
spark sql解析
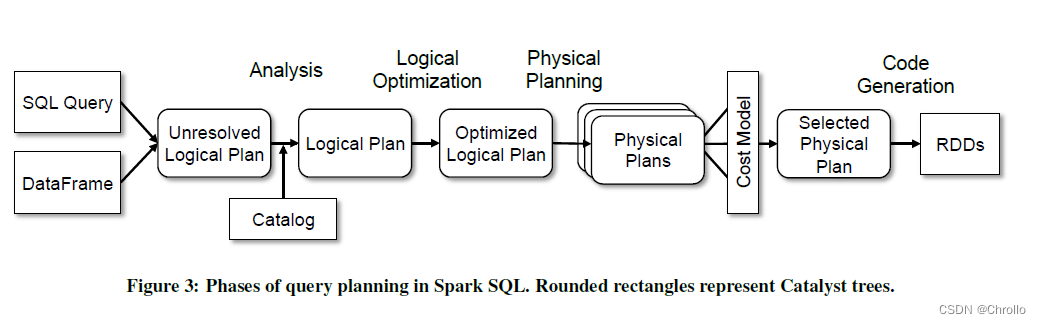
spark sql解析过程这里直接引用论文
Spark SQL: Relational Data Processing in Spark
中的流程图,整体流程非常的清晰。下面将按顺序进去讲解。
从Analysis这个阶段开始,主要流程都是在QueryExecution类中进行处理的。
// Analysis阶段
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
// We can't clone `logical` here, which will reset the `_analyzed` flag.
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}
// 优化阶段
lazy val optimizedPlan: LogicalPlan = executePhase(QueryPlanningTracker.OPTIMIZATION) {
// clone the plan to avoid sharing the plan instance between different stages like analyzing,
// optimizing and planning.
val plan = sparkSession.sessionState.optimizer.executeAndTrack(withCachedData.clone(), tracker)
// We do not want optimized plans to be re-analyzed as literals that have been constant folded
// and such can cause issues during analysis. While `clone` should maintain the `analyzed` state
// of the LogicalPlan, we set the plan as analyzed here as well out of paranoia.
plan.setAnalyzed()
plan
}
// 转换成物理计划
lazy val sparkPlan: SparkPlan = {
// We need to materialize the optimizedPlan here because sparkPlan is also tracked under
// the planning phase
assertOptimized()
executePhase(QueryPlanningTracker.PLANNING) {
// Clone the logical plan here, in case the planner rules change the states of the logical
// plan.
QueryExecution.createSparkPlan(sparkSession, planner, optimizedPlan.clone())
}
}
// 转换成可执行计划
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = {
// We need to materialize the optimizedPlan here, before tracking the planning phase, to ensure
// that the optimization time is not counted as part of the planning phase.
assertOptimized()
executePhase(QueryPlanningTracker.PLANNING) {
// clone the plan to avoid sharing the plan instance between different stages like analyzing,
// optimizing and planning.
