
一、前言
B站评论没有查找功能,就随手写了一个爬虫爬取B站评论存储到本地txt中
首先需要安装python的request库,和beautifulsoup库
pip install requests
pip install bs4
出现successfully就代表安装成功了
下面就是所需的所有库
import requests
from bs4 import BeautifulSoup
import re
import json
from pprint import pprint
import time
二、分析网页
示例网页 兰音『探窗』BV18T411G7xJ
我们在页面中查看源代码,发现源代码中并没有有关评论的信息。我们继续往下滑到评论的位置,发现评论是需要加载一会才出现,这时候我就猜测需要抓包才能获取到评论的信息。
打开F12,在**network**中查询reply有关选项,查找到了评论信息。

我提取出URL,查看里面的各项数据
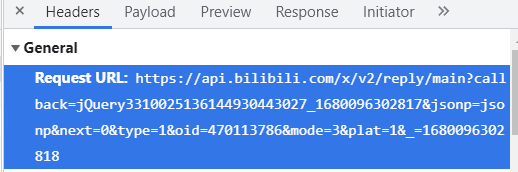
不知道为什么这里的URL需要删除掉Callback后面的数据才能正常查看
在Edge里下载**Json Formatter**可以更好的查看。


发现一个包并不能显示所有的评论,我们继续往下滑,在F12寻找有关reply的数据,提取出URL

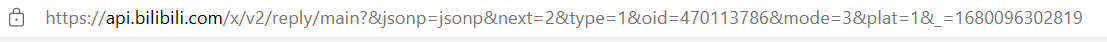 发现只有next会改变,那么next=1是什么?实践发现next=1和next=0的数据一样,所以我们编程序的时候可以直接从1开始。
发现只有next会改变,那么next=1是什么?实践发现next=1和next=0的数据一样,所以我们编程序的时候可以直接从1开始。
但是我们又发现这里面只有根评论没有子评论,怀疑子评论在另一个包中,查看其中一个评论的子评论,我们又在F12中抓到了一个新包。
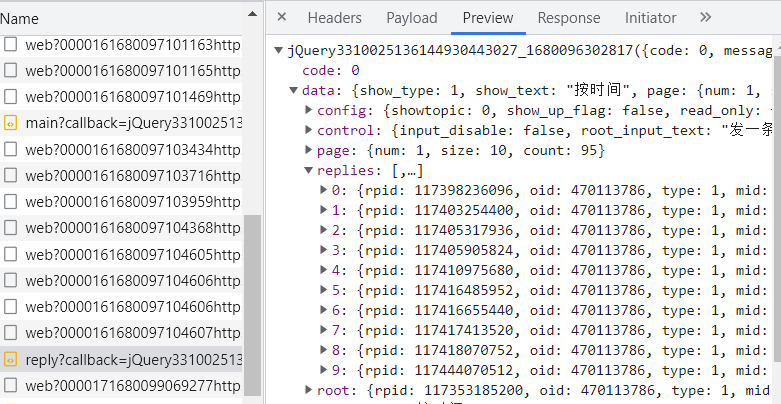
同样我们提取URL,观察replies就是所需要的子评论。同样一页也不能显示完所有回复,观察后发现,各个评论只有pn不一样。

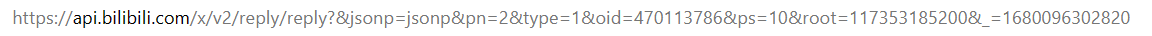
那么子评论和根评论是怎么联系在一起的呢?
观察URL,发现子评论的URL有root这项,我们就去研究了根和子的一致,发现根的**rpid**就是子的**root**,这样我们就找到了关系。

