口: 建立标准化的数据接口和API,将不同格式的数据转换为统一的格式,便于后续处理。
# 使用Python Pandas整合不同来源的数据import pandas as pd
# 读取不同来源的数据
df_sql = pd.read_sql("SELECT * FROM sql_table", con=sql_connection)
df_csv = pd.read_csv("data.csv")
df_json = pd.read_json("data.json")# 合并数据
df_combined = pd.concat([df_sql, df_csv, df_json], axis=0)print(df_combined)
挑战3:数据质量问题
问题描述: 数据质量问题包括缺失值、异常值、格式不一致等。这些问题会直接影响分析结果的准确性。
解决方案:
- 数据验证: 在数据输入阶段进行验证,确保数据符合预定的格式和范围。可以使用正则表达式或自定义的验证函数来验证数据。
- 异常检测: 使用统计方法或机器学习模型检测异常值,并根据业务规则决定如何处理异常数据。
- 数据标准化: 将数据转换为统一的格式,例如,日期统一为
YYYY-MM-DD格式,数值统一为标准单位等。
# Pandas 例子:异常值检测和处理import pandas as pd
df = pd.read_csv("data.csv")# 使用Z-score检测异常值
df['z_score']=(df['value']- df['value'].mean())/ df['value'].std()
df_no_outliers = df[df['z_score'].abs()<=3]print(df_no_outliers)
挑战4:数据一致性和冗余
问题描述: 在数据清洗过程中,确保数据的一致性是一个关键问题。例如,多个数据源中同一实体的信息是否一致,如何处理冗余数据?
解决方案:
- 数据去重: 在合并多个数据源的数据时,使用唯一标识符(如主键)来去除冗余数据。
- 数据一致性检查: 定义业务规则来检查数据的一致性。例如,客户信息在多个系统中的一致性,可以通过业务ID进行匹配和校验。
- 数据治理: 实施数据治理策略,包括数据管理流程、数据质量监控和数据标准的制定。
# Pandas 例子:数据一致性检查import pandas as pd
df1 = pd.read_csv("data1.csv")
df2 = pd.read_csv("data2.csv")# 按客户ID检查数据一致性
merged_data = pd.merge(df1, df2, on='customer_id', suffixes=('_df1','_df2'))# 检查不一致的数据
inconsistent_data = merged_data[merged_data['name_df1']!= merged_data['name_df2']]print(inconsistent_data)
实际案例:电商数据清洗和转换
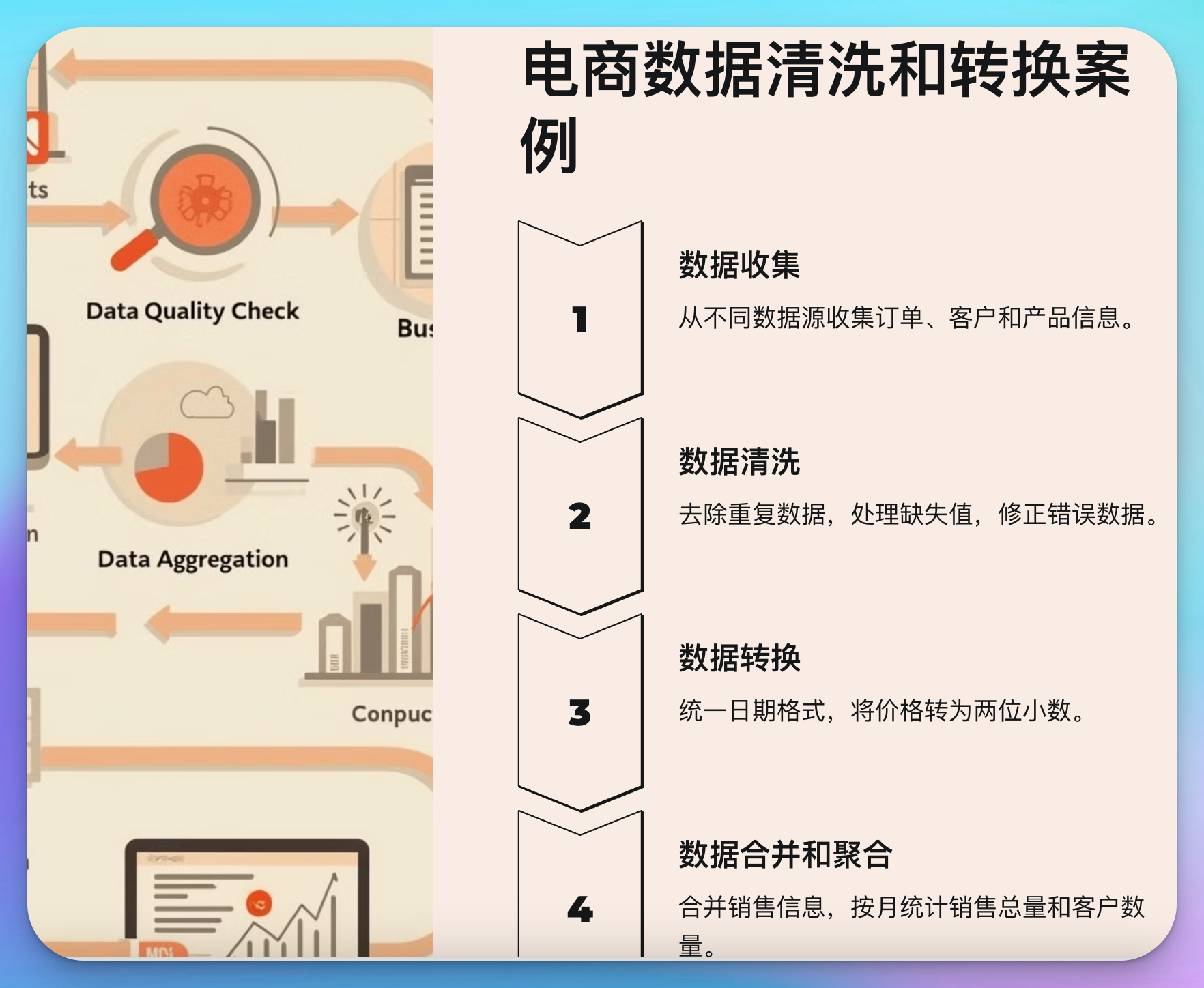
为了更好地理解数据清洗和转换,我们以一个电商数据为例。假设我们有一个大型电商平台的销售数据,包括订单信息、客户信息和产品信息。我们需要将这些数据清洗和转换,准备好进行销售分析。
步骤1:数据收集