QueryExecution.prepareForExecution(preparations, sparkPlan.clone())
}
}
// 转换成rdd
lazy val toRdd: RDD[InternalRow] = new SQLExecutionRDD(
executedPlan.execute(), sparkSession.sessionState.conf)
antlr4的解析
依靠antlr4的语法分析能力,将定义的sql语法解析成对应的LogicalPlan。这一块内容比较多,以后专门开一篇来讲解。这里只要记住将sql解析成了一颗LogicalPlan树,树的每个节点都是TreeNode。
拿一个简单的例子来看看:
val sql =
"""
|select a.name, b.age
|from local.ods.member1 a join local.ods.member1 b
|on a.name = b.name
|""".stripMargin
val logicalPlan: LogicalPlan = spark.sessionState.sqlParser.parsePlan(sql)
这里得到未解析的LogicalPlan
'Project ['a.name, 'b.age]
+- 'Join Inner, ('a.name = 'b.name)
:- 'SubqueryAlias a
: +- 'UnresolvedRelation [local, ods, member1], [], false
+- 'SubqueryAlias b
+- 'UnresolvedRelation [local, ods, member1], [], false
- 顶层节点是Project节点里面包含了两个UnresolvedAttribute,一个是
a.name,一个是b.age。 - Project节点的child节点是Join节点,Join节点里面有一个left节点和一个right节点, 它们的类为SubqueryAlias。Join节点的joinType为Inner类型, condition为Some(('a.name = 'b.name))。
- 左节点和右节点类似,看一个就行。左节点的child节点为UnresolveRelation节点,里面有一个multipartIdentifier属性,它是一个ArrayBuffer类型,里面有三个元素:
local,ods,member1。这个UnresolveRelation节点是LeafNode,所以它没有子节点了。
Analysis阶段
Analysis阶段依次调用了Analyzer的execute方法–>RuleExecutor的execute方法。后面的这个execute方法里面接受一个LogicalPlan。
这里面主要有一个batches成员,定义了一系列的规则。
/** A batch of rules. */
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
/** Defines a sequence of rule batches, to be overridden by the implementation. */
protected def batches: Seq[Batch]
Analyzer里面重写的batches:
override def batches: Seq[Batch] = Seq(
Batch("Substitution", fixedPoint,
// This rule optimizes `UpdateFields` expression chains so looks more like optimization rule.
// However, when manipulating deeply nested schema, `UpdateFields` expression tree could be
// very complex and make analysis impossible. Thus we need to optimize `UpdateFields` early
// at the beginning of analysis.
OptimizeUpdateFields,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
SubstituteUnresolvedOrdinals),
Batch("Disable Hints", Once,
new ResolveHints.DisableHints),
Batch("Hints", fixedPoint,
ResolveHints.ResolveJoinStrategyHints,
ResolveHints.ResolveCoalesceHints),
Batch("Simple Sanity Check", Once,
LookupFunctions),
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions ::
ResolveNamespace(catalogManager) ::
new ResolveCatalogs(catalogManager) ::
ResolveUserSpecifiedColumns ::
ResolveInsertInto ::
ResolveRelations ::
ResolveTables ::
ResolvePartitionSpec ::
AddMetadataColumns ::
ResolveReferences ::
ResolveCreateNamedStruct ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveAggAliasInGroupBy ::
ResolveMissingReferences ::
ExtractGenerator ::
ResolveGenerate ::
ResolveFunctions ::
ResolveAliases ::
ResolveSubquery ::
ResolveSubqueryColumnAliases ::
ResolveWindowOrder ::
ResolveWindowFrame ::
ResolveNaturalAndUsingJoin ::
ResolveOutputRelation ::
ExtractWindowExpressions ::
GlobalAggregates ::
ResolveAggregateFunctions ::
TimeWindowing ::
ResolveInlineTables ::
ResolveHigherOrderFunctions(v1SessionCatalog) ::
ResolveLambdaVariables ::
ResolveTimeZone ::
ResolveRandomSeed ::
ResolveBinaryArithmetic ::
ResolveUnion ::
TypeCoercion.typeCoercionRules ++
extendedResolutionRules : _*),
Batch("Apply Char Padding", Once,
ApplyCharTypePadding),
Batch("Post-Hoc Resolution", Once,
Seq(ResolveNoopDropTable) ++
postHocResolutionRules: _*),
Batch("Normalize Alter Table", Once, ResolveAlterTableChanges),
Batch("Remove Unresolved Hints", Once,
new ResolveHints.RemoveAllHints),
Batch("Nondeterministic", Once,
PullOutNondeterministic),
Batch("UDF", Once,
HandleNullInputsForUDF,
ResolveEncodersInUDF),
Batch("UpdateNullability", Once,
UpdateAttributeNullability),
Batch("Subquery", Once,
UpdateOuterReferences),
Batch("Cleanup", fixedPoint,
CleanupAliases)
)
这里是一些解析规则,继承于
Plan
类。
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val result = rule(plan)
...