最后在写代码的时候还发现有个问题,就是有些根评论不需要展开,那么子评论的包中replies这一项就是空的,而这些评论的信息存在梗评论的包中,我们只需要简单判断一下就可以了。
了解完结构后,编程就简单多了。
三、代码
1.头
#网页头
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"referer" : "https://www.bilibili.com/"
}
2.获取根评论
def get_rootReply(headers):
num = 1
replay_index = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={num}&type=1&oid=470113786&mode=3&plat=1&_=1680096302818") #获得网页源码
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
# print(respond.status_code)
reply_num = 0
if(respond.status_code == 200): # 如果响应为200就继续,否则退出
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html) # 把格式转化为json格式 一个是好让pprint打印,一个是好寻找关键代码
if json_html['data']['replies'] is None or len(json_html['data']['replies']) == 0 :
break
for i in range(0,len(json_html['data']['replies'])): #一页只能读取20条评论
reply = json_html['data']['replies'][reply_num]['content']['message']
root = json_html['data']['replies'][reply_num]['rpid']
reply = reply.replace('\n',',')
# print(reply)
file.write(str(replay_index) + '.' + reply + '\n')
if json_html['data']['replies'][reply_num]['replies'] is not None:
if(get_SecondReply(headers,root) == 0):
for i in range(0,len(json_html['data']['replies'][reply_num]['replies'])):
reply = json_html['data']['replies'][reply_num]['replies'][i]['content']['message']
reply = reply.replace('\n',',')
file.write(" " + reply + '\n')
reply_num += 1
replay_index += 1
num += 1
time.sleep(0.5)
else :
print("respond error!")
break
file.close()
3.获取子评论
def get_SecondReply(headers,root):
pn = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={pn}&type=1&oid=824175427&ps=10&root={root}&_=1679992607971")
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
reply_num = 0
if(respond.status_code == 200):
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html)
if json_html['data']['replies'] is None:
if(pn == 1):
return 0
else :
return 1
for i in range(0,len(json_html['data']['replies'])):
if json_html['data']['replies'] is None:
break
reply = json_html['data']['replies'][reply_num]['content']['message']
reply = reply.replace('\n',',')
# print(reply)
reply_num += 1
file.write(" " + reply + '\n')
pn += 1
time.sleep(0.5)
else:
print("Sreply error!")
exit(-1)
这样各个模块就集齐了
四、总代码
import requests
from bs4 import BeautifulSoup
import re
import json
from pprint import pprint
import time
#网页头
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"referer" : "https://www.bilibili.com/"
}
file = open('lanyin.txt', 'w',encoding='utf-8')
def get_SecondReply(headers,root):
pn = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={pn}&type=1&oid=824175427&ps=10&root={root}&_=1679992607971")
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
reply_num = 0
if(respond.status_code == 200):
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html)
if json_html['data']['replies'] is None:
if(pn == 1):
return 0
else :
return 1
for i in range(0,len(json_html['data']['replies'])):
if json_html['data']['replies'] is None:
break
reply = json_html['data']['replies'][reply_num]['content']['message']
reply = reply.replace('\n',',')
# print(reply)
reply_num += 1
file.write(" " + reply + '\n')
pn += 1
time.sleep(0.5)
else:
print("Sreply error!")
exit(-1)
def get_rootReply(headers):
num = 1
replay_index = 1
while True:
URL = (f"https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={num}&type=1&oid=470113786&mode=3&plat=1&_=1680096302818") #获得网页源码
respond = requests.get(URL , headers = headers) # 获得源代码 抓包
# print(respond.status_code)
reply_num = 0
if(respond.status_code == 200): # 如果响应为200就继续,否则退出
respond.encoding = "UTF-8"
html = respond.text
json_html = json.loads(html) # 把格式转化为json格式 一个是好让pprint打印,一个是好寻找关键代码
if json_html['data']['replies'] is None or len(json_html['data']['replies']) == 0 :
break
for i in range(0,len(json_html['data']['replies'])): #一页只能读取20条评论
reply = json_html['data']['replies'][reply_num]['content']['message']
root = json_html['data']['replies'][reply_num]['rpid']
reply = reply.replace('\n',',')
# print(reply)
file.write(str(replay_index) + '.' + reply + '\n')
if json_html['data']['replies'][reply_num]['replies'] is not None:
if(get_SecondReply(headers,root) == 0):
for i in range(0,len(json_html['data']['replies'][reply_num]['replies'])):
reply = json_html['data']['replies'][reply_num]['replies'][i]['content']['message']
reply = reply.replace('\n',',')
file.write(" " + reply + '\n')
reply_num += 1
replay_index += 1
num += 1
time.sleep(0.5)
else :
print("respond error!")
break
file.close()
if __name__ == '__main__':
get_rootReply(headers)
print("sucessful")
五、总结
自己随手写的代码,比较垃圾,欢迎大佬指正。
本文转载自: https://blog.csdn.net/ClushioAqua/article/details/129834114
版权归原作者 Clushio小汐 所有, 如有侵权,请联系我们删除。
版权归原作者 Clushio小汐 所有, 如有侵权,请联系我们删除。