
👳我亲爱的各位大佬们好😘😘😘
♨️本篇文章记录的为 利用MySQL JSON特性优化千万级文库表 相关内容,适合在学Java的小白,帮助新手快速上手,也适合复习中,面试中的大佬🙉🙉🙉。
♨️如果文章有什么需要改进的地方还请大佬不吝赐教❤️🧡💛
👨🔧 个人主页: 阿千弟
🔥 上期内容👉👉👉: AOP的另类用法 (权限校验&&自定义注解)
前言:
一个类似于知网,范围又不局限于论文的这样的一个高质量文库,比如图书呢,它也有着与图书专属的这种类型属性,那像这样的底层的数据表呢,有几十个,都是围绕着一份文档来进行的描述,那刚开始构建的时候,我的哥们遇到了一个比较棘手的问题,就是不同类型的图书呢,他们所使用的属性是不一样的😥😥😥.

问题描述: 多表关联查询, 效率低
比如说图书类的文档呢,它可能会包含SBN、出版社这些信息,而论文类的呢,它要发表在报纸、期刊、杂志上,同时呢,还要去登记版号、版面等等这些信息,至于其他的,比如说一些网文或者一些高价值的文章呢,也都有自己的一些专有的属性,那么这就意味着在进行一个文档提取的时候,前台要显示出来,我们要底层查询的表其实是很多的.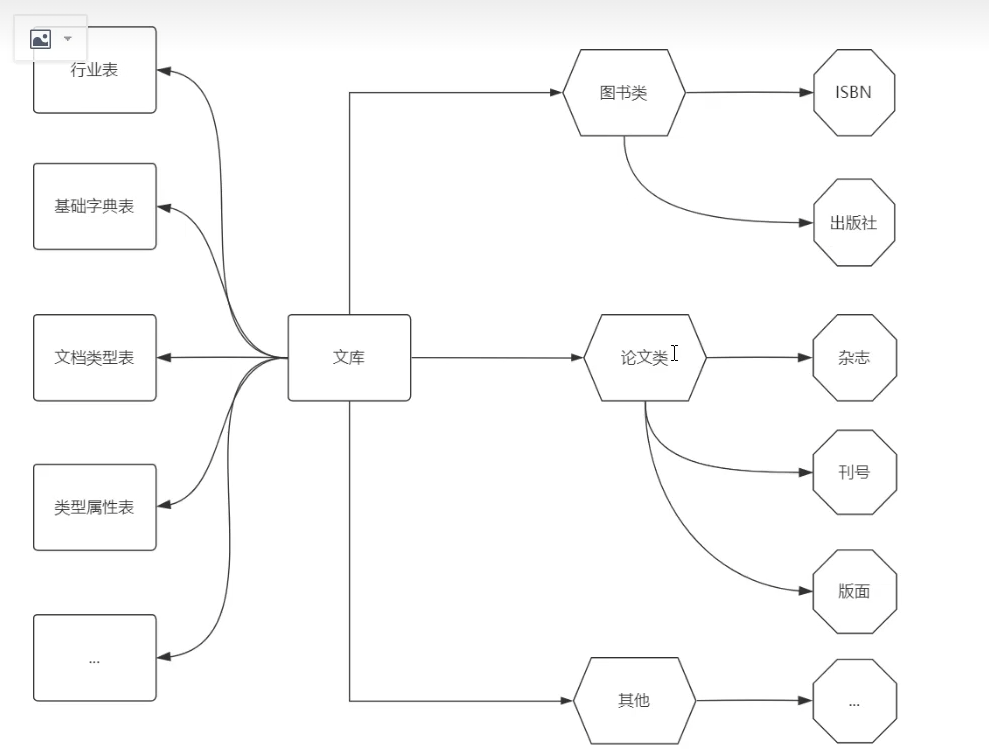
我简单的罗列一下,比如说先要获取文档的主体的内容,然后去获取对应这个文档是哪个类型的,之后呢,再获取这个文档所拥有的哪些属性,比如说这个文档是个图书的话,那么它要获取SBN和出版社,然后再根据刚才的SBN和出版社获取这个文档,存在一些多对多的关系,那除此以外,还有比如说其他若干个基础信息都分散在了不同的表里边,那么我们可以看到针对于这一个操作来说,它呢其实包含了很多个数据表的查询和关联,这个处理效率在它们之前没有经过优化的时候呢,大概需要200毫秒时间才能把这些数据都提取完,那后来他们是怎么调整的呢?