核心部分就是这个循环,将上面的解析规则一个个应用到plan上面。
rule(plan)
这里调用的是rule的apply方法。上面的例子中有一个
UnresolvedRelation
,所以这里就选用这个plan对应的规则
ResolveRelations
跟进去看看。
ResolveRelations
的apply方法首先调用了一个
ResolveTempViews
的规则。
object ResolveTempViews extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp {
case u @ UnresolvedRelation(ident, _, isStreaming) =>
lookupAndResolveTempView(ident, isStreaming).getOrElse(u)
case i @ InsertIntoStatement(UnresolvedRelation(ident, _, false), _, _, _, _, _) =>
lookupAndResolveTempView(ident)
.map(view => i.copy(table = view))
.getOrElse(i)
// TODO (SPARK-27484): handle streaming write commands when we have them.
...
这里对plan调用
resolveOperatorsUp
的方法。
/**
* Returns a copy of this node where `rule` has been recursively applied first to all of its
* children and then itself (post-order, bottom-up). When `rule` does not apply to a given node,
* it is left unchanged. This function is similar to `transformUp`, but skips sub-trees that
* have already been marked as analyzed.
*
* @param rule the function use to transform this nodes children
*/
def resolveOperatorsUp(rule: PartialFunction[LogicalPlan, LogicalPlan]): LogicalPlan = {
if (!analyzed) {
AnalysisHelper.allowInvokingTransformsInAnalyzer {
val afterRuleOnChildren = mapChildren(_.resolveOperatorsUp(rule))
if (self fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(self, identity[LogicalPlan])
}
} else {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(afterRuleOnChildren, identity[LogicalPlan])
}
}
}
} else {
self
}
}
这个方法说的是返回此节点的副本,将rule递归应用于自己的孩子节点,然后是自己(后序,自下而上)。 当rule不适用于给定节点时,保持plan不变。 这个函数类似于 transformUp ,但是跳过已经分析过的节点。这个方法接受的是一个偏函数,在这个例子里面,会自下而上的匹配plan。最下面的节点是
UnresolvedRelation
,所以会调用下面的
lookupAndResolveTempView
方法。
case u @ UnresolvedRelation(ident, _, isStreaming) =>
lookupAndResolveTempView(ident, isStreaming).getOrElse(u)
这个方法的核心是在当前的catalog里面寻找注册的view:
val tmpView = identifier match {
case Seq(part1) => v1SessionCatalog.lookupTempView(part1)
case Seq(part1, part2) => v1SessionCatalog.lookupGlobalTempView(part1, part2)
case _ => None
}
不是view就返回None。
ResolveRelations
这个rule调用ResolveTempViews(plan)这个方法后紧接着又调用了一次
resolveOperatorsUp
方法;
case u: UnresolvedRelation =>
lookupRelation(u.multipartIdentifier, u.options, u.isStreaming)
.map(resolveViews).getOrElse(u)
这次匹配到
UnresolvedRelation
,会调用
lookupRelation
方法。这个方法的逻辑是:
1)如果被解析的catalog不是当前会话(session)的catalog,返回None
2)如果relation不在catalog里面,返回None
3)如果发现的是v1 table,返回v1 relation,其他的返回v2 relation。
private def lookupRelation(
identifier: Seq[String],
options: CaseInsensitiveStringMap,
isStreaming: Boolean): Option[LogicalPlan] = {
expandRelationName(identifier) match {
case SessionCatalogAndIdentifier(catalog, ident) =>
...