从不同的数据源收集数据,包括订单表、客户表和产品表。这些数据可能存储在不同的数据库中,或者以CSV文件的形式存在。
# 收集数据
orders = pd.read_csv("orders.csv")
customers = pd.read_csv("customers.csv")
products = pd.read_csv("products.csv")
步骤2:数据清洗
对收集到的数据进行清洗,包括去除重复数据、处理缺失值、修正错误数据等。
# 去除订单表中的重复数据
orders_cleaned = orders.drop_duplicates()# 处理缺失的客户信息
customers_cleaned = customers.fillna({'phone_number':'Unknown','email':'Unknown'})# 修正产品表中的价格错误
products['price']= products['price'].apply(lambda x:abs(x))# 修正负值价格
步骤3:数据转换
将清洗后的数据转换为统一的格式,例如,将订单日期转换为标准日期格式,将价格统一为两位小数。
# 转换订单日期为标准格式
orders_cleaned['order_date']= pd.to_datetime(orders_cleaned['order_date'],format='%Y-%m-%d')# 将价格统一为两位小数
products['price']= products['price'].round(2)
步骤4:数据合并和聚合
将清洗和转换后的数据进行合并,得到完整的销售信息。然后按月统计销售总量和客户数量。
# 合并订单和客户信息
order_customer_data = pd.merge(orders_cleaned, customers_cleaned, on='customer_id')# 按月份聚合销售数据
order_customer_data['month']= order_customer_data['order_date'].dt.month
monthly_sales = order_customer_data.groupby('month')['order_amount'].sum()
monthly_customers = order_customer_data.groupby('month')['customer_id'].nunique()print(monthly_sales)print(monthly_customers)
结论
数据清洗和转换是数据仓库建设中不可或缺的部分,通过有效的数据清洗和转换,可以确保数据的质量和一致性,为后续的数据分析和决策提供坚实的基础。在实践中,根据具体的业务需求和数据特点选择合适的方法和工具,才能真正发挥数据的价值。
小贴士
- 持续改进: 数据清洗和转换不是一次性的任务,而是一个持续的过程。随着业务需求和数据源的变化,数据清洗和转换的策略也需要不断调整和优化。
- 工具和技术的选择: 根据数据的规模和复杂性,选择合适的工具和技术。对于大规模数据,推荐使用分布式计算框架,如Apache Spark;对于复杂的业务逻辑,可以考虑自定义清洗和转换脚本。
通过本篇文章的详细讲解,希望你对数据清洗和转换有了更深入的理解。如果你在实际工作中遇到相关问题,欢迎随时交流和讨论。你的每一条反馈都是我们前进的动力!
版权归原作者 数据小羊 所有, 如有侵权,请联系我们删除。