解决方案一 : 反范式设计
一个版本,这个1.0呢,就是采用反范式设计,基于宽表,也就是我们典型的空间换时间,可以看到刚才我们处理慢的一个主要思路呢,就是一个数据表要查询多次才能获得完整的信息。那如果我们把这些数据都。综合到一个宽表里边儿,也就是我们反范式表是不是就可以了呢?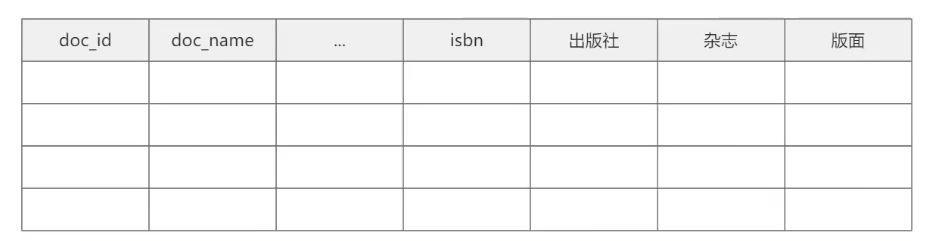
其实这个思路非常的好,我们可以比如说把所有的属性呢,以列的形式在这儿呢,都进行体现出来
弊端
在当前的这个宽表中呢,包含了所有可能会出现的属性,哪一个属性有数据,我们就提取哪一个,但是针对宽表呢,在我们日常工作中啊,并不太推荐使用,有两个原因 :
- 它的字段一多以后,字段的动态填充和减少是要锁表的,尤其在数据量一大的时候,比如现在我们针对某一个杂文又有一个新的属性,你一旦添加列的时候,整个这个表就锁了。 对于我们的维护非常的不方便.
- 数据查询的时候非常麻烦,难以基于动态列的方式来进行了提取数据
- 作为宽表还有一些不能解决的问题,难以体现出一对多的关系

解决方案二 : mysql5.7后Json特性
采用mysql5.7之后所提供的一个叫Json的数据类型,所谓Json数据类型啊,其实就是把我们日常开发中数据序列化产生的这个Json直接存储到了mysql的对应的Json列里边,作为MYSQL5.7以后天然的对于这个Jason的存储解析,还有提取呢,都进行了支持
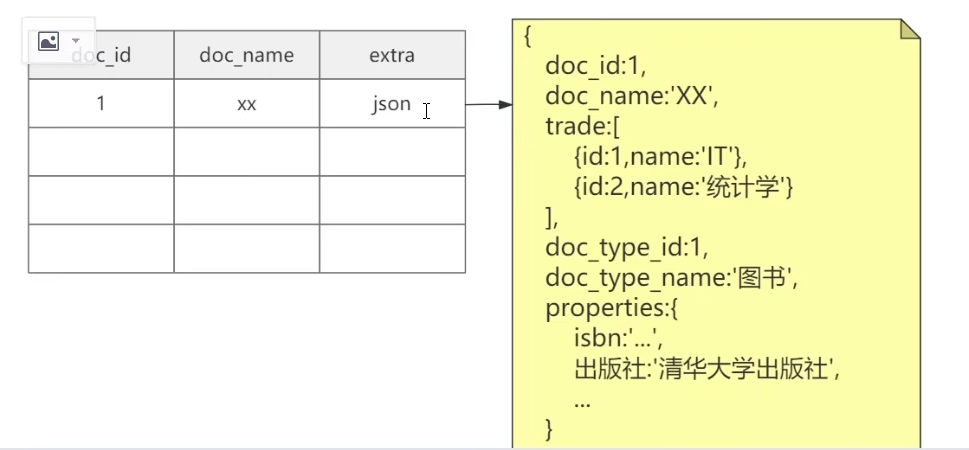
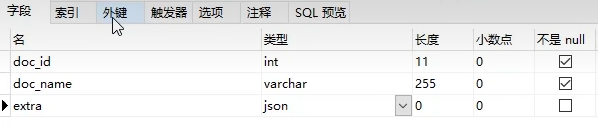
创建json列
这里模拟插入一条假数据
INSERT INTO t_base_data VALUES (1,'量子纠缠理论',
'{"caption":"量子领域","brandId":103,"category1Id":903,"category2Id":945,"category3Id":946,"freightId":10,"image":"https://img14.360buyimg.com/n1/jfs/t1/181065/5/3216/48663/6098c03fEad0ea4e5/659d59d79f8d0043.jpg","introduction":"遇事不决,量子力学","saleService":"实验室实战","templateId":42}'
);
执行sql语句
SELECT NAME,(JSON_EXTRACT(content, '$.brandId')) brandId,JSON_UNQUOTE(JSON_EXTRACT(content, '$.caption')) caption
FROM t_base_data;