case _ => None
因为是iceberg的表,这里的没有匹配上,返回了None。这里很奇怪,明明是
UnresolvedRelation
的节点,为什么在
ResolveRelations
里面没有做任何处理,但是在Analysis的过程中确实被解析过了。debug发现,iceberg的
UnresolvedRelation
是在
ResolveTables
规则中处理的。
object ResolveTables extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = ResolveTempViews(plan).resolveOperatorsUp {
case u: UnresolvedRelation =>
lookupV2Relation(u.multipartIdentifier, u.options, u.isStreaming)
这里面调用了一个
lookupV2Relation
的方法。
private def lookupV2Relation(
identifier: Seq[String],
options: CaseInsensitiveStringMap,
isStreaming: Boolean): Option[LogicalPlan] =
expandRelationName(identifier) match {
case NonSessionCatalogAndIdentifier(catalog, ident) =>
CatalogV2Util.loadTable(catalog, ident) match {
case Some(table) =>
if (isStreaming) {
Some(StreamingRelationV2(None, table.name, table, options,
table.schema.toAttributes, Some(catalog), Some(ident), None))
} else {
Some(DataSourceV2Relation.create(table, Some(catalog), Some(ident), options))
}
case None => None
}
case _ => None
}
这个跟上面的不同在于这里是
NonSessionCatalogAndIdentifier
上面匹配的是
SessionCatalogAndIdentifier
。根据注释来看
lookupV2Relation
这个函数是从v2 catalog里面查找DataSourceV2。Iceberg的实现是基于DataSourceV2,因此匹配到了这里的规则。然后将
UnresolvedRelation
转换成了
RelationV2
。结果如下:
Project [name#6, age#11]
+- Join Inner, (name#6 = name#9)
:- SubqueryAlias a
: +- SubqueryAlias local.ods.member1
: +- RelationV2[name#6, sex#7, age#8] local.ods.member1
+- SubqueryAlias b
+- SubqueryAlias local.ods.member1
+- RelationV2[name#9, sex#10, age#11] local.ods.member1
这里只给出了数据源解析部分的分析,其他部分感兴趣的可以自己debug看看。
Optimizer阶段
题外
这题我看到了scala一个神奇的操作,抽象类里面定义的是
protected def batches: Seq[Batch]
一个方法,在子类里面用一个成员去重写。
object Optimize extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Subqueries", Once,
EliminateSubqueryAliases) ::
// this batch must reach expected state in one pass
Batch("Filter Pushdown One Pass", Once,
ReorderJoin,
PushDownPredicates
) :: Nil
}
正题
Optimizer优化整体的流程和Analysis使用的是相同的流程,Optimizer对batches也进行了重写。
final override def batches: Seq[Batch] = {
val excludedRulesConf =
SQLConf.get.optimizerExcludedRules.toSeq.flatMap(Utils.stringToSeq)
val excludedRules = excludedRulesConf.filter { ruleName =>
val nonExcludable = nonExcludableRules.contains(ruleName)
if (nonExcludable) {
logWarning(s"Optimization rule '${ruleName}' was not excluded from the optimizer " +
s"because this rule is a non-excludable rule.")
}
!nonExcludable
}
if (excludedRules.isEmpty) {
defaultBatches
} else {
defaultBatches.flatMap { batch =>
val filteredRules = batch.rules.filter { rule =>
val exclude = excludedRules.contains(rule.ruleName)
if (exclude) {
logInfo(s"Optimization rule '${rule.ruleName}' is excluded from the optimizer.")
}
!exclude
}
if (batch.rules == filteredRules) {
Some(batch)
} else if (filteredRules.nonEmpty) {
Some(Batch(batch.name, batch.strategy, filteredRules: _*))
} else {
logInfo(s"Optimization batch '${batch.name}' is excluded from the optimizer " +
s"as all enclosed rules have been excluded.")
None
}
}
}
}
去掉排除的规则,如果配置中排除规则为空,则使用默认的规则defaultBatches。默认的规则非常的多,这里就不一一列出了。
def defaultBatches: Seq[Batch] = {
val operatorOptimizationRuleSet =
Seq(
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
PushDownPredicates,
PushDownLeftSemiAntiJoin,
PushLeftSemiLeftAntiThroughJoin,
LimitPushDown,
ColumnPruning,
// Operator combine
...
大概是这个样子,粗略地可以看到有谓语下压,列裁剪之类的优化操作,这些是在Optimizer里面做的。这里具体的过程等有时间的时候再详细看看,留个坑。得到的优化后的逻辑计划如下:
Project [name#6, age#11]
+- Join Inner, (name#6 = name#9)
:- Filter isnotnull(name#6)
: +- RelationV2[name#6] local.ods.member1
+- Filter isnotnull(name#9)
+- RelationV2[name#9, age#11] local.ods.member1
Physical Plan阶段
将optimazedPlan转换成物理执行计划SparkPlan。
lazyval sparkPlan: SparkPlan = {
// We need to materialize the optimizedPlan here because sparkPlan is also tracked under
// the planning phase
assertOptimized()
executePhase(QueryPlanningTracker.PLANNING) {
// Clone the logical plan here, in case the planner rules change the states of the logical
// plan.
