
1.简介:
PaddleOCR是飞桨(PaddlePaddle)推出的一个端到端的光学字符识别开源工具集,支持中文、英文、数字以及特殊符号等各种类型的文字检测、识别和词语整体识别。该工具集使用PaddlePaddle深度学习框架技术,提供了多种OCR模型和算法,包括基于CNN+CTC、DenseNet+CTC等模型,能够针对不同场景和应用提供最优的OCR解决方案。同时,PaddleOCR还集成了OCR精度评估工具,可以快速地评估OCR模型的准确率和鲁棒性。除此之外,PaddleOCR还提供了丰富的API接口和命令行工具,使得用户可以轻松地进行OCR应用的开发和部署。
PaddleOCR除了支持通用文字识别外,还具备大量针对特定领域或行业的OCR功能,例如身份证/银行卡实现、表格识别、汽车VIN码识别、发票识别、名片识别等。相比其他OCR工具,PaddleOCR在识别精度、效率和扩展性等方面都有着较好的表现和广泛的适用性,是目前业内较为流行和优秀的OCR工具之一。
2.安装部署
PaddleOCR的安装较为简单,直接在终端用pip安装即可,共三部分:
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple/
tips:运行第三步的时候可能报错:
PyMuPDF/setup.py: extra_link_args=['mupdf-1.20.3-source/build/release/libmupdf.a', 'mupdf-1.20.3-source/build/release/libmupdf-third.a']
running bdist_wheel
running build
running build_py
running build_ext
building 'fitz._fitz' extension
swigging fitz/fitz.i to fitz/fitz_wrap.c
swig -python -o fitz/fitz_wrap.c fitz/fitz.i
error: command 'swig' failed: No such file or directory
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for PyMuPDF
Running setup.py clean for PyMuPDF
Failed to build PyMuPDF
ERROR: Could not build wheels for PyMuPDF, which is required to install pyproject.toml-based projects
解决方法:这个错误信息表示在安装 PyMuPDF 时出现了问题,可能是因为缺少 swig 工具。swig 是一个用于将 C/C++ 代码转换为 Python 可调用接口的工具,PyMuPDF 使用 swig 来生成 Python 接口。你需要先安装 swig 才能成功安装 PyMuPDF。
使用以下命令来安装 swig:
sudo apt-get install swig
然后再重新安装 PyMuPDF即可安装成功。