可以看出
JSON_UNQUOTE函数作用是 去除json字符串的引号,将值转成string类型JSON_EXTRACT函数作用是 提取json值
使用json中的字段作为查询条件
SELECT NAME,
content -> '$.brandId' brandId,
content -> '$.caption' caption
FROM t_base_data
WHERE content -> '$.templateId' =42;

->表达式 等同于JSON_EXTRACT(content , '$.caption'))
SELECT NAME,
content ->> '$.brandId' brandId,
content ->> '$.caption' caption
FROM t_base_data
WHERE content -> '$.templateId' =42;

->>表达式 等同于JSON_UNQUOTE(JSON_EXTRACT(content , ‘$.caption’))
很好, 通过上面的方法, 我们可以很好的将弱关联字段查询出来了, 但是呢, 这个方式仍然不够完美, 虽然解决了链表查询耗时的问题, 但是我们如果想在千万级的数据中查询出我们所期望的这仍然很耗时
不妨尝试建立索引, 我们该怎么建索引呢?
小老弟小老妹们可能就要问了, 都是json串, 怎么建立索引呢
也许你们忘了一种叫做虚拟列的东西

继续优化
1. 创建虚拟列
ALTER TABLE t_base_data ADD COLUMN tb_templateId VARCHAR(32) GENERATED ALWAYS AS (content -> '$.templateId');

那与此同时呢,还有一个优秀的特点,基于这样书写以后,如果我们原始的Json数据发生了变化,只要一更新以后,对应的结果也会随之发生对应,从使用的角度来说,它就是一个标准的字段,只不过这个字段呢,只能读不能写而已
2. 将索引创建在虚拟列上
CREATE INDEX idx_tb_templated ONt_base_data(tb_templateId);
EXPLAIN SELECT * FROM t_base_data WHERE `tb_templateId` =43;

可以看到索引已经生效, 问题完美解决
总结 : 效率高, json实用性强
- 利用JSON解决动态数据问题,MySQL5.7以后提供了JSON数据类型,可以直接对JSON存储、提取与解析。
- 因为JSON是弱约束的,因此存储数据非常灵活,同时也可基于虚拟列实现索引优化。
我的哥们儿把数据的查询效率一下子提升了有十几倍之多,这是一个非常好的办法, 在未来的项目中,我也会考虑基于Jason的这种活性呢,来优化我们的程序结构

如果这篇【文章】有帮助到你💖,希望可以给我点个赞👍,创作不易,如果有对Java后端或者对
spring感兴趣的朋友,请多多关注💖💖💖
👨🔧 个人主页: 阿千弟
版权归原作者 阿千弟 所有, 如有侵权,请联系我们删除。