QueryExecution.createSparkPlan(sparkSession, planner, optimizedPlan.clone())
}
}
def createSparkPlan(
sparkSession: SparkSession,
planner: SparkPlanner,
plan: LogicalPlan): SparkPlan = {
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(plan)).next()
}
这里对优化后的plan做了一层包装,这个ReturnAnswer节点的注释是规则的模式匹配只作用于最顶层的逻辑计划。然后将其丢入了SparkPlan中,这里有一个next是因为plan方法返回的是一个迭代器。
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
// Obviously a lot to do here still...
// Collect physical plan candidates.
val candidates = strategies.iterator.flatMap(_(plan))
// The candidates may contain placeholders marked as [[planLater]],
// so try to replace them by their child plans.
val plans = candidates.flatMap { candidate =>
val placeholders = collectPlaceholders(candidate)
if (placeholders.isEmpty) {
// Take the candidate as is because it does not contain placeholders.
Iterator(candidate)
} else {
// Plan the logical plan marked as [[planLater]] and replace the placeholders.
placeholders.iterator.foldLeft(Iterator(candidate)) {
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
// Plan the logical plan for the placeholder.
val childPlans = this.plan(logicalPlan)
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders =>
childPlans.map { childPlan =>
// Replace the placeholder by the child plan
candidateWithPlaceholders.transformUp {
case p if p.eq(placeholder) => childPlan
}
}
}
}
}
}
这个plan方法调用的是父类QueryPlanner的plan方法,也是物理执行计划的核心部分。我们顺着看第一个部分
strategies.iterator.flatMap(_(plan))
,SparkPlanner重写了策略,下面是实际执行的策略:
override def strategies: Seq[Strategy] =
experimentalMethods.extraStrategies ++
extraPlanningStrategies ++ (
LogicalQueryStageStrategy ::
PythonEvals ::
new DataSourceV2Strategy(session) ::
FileSourceStrategy ::
DataSourceStrategy ::
SpecialLimits ::
Aggregation ::
Window ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)
可以看到有数据源,聚合,窗口,Join等。将上面的策略依次执行到当前的节点,注意这里是不处理子节点的,子节点会在后面递归调用到这里时处理。优化后的逻辑计划顶层节点是Project节点,外面包装了ReturnAnswer节点,这个节点会被
SpecialLimits
策略转换成一个
PlanLater
节点,然后被扔进
collectPlaceholders
方法中。
override protected def collectPlaceholders(plan: SparkPlan): Seq[(SparkPlan, LogicalPlan)] = {
plan.collect {
case placeholder @ PlanLater(logicalPlan) => placeholder -> logicalPlan
}
}
这个collect方法会对当前节点和children节点作用collect后面的偏函数,这个偏函数处理的是PlanLater节点,当前只有根节点是PlanLater节点,返回的是一个元祖,第一个元素是当前PlanLater节点的本身,第二个元素是当前节点被转换前的节点,也就是Project节点。这个PlanLater节点相当于是一个占位符,这个占位符对应的是没有处理的节点。后面会用处理后的节点来替换这个占位符。接着,Project节点被递归调用
val childPlans = this.plan(logicalPlan)
,重新扔进了plan方法中。这一次strategies中能够处理Project节点的策略就会起作用对其进行转换。在这个递归调用的作用下,从上至下所有的节点都会被对应的策略转换。Project->Join->Filter->RelationV2。
candidateWithPlaceholders.transformUp {
case p if p.eq(placeholder) => childPlan
}
然后从下往上对
PlanLater
进行替换。最终用
Project
的物理计划
ProjectExec
将
PlanLater(Project)
替换并返回。最终的转换结果如下:
Project [name#6, age#11]
+- BroadcastHashJoin [name#6], [name#9], Inner, BuildLeft, false
:- Project [name#6]
: +- Filter isnotnull(name#6)
: +- BatchScan[name#6] local.ods.member1 [filters=name IS NOT NULL]
+- Project [name#9, age#11]
+- Filter isnotnull(name#9)
+- BatchScan[name#9, age#11] local.ods.member1 [filters=name IS NOT NULL]
中间具体的转换策略等有时间再写,留个坑。
Prepare Executed Plan
执行准备阶段,构建一系列的规则用作执行的准备。这些规则保证子查询执行计划的构建,确保数据分区和排序的正确性,
insert whole stage
代码的生成,通过复用
exchange
和
subqueries
来减少工作。一下是具体的规则:
private[execution] def preparations(
sparkSession: SparkSession,
adaptiveExecutionRule: Option[InsertAdaptiveSparkPlan] = None): Seq[Rule[SparkPlan]] = {
// `AdaptiveSparkPlanExec` is a leaf node. If inserted, all the following rules will be no-op
// as the original plan is hidden behind `AdaptiveSparkPlanExec`.