3.应用简单项目:
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
#要识别图片的路径:
img_path = r"./1.png"
#识别结果:
result = ocr.ocr(img_path, cls=True)
#结果输出展示:
for line in result[0]:
print(line)
paddle识别输出结果包含三部分内容:识别文字在图中的位置boxes、识别出来的文本txts、识别结果置信度scores。
这三分存放在result列表中。其结构是这样的:
[[
[第一行的位置,(第一行的内容,得分)],
[第二行的位置,(第二行的内容,得分)],
[第三行的位置,(第三行的内容,得分)]
]]
由于boxes、txts、scores混合在列表中不方面使用,这里我们在识别结果的基础上把最终识别内容提取出来:
boxes = []
txts = []
scores = []
for line in result[0]:
txts.append(line[1][0])
print("txts:")
for i in range(len(txts)):
#原格式文本输出
print (txts[i])
#输出不换行
#print (txts[i],end = "")
4.本人案例实现
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
#要识别图片的路径:
img_path = r"./2.png"
#识别结果:
result = ocr.ocr(img_path, cls=True)
#结果输出展示:
#for line in result[0]:
# print(line)
boxes = []
txts = []
scores = []
for line in result[0]:
txts.append(line[1][0])
print("txts:")
for i in range(len(txts)):
#原格式文本输出
print (txts[i])
待识别的图像2.png

识别结果:
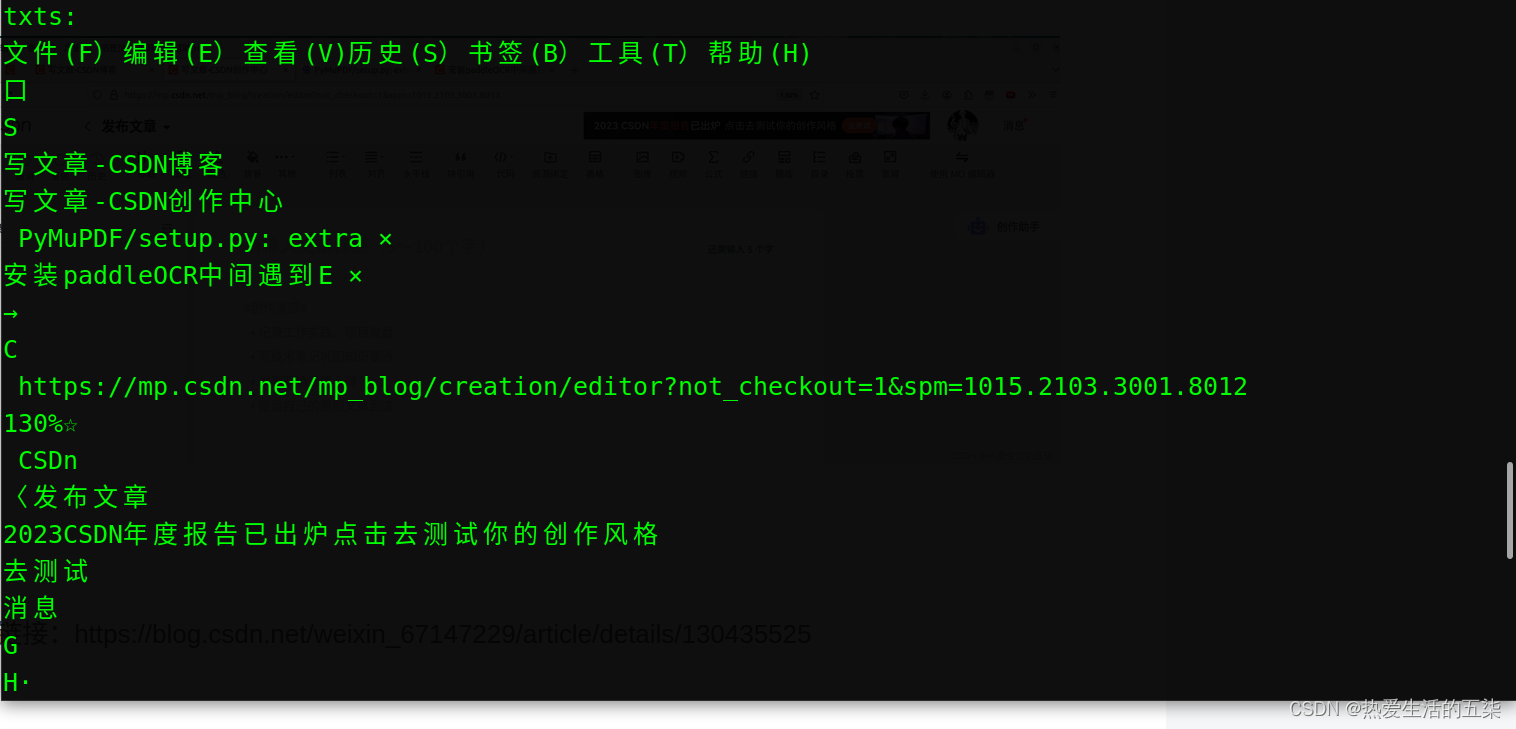
tips:
1.识别时候三从上到下按行识别。
2.身份证/银行卡实现、表格识别、汽车VIN码识别、发票识别、名片识别等。相比其他OCR工具,PaddleOCR在识别精度、效率和扩展性等方面都有着较好的表现和广泛的适用性,是目前业内较为流行和优秀的OCR工具之一。
3.PaddleOCR 库可以处理倾斜、歪曲或旋转的图片。通过启用角度分类功能 (
use_angle_cls=True
),PaddleOCR 可以检测并自动校正这些图像的角度。
项目地址:ocr: 利用PaddleOCR识别图片文字https://gitee.com/qu-zhijie-666/ocr.git
参考链接:https://blog.csdn.net/weixin_67147229/article/details/130435525
版权归原作者 热爱生活的五柒 所有, 如有侵权,请联系我们删除。