adaptiveExecutionRule.toSeq ++
Seq(
CoalesceBucketsInJoin,
PlanDynamicPruningFilters(sparkSession),
PlanSubqueries(sparkSession),
RemoveRedundantProjects,
EnsureRequirements,
// `RemoveRedundantSorts` needs to be added after `EnsureRequirements` to guarantee the same
// number of partitions when instantiating PartitioningCollection.
RemoveRedundantSorts,
DisableUnnecessaryBucketedScan,
ApplyColumnarRulesAndInsertTransitions(sparkSession.sessionState.columnarRules),
CollapseCodegenStages(),
ReuseExchange,
ReuseSubquery
)
这里看一个例子:
object ReuseExchange extends Rule[SparkPlan] {
def apply(plan: SparkPlan): SparkPlan = {
if (!conf.exchangeReuseEnabled) {
return plan
}
// Build a hash map using schema of exchanges to avoid O(N*N) sameResult calls.
val exchanges = mutable.HashMap[StructType, ArrayBuffer[Exchange]]()
// Replace a Exchange duplicate with a ReusedExchange
def reuse: PartialFunction[Exchange, SparkPlan] = {
case exchange: Exchange =>
val sameSchema = exchanges.getOrElseUpdate(exchange.schema, ArrayBuffer[Exchange]())
val samePlan = sameSchema.find { e =>
exchange.sameResult(e)
}
if (samePlan.isDefined) {
// Keep the output of this exchange, the following plans require that to resolve
// attributes.
ReusedExchangeExec(exchange.output, samePlan.get)
} else {
sameSchema += exchange
exchange
}
}
plan transformUp {
case exchange: Exchange => reuse(exchange)
} transformAllExpressions {
// Lookup inside subqueries for duplicate exchanges
case in: InSubqueryExec =>
val newIn = in.plan.transformUp {
case exchange: Exchange => reuse(exchange)
}
in.copy(plan = newIn.asInstanceOf[BaseSubqueryExec])
}
}
}
可以看到,有一个
exchanges
的HashMap存储了当前的Exchange信息,key为一个StructType对象,StructType存储了Join的字段信息,value是存储了Exchange的一个ArrayBuffer。这里先是在map中找到Join字段的Exchange的ArrayBuffer,如果找到了就与ArrayBuffer中的Exchange进行匹配,匹配上了就返回
ReusedExchangeExec
复用的Exchage对象。如果没有匹配上就向map中进行添加。上面的执行计划中有一个
BroadcastExchangeExec
节点,实现了
BroadcastExchangeLike
特质,这个特质又继承了
Exchange
的抽象类。例子中的exchanges内容如下所示:
(StructType(StructField(name,StringType,false)),
ArrayBuffer(BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, false]),false), [id=#38]
+- *(1) Filter isnotnull(name#6)
+- BatchScan[name#6] local.ods.member1 [filters=name IS NOT NULL]))
。
版权归原作者 Chrollo 所有, 如有侵权,请联系我们删除。